接着之前的一篇文章 BookKeeper 集群搭建及使用,本文是 BookKeeper 系列的第二篇,短期来看应该也是最后一篇,本篇文章主要聚焦于 BookKeeper 内核的实现机制上,会从 BookKeeper 的基本概念、架构、读写一致性实现、读写分离实现、容错机制等方面来讲述,因为我并没有看过 BookKeeper 的源码,所以这里的讲述主要还是从原理、方案实现上来介绍,具体如何从解决方案落地到具体的代码实现,有兴趣的可以去看下 BookKeeper 的源码实现。
BookKeeper 基础
正如 Apache BookKeeper 官网介绍的一样:A scalable, fault-tolerant, and low-latency storage service optimized for real-time workloads。BookKeeper 的定位是一个可用于实时场景下的高扩展性、强容错、低延迟的存储服务。Pulsar-Cloud Native Messaging & Streaming - 示说网 中也做了一个简单总结:
- 低延迟多副本复制:Quorum Parallel Replication;
- 持久化:所有操作保证在刷盘后才 ack;
- 强一致性:可重复读的一致性(Repeatable Read Consistency);
- 读写高可用;
- 读写分离。
BookKeeper 基本概念
BookKeeper 简介 部分已经对 BookKeeper 的基本概念做了一些讲解,这里再重新回顾一下,只有明白这些概念之后才能对更好地理解后面的内容,如下图所示,一个 Log/Stream/Topic 可以由下面的部分组成(图片来自 Pulsar-Cloud Native Messaging & Streaming)。
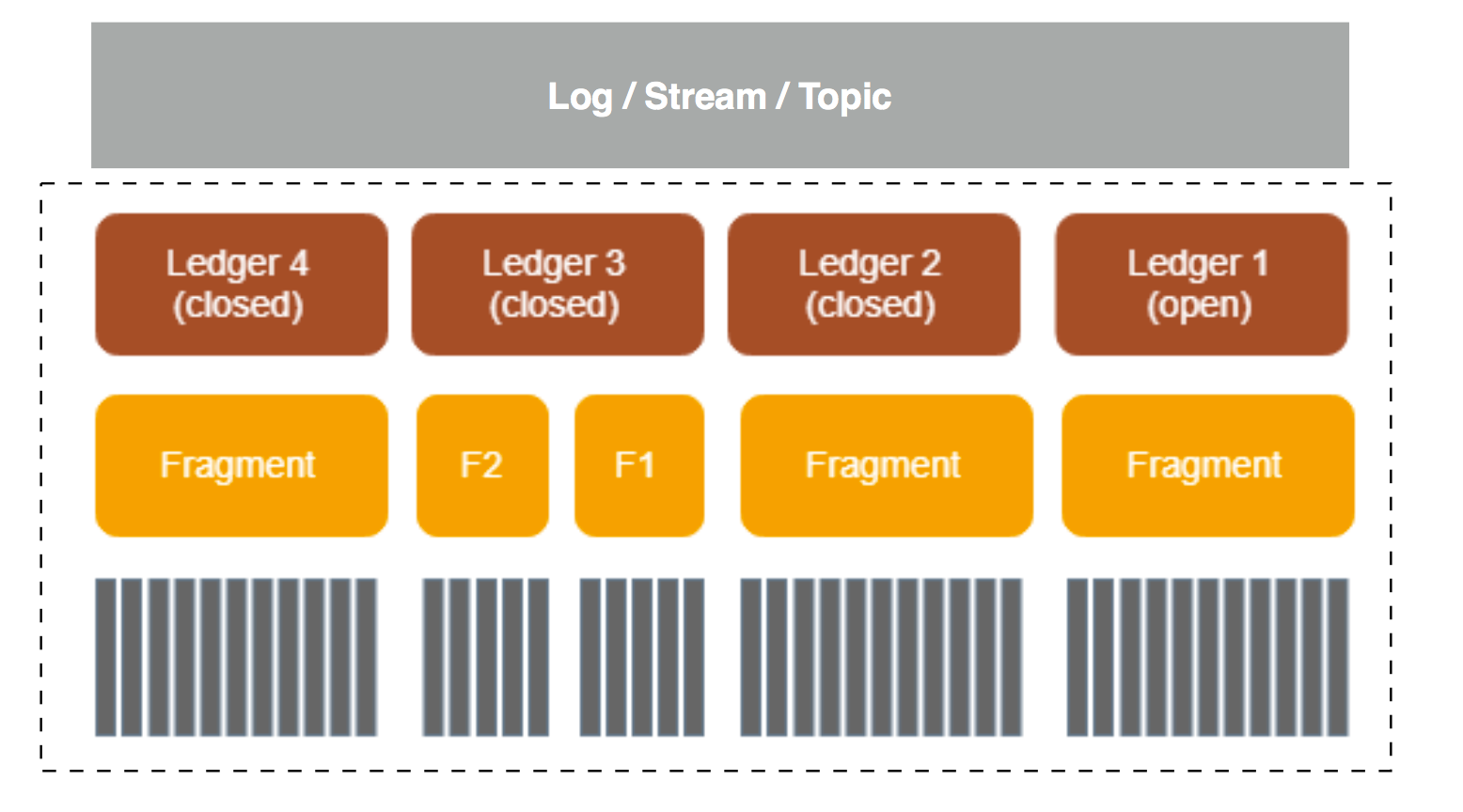 BookKeeper 中的基本概念
BookKeeper 中的基本概念
其中:
- Ledger:它是 BK 的一个基本存储单元(本质上还是一种抽象),BK Client 的读写操作也都是以 Ledger 为粒度的;
- Fragment:BK 的最小分布单元(实际上也是物理上的最小存储单元),也是 Ledger 的组成单位,默认情况下一个 Ledger 会对应的一个 Fragment(一个 Ledger 也可能由多个 Fragment 组成);
- Entry:每条日志都是一个 Entry,它代表一个 record,每条 record 都会有一个对应的 entry id;
关于 Fragment,它是 Ledger 的物理组成单元,也是最小的物理存储单元,在以下两种情况下会创建新的 Fragment:
- 当创建新的 Ledger 时;
