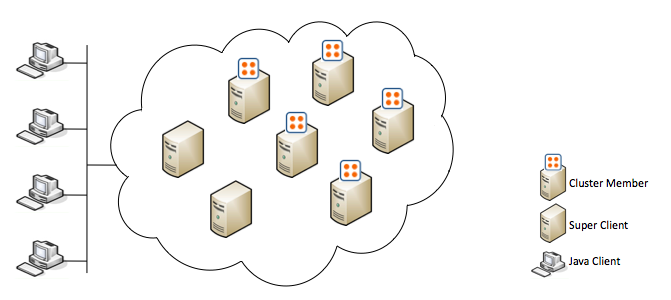
在 入门及使用案例一文介绍了什么是Hazelcast,并展示了一个简单的使用例子。原理大家都懂了,后面的篇章会给兄弟们更多干货。
本篇博文将细说如何配置Hazelcast,听我慢慢给你们侃。
XML基本配置
如果用户没有指定或提供任何配置文件,Hazelcast默认会使用jar包中自带的配置文件——"hazelcast-default.xml"来配置Hazelcast的运行环境。Hazelcast默认采用XML格式作为配置文件,当然也支持其他配置方法,后文会详细说明。我们先看看下面这个简单的配置文件例子。
<hazelcast xsi:schemaLocation="//" xmlns="//" xmlns:xsi="">
<group>
<name>dev</name>
<password>dev-pass</password>
</group>
<management-center enabled="false">http://localhost:8080/mancenter</management-center>
<network>
<port auto-increment="true" port-count="110">7701</port>
<outbound-ports>
<ports>0</ports>
</outbound-ports>
<join>
<multicast enabled="true">
<multicast-group>224.2.2.3</multicast-group>
<multicast-port>54327</multicast-port>
</multicast>
<tcp-ip enabled="false">
<interface>127.0.0.1</interface>
<member-list>
<member>127.0.0.1</member>
</member-list>
</tcp-ip>
</join>
</network>
<map name="demo.config">
<backup-count>1</backup-count>
<time-to-live-seconds>0</time-to-live-seconds>
<max-idle-seconds>0</max-idle-seconds>
<eviction-policy>NONE</eviction-policy>
<max-size policy="PER_NODE">0</max-size>
<eviction-percentage>25</eviction-percentage>
<merge-policy>com.hazelcast.map.merge.LatestUpdateMapMergePolicy
</merge-policy>
</map>
</hazelcast>如果你看到上面的配置内容有点蒙圈,建议你先看看上一篇Hazelcast基础介绍的文章。
前面已经介绍,Hazelcast以分布式的方式实现了Java中的绝大部分数据结构,这些数据结构的数据都以分区表的方式存储,因此可以推断XML配置文件中的<map></map>元素就是用来配置分布式map的相关参数的,这里先不细说每个参数的定义,从字面上看,大概就是配置map的备份副本个数、释放策略、释放比率等等。有了<map></map>当然还有<queue></queue>、<set></set>、<list></list>等针对各种数据结构的配置元素。
<network></network>是非常重要的元素,他指定了Hazelcast的网络环境。上面这个简短的配置文件例子指定网络使用5700到5800端口,使用组播协议来进行组网。
我们在创建Hazelcast集群时可以引入配置文件。下面的代码例子展示了如何引入自定义的配置文件。(文中所有例子的源码均在github:https://github.com/chkui/hazelcast-demo。使用“git clone”到本地用maven就可以运行。)
/** https://github.com/chkui/hazelcast-demo/blob/master/src/main/java/org/palm/hazelcast/config/HazelcastConfigSimple.java */
public class HazelcastConfigSimple {
public static void main(String[] args) {
// 从classpath加载配置文件
Config config = new ClasspathXmlConfig("xmlconfig/simple-config.xml");
// 获取网络配置
NetworkConfig netConfig = config.getNetworkConfig();
// 获取用户定义的map配置
MapConfig mapConfigXml = config.getMapConfig("demo.config");
// 获取系统默认的map配置
MapConfig mapConfigDefault = config.getMapConfig("default");
// 输出集群监听的起始端口号
System.out.println("Current port:" + netConfig.getPort());
// 输出监听端口的累加号
System.out.println("Current port count:" + netConfig.getPortCount());
// 输出自定义map的备份副本个数
System.out.println("Config map backup count:" + mapConfigXml.getBackupCount());
// 输出默认map的备份副本个数
System.out.println("Default map backup count:" + mapConfigDefault.getBackupCount());
// 测试创建Hazelcast实例并读写测试数据
HazelcastInstance instance1 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance instance2 = Hazelcast.newHazelcastInstance(config);
Map<Integer, String> defaultMap1 = instance1.getMap("defaultMap");
defaultMap1.put(1, "testMap");
