docker registry 就是管理 docker 镜像的服务, Docker 公司维护的 registry 就是 http://hub.docker.com ,它可以让我们方便的下载预先做好的镜像。这篇博客把作者做的一些实验分享给大家,让你也能在docker环境下起这些服务体会一下,再简单解释一下是如何用nginx来怎么这些问题。
AD:51CTO 网+ 第十二期沙龙:大话数据之美_如何用数据驱动用户体验
docker registry 介绍
docker registry 就是管理 docker 镜像的服务, Docker 公司维护的 registry 就是 http://hub.docker.com ,它可以让我们方便的下载预先做好的镜像。
- $ docker pull ubuntu
上面的命令就是缺省的从这个Docker官方源下载。在国内为了加快访问,你也可以使用docker.cn 的服务,他们同步了常用的镜像,使用也非常方便,如:
- $ docker pull docker.cn/docker/ubuntu
大部分公司在推广使用 docker 时,都会为了使用方便,在公司内部自己架设一个,不仅仅是为了安全、节省大量的带宽,而且也可以有效推动内部对docker的有效利用,如下图:
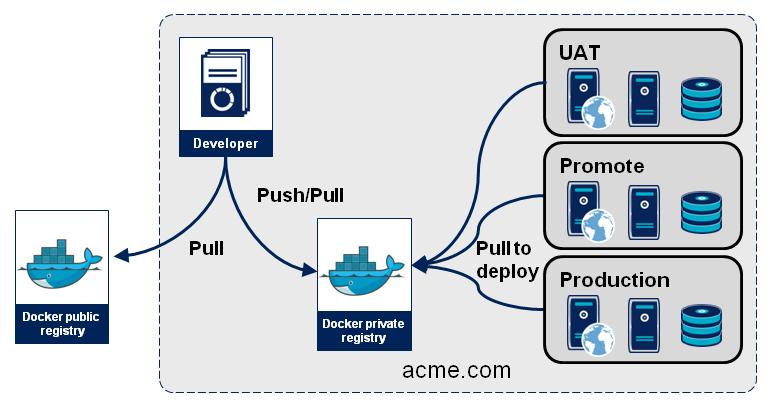
Docker公司的 docker registry也是开源的,我们可以很容易的架设自己的私有docker registry,启动时典型的docker方式,就是:
- $ docker run -d -p 5000:5000 registry
使用也很简单了,下面的命令就是把官方的ubuntu镜像放在私有的registry:
- $ docker tag ubuntu company.com:5000/ubuntu
- $ docker push company.com:5000/ubuntu
不过他有以下几个问题:
- registry缺省没有安全权限的设置,任何人都可以pull、push,这个基本上是不能接受的。
- 十月发布的docker 1.3.x版本的发布有很多新的功能,但也强制基本鉴定(basic authentication)必须使用https,极其烦人。
这篇博客就把作者做的一些实验分享给大家,让你也能在docker环境下起这些服务体会一下,再简单解释一下是如何用nginx来怎么这些问题。所有的实验都是在Windows boot2docker的环境下完成,理解后在其他docker环境应该也一样。
先会把成功的环境演示一下,后面再把其中的技术稍微解释一下。
演示环境说明
让我们先来看看这个nginx+registry的服务是怎么组成的。
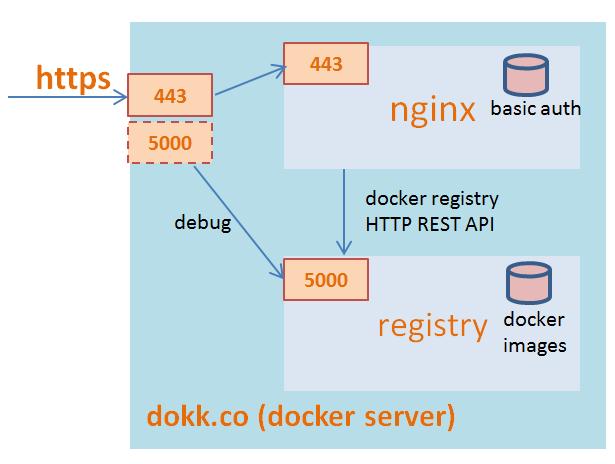
dokk.co 这是docker服务器的名字也就是你的公司docker私有服务器的地址,因为https的SSL证书不能用IP地址,我就随便找了个名字,做实验没有问题。
registry 服务器作为上游服务器处理docker镜像的最终上传和下载,用的是官方的镜像。
nginx 是一个用nginx作为反向代理服务器,通过模块提供https的ssl的认证和basic authentication,加上必要的配置,用的是我自己做的一个镜像 larrycai/nginx-auth-proxy 。
这里可以看到典型的互联网服务,nginx把这些https、认证服务搞定,registry关注docker的镜像服务就可以了。
可以很方便的启动这些服务,命令如下:
- $ docker run -d --name registry -p 5000:5000 registry
- $ docker run -d --name nginx --link registry:registry -p 443:443 larrycai/nginx-auth-proxy
命令稍加解释一下
--name registry:这是docker的容器链接(link)技术,为了方便 nginx 容器的访问 registry(对应 --link registry:registry ),稍后还有解释。
-p 5000:5000 registry 作为上游服务器,这个 5000 端口可以不用映射出来,因为所有的外部访问都是通过前端的nginx来提供,nginx 可以在私有网络访问 registry 。端口映射出来只是为了方便调试,确保查看 registry 是否独立也能工作。
-p 443:443 就是对外服务的https端口。
尝试
多说无益,尝试一下,看看到底现在可以能做啥了。
Registry服务
先验证 registry 是否正常:
- $ docker pull hello-world # 这个hello world包很小,适合做实验
- $ docker tag hello-world localhost:5000/hello-world
- $ docker push localhost:5000/hello-world
- The push refers to a repository [localhost:5000/hello-world] (len: 1)