- 当前 Fragment 使用的 Bookies 发生写入错误或超时,系统会在剩下的 Bookie 中新建 Fragment,但这时并不会新建 Ledger,因为 Ledger 的创建和关闭是由 Client 控制的,这里只是新建了 Fragment(需要注意的是:这两个 Fragment 对应的 Ensemble Bookie 已经不一样了,但它们都属于一个 Ledger,这里并不一定是一个 Ensemble Change 操作)。
BookKeeper 架构设计
Apache BookKeeper 的架构如下图所示,它主要由三个组件构成:客户端 (client)、数据存储节点 (Bookie) 和元数据存储 Service Discovery(ZooKeeper),Bookies 在启动的时候向 ZooKeeper 注册节点,Client 通过 ZooKeeper 发现可用的 Bookie。
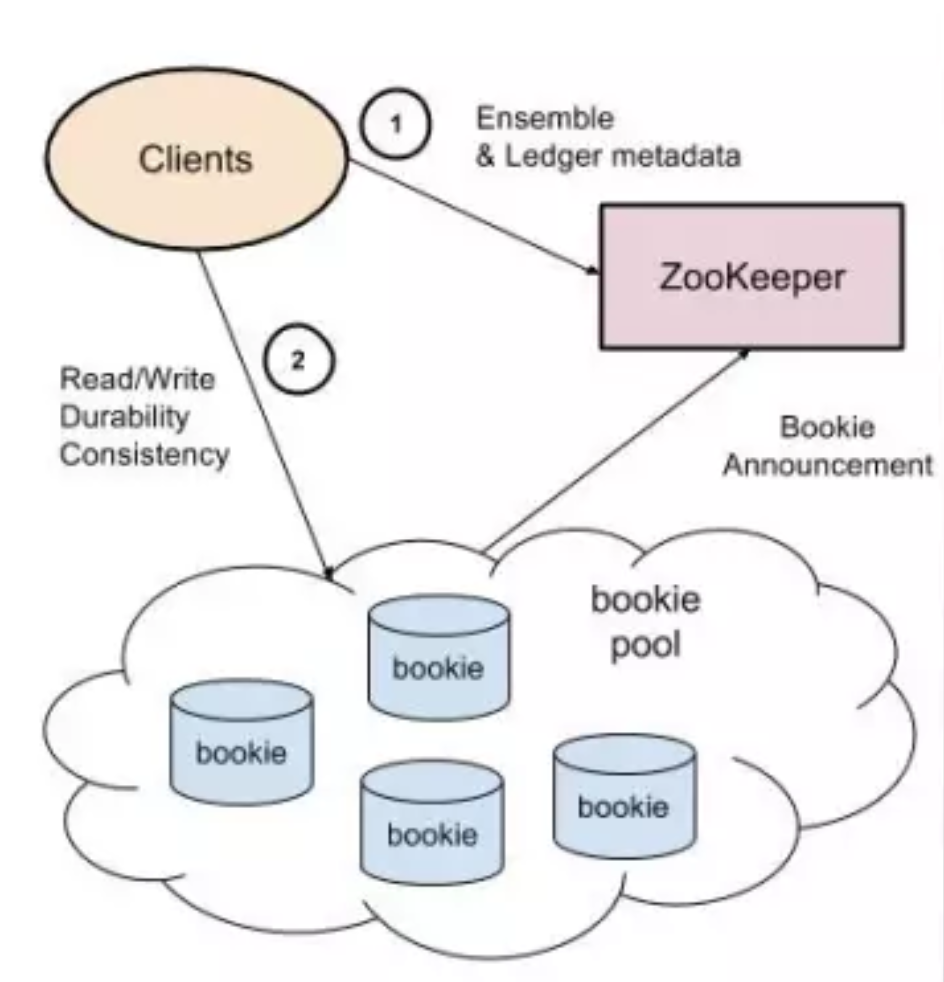 Apache BookKeeper 架构
Apache BookKeeper 架构
这里,我们可以看到 BookKeeper 架构属于典型的 slave-slave 架构,zk 存储其集群的 meta 信息(zk 虽是单点,但 zk 目前的高可用还是很有保障的),这种模式的好处显而易见,server 端变得非常简单,所有节点都是一样的角色和处理逻辑,能够这样设计的主要原因是其副本没有 leader 和 follower 之分,这是它与一些常见 mq(如:kafka、RocketMQ)系统的典型区别,每种设计都有其 trade-off,BeekKeeper 从设计之初就是为了高可靠而设计。
BookKeeper 存储层实现
Apache BookKeeper 是一个高可靠的分布式存储系统,存储层的实现是其核心,对一个存储系统来说,关键的几点实现,无非是:一致性如何保证、IO 如何优化、高可用如何实现等,这小节就让我们揭开其神秘面纱。
新建 Ledger
Ledger 是 BookKeeper 的基本存储抽象单元,这里先看下一个 Ledger 是如何创建的,这里会介绍一些关于 Ledger 存储层的一些重要概念(图片来自 Pulsar-Cloud Native Messaging & Streaming)。
 BookKeeper Ledger 的创建
BookKeeper Ledger 的创建
Ledger 是一组追加有序的记录,它是由 Client 创建的,然后由其进行追加写操作。每个 Ledger 在创建时会被赋予全局唯一的 ID,其他的 Client 可以根据 Ledger ID,对其进行读取操作。创建 Ledger 及 Entry 写入的相关过程如下:
- Client 在创建 Ledger 的时候,从 Bookie Pool 里面按照指定的数据放置策略挑选出一定数量的 Bookie,构成一个 Ensemble;