Map<Integer, String> configMap1 = instance1.getMap("configMap");
configMap1.put(1, "configMap");
Map<Integer, String> testMap2 = instance2.getMap("defaultMap");
System.out.println("Default map value:" + testMap2.get(1));
Map<Integer, String> configMap2 = instance2.getMap("configMap");
System.out.println("Config map value:" + configMap2.get(1));
}
}上面的例子使用ClasspathXmlConfig来生成Config实例,它表示从classpath路径来加载配置文件。 从上面的代码例子还可以看出,我们能够从Config实例中读取各种各样的配置信息,例如网络配置、Map配置等等。既然能get,当然也可以set,在Hazelcast没有初始化之前,都可以随意设置各种配置属性。下面的例子展示了如何在代码中修改Hazelcast的配置参数。
/** https://github.com/chkui/hazelcast-demo/blob/master/src/main/java/org/palm/hazelcast/config/HazelcastConfigRuntimeModify.java */
public class HazelcastConfigRuntimeModify {
public static void main(String[] args) {
// 创建默认config对象
Config config = new Config();
// 获取network元素<network></network>
NetworkConfig netConfig = config.getNetworkConfig();
System.out.println("Default port:" + netConfig.getPort());
// 设置组网起始监听端口
netConfig.setPort(9701);
System.out.println("Customer port:" + netConfig.getPort());
// 获取join元素<join></join>
JoinConfig joinConfig = netConfig.getJoin();
// 获取multicast元素<multicast></multicast>
MulticastConfig multicastConfig = joinConfig.getMulticastConfig();
// 输出组播协议端口
System.out.println(multicastConfig.getMulticastPort());
// 禁用multicast协议
multicastConfig.setEnabled(false);
// 初始化Hazelcast
Hazelcast.newHazelcastInstance(config);
}
}上面的例子中,我们首先从Config中获取了NetworkConfig实例,然后调用NetworkConfig::setPort方法将集群的监听起始端口设置为9701(默认为5701)。运行以上代码会输出以下片段内容:
class:com.hazelcast.instance.DefaultAddressPicker
info: [LOCAL] [dev] [3.6.3] Picked Address[192.168.1.100]:9701, using socket ServerSocket[addr=/0:0:0:0:0:0:0:0,localport=9701], bind any local is true
XML配置与源码配置
看到这兄弟可能要问了:“又是XML配置,又是代码级配置的,他两到底啥关系呢?”。其实他两是相辅相成的,既可以只用XML配置、也可以只在代码中进行配置、还可以两者混合使用——先加载XML配置再对其进行修改以满足各种需要。
一个简单的例子
我们先看一个简单的例子,再深入了解Hazelcast实现XML到Java对象映射的原理。
<!-- XML配置 -->
<hazelcast>
<network>
<join>
<multicast enabled="true">
<multicast-group>224.2.2.3</multicast-group>
<multicast-port>54327</multicast-port>
</multicast>
</join>
</network>
</hazelcast>// 代码读取数据
Config config = new Config();
NetworkConfig networkConfig = config.getNetworkConfig();
JoinConfig joinConfig = networkConfig .getJoin();
MulticastConfig multicastConfig = joinConfig.getMulticastConfig();
int multicastPort = multicastConfig.getMulticastPort();在上面这个XML配置和代码的例子中,<hazelcast></hazelcast>对应Java中Config对象,而<hazelcast>中包含<network></network>,因此Config::getNetwork方法可以获取NetworkConfig对象的实例。继续往下,<network>中包含<join></join>,因此NetworkConfig::getJoin可以得到JoinConfig。因为<join>包含<multicast></multicast>,所以JoinConfig::getMulticastConfig可以得到MulticastConfig。
看到这里应该都明白了吧:就是每个XML元素对应一个Java实体或数据,只要按照XML配置文件的树形关系来调用get或set,就可以在源码中获取和设置所有配置数据。
XML和源码配置的映射关系
友情提示:如果仅仅是想了解如何使用Hazelcast,建议直接跳过这一段。对XML定义、DTD、XSD不了解的话看多了反而容易混乱。