- Sending image list
- Pushing repository localhost:5000/hello-world (1 tags)
- 511136ea3c5a: Image successfully pushed
- 7fa0dcdc88de: Image successfully pushed
- ef872312fe1b: Image successfully pushed
- Pushing tag for rev [ef872312fe1b] on {http://localhost:5000/v1/repositories/hello-world/tags/latest}
结果一切正常,registry已经能提供后端的 docker registry 服务了。
docker的HTTPS服务
现在看看nginx的https服务怎么样,先用curl命令。( larrycai:passwd 是我预先放置的用户和密码)
- $ curl -i -k https://larrycai:passwd@dokk.co
噢
- curl: (6) Couldn't resolve host 'dokk.co'
对了,这是自己杜撰的域名,需要在 /etc/hosts的localhost 后面加上 dokk.co ,如下。
- $ cat /etc/hosts
- 127.0.0.1 boot2docker localhost localhost.local dokk.co
再来一次尝试一下
- $ curl -i -k https://larrycai:passwd@dokk.co
- HTTP/1.1 200 OK
- Server: nginx/1.6.2
- Date: Sat, 29 Nov 2014 09:21:18 GMT
- Content-Type: application/json
- Content-Length: 28
- Connection: keep-alive
- Expires: -1
- Pragma: no-cache
- Cache-Control: no-cache
- "\"docker-registry server\""
说明连通了 nginx 和 registry 。说句实话,以前我没玩过nginx,看到这么简单,还是有点小激动,这么容易。
实际上也打开浏览器访问 https://192.168.59.103 , 192.168.59.103是 boot2docker 的VM的IP地址(你可以换成你的docker机器的IP地址)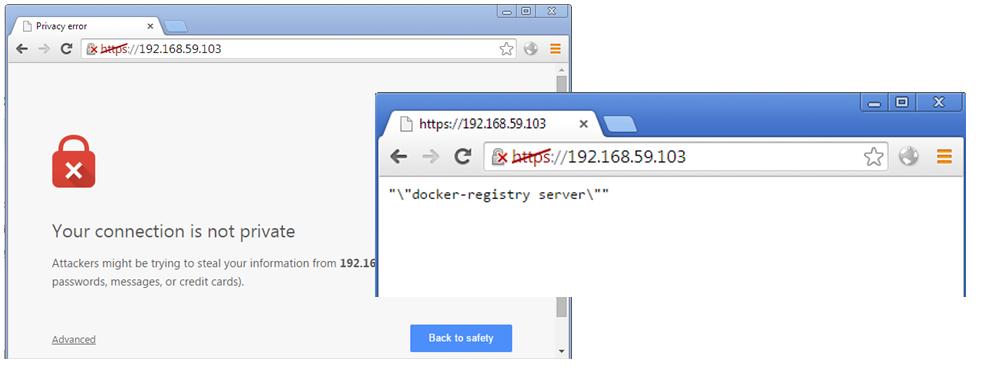
忽略安全告警后,输入用户名和密码 larrycai:passwd ,还是正确的访问到了上游的registry了。我用的是chrome,如果是IE,可能会要你存盘才能看到 "\"docker-registry server\"" 这行字符串。
docker 的 login 服务
如果我们希望 docker push 需要访问控制的话,在docker中是通过 docker login 先来登录的,成功后的配置信息存放在 ~/.dockercfg 。
先来试试不登录的情况:
- $ docker tag hello-world dokk.co/hello-world
- $ docker push dokk.co/hello-world
- The push refers to a repository [dokk.co/hello-world] (len: 1)
- Sending image list
看上去没啥反应,也没报啥错,但是明显没有 push 上去,再去docker的log( /var/lib/boot2docker/docker.log )中查查
- docker@boot2docker:~$ tail -f /var/lib/boot2docker/docker.log
- [debug] http.go:162 https://dokk.co/v1/repositories/hello-world/ -- HEADERS: map[User-Agent:[docker/1.3.2 go/go1.3.3 git-commit/39fa2fa kernel/3.16.7-tinycore64 os/linux arch/amd64] Authorization:[Basic Og==]]
- Error: Status 401 trying to push repository hello-world: <html>
- <head><title>401 Authorization Required</title></head>
- <body bgcolor="white">
- <center><h1>401 Authorization Required</h1></center>
- <hr><center>nginx/1.6.2</center>
- </body>
- </html>
- [00246b13] -job push(dokk.co/hello-world) = ERR (1)
可以发现提示需要鉴权,和预想的一样(这里要理解是docker的daemon和registry交互而不是docker客户)
