Cassandra是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,集GoogleBigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身Facebook于2008将 Cassandra 开源,此后,由于Cassandra良好的可扩放性,被Digg、Twitter等知名Web 2.0网站所采纳,成为了一种流行的分布式结构化数据存储方案。
Cassandra是一个混合型的非关系的数据库,类似于Google的BigTable。其主要功能比Dynamo (分布式的Key-Value存储系统)更丰富,但支持度却不如文档存储MongoDB(介于关系数据库和非关系数据库之间的开源产品,是非关系数据库当中功能最丰富,最像关系数据库的。支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型)。Cassandra最初由Facebook开发,后转变成了开源项目。它是一个网络社交云计算方面理想的数据库。以Amazon专有的完全分布式的Dynamo为基础,结合了Google BigTable基于列族(Column Family)的数据模型。P2P去中心化的存储。很多方面都可以称之为Dynamo 2.0
网站地址:http://cassandra.apache.org/
以下资料来源:http://asyty.iteye.com/blog/1202072
一、Cassandra框架

图1 Cassandra
Cassandra是社交网络理想的数据库,适合于实时事务处理和提供交互型数据。以Amazon的完全分布式的Dynamo为基础,结合了Google BigTable基于列族(Column Family)的数据模型,P2P去中心化的存储,目前twitter和digg中都有使用。
在CAP特性上,HBase选择了CP,Cassandra更倾向于AP,而在一致性上有所减弱。
Cassandra的类Dynamo特性有以下几点:
l 对称的,P2P架构
n 无特殊节点,无单点故障
l 基于Gossip的分布式管理
l 通过分布式hash表放置数据
n 可插拔的分区
n 可插拔的拓扑发现
n 可配置的放置策略
l 可配置的,最终一致性
类BigTable特性:
l 列族数据模型
n 可配置,2级maps,Super Colum Family
l SSTable磁盘存储
n Append-only commit log
n Mentable (buffer and sort)
n 不可修改的SSTable文件
l 集成Hadoop
二、 Cassandra数据模型
Colum / Colum Family, SuperColum / SuperColum Family
Column是数据增量最底层(也就是最小)的部分。它是一个包含名称(name)、值(value)和时间戳(timestamp)的三重元组。
下面是一个用JSON格式表示的column:
{ // 这是一个Column
name: "emailAddress",
value: "arin@example.com",
timestamp: 123456789
}
需要注意的是,name和value都是二进制的(技术上指byte[]),并且可以是任意长度。
与HBase相比,除了Colum/Colum Family外,Cassandra还支持SuperColum/SuperColum Family。
SuperColum与Colum的区别就是,标准Column的value是一个“字符串”,而 SuperColumn的value是一个包含多个Column的map,另一个细微的差别是:SuperColumn没有时间戳。
{ // 这是一个SuperColumn
name: "homeAddress",
// 无限数量的Column
value: {
street: {name: "street", value: "1234 x street", timestamp: 123456789},
city: {name: "city", value: "san francisco", timestamp: 123456789},
zip: {name: "zip", value: "94107", timestamp: 123456789},
}
}
Column Family(CF)是某个特定Key的Colum集合,是一个行结构类型,每个CF物理上被存放在单独的文件中。从概念上看,CF像数据库中的Table。
SuperColum Family概念上和Column Family(CF)相似,只不过它是Super Colum的集合。
Colum排序
不同于数据库可以通过Order by定义排序规则,Cassandra取出的数据顺序是总是一定的,数据保存时已经按照定义的规则存放,所以取出来的顺序已经确定了。另外,Cassandra按照column name而不是column value来进行排序。
