RocketMq关键点理解
各个角色间的关系:
RocketMq中每个Broker(master和slave)与Name Server集群中的所有节点建立长连接,定时注册Topic信息到所有Name Server。
Name Server之间不会有任何信息交互,各自独立。
producer和consumer随机从一个name server即可获得全部topic的路由信息。
producer根据得到的路由信息,同master建立长连接。
consumer根据路由信息,同master个salve都建立长连接。然后根据设置的订阅规则,选择从master或者slave订阅消息。
Broker:
分为master和slave两个角色。master提供读写读物,salve只提供读服务。
为了保证可用性,需要部署多套broker,每套broker至少有1个master和1个以上的salve。
在同一套broker中,master和salve都是同样的brokerName,master的brokerId是0,salve的brokerId必须是非0的。
同步刷盘和异步刷盘。
同步刷盘是说,broker在收到每个消息后,都是先要保存到硬盘上,然后再给producer确认。异步刷盘就是先回复确认,然后批量保存到硬盘上。异步刷盘有更好的性能,当然也有更大的丢失消息的风险。
同步复制和异步复制。
是说在master和salve之间复制消息的方式。同步是说在salve也存储了消息后再答复producer。
异步复制是先答复producer,再去向salve复制。
通过同步复制技术可以完全避免单点,同步复制势必会影响性能,适合对消息可靠性要求极高的场合,例如与Money相关的应用。RocketMQ从3.0版本开始支持同步双写。
MQPullConsumer和MQPushConsumer的区别
consumer被分为2类:MQPullConsumer和MQPushConsumer,其实本质都是拉模式(pull),即consumer轮询从broker拉取消息。
区别是:
push方式里,consumer把轮询过程封装了,并注册MessageListener监听器,取到消息后,唤醒MessageListener的consumeMessage()来消费,对用户而言,感觉消息是被推送(push)过来的。
pull方式里,取消息的过程需要用户自己写,首先通过打算消费的Topic拿到MessageQueue的集合,遍历MessageQueue集合,然后针对每个MessageQueue批量取消息,一次取完后,记录该队列下一次要取的开始offset,直到取完了,再换另一个MessageQueue。
对RocketMQ使用长轮询Pull方式,可保证消息非常实时,消息实时性不低于Push的理解
数据交互有两种模式:Push(推模式)、Pull(拉模式)。
推模式指的是客户端与服务端建立好网络长连接,服务方有相关数据,直接通过长连接通道推送到客户端。其优点是及时,一旦有数据变更,客户端立马能感知到;另外对客户端来说逻辑简单,不需要关心有无数据这些逻辑处理。缺点是不知道客户端的数据消费能力,可能导致数据积压在客户端,来不及处理。
拉模式指的是客户端主动向服务端发出请求,拉取相关数据。其优点是此过程由客户端发起请求,故不存在推模式中数据积压的问题。缺点是可能不够及时,对客户端来说需要考虑数据拉取相关逻辑,何时去拉,拉的频率怎么控制等等。
长轮询:
轮询是说,每隔一定时间,客户端想服务端发起一次请求,服务端有数据就返回数据,没有数据就返回空,然后关闭请求。
长轮询,不同之处是,服务端如果此时没有数据,保持连接。等到有数据返回(相当于一种push),或者超时返回。
所以长轮询Pull的好处就是可以减少无效请求,保证消息的实时性,又不会造成客户端积压。
其他
- 对于一个消息中间件来说,持久化部分的性能直接决定了整个消息中间件的性能。RocketMQ充分利用Linux文件系统内存cache来提高性能
- RocketMq Broker的buffer不会满。原因是RocketMQ没有内存Buffer概念,RocketMQ的队列都是持久化磁盘,数据定期清除。这是RocketMq和其他消息中间件的重要区别。对RocketMQ来说的内存Buffer抽象成一个无限长度的队列,不管有多少数据进来都能装得下,这个无限是有前提的,Broker会定期删除过期的数据。
- 消息堆积。消息堆积的能力是评价一个消息中间件的重要方面。因为使用消息中间件有一部分功能是为了为后端系统挡住数据洪峰。在产生消息堆积时,消息中间件对外的服务能力至关重要。