好吧,先用docker登陆是否成功。
- $ docker login -u larrycai -p passwd -e test@gmail.com dokk.co
- 2014/11/29 12:42:12 Error response from daemon: Server Error: Post https://dokk.co/v1/users/: x509: certificate signed by unknown authority
OMG,镜像内部放的自签名证书它不相信,我们需要把服务器的根证书在docker这端自己认证一下。
让我们把我做 dokk.co 的根证书 ca.pem 下载下来,再加入到 boot2docker 的证书( /etc/ssl/certs/ca-certificates.crt )中。当然为了演示方便, ca.pem 已经放在容器中了,你可以直接把它拷贝出来。( docker cp 是个好命令,别忘了)
- $ docker cp nginx:/ca.pem $PWD
- $ cat ca.pem | sudo tee -a /etc/ssl/certs/ca-certificates.crt
不好意思,证书是docker的daemon需要用到的,docker服务需要重启。先停掉服务是个好习惯(体会到加 --name 的好处了吧)。
- $ docker rm -f registry nginx
- $ sudo /etc/init.d/docker restart
然后再次运行registry和nginx服务,然后 login
- $ docker run -d --name registry -p 5000:5000 registry
- $ docker run -d --name nginx --link registry:registry -p 443:443 larrycai/nginx-auth-proxy
- $ docker login -u larrycai -p passwd -e test@gmail.com dokk.co
- Login Succeeded
再上传试试
- $ docker tag hello-world dokk.co/hello-world
- $ docker push dokk.co/hello-world
- Sending image list
- Pushing repository dokk.co/hello-world (1 tags)
- 511136ea3c5a: Image successfully pushed
- 7fa0dcdc88de: Image successfully pushed
- ef872312fe1b: Image successfully pushed
- Pushing tag for rev [ef872312fe1b] on {https://dokk.co/v1/repositories/hello-world/tags/latest}
一切完美,测试结束,永远的v5。
技术讨论
现在来简单过一遍一些技术要点,不懂nginx的话也没多大关系,看懂关键点,多做实验。
basic auth
- 可以在 Dockerfile 中看到 nginx 编译的时候加载了 http_auth_request 模块
- RUN curl -s http://nginx.org/download/nginx-1.6.2.tar.gz | tar -xz -C /tmp \
- && cd /tmp/nginx-1.6.2 \
- && ./configure --with-http_ssl_module --with-http_auth_request_module && make && make install
然后在 nginx.conf 中配好用户名密码文件 docker-registry.htpasswd ,这个文件是有 htpasswd 命令产生。
- location / {
- auth_basic "Restricted";
- auth_basic_user_file docker-registry.htpasswd; # larrycai:passwd
- proxy_pass http://docker-registry;
- }
你可以试着进入 nginx 容器,运行 htpasswd 命令( docker exec 也是一个神奇的命令)
- $ docker exec -it nginx bash
- root@ea80e44b037b:/# htpasswd -c .htpasswd newuser
- New password:
- Re-type new password:
- Adding password for user newuser
- root@ea80e44b037b:/# cat .htpasswd
- newuser:$apr1$ZVVA17EI$pGLB1MtHbyML.K/ZfWNHD1
https ssl认证
上面可以看到, nginx 编译的时候加载了 http_ssl 模块。在 Dockerfile 中把预先创好的证书文件 server.crt/server.key 放到镜像中