Cassandra可以通过Colum Family的CompareWith属性配置Colume值的排序,在SuperColum中,则是通过SuperColum Family的CompareSubcolumnsWith属性配置Colum的排序。
Cassandra提供了以下一些选:BytesType,UTF8Type,LexicalUUIDType,TimeUUIDType,AsciiType, Column name识别成为不同的类型,以此来达到灵活排序的目的。
三、分区策略
Token,Partitioner
Cassandra中,Token是用来分区数据的关键。每个节点都有一个第一无二的Token,表明该节点分配的数据范围。节点的Token形成一个Token环。例如使用一致性HASH进行分区时,键值对将根据一致性Hash值来判断数据应当属于哪个Token。
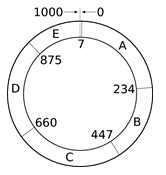
Token Ring
分区策略的不同,Token的类型和设置原则也有所不同。 Cassandra (0.6版本)本身支持三种分区策略:
RandomPartitioner:随机分区是一种hash分区策略,使用的Token是大整数型(BigInteger),范围为0~2^127,Cassandra采用了MD5作为hash函数,其结果是128位的整数值(其中一位是符号位,Token取绝对值为结果)。因此极端情况下,一个采用随机分区策略的Cassandra集群的节点可以达到2^127+1个节点。采用随机分区策略的集群无法支持针对Key的范围查询。
OrderPreservingPartitioner:如果要支持针对Key的范围查询,那么可以选择这种有序分区策略。该策略采用的是字符串类型的Token。每个节点的具体选择需要根据Key的情况来确定。如果没有指定InitialToken,则系统会使用一个长度为16的随机字符串作为Token,字符串包含大小写字符和数字。
CollatingOrderPreservingPartitioner:和OrderPreservingPartitioner一样是有序分区策略。只是排序的方式不一样,采用的是字节型Token,支持设置不同语言环境的排序方式,代码中默认是en_US。
分区策略和每个节点的Token(Initial Token)都可以在storage-conf.xml配置文件中设置。
bloom-filter, HASH
Bloom Filter是一种空间效率很高的随机数据结构,本质上就是利用一个位数组来表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有误差的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合,而在能容忍低错误率的场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
原理:位数组 + K个独立hash(y)函数。将位数组中hash函数对应的值的位置设为1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是完全正确的。
在Cassandra中,每个键值对使用1Byte的位数组来实现bloom-filter。
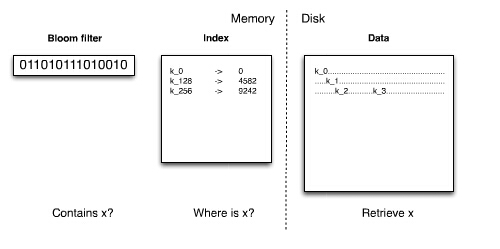
Bloom Filter
四、副本存储
Cassandra不像HBase是基于HDFS的分布式存储,它的数据是存在每个节点的本地文件系统中。
Cassandra有三种副本配置策略:
1) SimpleStrategy (RackUnawareStrategy):
副本不考虑机架的因素,按照Token放置在连续下几个节点。如图3所示,假如副本数为3,属于A节点的数据在B.C两个节点中也放置副本。
2) OldNetworkTopologyStrategy (RackAwareStrategy):
考虑机架的因素,除了基本的数据外,先找一个处于不同数据中心的点放置一个副本,其余N-2个副本放置在同一数据中心的不同机架中。
3) NetworkTopologyStrategy (DatacenterShardStrategy):
将M个副本放置到其他的数据中心,将N-M-1的副本放置在同一数据中心的不同机架中。
五、网络嗅探
网络嗅探主要用来计算不同host的相对距离,进而告诉Cassandra网络拓扑结构,以便更高效地对用户请求进行路由。主要有三种配置策略:
1) org.apache.cassandra.locator.SimpleSnitch:
将不同host逻辑上的距离(Cassandra Ring)作为他们之间的相对距离。
2) org.apache.cassandra.locator.RackInferringSnitch:
相对距离是由rack和data center决定的,分别对应ip的第3和第2个八位组。即,如果两个节点的ip的前3个八位组相同,则认为它们在同一个rack(同一个rack中不同节点,距离相同);如果两个节点的ip的前两个八位组相同,则认为它们在同一个数据中心(同一个data center中不同节点,距离相同)。
3) org.apache.cassandra.locator.PropertyFileSnitch:
相对距离是由rack和data center决定的,且它们是在配置文件cassandra-topology.properties中设置的。
六、一致性
在一致性上,Cassandra采用了最终一致性,可以根据具体情况来选择一个最佳的折衷,来满足特定操作的需求。Cassandra可以让用户指定读/插入/删除操作的一致性级别,一致性级别有多种,如图5所示。
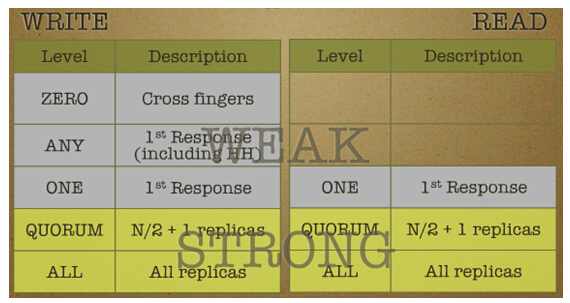
图5 Cassandra一致性级别
注:一致性级别是由副本数决定,而不是集群的节点数目决定。
Quorum NRW
- N: 复制的节点数量,即副本数
- R: 成功读操作的最小节点数
- W: 成功写操作的最小节点数
Quorum协议中,R 代表一次成功的读取操作中最小参与节点数量,W 代表一次成功的写操作中最小参与节点数量。R + W>N ,则会产生类似quorum 的效果。该模型中的读(写)延迟由最慢的 R(W)复制决定,为得到比较小的延迟,R和W有的时候的和比N小。
Quorum协议中,只需W + R > N,就可以保证强一致性。因为读取数据的节点和被同步写入的节点是有重叠的。在一个RDBMS的复制模型中(Master/salve),假如N=2,那么W=2,R=1此时是一种强一致性,但是这样造成的问题就是可用性的减低,因为要想写操作成功,必须要等 2个节点的写操作都完成以后才可以。
在分布式系统中,一般都要有容错性,因此N一般大于3的,此时根据CAP理论,我们就需要在一致性和分区容错性之间做一平衡,如果要高的一致性,那么就配置N=W,R=1,这个时候可用性就会大大降低。如果想要高的可用性,那么此时就需要放松一致性的要求,此时可以配置W=1,这样使得写操作延迟最低,同时通过异步的机制更新剩余的N-W个节点。
当存储系统保证最终一致性时,存储系统的配置一般是W+R<=N,此时读取和写入操作是不重叠的,不一致性的窗口就依赖于存储系统的异步实现方式,不一致性的窗口大小也就等于从更新开始到所有的节点都异步更新完成之间的时间。
一般来说,Quorum中比较典型的NRW为(3,2,2)。
维护最终一致性
Cassandra 通过4个技术来维护数据的最终一致性,分别为逆熵(Anti-Entropy),读修复(Read Repair),提示移交(Hinted Handoff)和分布式删除。
1) 逆熵
这是一种备份之间的同步机制。节点之间定期互相检查数据对象的一致性,这里采用的检查不一致的方法是 Merkle Tree;
2) 读修复
客户端读取某个对象的时候,触发对该对象的一致性检查:
读取Key A的数据时,系统会读取Key A的所有数据副本,如果发现有不一致,则进行一致性修复。
如果读一致性要求为ONE,会立即返回离客户端最近的一份数据副本。然后会在后台执行Read Repair。这意味着第一次读取到的数据可能不是最新的数据;如果读一致性要求为QUORUM,则会在读取超过半数的一致性的副本后返回一份副本给客户端,剩余节点的一致性检查和修复则在后台执行;如果读一致性要求高(ALL),则只有Read Repair完成后才能返回一致性的一份数据副本给客户端。可见,该机制有利于减少最终一致的时间窗口。
3) 提示移交
对写操作,如果其中一个目标节点不在线,先将该对象中继到另一个节点上,中继节点等目标节点上线再把对象给它:
Key A按照规则首要写入节点为N1,然后复制到N2。假如N1宕机,如果写入N2能满足ConsistencyLevel要求,则Key A对应的RowMutation将封装一个带hint信息的头部(包含了目标为N1的信息),然后随机写入一个节点N3,此副本不可读。同时正常复制一份数据到N2,此副本可以提供读。如果写N2不满足写一致性要求,则写会失败。 等到N1恢复后,原本应该写入N1的带hint头的信息将重新写回N1。
4) 分布式删除
单机删除非常简单,只需要把数据直接从磁盘上去掉即可,而对于分布式,则不同,分布式删除的难点在于:如果某对象的一个备份节点 A 当前不在线,而其他备份节点删除了该对象,那么等 A 再次上线时,它并不知道该数据已被删除,所以会尝试恢复其他备份节点上的这个对象,这使得删除操作无效。Cassandra 的解决方案是:本地并不立即删除一个数据对象,而是给该对象标记一个hint,定期对标记了hint的对象进行垃圾回收。在垃圾回收之前,hint一直存在,这使得其他节点可以有机会由其他几个一致性保证机制得到这个hint。Cassandra 通过将删除操作转化为一个插入操作,巧妙地解决了这个问题。
七、存储机制
Cassandra的存储机制借鉴了Bigtable的设计,采用Memtable和SSTable的方式。
CommitLog