- 每条 Entry 会被并行地发送给 Ensemble 里面的部分 Bookies(每条 Entry 发送多少个 Bookie 是由 Write Quorum size 设置、具体发送哪些 Bookie 是由 Round Robin 算法来计算),并且所有 Entry 的发送以流水线的方式进行,也就是意味着发送第 N + 1 条记录的写请求不需要等待发送第 N 条记录的写请求返回;
- 对于每条 Entry 的写操作而言,当它收到 Ensemble 里面大多数 Bookie 的确认后(这个由 Ack Quorum size 来设置),Client 认为这条记录已经持久化到这个 Ensemble 中,并且有大多数副本。
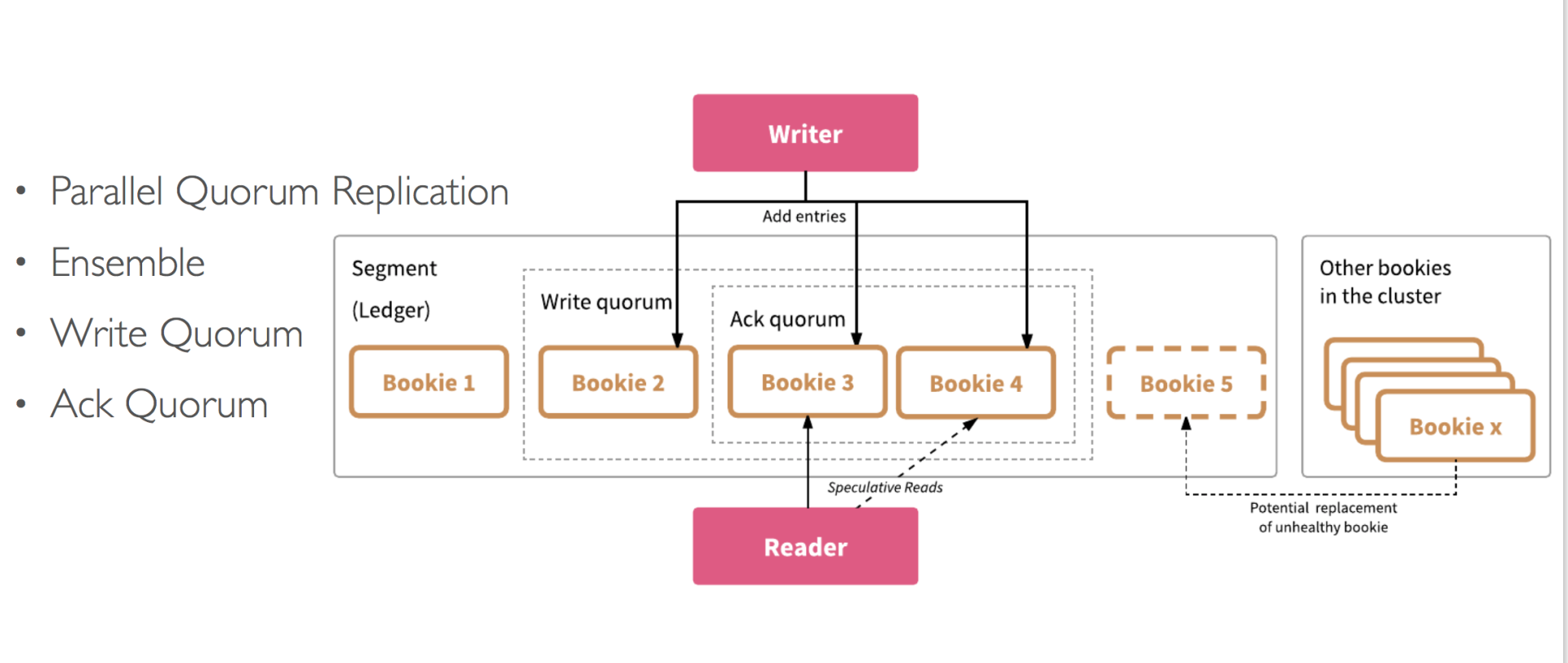
 BookKeeper Ledger 多副本复制
BookKeeper Ledger 多副本复制
这里引入了三个重要的概念,它们也是 BookKeeper 一致性的基础:
- Ensemble size(E):Set of Bookies across which a ledger is striped,一个 Ledger 所涉及的 Bookie 集合;
- Write Quorum Size(Qw):Number of replicas,副本数;
- Ack Quorum Size(Qa):Number of responses needed before client’s write is satisfied。
从上面 Ensemble、Qw、Qa 的概念可以得到以下这些推论:
- Ensemble:可以控制一个 Ledger 的读写带宽;
- Write Quorum:控制一条记录的复本数;
- Ack Quorum:写每条记录需要等待的 Ack 数 ,控制时延;
- 增加 Ensemble,可以增加读写带宽(增加了可写的机器数);
- 减少 Ack Quorum,可以减长尾时延。
一致性
对于分布式存储系统,为了高可用,多副本是其通用的解决方案,但也带来了一致性的问题,这里就看下 Apache BookKeeper 是如何解决其带来的一致性问题的。
一致性模型
在介绍其读写一致性之前,先看下 BK 的一致性模型(图片来自 Twitter高性能分布式日志系统架构解析)。
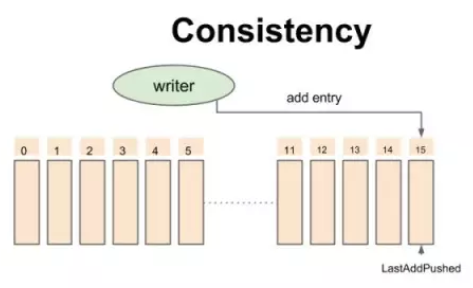 BookKeeper 一致性模型-开始时的状态
BookKeeper 一致性模型-开始时的状态
对于 Write 操作而言,writer 不断添加记录,每条记录会被 writer 赋予一个严格递增的 id,所有的追加操作都是异步的,也就是说:第二条记录不用等待第一条记录返回结果。所有写成功的操作都会按照 id 递增顺序返回 ack 给 writer。(图片来自 Twitter高性能分布式日志系统架构解析)。
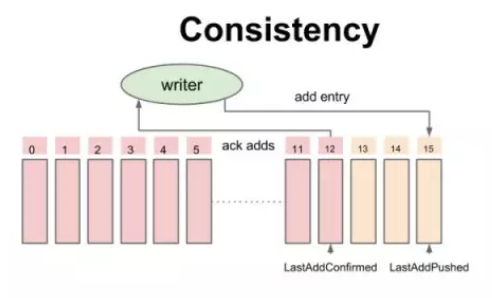 BookKeeper 一致性模型-追加数据时的中间状态
BookKeeper 一致性模型-追加数据时的中间状态