因为RocketMq的消息都是持久化硬盘的,当消息不能在内存Cache命中时,要不可避免的访问磁盘,会产生大量读IO,读IO的吞吐量直接决定了消息堆积后的访问能力。 - 分布式事务。分布式事务涉及到两阶段提交。分为预提交阶段和commit阶段。在commit阶段需要回去改消息的状态。RocketMq在这里没有使用KV存储来做。而是在commit阶段会拿到消息的offset,然后直接去找消息,修改其状态。这样的好处是设计更简单,速度更快。缺点是会产生过多的数据脏页。
- producer只与master建立连接,consumer同master和slave都建立连接,向谁订阅可以配置。
- Rocketmq的消息的存储是由consume queue和 commitLog 配合完成的
consume queue 消息的逻辑队列,相当于字典的目录用来指定消息在消息的真正的物理文件commitLog上的位置, 每个topic下的每个queue都有一个对应的consumequeue文件。
默认文件地址:${user.home} \store\consumequeue${topicName}${queueId}${fileName}
修改方法:配置文件的
storePathRootDir=/home/haieradmin/mqstore/rocketmqstore
storePathCommitLog=/home/haieradmin/mqstore/rocketmqstore/commitlog
这两个参数。
说到高性能消息中间件,第一个想到的肯定是 LinkedIn 开源的 Kafka ,虽然最初 Kafka 是为日志传输而生,但也非常适合互联网公司消息服务的应用场景,他们不要求数据实时的强一致性(事务),更多是希望达到数据的最终一致性。 RocketMQ 是 MetaQ 的 3.0 版本,而 MetaQ 最初的设计又参考了 Kafka 。MetaQ 1.x 和 MetaQ 2.x 是依赖 ZooKeeper 的,但 RocketMQ (即 MetaQ 3.x )却去掉了 ZooKeeper 依赖,转而采用自己的 NameServer (专门为Rocket设计的轻量级名称服务)。接下来看一下NameSever在RocketMQ中的作用想必大家就清楚了。
一:rocketmq为什么使用nameserver?
RocketMQ 的 Broker 有三种集群部署方式: 1. 单台 Master 部署; 2. 多台 Master部署; 3. 多 Master 多 Slave 部署;采用第 3 种部署方式时, Master 和 Slave 可以采用同步复制和异步复制两种方式。下图是第 3 种部署方式的简单图:
图1.多master多slave部署
下面解读一下它们之间的关系:
1.1.NameServer互相独立,彼此没有通信关系,单台NameServer挂掉,不影响其他NameServer。NameServer不去连接别的机器,不会主动推消息。
1.2.单个broker(Master、Slave)与所有NameServer进行定时注册,以便告知NameServer自己还活着。Broker每隔30秒向所有NameServer发送心跳,心跳包含了自身的topic配置信息。NameServer每隔10秒,扫描所有还存活的broker连接,如果某个连接的最后更新时间与当前时间差值超过2分钟,则断开此连接。此外,NameServer也会断开此broker下所有与slave的连接。同时更新topic与队列的对应关系,但不会通知生产者和消费者。
Broker slave 同步或者异步从Broker master 上拷贝数据。
1.3.consumer随机与一个NameServer建立长连接,如果该NameServer断开,则从NameServer列表中查找下一个进行连接。
consumer主要从NameServer中根据topic查询broker的地址,查到就会缓存到客户端,并向提供topic服务的master、slave建立长连接,且定时向master、slave发送心跳。如果broker宕机,则NameServer会将其剔除,而consumer端的定时任务MQClientInstance.this.updateTopicRouteInfoFromNameServer每30秒执行一次,会将topic对应的broker地址拉取下来,此地址已经为slave地址了,故此时consumer会从slave上消费。 消费者与master和slave都建有连接,在不同场景有不同的消费规则。
1.4.Producer随机与一个NameServer建立长连接,每隔30秒(此处时间可配置)从NameServer获取topic的最新队列情况,这就表示如果某个broker master宕机,producer最多30秒才能感知,在这个期间,发往该broker master的消息将会失败。Producer会向提供topic服务的master建立长连接,且定时向master发送心跳。生产者与所有的master连接,但不能向slave写入。