和HBase一样,Cassandra在写数据之前,也需要先记录日志,称之为Commit Log,然后数据才会写入到Column Family对应的MemTable中,且MemTable中的数据是按照key排序好的。SSTable一旦完成写入,就不可变更,只能读取。下一次Memtable需要刷新到一个新的SSTable文件中。所以对于Cassandra来说,可以认为只有顺序写,没有随机写操作。
MenTable
MemTable是一种内存结构,当数据量达到块大小时,将批量flush到磁盘上,存储为SSTable。这种机制,相当于缓存写回机制(Write-back Cache),优势在于将随机IO写变成顺序IO写,降低大量的写操作对于存储系统的压力。所以我们可以认为Cassandra中只有顺序写操作,没有随机写操作。
SSTable
SSTable是Read Only的,且一般情况下,一个CF会对应多个SSTable,当用户检索数据时,Cassandra使用了Bloom Filter,即通过多个hash函数将key映射到一个位图中,来快速判断这个key属于哪个SSTable。
为了减少大量SSTable带来的开销,Cassandra会定期进行compaction,简单的说,compaction就是将同一个CF的多个SSTable合并成一个SSTable。在Cassandra中,compaction主要完成的任务是:
1) 垃圾回收: cassandra并不直接删除数据,因此磁盘空间会消耗得越来越多,compaction 会把标记为删除的数据真正删除;
2) 合并SSTable:compaction 将多个 SSTable 合并为一个(合并的文件包括索引文件,数据文件,bloom filter文件),以提高读操作的效率;
3) 生成 MerkleTree:在合并的过程中会生成关于这个 CF 中数据的 MerkleTree,用于与其他存储节点对比以及修复数据。
详细存储数据结构参考 http://www.ibm.com/developerworks/cn/opensource/os-cn-cassandraxu2
附
单体、模块化
Cassandra和HBase的一个重要区别是, Cassandra在每个节点是是一个单 Java 进程,而完整的HBase 解决方案却由不同部分组成:有数据库进程本身,它可能会运行在多个模式;一个配置好的 hadoop HDFS 分布式文件系统,以及一个 Zookeeper 系统来协调不同的 HBase 进程。
同类文章:
 它 持久化的策略也很简单,就是首先将用户提交的数据所在的对象 RowMutation 序列化成 byte 数组,然后把这个对象和 byte 数组传给 LogRecordAdder 对象,由 LogRecordAdder 对象调用 CommitLogSegment 的 write 方法去完成写操作,这个 write 方法的代码如下:
它 持久化的策略也很简单,就是首先将用户提交的数据所在的对象 RowMutation 序列化成 byte 数组,然后把这个对象和 byte 数组传给 LogRecordAdder 对象,由 LogRecordAdder 对象调用 CommitLogSegment 的 write 方法去完成写操作,这个 write 方法的代码如下: 上图中每个不同的 columnFamily 的 id 都包含在 header 中,这样做的目的是更容易的判断那些数据没有被序列化。
上图中每个不同的 columnFamily 的 id 都包含在 header 中,这样做的目的是更容易的判断那些数据没有被序列化。
 Memtable 中的数据会根据配置文件中的相应配置参数刷到本地磁盘中。这些参数在上一篇中已经做了详细说明。
Memtable 中的数据会根据配置文件中的相应配置参数刷到本地磁盘中。这些参数在上一篇中已经做了详细说明。
 Memtable 的条件满足后,它会创建一个 SSTableWriter 对象,然后取出 Memtable 中所有的 <DecoratedKey, ColumnFamily> 集合,将 ColumnFamily 对象的序列化结构写到 DataOutputBuffer 中。接下去 SSTableWriter 根据 DecoratedKey 和 DataOutputBuffer 分别写到 Date、Index 和 Filter 三个文件中。
Memtable 的条件满足后,它会创建一个 SSTableWriter 对象,然后取出 Memtable 中所有的 <DecoratedKey, ColumnFamily> 集合,将 ColumnFamily 对象的序列化结构写到 DataOutputBuffer 中。接下去 SSTableWriter 根据 DecoratedKey 和 DataOutputBuffer 分别写到 Date、Index 和 Filter 三个文件中。 Data 文件就是按照上述 byte 数组来组织文件的,数据被写到 Data 文件中是接着就会往 Index 文件中写,Index 中到底写什么数据呢?