伴随着写成功的 ack,writer 不断地更新一个指针叫做 Last-Add-Confirm(LAC),所有 Entry id 小于等于 LAC 的记录保证持久化并复制到大多数副本上,而 LAC 与 LAP(Last-Add-Pushed)之间的记录就是已经发送到 Bookie 上但还未被 ack 的数据。
读的一致性
所有的 Reader 都可以安全读取 Entry ID 小于或者等于 LAC 的记录,从而保证 reader 不会读取未确认的数据,从而保证了 reader 之间的一致性(图片来自 Twitter高性能分布式日志系统架构解析)。
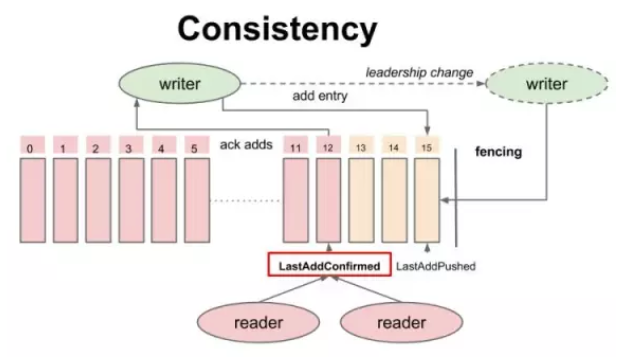 BookKeeper 一致性模型-读的一致性
BookKeeper 一致性模型-读的一致性
写的一致性
从上面的介绍中,也可以看出,对于 BK 的多个副本,其并没有 leader 和 follower 之分,因此,BK 并不会进行相应的选主(leader election)操作,并且限制每个 Ledger 只能被一个 Writer 写,BK 通过 Fencing 机制来防止出现多个 Writer 的状态,从而保证写的一致性。
读写分离
下面来看下 BK 存储层一个很重要的设计,那就是读写分离机制。在论文 Durability with BookKeeper 中,关于读写分离机制的介绍如下所示(图片来自 Durability with BookKeeper):
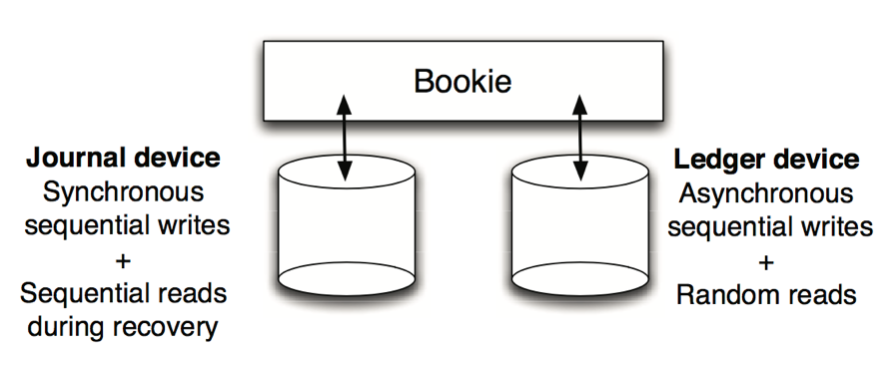 BookKeeper 读写分离
BookKeeper 读写分离
A bookie uses two devices, ideally in separate physical disks:
- The journal device is a write-ahead log and stores synchronously and sequentially all updates the bookie executes.
- The ledger device contains an indexed copy of a ledger fragment, which a bookie uses to respond to read requests.
上面是论文中关于 BK 读写分离机制实现的介绍,我当时在看完上面的记录之后,脑海中有以下疑问:
- 一个写请求是怎么处理?什么时候数据被认为是 ack 了;
- 数据肯定先写到 Journal Device 中的,那么数据是如何到 Ledger Device 中的?
- Ledger Device 中的顺序写跟随机读是什么意思?难道跟 RocketMQ 的存储结构一样?
- Ledger Device 底层是怎么切分实际的物理文件的?
- 数据在什么时候才能可见?
- 在从 Ledger Device 读数据时,它是通过什么机制提高查询速度的?
