典型的现代关系数据库在某些类型的应用程序中表现平平,难以满足如今的互联网应用程序的性能和可扩展 性要求。因此,需要采用不同的方法。在过去几年中,一种新的数据存储类型变得非常流行,通常称为 NoSQL,因为它可以直接解决关系数据库的一些缺陷。Riak 就是这类数据存储类型中的一种。
Riak 并不是惟一的一种 NoSQL 数据存储。另外两种较流行的数据存储是 MongoDB 和 Cassandra。尽管在许多方面十分相似,但是它们之间也存在明显的不同。例如,Riak 是一种分布式系统,而 MongoDB 是一种单独的系统数据库,也就是说,Riak 没有主节点的概念,因此在处理故障方面有更好的弹性。尽管 Cassandra 同样是基于 Amazon 的 Dynamo 描述,但是它在组织数据方面摒弃了向量时钟和相容散列等特性。Riak 的数据模型更加灵活。在 Riak 中,在第一次访问 bucket 时会动态创建这些 bucket;Cassandra 的数据模型是在 XML 文件中定义的,因此在修改它们过后需要重启整个群集。
Riak 的另一个优势是它是用 Erlang 编写的。而 MongoDB 和 Cassandra 是用通用语言(分别为 C++和 Java)编写,因此 Erlang 从一开始就支持分布式、容错应用程序,所以更加适用于开发 NoSQL 数据存储等应用程序,这些应用程序与使用 Erlang 编写的应用程序有一些共同的特征。
Map/Reduce 作业只能使用 Erlang 或 JavaScript 编写。对于本文呢,我们选择使用 JavaScript 编写 map 和 reduce 函数,但是也可以用 Erlang 编写它们。虽然 Erlang 代码的执行速度可能稍快一些,然而我们选择 JavaScript 代码的理由是它的受众更广。参阅 参考资料 中的链接,详细了解 Erlang。
开始
如果您希望尝试本文中的一些示例,则需要在您的系统中安装 Riak(参阅 参考资料)和 Erlang。
您 还需要构建一个包含三个节点的群集并在您的本地机器上运行它。Riak 中保存的所有数据都被复制到群集的大量节点中。数据所在的 bucket 的一个属性 (n_val) 决定了将要复制的节点的数量。该属性的默认值为 3,因此,要完成本示例,我们需要创建一个至少包含三个节点的群集(之后您可以创建任意数量的节点)。
下载了源代码后,您需要进行构建。基本步骤如下:
- 解压缩源代码:
$ tar xzvf riak-1.0.1.tar.gz - 修改目录:
$ cd riak-1.0.1 - 构建:
$ make all rel
这 将构建 Riak (./rel/riak)。要在本地运行多个节点,则需要生成 ./rel/riak 的副本,对每个额外的节点使用一个副本。将 ./rel/riak 复制到 ./rel/riak2、./rel/riak3 等地方,然后对每个副本执行下面的修改:
- 在 riakN/etc/app.config 中,修改下面的值:http{} 部分中指定的端口,handoff_port 和 pb_port,将它们修改为惟一值
- 打开 riakN/etc/vm.args 并修改名称,同样是修改为惟一值,例如
-name riak2@127.0.0.1
现在依次启动每个节点,如 清单 1 所示。
清单 1. 清单 1. 启动每个节点
$ cd rel
$ ./riak/bin/riak start
$ ./riak2/bin/riak start
$ ./riak3/bin/riak start
最后,将节点连接起来形成群集,如 清单 2 所示。
清单 2. 清单 2. 形成群集
$ ./riak2/bin/riak-admin join riak@127.0.0.1
$ ./riak3/bin/riak-admin join riak@127.0.0.1
您现在应该创建了一个在本地运行的 3 节点群集。要进行测试,运行如下命令: $ ./riak/bin/riak-admin status | grep ring_members。
您应当看到,每个节点都是刚刚创建的群集的一部分,例如 ring_members : ['riak2@127.0.0.1','riak3@127.0.0.1','riak@127.0.0.1']。
Riak API
目 前有三种方式可以访问 Riak:HTTP API(RESTful 界面)、Protocol Buffers 和一个原生 Erlang 界面。提供多个界面使您能够选择如何集成应用程序。如果您使用 Erlang 编写应用程序,那么应当使用原生的 Erlang 界面,这样就可以将二者紧密地集成在一起。其他一些因素也会影响界面的选择,比如性能。例如,使用 Protocol Buffers 界面的客户端的性能要比使用 HTTP API 的客户端性能更高一些;从性能方面讲,数据通信量变小,解析所有这些 HTTP 标头的开销相对更高。然而,使用 HTTP API 的优点是,如今的大部分开发人员(特别是 Web 开发人员)非常熟悉 RESTful 界面,再加上大多数编程语言都有内置的原语,支持通过 HTTP 请求资源,例如,打开一个 URL,因此不需要额外的软件。在本文中,我们将重点介绍 HTTP API。