前文已经提到Hazelcast的配置文件已经预定义了所有要使用的 参数(对应XML的Element和Attribuet),定义文件是hazelcast-<version>.jar包中的hazelcast-3.*.xsd(目前是3.6版本)。XSD文件中所有 类型(XSD:Type)不为 预定义类型(xs:boolean、xs:unsignedInt 等)的 元素(XSD:Element)映射到Java中都对应一个 实体(Entity或Pojo)。如果 元素 中还包含 类型 不为预定义类型的 元素,则对应到Java数据结构时 实体 中还包含另外一个 实体。若XSD文件中定义的 元素类型 为 预定义类型,则对应一个Java基本数据值(int、String等)。
例如下面这些XSD文件片段:
<xs:element name="network" type="network" minOccurs="0" maxOccurs="1"/>
<xs:element name="join" type="join" minOccurs="0" maxOccurs="1"/>
<xs:element name="multicast" type="multicast" minOccurs="0"/>
<xs:element name="multicast-port" type="xs:unsignedShort" minOccurs="0" maxOccurs="1" default="54327"><network></network>元素在xsd文件中定义的类型为network,因此他是一个名为NetworkConfig的实体。XML文件中在<network>元素内还有一个<join></join>元素,<join>元素的type为join,因此调用NetworkConfig::getJoin方法可以得到一个JoinConfig实例。以此类推,<join>内的<multicast></multicast>元素也是一个名为MulticastConfig的实体,而<multicast>中的<multicast-port></multicast-port>对应一个Java的基本数据值——int,因为它在XSD中的类型为xs:unsignedShort。
如果使用的XML配置文件中出现了XSD文件中没有定义的元素和属性,在解析过程中会抛出meaningful异常。
Hazelcast配置文件详解
前面通过几个例子介绍了Hazelcast如何配置,后面的篇幅将会逐一介绍Hazelcast所有配置细节及其参数定义。如果某位仁兄现在已经需要将Hazelcast引入到现在的项目中,建议您仔细阅读。
加载配置文件
当调用Hazelcast.newHazelcastInstance()或Hazelcast.newHazelcastInstance(null)时,Hazelcast会从指定的路径加载XML配置文件或者加载默认配置文件。执行过程如下。
首先,可以通过系统配置参数(system property)指定XML配置文件的加载路径。Hazelcast将在创建实例时检查是否设置了"hazelcast.config"这个启动参数并引用。可以通过Jvm 参数或 System参数来指定它:
java -Dhazelcast.config=/user/my_hazelcast_config.xml ....或
// Java
System.setProperty( "hazelcast.config", "/user/my_hazelcast_config.xml" );其次,如果没有设置这个参数或者指定路径的文件不存在,Hazelcast会搜寻当前classpath路径检查是否存在一个名为“hazelcast.xml”,有则使用。
最后,如果通过以上2个步骤都没有加载到配置文件,则使用jar包中的“hazelcast-default.xml”。
在编码中加载配置文件
除了上面指定系统参数的方法,还可以通过编码实现加载配置文件。Hazelcast提供了多种初始化配置文件的方法,主要有:ClasspathXmlConfig、FileSystemXmlConfig、UrlXmlConfig、InMemoryXmlConfig、XmlConfigBuilder。
- ClasspathXmlConfig:从classpath路径加载配置文件。通常情况下,除了Java的运行环境路径,classpath的根目录可以认为是classes文件夹。因此如果一个文件存放于....../target/classes/xmlconfig/simple-config.xml。那么Config cfg = new ClasspathXmlConfig("xmlconfig/simple-config.xml")即可加载该配置文件。
- FileSystemXmlConfig:从文件系统加载配置文件。文件系统是指从操作系统的文件路径加载文件,因此如果文件存放在 linux:/user/local/hazelcast/hazelcast.xml 或 windows:D:\local\hazelcast\hazelcast.xml。那么使用new FileSystemXmlConfig("/user/local/hazelcast/hazelcast.xml") 或new FileSystemXmlConfig("D:\\local\\hazelcast\\hazelcast.xml") 即可获取配置文件。
- UrlXmlConfig:从网络地址获取配置文件。
- InMemoryXmlConfig:从内存中的xml字符串生成配置文件。
- XmlConfigBuilder:从InputStream流中读取配置文件。使用Config cfg = new XmlConfigBuilder(inputStream).build()可以创建一个Config实例。
得到Config实例之后使用 HazelcastInstance hazelcast = Hazelcast.newHazelcastInstance(config)可以创建HazelcastInstance实例。
在Config中使用Config::setInstanceName方法可以设置实例名称。此后使用这个名称可以获取同一个HazelcastInstance 实例。例如:
//Java
// 创建配置
Config cfg = new XmlConfigBuilder(inputStream).build();
// 设置实例名称
config.setInstanceName("my-instance");
// 创建Hazelcast实例
Hazelcast.newHazelcastInstance(cfg);
// 获取已创建的实例
Hazelcast.getHazelcastInstanceByName("my-instance");在配置文件中使用通配符
在XML配置文件中,可以使用通配符*来匹配某些元素的名称。例如像下面这样配置一个分布式Map的名称:
<map name="map.*">
...