带着这些疑问,接下来来分析其实现(图片来自 Pulsar-Cloud Native Messaging & Streaming):
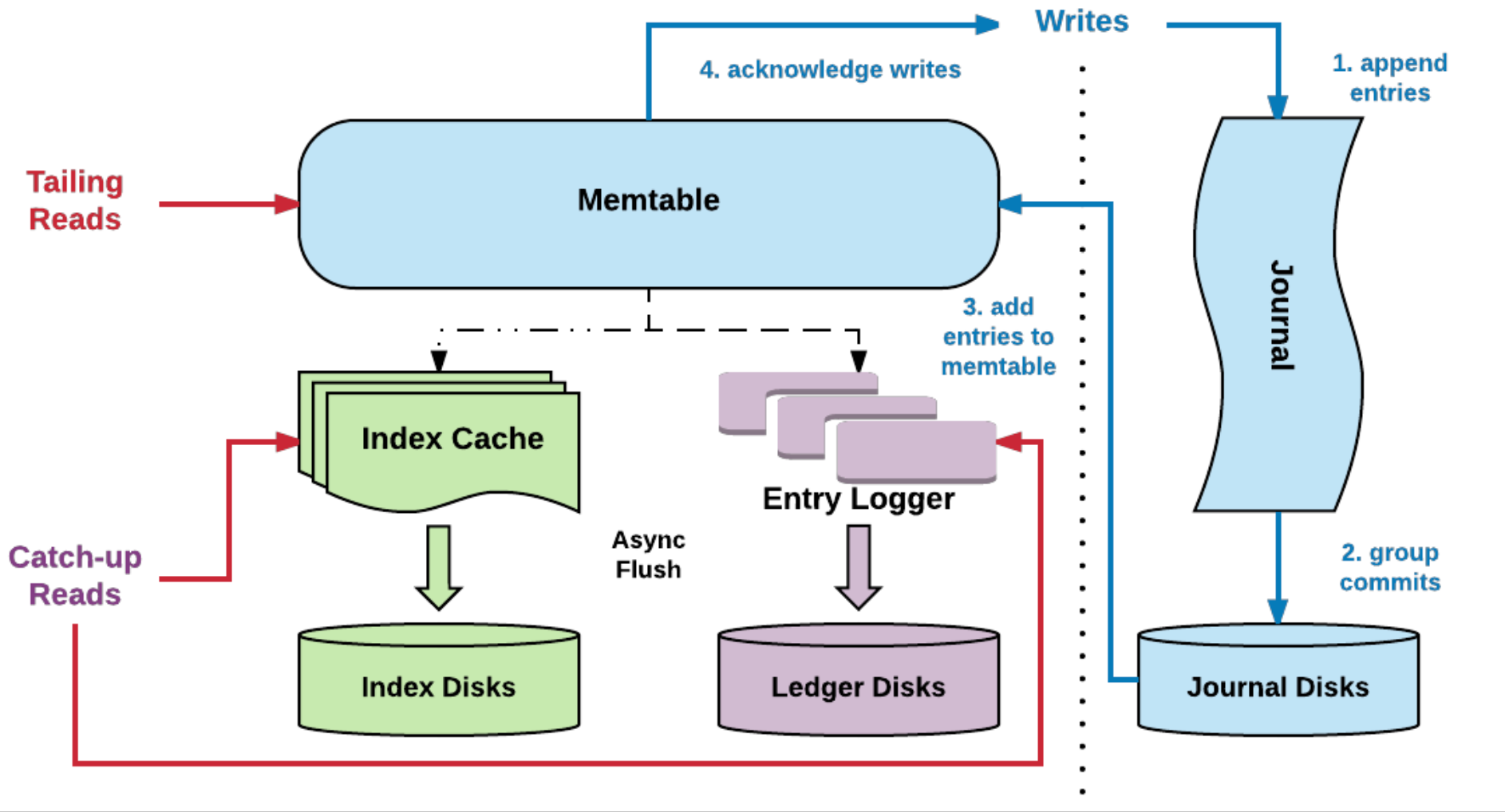 BookKeeper 读写分离
BookKeeper 读写分离
Journal Device 分析:
- 处理写入请求时,如果 Journal 是在专用的磁盘上,由于是顺序写入刷盘,性能会很高;
Ledger Device 的实现:
- Bookie 最初的设计方案是每个 Ledger 对应一个物理文件,但这样会极大消耗写性能,所以 Bookie 当前的设计方案是所有 Ledger 都写一个单独的文件中,这个文件又叫 entry log;
- 写入时,不但会写入到 Journal 中还会写入到缓存(memtable)中,定期会做刷盘(刷盘前会做排序,通过 聚合+排序 优化读取性能);
- 优化查找:Ledger Device 中会维护一个索引结构,存储在 RocksDB 中,它会将 (LedgerId,EntryId) 映射到(EntryLogId,文件中的偏移量)。
读写流程
了解完 BK 的一致性模型和读写分离机制之后,这里来看下 BK 的读写流程。
Entry 写入流程
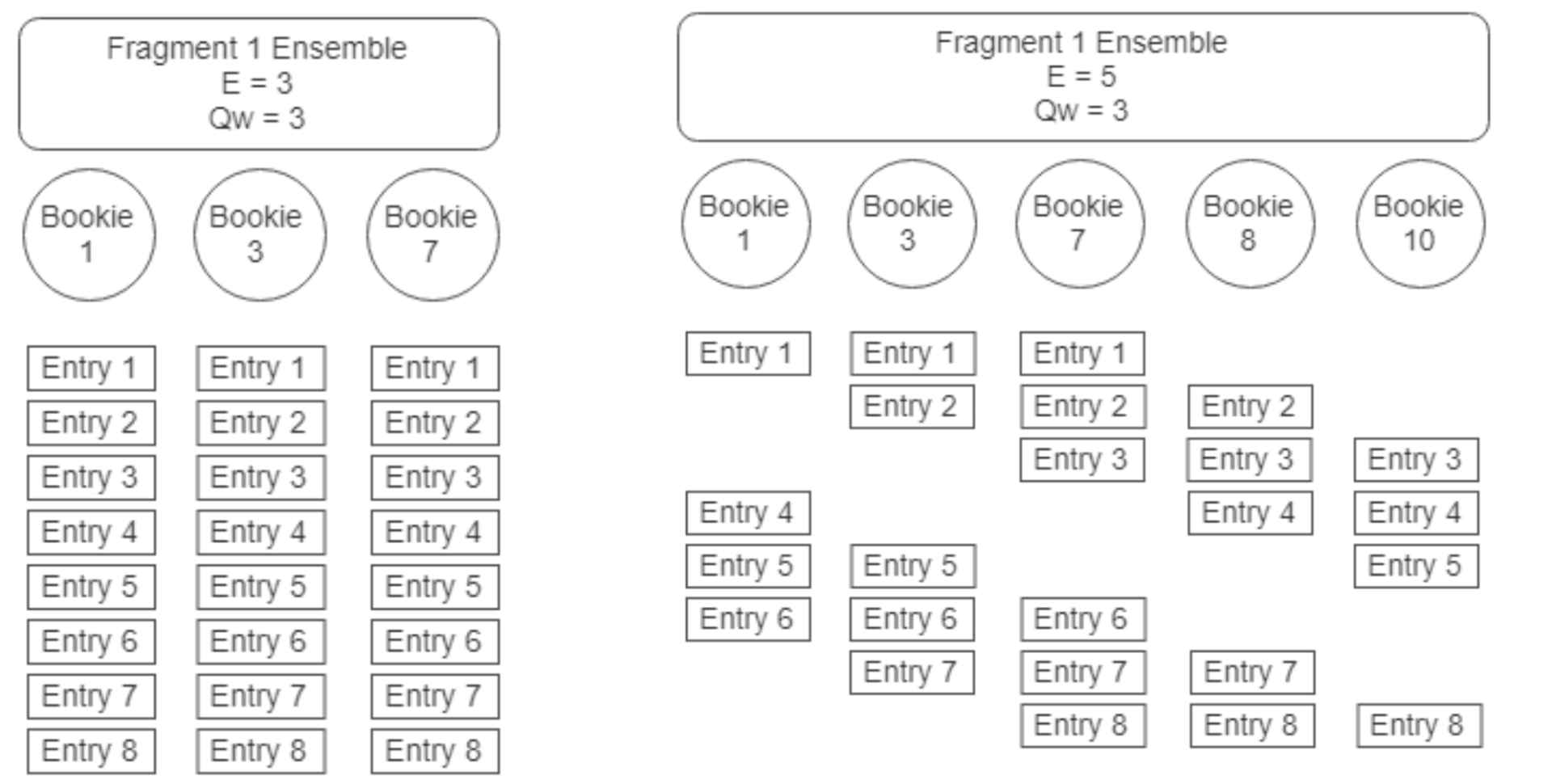
这里以一个例子来说明,假设 E 是3,Qw 和 Qa 是2,那么 Entry 写入如下图(图片来自 Durability with BookKeeper):
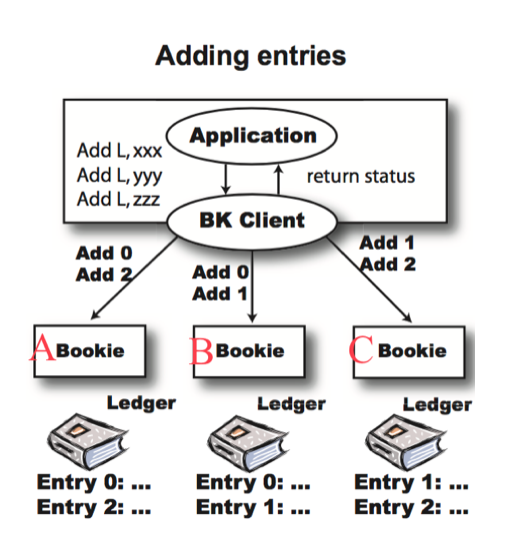 BookKeeper Entry 写入流程
BookKeeper Entry 写入流程
- Writer 会先分配对应的 id,然后按照 round-robin 算法从3个 Bookie 中选取2个 Bookie;
- Writer 会向两个 Bookie 发送写入请求,因为 Qa 设置为2,只有收到两个 ack 响应后,才会认为这条 Entry 写入成功;
如果写入过程中有一台 Bookie 挂了怎么办?
- 那么只能向另外2台 Bookie 写入数据;
- 这时候这个 Ledger 会新建一个 Fragment,假设挂的是A,之前 Ensemble 是 A、B、C,现在的是 B、C;