所有示例都将使用 curl 通过 HTTP 界面与 Riak 交互。这样做是为了更好地理解底层的 API。许多语言都提供了大量客户端库,在开发使用 Riak 作为数据存储的应用程序时,应当考虑使用这些客户端库。客户端库提供了与 Riak 连接的 API,可以轻松地与应用程序集成;您不必亲自编写代码来处理在使用 curl 时出现的响应。
API 支持常见的 HTTP 方法:GET、PUT、POST、DELETE,它们将分别用于检索、更新、创建和删除对象。我们稍后将依次介绍每一种方法。
存储对象
您可以将 Riak 看成是创建键(字符串)与值(对象)的分布式映射。Riak 将值保存在 bucket 中。在保存对象之前,不需要显式地创建 bucket;如果将对象保存到一个不存在的 bucket 中,则会自动创建该 bucket。
Bucket 在 Riak 中是一个虚拟概念,主要是为了对相关对象分组而存在。bucket 还具有其他一些属性,这些属性的值定义了 Riak 对存储在其中的对象的处理。下面是 bucket 属性的一些示例:
n_val:对象在群集内进行复制的次数allow_mult:是否允许并发更新
您可以通过对 bucket 发出 GET 请求查看 bucket 的属性(及其当前值)。
要存储对象,我们将对 清单 3 所示的其中一个 URL 执行 HTTP POST。
清单 3. 清单 3. 存储对象
POST -> /riak/<bucket> (1)
POST -> /riak/<bucket>/<key> (2)
键可以由 Riak (1)自动分配,或由用户 (2) 定义。
当使用用户定义的键存储对象时,也可以向 (2) 执行一个 HTTP PUT 操作来创建对象。
Riak 的最新版本还支持以下 URL 格式:/buckets/<bucket>/keys/<key>,但是在本文中,我们将使用更旧的格式来维持与早期 Riak 版本的向后兼容性。
如果没有指定键,Riak 会自动为对象分配一个键。例如,我们将在 bucket “foo” 中存储一个明文对象,并且不会显式指定键(参见 清单 4)。
清单 4. 清单 4. 在不显式指定键的情况下存储一个明文对象
$ curl -i -H "Content-Type: plain/text" -d "Some text" \
http://localhost:8098/riak/foo/
HTTP/1.1 201 Created
Vary: Accept-Encoding
Location: /riak/foo/3vbskqUuCdtLZjX5hx2JHKD2FTK
Content-Type: plain/text
Content-Length: ...
通过检查 Location 标头,您可以看到 Riak 分配给对象的键。这样做不容易记忆,因此另一种选择是让用户提供键。让我们创建一个艺术家 bucket,并添加一个叫做 Bruce 的艺术家(参见 清单 5)。
清单 5. 清单 5. 创建一个艺术家 bucket 并添加一个艺术家
$ curl -i -d '{"name":"Bruce"}' -H "Content-Type: application/json" \
http://localhost:8098/riak/artists/Bruce
HTTP/1.1 204 No Content
Vary: Accept-Encoding
Content-Type: application/json
Content-Length: ...如果使用我们指定的键成功存储了对象,我们将从服务器得到一个 204 No Content 响应。
在本例中,我们将对象的值保存为 JSON,但是它既可以是明文格式,也可以是其他格式。在存储对象时,需要注意正确设置 Content-Type 标头。例如,如果希望存储一个 JPEG 图像,那么您必须将内容类型设置为 image/jpeg。
检索对象
要检索已存储的对象,使用您希望检索的对象的键对 bucket 运行 GET 方法。如果对象存在,则会在响应的正文中返回对象,否则服务器会返回 404 Object Not Found 响应(参见 清单 6)。
清单 6. 清单 6. 在 bucket 上执行一个 GET 方法
$ curl http://localhost:8098/riak/artists/Bruce
HTTP/1.1 200 OK
...