Data 文件就是按照上述 byte 数组来组织文件的,数据被写到 Data 文件中是接着就会往 Index 文件中写,Index 中到底写什么数据呢? Index 文件实际上就是 Key 的一个索引文件,目前只对 Key 做索引,对 super column 和 column 都没有建索引,所以要匹配 column 相对来说要比 Key 更慢。
Index 文件实际上就是 Key 的一个索引文件,目前只对 Key 做索引,对 super column 和 column 都没有建索引,所以要匹配 column 相对来说要比 Key 更慢。 BloomFilter 对象实际上对应一个 Hash 算法,这个算法能够快速的判断给定的某个 Key 在不在当前这个 SSTable 中,而且每个 SSTable 对应的 BloomFilter 对象都在内存中,Filter 文件指示 BloomFilter 持久化的一个副本。三个文件对应的数据格式可以用下图来清楚的表示:
BloomFilter 对象实际上对应一个 Hash 算法,这个算法能够快速的判断给定的某个 Key 在不在当前这个 SSTable 中,而且每个 SSTable 对应的 BloomFilter 对象都在内存中,Filter 文件指示 BloomFilter 持久化的一个副本。三个文件对应的数据格式可以用下图来清楚的表示:
 大慨的写入逻辑是这样的:
大慨的写入逻辑是这样的:
 根 据上面的类图读取的逻辑是,CassandraServer 创建 ReadCommand 对象,这个对象保存了用户要获取记录的所有必须指定的条件。然后交给 weakReadLocalCallable 这个线程去到 ColumnFamilyStore 对象中去搜索数据,包括 Memtable 和 SSTable。将找到的数据组装成 Row 返回,这样一个查询过程就结束了。这个查询逻辑可以用下面的时序图来表示:
根 据上面的类图读取的逻辑是,CassandraServer 创建 ReadCommand 对象,这个对象保存了用户要获取记录的所有必须指定的条件。然后交给 weakReadLocalCallable 这个线程去到 ColumnFamilyStore 对象中去搜索数据,包括 Memtable 和 SSTable。将找到的数据组装成 Row 返回,这样一个查询过程就结束了。这个查询逻辑可以用下面的时序图来表示: 在 上图中还一个地方要说明的是,取得 key 对应的 ColumnFamily 要至少在三个地方查询,第一个就是 Memtable 中,第二个是 MemtablesPendingFlush,这个是将 Memtable 转化为 SSTable 之前的一个临时 Memtable。第三个是 SSTable。在 SSTable 中查询最为复杂,它首先将要查询的 key 与每个 SSTable 所对应的 Filter 做比较,这个 Filter 保存了所有这个 SSTable 文件中含有的所有 key 的 Hash 值,这个 Hsah 算法能快速判断指定的 key 在不在这个 SSTable 中,这个 Filter 的值在全部保存在内存中,这样能快速判断要查询的 key 在那个 SSTable 中。接下去就要在 SSTable 所对应的 Index 中查询 key 所对应的位置,从前面的 Index 文件的存储结构知道,Index 中保存了具体数据在 Data 文件中的 Offset。,拿到这个 Offset 后就可以直接到 Data 文件中取出相应的长度的字节数据,反序列化就可以达到目标的 ColumnFamily。由于 Cassandra 的存储方式,同一个 key 所对应的值可能存在于多个 SSTable 中,所以直到查找完所有的 SSTable 文件后再与前面的两个 Memtable 查找出来的结果合并,最终才是要查询的值。
在 上图中还一个地方要说明的是,取得 key 对应的 ColumnFamily 要至少在三个地方查询,第一个就是 Memtable 中,第二个是 MemtablesPendingFlush,这个是将 Memtable 转化为 SSTable 之前的一个临时 Memtable。第三个是 SSTable。在 SSTable 中查询最为复杂,它首先将要查询的 key 与每个 SSTable 所对应的 Filter 做比较,这个 Filter 保存了所有这个 SSTable 文件中含有的所有 key 的 Hash 值,这个 Hsah 算法能快速判断指定的 key 在不在这个 SSTable 中,这个 Filter 的值在全部保存在内存中,这样能快速判断要查询的 key 在那个 SSTable 中。