BizCloud简介
我们基础环境非常复杂,目前有多个版本操作系统共存,应用也常常存在着多个版本同时测试或部署,在多版本并行测试过程中,经常出现环境借用的情况,因操作系统和基础软件不一致的问题,会出现线下测试没问题,但上线后出问题;其次,线上的实体机在业务低峰时使用率较低,存在较大的提升空间;服务上下线也涉及到一系列机器的申请回收流程,需要手工执行,系统的弹性伸缩能力不足。这种种问题都是我们设计私有云的原因,也就是要做到保持环境一致、提升资源利用率,并提升弹性计算能力。
为了解决上述问题,我们使用目前非常流行的容器技术Docker和容器编排工具Kubernetes,研发了商业云平台BizCloud。但Docker和Kubernenets只提供了一个基础功能:容器运行和容器编排,如何能快速地学会使用,并为大家所接受才是关键。
在自研BizCloud过程中,一个重点就是要对接、打通现存的系统和流程,尽量保持用户操作习惯,服务在容器化的过程中,尽可能不需要调整,这样系统才易于推广落地;另一方面,我们要支持服务一键自动部署(QA特别需要这样的功能),服务出现故障后,如系统宕机或服务挂掉后,服务能自动迁移,而且我们需要支持灰度发布,尽量实现运维的自动化。
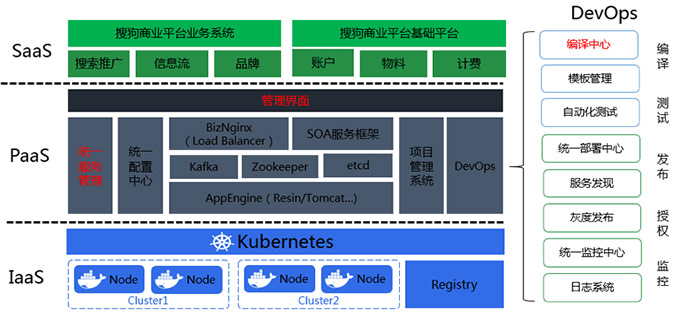
商业平台系统的整体架构如下图所示。共分为三层,IaaS层、PaaS层、SaaS层:在IaaS层,我们使用Docker+Kubernetes封装了部门的基础资源,提供容器化服务;PaaS层提供了很多基础服务和基础框架,并且也实现了一些自动化工具,包括刚才提到过的统一服务管理中心,统一配置中心,项目管理系统、SOA服务框架等,贯穿了应用开发、测试、运维整个生命周期的一体化平台,其中的红色部分,包括服务管理、编译中心、商业云平台都是为BizCloud而新开发的模块;第三层SaaS主要是一些商业平台业务系统。本文的分享也主要集中在PaaS层的研发实践上。
关键功能解析
对于一个服务而言,不管是部署还是故障迁移,都有很重要的两个功能:在服务启动之前,要申请服务所需资源的权限,如数据库权限,开通iptables等,也就是服务授权;而服务启动之后,要暴露服务给使用方,现在服务部署到某个机器上了,需要将请求发送到这台机器上,这个过程是服务发现。以往这两个工作主要是人工执行,在BizCloud中,这两个过程需要自动化执行。