- 这个变化会更新到 zk 中这个 Ledger 的 meta 中。
如果写入过程中有两个 Bookie 挂了怎么办?
- Ensemble 里面的存活的 Bookies 不能满足 Qw 的要求;
- Client 会进行一个 Ensemble Change 操作;
- Ensemble Change 将从 Bookie Pool 中根据数据放置策略挑选出额外的 Bookie 用来取代那些不存活的 Bookie 。
Entry 读取流程
这里依然以一个例子做说明,例子是紧接着上面的示例,如下图所示(图片来自 Durability with BookKeeper):
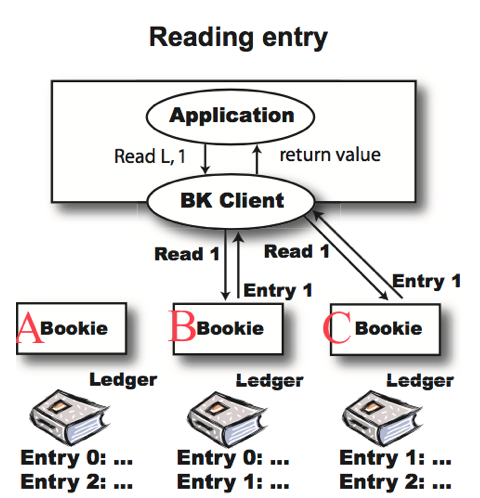 BookKeeper Entry 读取流程
BookKeeper Entry 读取流程
如何想要读取 id 为1的那条 Entry 应该怎么做?
- 在读取会选择最优的 Bookie,有了 Entry 的 id 和 Ledger 的 Ensemble 就可以根据 round-robin 计算出其所在 Bookie 信息,会选择向其中一个 Bookie 发送读请求。
这种机制会导致,读取数据时可能需要从多个 Bookie 获取数据,需要并发访问多个 Bookie,性能会变差,极端情况会有这个问题。
- BK 有一个优化策略:读取时一般是选择读一段数据,如果 entries 在同一台机器上,会从同一个 Bookie 把这批 Entry 全部读取。
BK 怎么处理长尾效应的问题(长尾效应指的是某台机器上某段或者某条数据读取得比较慢,进而影响了整体的效率)?
- Client 可以向任意一个副本读取相应的 Entry,但为了保证低延时,这里使用了一个叫 Speculative Read 的机制。读请求首先发送给第一个副本后,如果在指定的时间内没有收到 reponse,则发送读请求给第二个副本,然后同时等待第一个和第二个副本。谁第一个返回,即读取成功。通过有效的 Speculative read,可以很大程度减少长尾效应。
BookKeeper 容错机制
这里来简单来看下 BookKeeper 容错机制的实现。
Fencing 机制
Fencing 机制在前面已经简单介绍过了,它目的主要是为了保证写的一致性,严格保证一个 Ledger 只能被一个 Writer 来写。
Fencing 怎么触发呢?