{ "name" : "Bruce" }更新对象
在更新对象时,和存储对象一样,需要用到 Content-Type 标头。例如,让我们来添加 Bruce 的别名,如 清单 7 所示。
清单 7. 清单 7. 添加 Bruce 的别名
$ curl -i -X PUT -d '{"name":"Bruce", "nickname":"The Boss"}' \
-H "Content-Type: application/json" http://localhost:8098/riak/artists/Bruce如 前所述,Riak 自动创建了 bucket。这些 bucket 拥有一些属性,其中一个属性为 allow_mult,用于确定是否允许执行并发写操作。默认情况下,该属性被设置为 false;但是,如果允许进行并发更新,则需要向每个更新发送 X-Riak-Vclock 标头。应该将该标头的值设置为与客户端最后一次读取对象时看到的值相同。
Riak 使用向量时钟 (vector clock) 判断修改对象的原因。向量时钟的工作原理超出了本文的讨论范围,但是,在允许执行并发写操作时,可能会出现冲突,这时需要使用应用程序来解决这些冲突(参阅 参考资料)。
删除对象
删除对象的操作使用了一个与前面的命令类似的模式,我们只需要对希望删除的对象所对应的 URL 执行一个 HTTP DELETE 方法: $ curl -i -X DELETE http://localhost:8098/riak/artists/Bruce。
如果成功删除对象,我们会从服务器获得一个 204 No Content 响应;如果试图删除的对象不存在,那么服务器会返回一个 404 Object Not Found 响应。
链接
目前为止,我们已经了解了如何通过将对象与特定键相关联来存储对象,稍后可以使用此特定键来检索对象。如果能够将这个简单的模型进行扩展以表示对象如何(以及是否)与其他对象相关,那么这会非常有用。我们当然可以实现这一点,并且 Riak 是使用链接实现的。
那么,什么是链接?链接允许用户创建对象之间的关系。如果熟悉 UML 类图的话,您可以将链接看作是对象之间的某种关联,并用一个书签说明这种关系;在关系数据库中,该关系被表示为一个外键。
通过 “Link” 标头,以将链接 “依附” 到对象上。下面演示了链接标头看起来是什么样子。例如,关系的目标(即我们准备进行链接的对象)是尖括号中的内容。关系内容(本例中为 “performer”)是通过 riaktag 属性来表示的:Link: </riak/artists/Bruce>; riaktag="performer"。
现在让我们添加一些专辑,并将它们与专辑的表演者艺术家 Bruce 关联起来(参见 清单 8)。
清单 8. 清单 8. 添加一些专辑
$ curl -H "Content-Type: text/plain" \
-H 'Link: </riak/artists/Bruce> riaktag="performer"' \
-d "The River" http://localhost:8098/riak/albums/TheRiver
$ curl -H "Content-Type: text/plain" \
-H 'Link: </riak/artists/Bruce> riaktag="performer"' \
-d "Born To Run" http://localhost:8098/riak/albums/BornToRun
现在我们已经设置了一些关系,接下来要通过 link walking 查询它们,link walking 是一个用于查询对象关系的进程。例如,要查找表演 River 专辑的艺术家,您应当这样做:$ curl -i http://localhost:8098/riak/albums/TheRiver/artists,performer,1。
末尾的位是链接说明。链接查询的外观就是这个样子。第一个部分(artists)指定我们应当执行查询的 bucket。第二个部分(performer)指定了我们希望用于限制结果的标签,最后的 1 部分表示我们希望包含这个查询阶段的结果。
还可以发出过渡性查询。假设我们在专辑和艺术家之间建立了关系,如 图 1 所示。
图 1. 图 1. 专辑和艺术家之间的关系
 通过执行下面的命令,可以发出 “哪些艺术家与表演 The River 专辑的艺术家合作过” 之类的查询:
通过执行下面的命令,可以发出 “哪些艺术家与表演 The River 专辑的艺术家合作过” 之类的查询:$ curl -i http://localhost:8098/riak/albums/TheRiver/artists,_,0/artists,collaborator,1。链接说明中的下划线的作用类似于通配符,表示我们不关心具体的关系是什么。
运行 Map/Reduce 查询
Map/Reduce 是一个由 Google 推广的框架,用于在大型数据集上同时运行分布式计算。Riak 还提供 Map/Reduce 支持,它允许对群集中的数据运行功能更强大的查询。