自动化执行这个过程需要解决3个问题:1) when,什么时候执行;2)who,谁来执行;3)how,怎么执行。为实现服务版本的平滑过渡,BizCloud也提供了灰度发布功能,以降低上线风险;灰度发布不是一个独立的系统,但和系统的架构是紧密相连的。下面我们分别介绍服务发现,服务授权和灰度发布的实现要点。
服务发现
首先是when,即服务发现和服务授权的发起时间,我们知道在Kubernetes服务里,服务状态的变化和Pod的变化是紧密相连的,因此,我们引入了一个模块k8s-monitor,用来监控并判断发起动作。
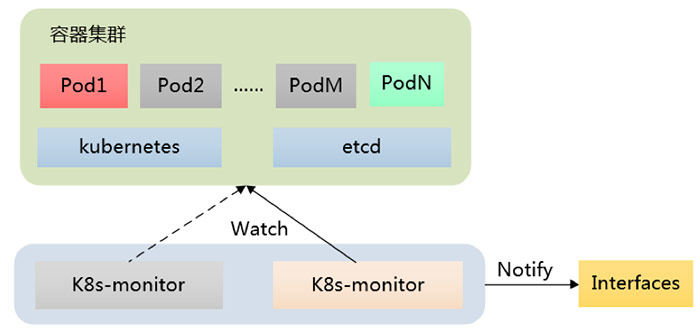
k8s-monitor是BizCloud的监控器,其主要功能是监控Kubernetes集群中的Pods的状态事件:ADD、MODIFY、DELETE,监控到事件后,k8s-monitor计算是否需要进行服务发现或服务授权等相关处理,如果需要,则通知下游系统进行处理。除了常规的事件监控之外,k8s-monitor还会定期与服务管理模块同步数据,清理服务管理模块上可能存在的脏数据。
使用k8s-monitor这样一个单独的模块,好处是显而易见的:将相关权限集中管理起来,避免云平台入侵应用,如果没有这样一个模块,每个应用都需要增加自己的的服务授权和服务发现的功能,对模块入侵较大;其次,这个模块非常容易扩展,其他服务也可以订阅这个模块的数据,实现自己的处理逻辑。
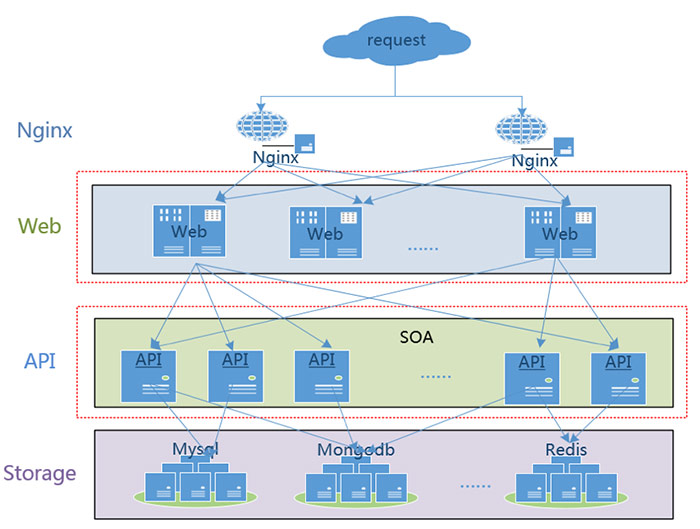
通常一个典型的服务都有两层:一个用户接入层,通常是用Nginx接入用户流量,Nginx将流量分发到后面的Web服务器上;第二层SOA层,这里Web服务通过SOA调用后端服务,后端服务也可继续调用其他服务,最终将用户请求返回。在做服务发现时,需要完成这两种类型的服务发现。
首先,对于接入层,如图所示,如果Pod1因故障挂掉,Kubernetes重新调度了PodN之后,k8s-monitor监控到(至少)2个事件:Pod1 DEL,PodN ADD,k8s-monitor将事件通知到服务管理中心。Nginx会实时从服务管理中心获取服务对应关系,动态加载Nginx配置,将已经挂掉的Pod1从Nginx中摘除,新增加的PodN暴露给外部。
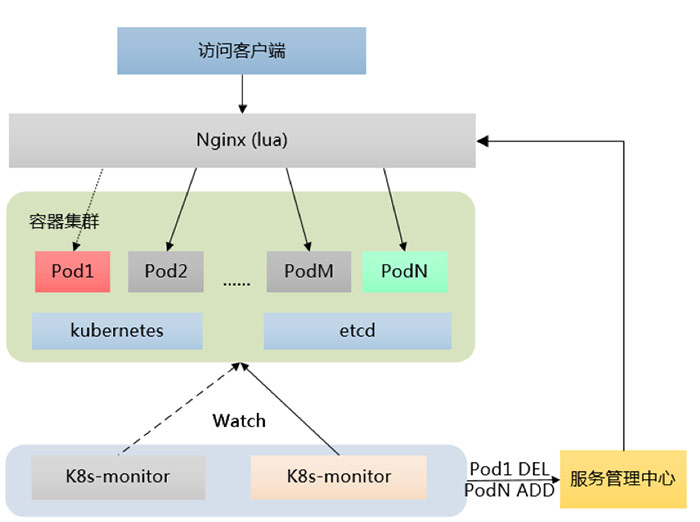