客户端是先从NameServer寻址的,得到可用Broker的IP和端口信息,然后自己去连接broker。
(ps:我们在设计系统的时候,有一些全局使用的公用信息,可以单独独立一个模块进行专门的管理;各个子模块只需要定时向该模块更新信息即可。)
综上所述,我们可以得出NameServer在RocketMQ中所扮演的角色:1.NameServer 用来保存活跃的 broker 列表,包括 Master 和 Slave 。
2.NameServer 用来保存所有 topic 和该 topic 所有队列的列表。3.NameServer 用来保存所有 broker 的 Filter 列表。
对于RocketMQ 来说,topic 的数据在每个 Master 上是对等的,没有哪个 Master 上有 topic 上的全部数据,所以对于zookeeper的Master 选举功能在Rocket中使用不到。
Broker与slave配对是通过指定相同的brokerName参数来配对,master的brokerId必须为0,slave的brokerId必须大于0,此外一个master下可以挂多个slave,同一个master下的多个slave通过指定不同的brokerId来区分。
二:核心模块
2.1.注册broker
2.2 存放消息
Producer在存放消息时,首先会使用GET_ROUTEINTO_BY_TOPIC获取route信息TopicRouteData。
Producer Group–Producer实例的集合。
Producer实例可以是多机器、但机器多进程、单进程中的多对象。Producer可以发送多个Topic。处理分布式事务时,也需要Producer集群提高可靠性。
2.3 读取消息
Consumer在读取消息时,也会先使用GET_ROUTEINTO_BY_TOPIC获取route信息TopicRouteData。
Consumer Group–Consumer实例的集合。
Consumer 实例可以是多机器、但机器多进程、单进程中的多对象。同一个Group中的实例,在集群模式下,以均摊的方式消费;在广播模式下,每个实例都全部消费。
2.3.1.Push Consumer
Consumer的一种,应用通常向Consumer对象注册一个Listener接口,一旦收到消息,Consumer对象立刻回调Listener接口方法。所以,所谓Push指的是客户端内部的回调机制,并不是与服务端之间的机制。
2.3.2.Pull Consumer
Consumer的一种,应用通常主动调用Consumer从服务端拉消息,consumer 向 broker 发送拉消息请求, PullMessageService 服务通过一个线程将阻塞队列 LinkedBlockingQueue 中的 PullRequest 到 broker 拉取消息,长轮询向broker拉取消息是批量拉取的,默认设置批量的值为pullBatchSize = 32, 可配置。主动权由应用控制,这用的就是短轮询方式了,在不同情况下,与长轮询各有优点。
三:消息
*Message priority
处于一个队列,可用整数来描述每条消息的优先级,在投递前先按优先级排好序,然后令优先级高的消息先投递。RocketMQ没有特意支持消息优先级,它的所有的消息都是持久化,如果按优先级排序,开销会非常大,可以通过变通方式实现类似功能,即不同优先级各对应一个队列,发送消息时根据优先级发送到与之对应的队列中。
*Message order
rocketmq的顺序消息需要满足2点:
1.Producer端保证发送消息有序,且发送到同一个队列。
2.consumer端保证消费同一个队列。
顺序消费的发送的原理:
SendResult sendResult = producer.send(msg, new MessageQueueSelector()
{
@Override
public MessageQueue select(List mqs,Message msg, Object arg)
{
Integer id = (Integer) arg;
int index = id % mqs.size(); // 如果队列数不变,同一个订单号取到的队列是同一个
return mqs.get(index);
}
}, “10001”); // orderID “10001”是传递给回调方法的自定义数据
}
//List mqs 就是从namesrv 获取的所有队列
那么在集群消费时它是如何做到消息的有序性?