- ADD server.crt /etc/ssl/certs/docker-registry
- ADD server.key /etc/ssl/private/docker-registry
然后在 nginx.conf 中把 ssl 开关打开,配好证书。
- ssl on;
- ssl_certificate /etc/ssl/certs/docker-registry;
- ssl_certificate_key /etc/ssl/private/docker-registry;
关于https自签名证书的问题,自己可以搜索学习,我是照着 Building private Docker registry with basic authentication 做的,关键是还要保留CA的证书,应该可以从浏览器中导出,我就直接放在镜像里了。
在 boot2docker 下如何处理证书,可以查看 boot2docker的issues #347 。现在重启后,证书目录会重置,现在可以放在脚本中 /var/lib/boot2docker/bootlocal.sh 自动加载,代码如下。
- #!/bin/sh
- cat /var/lib/boot2docker/ca.pem | sudo tee -a /etc/ssl/certs/ca-certificates.crt
nginx 到 docker registry
- 这个如果有 nginx 的知识一看就明白了,不懂的话,直接使用就好了,官方配置 https://github.com/docker/docker-registry/tree/master/contrib/nginx ,主要就是下面一些代码
- proxy_set_header Host $http_host; # required for docker client's sake
- proxy_set_header X-Real-IP $remote_addr; # pass on real client's IP
- proxy_set_header Authorization ""; # see https://github.com/dotcloud/docker-registry/issues/170
- proxy_read_timeout 900;
- client_max_body_size 0; # disable any limits to avoid HTTP 413 for large image uploads
- chunked_transfer_encoding on; # required to avoid HTTP 411: see Issue #1486 (https://github.com/dotcloud/docker/issues/1486)
- root /usr/local/nginx/html;
- index index.html index.htm;
- location / {
- auth_basic "Restricted";
- auth_basic_user_file docker-registry.htpasswd; # testuser:testpasswd & larrycai:passwd
- proxy_pass http://docker-registry;
- }
- location /v1/_ping {
- auth_basic off;
- proxy_pass http://docker-registry;
- }
- location /_ping {
- auth_basic off;
- proxy_pass http://docker-registry;
- }
摘要
在这篇博客中,我们演示了如何用Nginx作为前端服务器来解决Docker 私有registry的安全认证问题,通过它,你应该可以架设一个可以使用的安全的私有regsitry。
- 用nginx配好basic auth (使用htpasswd)
- 做好https自签名证书
- 用nginx配好https服务
- 把CA根证书导入要访问的docker机器
所有的代码你都可以在 github上的larrycai/nginx-auth-proxy 上找到。
当然现在常用的 pull 命令下载镜像也要认证了,在公司内部会非常讨厌,最好是可以匿名访问。而且一些出错处理也很简单,这些用nginx是比较容易实现的,有机会的话,我会再写博客讲解,如果你有好的方案的话,也请告知。
Docker 可以帮助我们做很多事情,关注我的新浪微博 @larrycaiyu ,我特别愿意探讨软件开发中如何使用docker。
原文出自:https://docker.cn/p/private-docker-registry-with-nginx
【编辑推荐】
- CentOS 下安装LEMP服务(Nginx、MariaDB/MySQL和PHP)
- 如何在 CentOS 7 上安装 Docker
- Docker容器对PaaS来说必不可少吗?
- CoreOS 称 Docker 有根本性缺陷,推出自己的容器引擎 Rocket
- Docker如何改变云计算安全?