而SOA服务的角色分为两种,一种是consumer,一种是provider。consumer和provider之间的负载均衡、白名单控制是通过SOA的注册中心来统一管理。像图里展示的,如果Pod1因故障挂掉,Kubernetes重新调度了PodN之后,k8s-monitor将监控到的事件Pod1 DEL,PodN ADD通知到SOA注册中心,SOA注册中心会将对应的变化更新到ZK上,ZK会触发事件通知服务的consumer获取最新的服务provider。
授权
由于商业平台的特殊性,对权限控制非常严格,权限控制的重要性在于:1)防止测试流量打到线上; 2)防止恶意访问等。以前模式往往是人工检验进行授权,但在云平台上,这种方式不再适用,Kubernetes也没有直接提供授权的功能,而且授权是和系统架构紧密相关的。
为满足BizCloud的需求,对服务授权进行了改造,当时改造面临了一些挑战:首先服务依赖关系从何获取;其次,容器可能随时启动、销毁,服务IP会随容器变动;再次,我们需要同时支持DB授权、IP白名单授权、SOA等不同粒度的授权。
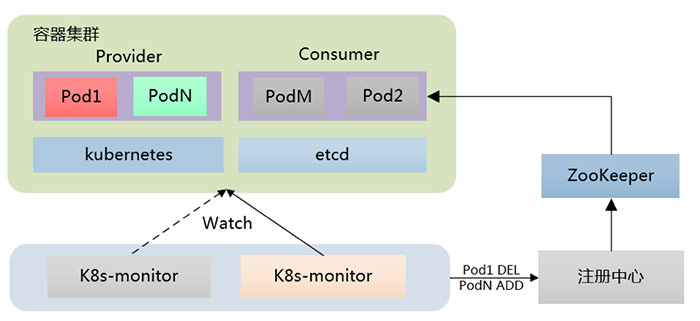
服务授权的发起仍然依赖于k8s-monitor,与服务发现类似,k8s-monitor将监控到的事件Pod1 DEL,PodN ADD,包括一些其他服务基本信息、IP等通知到授权模块,授权模块开始执行授权工作。
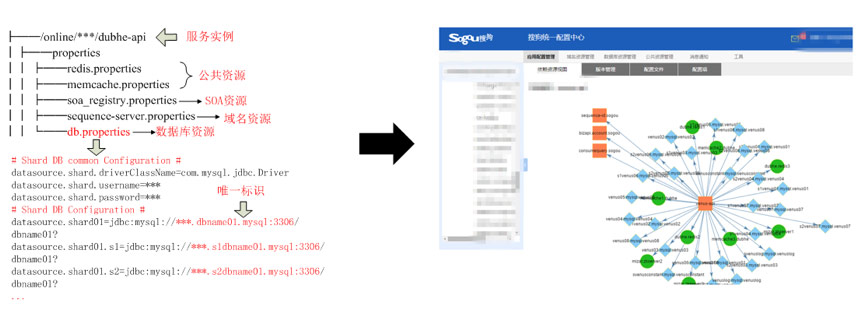
刚才说明了授权的时间,但具体给谁来授权呢?如下图所示,每一个服务都有自己的服务配置信息,这里展示一个服务,该服务依赖了很多资源,包Redis、数据库(1个主库、2个从库)等资源。将这些配置文件上传到配置中心后,配置中心会将这些配置解析,然后根据这些依赖关系计算出依赖图,如右图所示。新启动的服务可以从配置中心获取自己的资源依赖关系,要申请的资源。
对于不同类型的授权,我们有不同的处理方式,每种授权对应的粒度也不同:1)DB授权,授权信息包括ip+port+user,通过数据库执行机来执行,将授权信息写入数据库权限表;2)SOA授权,这里授权信息包括服务实例+ip+port,该类授权通过SOA注册中心执行,最终生成服务访问白名单;3)iptable授权,授权信息包括ip+port,这类授权通过salt-stack执行,最终会写入系统的iptables文件。

灰度发布