接下去就要在 SSTable 所对应的 Index 中查询 key 所对应的位置,从前面的 Index 文件的存储结构知道,Index 中保存了具体数据在 Data 文件中的 Offset。,拿到这个 Offset 后就可以直接到 Data 文件中取出相应的长度的字节数据,反序列化就可以达到目标的 ColumnFamily。由于 Cassandra 的存储方式,同一个 key 所对应的值可能存在于多个 SSTable 中,所以直到查找完所有的 SSTable 文件后再与前面的两个 Memtable 查找出来的结果合并,最终才是要查询的值。



 创建每个 Table 的实例
创建每个 Table 的实例 一 个 Keyspace 对应一个 Table,一个 Table 持有多个 ColumnFamilyStore,而一个 ColumnFamily 对应一个 ColumnFamilyStore。Table 并没有直接持有 ColumnFamily 的引用而是持有 ColumnFamilyStore,这是因为 ColumnFamilyStore 类中不仅定义了对 ColumnFamily 的各种操作而且它还持有 ColumnFamily 在各种状态下数据对象的引用,所以持有了 ColumnFamilyStore 就可以操作任何与 ColumnFamily 相关的数据了。与 ColumnFamilyStore 相关的类如图 6 所示
一 个 Keyspace 对应一个 Table,一个 Table 持有多个 ColumnFamilyStore,而一个 ColumnFamily 对应一个 ColumnFamilyStore。Table 并没有直接持有 ColumnFamily 的引用而是持有 ColumnFamilyStore,这是因为 ColumnFamilyStore 类中不仅定义了对 ColumnFamily 的各种操作而且它还持有 ColumnFamily 在各种状态下数据对象的引用,所以持有了 ColumnFamilyStore 就可以操作任何与 ColumnFamily 相关的数据了。与 ColumnFamilyStore 相关的类如图 6 所示 CommitLog 日志恢复
CommitLog 日志恢复 以上是 AutoBootstrap 模式启动,如果是以非 AutoBootstrap 模式启动,那么启动将会非常简单,这个过程如下:
以上是 AutoBootstrap 模式启动,如果是以非 AutoBootstrap 模式启动,那么启动将会非常简单,这个过程如下: 当组装成一个 message 后,再将这个消息按照 Gossip 协议组装成一个 pocket 发送到目的地址。关于这个 pocket 数据包的结构如下:
当组装成一个 message 后,再将这个消息按照 Gossip 协议组装成一个 pocket 发送到目的地址。关于这个 pocket 数据包的结构如下: 当 另外一个节点接受到 Syn 消息后,反序列化 message 的 byte 数组,它会取出这个消息的 verb 执行相应的动作,Syn 的 verb 就是解析出发送节点传过来的节点的状态信息与本地节点的状态信息进行比对,看哪边的状态信息更新,如果发送方更新,将这个更新的状态所对应的节点加入请求 列表,如果本地更新,则将本地的状态再回传给发送方。回送的消息是 Ack,当发送方接受到这个 Ack 消息后,将接受方的状态信息更新的本地对应的节点。再将接收方请求的节点列表的状态发送给接受方,这个消息是 Ack2,接受方法接受到这个 Ack2 消息后将请求的节点的状态更新到本地,这样一次状态同步就完成了。
当 另外一个节点接受到 Syn 消息后,反序列化 message 的 byte 数组,它会取出这个消息的 verb 执行相应的动作,Syn 的 verb 就是解析出发送节点传过来的节点的状态信息与本地节点的状态信息进行比对,看哪边的状态信息更新,如果发送方更新,将这个更新的状态所对应的节点加入请求 列表,如果本地更新,则将本地的状态再回传给发送方。回送的消息是 Ack,当发送方接受到这个 Ack 消息后,将接受方的状态信息更新的本地对应的节点。再将接收方请求的节点列表的状态发送给接受方,这个消息是 Ack2,接受方法接受到这个 Ack2 消息后将请求的节点的状态更新到本地,这样一次状态同步就完成了。 节点的状态同步操作有点复杂,如果前面描述的还不是很清楚的话,再结合下面的时序图,你就会更加明白了,如图 11 所示:
节点的状态同步操作有点复杂,如果前面描述的还不是很清楚的话,再结合下面的时序图,你就会更加明白了,如图 11 所示: 上图中省去了一部分重复的消息,还有节点是如何更新状态也没有在图中反映出来,这些部分在后面还有介绍,这里也无法完整的描述出来。
上图中省去了一部分重复的消息,还有节点是如何更新状态也没有在图中反映出来,这些部分在后面还有介绍,这里也无法完整的描述出来。 从 上图可以看出节点的状态信息由 ApplicationState 表示,并保存在 EndPointState 的集合中。状态的修改将会通知 IendPointStateChangeSubscriber,继而再更新 Subscriber 的具体实现类修改相应的状态。
从 上图可以看出节点的状态信息由 ApplicationState 表示,并保存在 EndPointState 的集合中。状态的修改将会通知 IendPointStateChangeSubscriber,继而再更新 Subscriber 的具体实现类修改相应的状态。 上 图基本描述了 Cassandra 更新状态的过程,需要说明的点是,Cassandra 为何要更新节点的状态,这实际上就是关于 Cassandra 对集群中节点的管理,它不是集中管理的方式,所以每个节点都必须保存集群中所有其它节点的最新状态,所以将本节点所持有的其它节点的状态与另外一个节点交 换,这样做有一个好处就是,并不需要和某个节点通信就能从其它节点获取它的状态信息,这样就加快了获取状态的时间,同时也减少了集群中节点交换信息的频 度。另外,节点状态信息的交换的根本还是为了控制集群中 Cassandra 所维护的一个 Token 环,这个 Token 是 Cassandra 集群管理的基础。因为数据的存储和数据流动都在这个 Token 环上进行,一旦环上的节点发生变化,Cassandra 就要马上调整这个 Token 环,只有这样才能始终保持整个集群正确运行。
上 图基本描述了 Cassandra 更新状态的过程,需要说明的点是,Cassandra 为何要更新节点的状态,这实际上就是关于 Cassandra 对集群中节点的管理,它不是集中管理的方式,所以每个节点都必须保存集群中所有其它节点的最新状态,所以将本节点所持有的其它节点的状态与另外一个节点交 换,这样做有一个好处就是,并不需要和某个节点通信就能从其它节点获取它的状态信息,这样就加快了获取状态的时间,同时也减少了集群中节点交换信息的频 度。另外,节点状态信息的交换的根本还是为了控制集群中 Cassandra 所维护的一个 Token 环,这个 Token 是 Cassandra 集群管理的基础。因为数据的存储和数据流动都在这个 Token 环上进行,一旦环上的节点发生变化,Cassandra 就要马上调整这个 Token 环,只有这样才能始终保持整个集群正确运行。
 让我们看看使用 Cassandra 数据模型如何实现此项操作。清单 3 展示了 Cassandra 的可能模式,其中第一行表示 “Book" 列族(拥有多个行),每一行拥有和列相同的书籍属性。<TS1> 和 <TS2> 表示时间戳。
让我们看看使用 Cassandra 数据模型如何实现此项操作。清单 3 展示了 Cassandra 的可能模式,其中第一行表示 “Book" 列族(拥有多个行),每一行拥有和列相同的书籍属性。<TS1> 和 <TS2> 表示时间戳。 Cassandra 使用一致的散列算法给节点分配数据项。简言之,Cassandra 使用一个散列算法来计算存储在 Cassandra (例如,列名称和行 ID)中的每个数据项的密钥散列。散列范围或所有可能的散列值(又称为密钥空间)是在 Cassandra 集群中的节点之间进行分配的。然后,Cassandra 向该节点分配每一个数据项,而该节点负责存储或管理数据项。论文 “Cassandra - A Decentralized Structured Storage System”(参阅 参考资料)提供了有关 Cassandra 架构的详细讨论。
Cassandra 使用一致的散列算法给节点分配数据项。简言之,Cassandra 使用一个散列算法来计算存储在 Cassandra (例如,列名称和行 ID)中的每个数据项的密钥散列。散列范围或所有可能的散列值(又称为密钥空间)是在 Cassandra 集群中的节点之间进行分配的。然后,Cassandra 向该节点分配每一个数据项,而该节点负责存储或管理数据项。论文 “Cassandra - A Decentralized Structured Storage System”(参阅 参考资料)提供了有关 Cassandra 架构的详细讨论。