</map>在使用时,下面的方法都是获得同一个Map。
Map map1 = hazelcastInstance.getMap("map.1");
Map map2 = hazelcastInstance.getMap("map.2");
Map map3 = hazelcastInstance.getMap("map.3");在配置文件中使用变量
Hazelcast提供了使用变量来配置XML中元素值的方法,通过在配置文件中使用${}来指定变量要替换的参数。
首先,可以通过系统参数来设置Hazelcast参数。例如像下面这样设置变量:
-Dgroup.name=dev
-Dgroup.password=somepassword或
System.setProperty( "group.name", "demo" );
System.setProperty( "group.password", "passwd" );可以在XML配置文件中可以像下面这样设置${}:
<hazelcast>
<group>
<name>${group.name}</name>
<password>${group.password}</password>
</group>
</hazelcast>在创建配置文件时,${}会被变量替换。
其次,可以通过XML中的<properties></properties>元素配置参数。如下:
<hazelcast>
<properties>
<property name="group.name">dev</property>
<property name="group.passwd">devpasswd</property>
</properties>
<group>
<name>${group.name}</name>
<password>${group.passwd}</password>
</group>
</hazelcast>引入配置文件后,会将properties中的变量替换到对应的${}中。
最后,还可以通过标准的properties文件来配置参数。如下面示例代码:
/** https://github.com/chkui/hazelcast-demo/blob/master/src/main/java/org/palm/hazelcast/config/HazelcastConfigVariable.java */
public class HazelcastConfigVariable {
// XML配置文件存放路径
final static String DEF_CONFIG_FILE = "xmlconfig/variable-config.xml";
// properties文件路径
final static String DEF_PROPERTIES_FILE = "properties/variable-config.properties";
public static void main(String[] args) {
try {
// 获取配置文件磁盘路径
final String path = Thread.currentThread().getContextClassLoader().getResource("").toString() + DEF_CONFIG_FILE;
// 构建XML配置
XmlConfigBuilder builder = new XmlConfigBuilder(path);
// 设置properties
builder.setProperties(getProperties());
// 创建Config,此时会替换${}
Config config = builder.build();
// 输出Config参数
System.out.println(config.getGroupConfig().getName());
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
// get Properties
private static Properties getProperties() {
Properties p = null;
try (InputStream in = Thread.currentThread().getContextClassLoader().getResourceAsStream(DEF_PROPERTIES_FILE)) {
if (null != in) {
p = new Properties();
p.load(in);
}
} catch (Exception e) {
e.printStackTrace();
System.exit(0);
}
return p;
}
}代码对应的XML配置文件:
<!-- https://github.com/chkui/hazelcast-demo/blob/master/src/main/resources/xmlconfig/variable-config.xml -->
<hazelcast>
<group>
<name>${group.name}</name>
<password>${group.password}</password>
</group>
<network>
<port auto-increment="true" port-count="100">5701</port>
<join>
<multicast enabled="true">
<multicast-group>224.2.2.3</multicast-group>
<multicast-port>54327</multicast-port>
</multicast>
</join>
</network>
</hazelcast>对应properties文件:
#https://github.com/chkui/hazelcast-demo/blob/master/src/main/resources/properties/variable-config.properties
group.name=demo
group.password=demopasswd上面的代码先创建了一个XmlConfigBuilder实例,然后调用XmlConfigBuilder::setProperties方法设置Properties到 XmlConfigBuilder中。在build时,会用Properties定义的变量替换XML中对应的${}参数。通过使用properties来控制配置参数,我们可以使用更多的工具来管理Hazelcast配置,例如使用Maven的<resources>元素管理properties。
结构化配置
和spring的配置文件一样,Hazelcast的XML配置文件也可以通过<import>元素来整合多个配置文件。例如有下面2份配置文件。
group-config.xml :
<hazelcast>
<group>
<name>dev</name>
<password>dev-pass</password>
</group>
</hazelcast>network-config.xml:
<hazelcast>
<network>
<port auto-increment="true" port-count="100">5701</port>
<join>
<multicast enabled="true">
<multicast-group>224.2.2.3</multicast-group>
<multicast-port>54327</multicast-port>
</multicast>
</join>
</network>
</hazelcast>然后我们可以像下面这样把2份配置整合在一起。
<hazelcast>
<import resource="group-config.xml"/>
<import resource="network-config.xml"/>
</hazelcast><import>元素同样支持参数:
<hazelcast>
<import resource="${param1}-group-config.xml"/>
<import resource="${param2}-network-config.xml"/>
</hazelcast>有了结构化配置的方法,可以把一份大文档,划分成很多相关部分去维护。