我们的灰度发布的周期一般比较长,为了保证灰度的一致性,我们会将上下游依赖的服务分组,一个正常组,一个灰度组。在具体执行时,我们会多建一个灰度的Deployment,这样每个服务有2组Deployment,一个正常Deployment、一个灰度Deployment,然后根据灰度比例动态调节正常Deployment和灰度Deployment的实例数,从而实现灰度发布。在流量接入方面,我们已经实现了基于用户ID的灰度,在BizCloud上,我们的灰度分流仍然基于用户ID。

灰度发布时的服务发现同样包括接入层和SOA层两部分:对于接入层,我们使用了OpenResty,并引入了ngx_dynamic_upstream模块,这样可以通过HTTP API方式动态调整服务的Upstream;在SOA层的灰度发布中,我们对consumer-provider划分为了可以动态更新的两个组:正常组和灰度组,k8s-monitor将变更发送到SOA注册中心后,SOA注册中心还是通过ZK通知Consumer取最新的provider分组,从而实现灰度分流。
配套工具
为了更方便地使用BizCloud,我们提供了多个配套工具。
WebShell
首先是WebShell。通过WebShell,我们可以从Web浏览器以类似SSH的方式登录并操作Docker容器,方便开发运维等查看、调试系统。
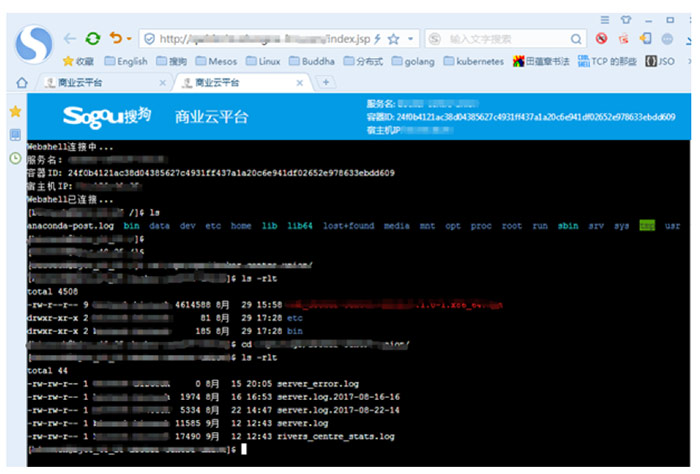

Webshell主要有3个组件:1)Web浏览器负责界面呈现;2)Docker Controller是Docker容器应用的控制中心,作为桥梁,负责消息的转发;3)Docker Daemon提供HTTP API接口给外部系统调用以访问容器内部。

Web浏览器运行JS脚本,通过Web Socket与Docker Controller建立通信链路。Docker Controller通过Docker HTTP API与Docker Daemon建立通信链路。这里使用到Docker HTTP API的接口,利用返回的数据流承载Docker Controller和Docker Daemon之间的交互数据。链路建立后,用户就可以在Web浏览器输入字符与Docker容器交互。
模板生成
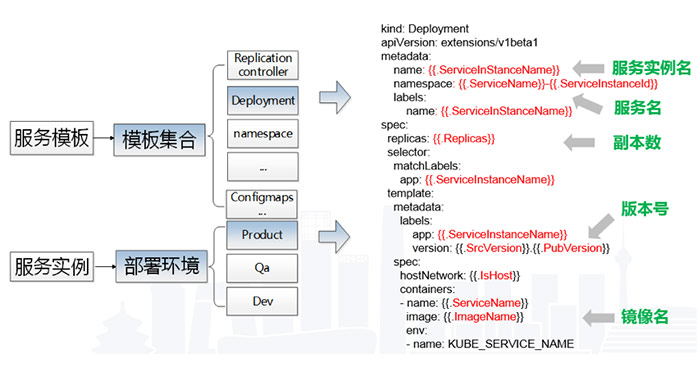
我们还提供了模块自动生成的功能,这样开发只需要关注自己的服务即可,不需要重复编写发布等一系列Kubernetes部署文件。对于一个服务,服务部署模板是提供了一类模板的集合,包括Deployment、Namespace、ConfigMaps,这些模板都是可参数化的。在具体部署服务时,也就是实例化一个服务,我们先查找服务实例的部署环境具体的部署参数,然后将这些参数注入到模板中,生成具体的模板文件,然后发布。