1.ConsumeMessageOrderlyService类的start()方法,如果是集群消费,则启动定时任务,定时向broker发送批量锁住当前正在消费的队列集合的消息,具体是consumer端拿到正在消费的队列集合,发送锁住队列的消息至broker,broker端返回锁住成功的队列集合。 consumer收到后,设置是否锁住标志位。
2.ConsumeMessageOrderlyService.ConsumeRequest的run方法是消费消息,这里还有个MessageQueueLock messageQueueLock,维护当前consumer端的本地队列锁。保证当前只有一个线程能够进行消费。
3.拉到消息存入ProcessQueue,然后判断,本地是否获得锁,全局队列是否被锁住,然后从ProcessQueue里取出消息,用MessageListenerOrderly进行消费。 拉到消息后调用ProcessQueue.putMessage(final List msgs) 存入,具体是存入TreeMap msgTreeMap。
然后是调用ProcessQueue.takeMessags(final int batchSize)消费,具体是把msgTreeMap里消费过的消息,转移到TreeMap msgTreeMapTemp。
4.本地消费的事务控制,ConsumeOrderlyStatus.SUCCESS(提交),ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT(挂起一会再消费),在此之前还有一个变量ConsumeOrderlyContext context的setAutoCommit()是否自动提交。
当SUSPEND_CURRENT_QUEUE_A_MOMENT时,autoCommit设置为true或者false没有区别,本质跟消费相反,把消息从msgTreeMapTemp转移回msgTreeMap,等待下次消费。
当SUCCESS时,autoCommit设置为true时比设置为false多做了2个动作,consumeRequest.getProcessQueue().commit()和this.defaultMQPushConsumerImpl.getOffsetStore().updateOffset(consumeRequest.getMessageQueue(), commitOffset, false);
ProcessQueue.commit() :本质是删除msgTreeMapTemp里的消息,msgTreeMapTemp里的消息在上面消费时从msgTreeMap转移过来的。
this.defaultMQPushConsumerImpl.getOffsetStore().updateOffset() :本质是把拉消息的偏移量更新到本地,然后定时更新到broker。
Listener 接口方法:
MessageListenerOrderly ->是有序的
MessageListenerConcurrently ->是无序的
*Message Filter
Broker端过滤-RocketMQ支持根据msgId、key、Header、body进行过滤。根据Message Key查询仅仅返回符合条件的最近64条数据,所以key值尽量唯一,并且有业务区分度。
*发送消息负载均衡
使用Roundbin方式,轮询发送消息,每个队列接收平均的消息量。也可以自定义选择发往哪个队列。

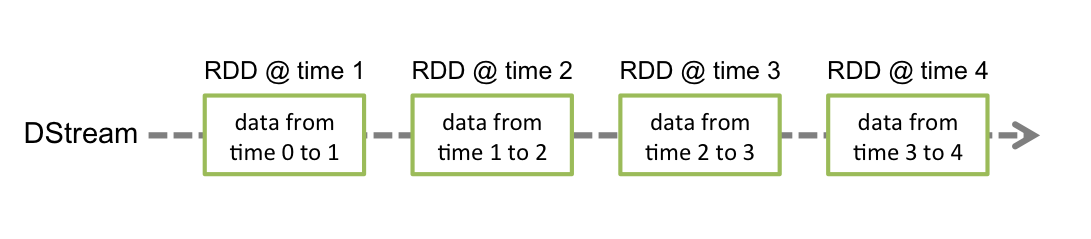
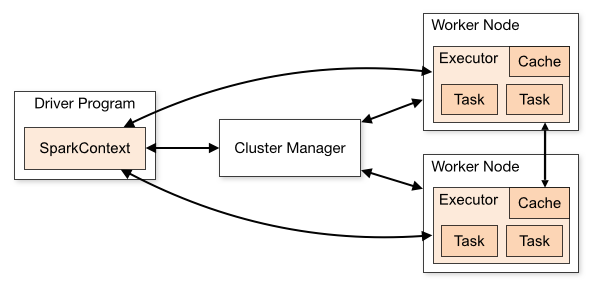 无论是在本地模式、Standalone模式,还是在Mesos或YARN模式下,整个Spark集群的结构都可以用上图抽象表示,只是各个组件的运行环 境不同,导致组件可能是分布式的,或本地的,或单个JVM实例的。如在本地模式,则上图表现为在同一节点上的单个进程之内的多个组件;而在YARN Client模式下,Driver程序是在YARN集群之外的一个节点上提交Spark Application,其他的组件都运行在YARN集群管理的节点上。
无论是在本地模式、Standalone模式,还是在Mesos或YARN模式下,整个Spark集群的结构都可以用上图抽象表示,只是各个组件的运行环 境不同,导致组件可能是分布式的,或本地的,或单个JVM实例的。如在本地模式,则上图表现为在同一节点上的单个进程之内的多个组件;而在YARN Client模式下,Driver程序是在YARN集群之外的一个节点上提交Spark Application,其他的组件都运行在YARN集群管理的节点上。