- 如果一个 Writer 打开一个 Ledger,发现这个 Ledger 存在,并且没有 close,这种情况下,就会触发 Fencing 策略,并且触发 Ledger Recovery。
Log Recovery 机制
一个 Ledger 正常关闭后,会在其 Metadata 中存储 the last entry 的信息,所以正常关闭一个 Ledger 是非常重要的(Ledger 一旦关闭,其就是不可变的,读取的时候可以从任意一个 Bookie 上读取,而不需要再取 care 这个 Ledger 的 LAC 信息),否则可能会出现这样一种情况:
由于 Writer 挂了(Ledger 未正常关闭),导致部分数据写入成功,实际上这个条消息并不满足 Qw(可能满足了 Qa),会导致不同 Reader 读取的结果不一致!如下图所示:
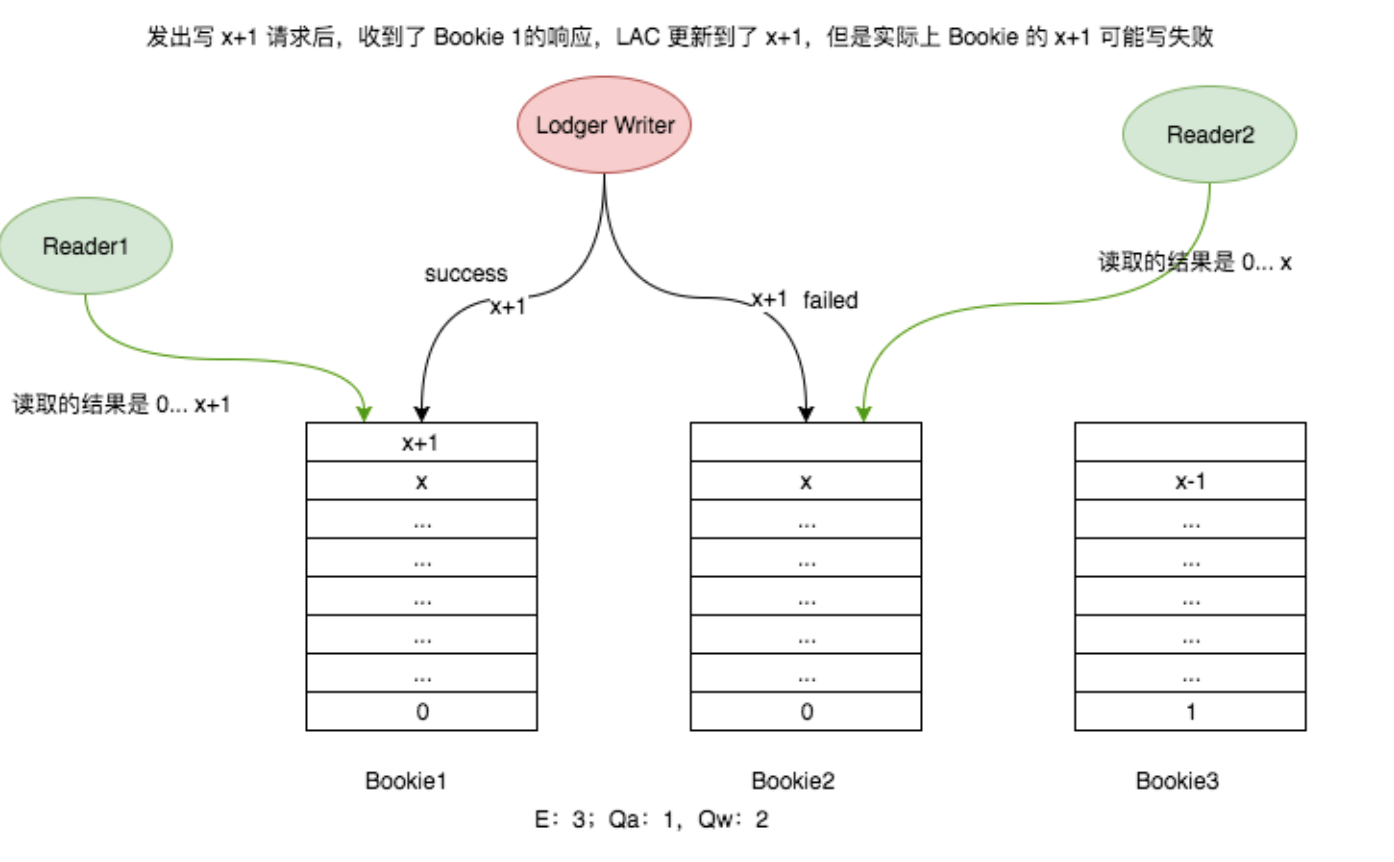 不同 Reader 读取不一致的情况
不同 Reader 读取不一致的情况
解决方案就是: Log Recovery,正常关闭这个 Ledger,并将 The Last Entry 及状态更新到 metadata 中。
Log Recovery 怎么实现呢?通常有两种方案:
- 遍历这个 Ledger 所有 Entry 进行恢复;
- 利用 LAC 机制可以加速 recovery:恢复前,先获取每个 Ledger 的 LAC 信息,然后从 LAC 开始恢复;
很明显,第二种方案是比较合理的恢复速度更快。
Bookie 容错
当一个 Bookie 故障时:
- 所有在这个 Bookie 上的 Ledgers 都处于 under-replica 状态,恢复就是复制 Fragment (Ledger 的组成单位)的过程,以确保每个 Ledger 维护的副本数打到 Qw。
Bk 提供自动和手动两种方式:两种方式的复制协议是一样的;自动恢复是 BK 内部自动触发,手动过程需要手动干预,这里重点介绍自动过程:
- 自动恢复是在 Bookie 上运行 AutoRecoveryMain 线程来实现,它会首先通过 zk 选举一个 Auditor;
- Auditor 的作用是检查不可用的 Bookie,然后做下面的操作:读取 zk 上完整的 Ledgers 信息,找到失败的 Ledgers(副本不满足条件的);然后在 zk 的
/underreplicatedznode 节点创建重新复制任务; - AutoRecoveryMain 还有 Replicator Worker 线程会复制相应的 Fragment 到自己的 Ledger 上,如果复制后满足 Fully Replicated,那么就从 zk 的节点中删除这个任务;
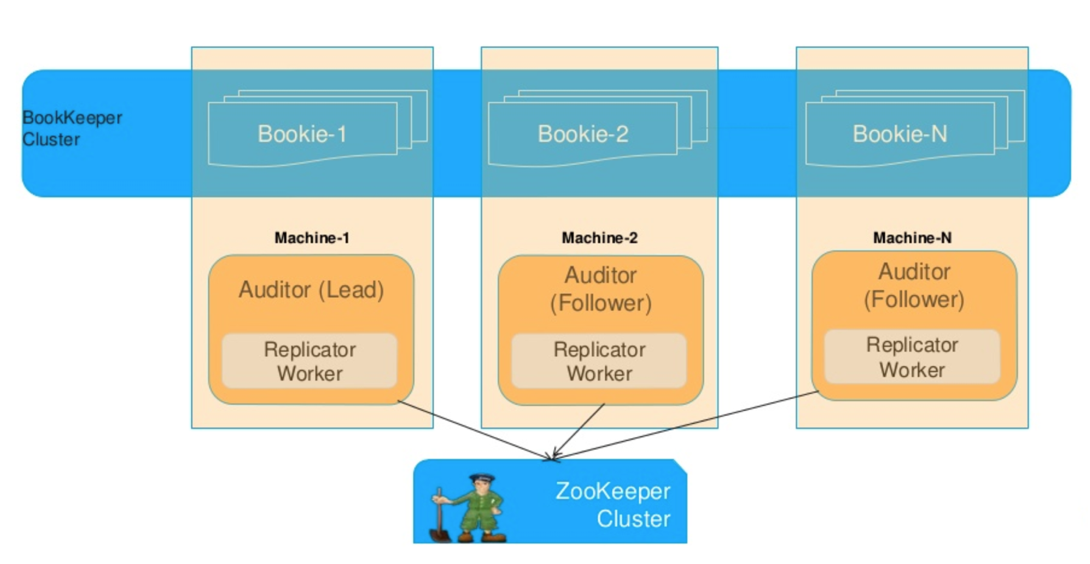 Bookie 容错机制
Bookie 容错机制
每个 Bookie 在发现任务时会尝试锁定,如果无法锁定就会执行后面的任务。如果获得锁,那么:
- 扫描 Ledgers,查找不属于当前 Bookie 的 Fragment;
- 对于每个匹配的 Fragment,它将另一个 Bookie 的数据复制到它自己的 Bookie,用新的集合更新 Zookeeper 并将 Fragment 标识为 Fully Replicated。
如果 Ledgers 仍然存在副本数不足的 Fragment,则释放锁。如果所有 Fragment 都已经Fully Replicated,则从 /underreplicated 删除重复复制任务。
BookKeeper介绍