相关系统
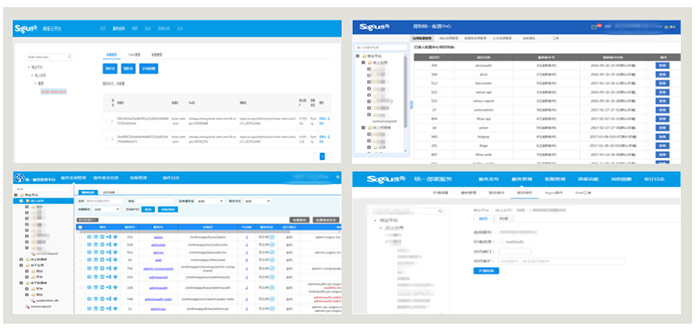
云平台其他模块在这里做了一个简单的展示,在左上角展示了一个应用正在运行的容器,并可以点击控制台登录到容器内部;右上角是统一配置中心,可以查看、操作引用对应的配置;左下角是统一服务管理平台,上面罗列了现在线上存在的一些服务信息;右下角是统一部署中心,在上面可以查看服务部署的情况,包括服务授权信息、服务发现信息等等。
小结
在本次分享中,我们对搜狗商业平台部的私有云BizCloud的来龙去脉做了一个简要介绍,然后介绍了在实现商业云平台中的关键机制,包括授权、服务发现、灰度发布的实现,也介绍了一些相关配套工具如WebShell等。使用BizCloud后, 对于dev而言流程基本不变,QA在搭建测试环境时,能一键部署相关服务,方便了很多,但对ops,在BizCloud上配置好应用的资源需求后,即可部署系统,一键实现服务扩缩容(包括横向扩展,增加或减少服务实例数,也可以横向扩展,增加服务的CPU和内存数),自动进行服务发现和授权,避免了大量重复性手工操作。
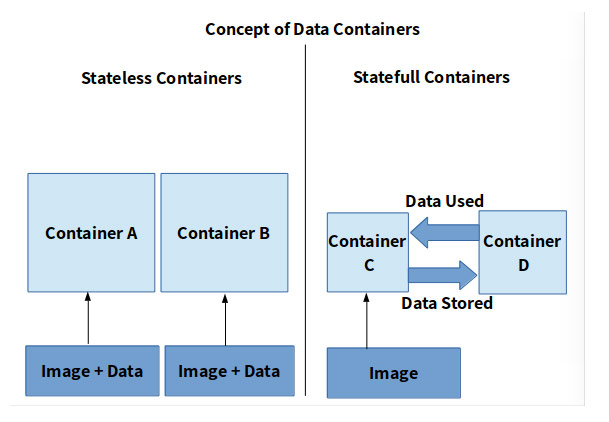
目前我们正在进行一些有状态服务的容器化工作,如Redis、MySQL的容器化。因为我们对数据的准确性和稳定性要求非常高,所以将数据库的容器化是非常谨慎的,我们希望随着容器技术不断发展,在未来也能顺利实现基础资源的容器化。更智能的调度:我们希望能实现一个资源负载可预测的调度算法,能结合应用的CPU、内存、磁盘、网络IO、DISKIO、DBIO等历史数据指标进行综合计算,给出多维度下的基于时间片、优先级的准确实时的负载预测,来执行更智能的调度。
以上内容根据2017年09月26日晚DockOne社区微信群分享内容整理。 分享人刘林,搜狗高级工程师,毕业于中国人民大学,有多年的后台服务开发经验,现供职于搜狗商业平台研发部,负责私有云的研发工作。DockOne每周都会组织定向的技术分享,欢迎感兴趣的同学加微信:liyingjiesa,进群参与,您有想听的话题或者想分享的话题都可以给我们留言。
来源: https://www.kubernetes.org.cn/2831.html