BookKeeper带有多个读写日志的server,称为 bookies。每一个bookie是一个BookKeeper的存储服务,存储了写到BookKeeper上的write-ahead日志,及其数据内容。写入的log流(称它为流是因为BookKeeper记录的是byte[])称为 ledgers,一个ledger是一个日志文件,每个日志单元叫 ledger entry,也就是bookies是存ledgers的。ledger只支持append操作,而且同时只能有一个单线程来写。ZK充当BookKeeper的元数据存储服务,在zk中会存储ledger相关的元数据,包括当前可用的bookies,ledger分布的位置等。
BookKeeper通过读写多个存储节点达到高可用性,同时为了恢复由于异常造成的多节点数据不一致性,引入了数据一致性算法。BookKeeper的可用性还体现在只要有足够多的bookies可用,整个服务就可用。实际上,一份entry的写入需要确保N份日志冗余在N个bookie上写成功,而我们需要>N个bookie提供服务。在启动BookKeeper的时候,需要指定一个ensemble值,即bookie可用的最小节点数量,还需要指定一个quorums值,即日志写入BookKeeper服务端的冗余份数。BookKeeper的可扩展性体现在可以增加bookie数目,增加bookies可以提升读写吞吐量。
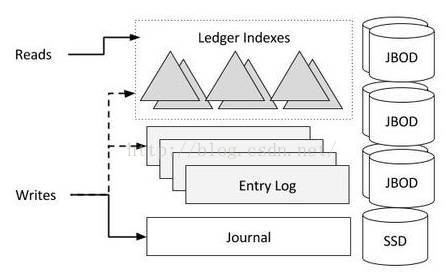
下面这张图,展示了序列化日志怎样写入到Bookie上。
Ledger记录首先写入到Journal,然后再写入到Indexes和Entry Log。写入到Journal是同步落盘持久化的。写入到Entry Log的是先缓存在Page Cache中,异步刷盘。一般建议Journal与日志实体(Entry Log/Ledger Indexes)分开存储,避免写入IO竞争。另外,为了写入的高性能,Journal选择SSD保存;日志实体可以存储在通用的硬盘设备上,比如JBOD。
由于不同Ledgers的记录都是汇聚到一起写入Entry Log的,即Bookies是顺序写,随机读的。为了提升读取性能,Bookies给每个Ledger维护了一个Ledger Indexes。这个索引映射日志实体(entries)位置与Ledger的关系(即entry log上哪个位置开始到哪个位置结束的数据属于哪个Ledger)。
最后
到这里,关于 BK 内核实现的主要部分已经介绍完毕,这篇文章的主要内容来自之前在团队的一次分享,一直想整理成博客的,但一直拖到了现在(因为并没有去看代码实现,主要是跟 bk 的论文及相关资料来整理的,有问题的地方欢迎指正)。
参考:
- Durability with BookKeeper;
- Pulsar-Cloud Native Messaging & Streaming;
- Apache BookKeeper Documentation;
- Introduction to Apache BookKeeper;
- Why Apache BookKeeper? Part 1: consistency, durability, availability;
- Why Apache Bookkeeper? Part 2;
- Understanding How Apache Pulsar Works;
- How to Lose Messages on a RabbitMQ Cluster;
- Pulsar-Cloud Native Messaging & Streaming - 示说网;
- Twitter高性能分布式日志系统架构解析;
- 来源:锌闻资讯