Map/Reduce 函数包括一个 map 阶段和一个 reduce 阶段。map 阶段应用于某些数据并生成 0 个或多个结果;这在编程中类似于通过列表中的每一项映射函数。map 阶段是并行发生的。reduce 阶段将获取 map 阶段的所有结果,并将它们组合起来。
例如,计算某个单词在大量文档中出现的次数。每个 map 阶段都将计算每个单词在特定文档中出现的次数。这些中间计数在计算完后将发送到 reduce 函数,然后计算总数并得出在所有文档中的次数。参见 参考资料,获得有关 Google 的 Map/Reduce 文章的链接。
示例:分布式 grep
对于本文,我们将开发一个 Map/Reduce 函数,该函数将对 Riak 中存储的一组文档执行一次分布式 grep。和 grep 一样,最终的输出是一些匹配所提供模式的行。此外,每个结果还将表示文档中出现匹配时所在位置的行号。
要执行一个 Map/Reduce 查询,我们将对 /mapred 资源执行 POST 操作。请求的内容是查询的 JSON 表示;和前面的例子一样,必须提供 Content-Type 标头,并且始终将其设置为 application/json。清单 9 显示了我们为执行分布式 grep 而做的查询。后面将依次讨论查询的每一个部分。
清单 9. 清单 9. 示例 Map/Reduce 查询
{
"inputs": [["documents","s1"],["documents","s2"]],
"query": [
{ "map": {
"language": "javascript",
"name": "GrepUtils.map",
"keep": true,
"arg": "[s|S]herlock" }
},
{ "reduce": { "language": "javascript", "name": "GrepUtils.reduce" } }
]
}每个查询都包含若干输入,例如,我们希望对之执行计算的文档,在 map 和 reduce 阶段运行的函数的名称。也可以直接在查询中包含 map 和 reduce 函数的源代码,只需要使用源属性替代名称即可,但是我在本例中没有这样做;然而,要使用指定的函数,则需要对 Riak 的默认配置进行一些修改。将清单 9 中的代码保存到某个目录中。对于群集中的每个节点,找到文件 etc/app.config,打开它并将属性 property js_source_dir 设置为您用于保存代码的目录。您需要重启群集中的所有节点使变更生效。
清单 10 中的代码包含将在 map 和 reduce 阶段执行的函数。map 函数将查看文档的每一行,确定是否与提供的模式(arg 参数)匹配。本例中的 reduce 函数并不会执行太多操作;它类似于一个恒等函数,仅仅用于返回输入。
清单 10. 清单 10. GrepUtils.js
var GrepUtils = {
map: function (v, k, arg) {
var i, len, lines, r = [], re = new RegExp(arg);
lines = v.values[0].data.split(/\r?\n/);
for (i = 0, len = lines.length; i < len; i += 1) {
var match = re.exec(lines[i]);
if (match) {
r.push((i+1) + “. “ + lines[i]);
}
}
return r;
},
reduce: function (v) {
return [v];
}
};在运行查询之前,我们需要一些数据。我从 Project Gutenberg Web 站点下载了 Sherlock Holmes 电子图书(参见 参考资料)。第一个文本存储在键 “s1” 下的 “documents” bucket 中;第二个文本位于同一个 bucket 中,键为 “s2”。
清单 11 展示了如何将这类文档上传到 Riak。
清单 11. 清单 11. 将文档上传到 Riak
$ curl -i -X POST http://localhost:8098/riak/documents/s1 \
-H “Content-Type: text/plain” --data-binary @s1.txt
上传文档后,我们现在可以对文档执行搜索。在本例中,我们想输出匹配常规表达式 "[s|S]herlock"(参见 清单 12)的所有行。
清单 12. 清单 12. 搜索文档
$ curl -X POST -H "Content-Type: application/json" \
http://localhost:8098/mapred --data @-<<\EOF
{
"inputs": [["documents","s1"],["documents","s2"]],
"query": [
{ "map": {
"language":"javascript",
"name":"GrepUtils.map",
"keep":true,
"arg": "[s|S]herlock" }
},
{ "reduce": { "language": "javascript", "name": "GrepUtils.reduce" } }
]
}
EOF查询中的 arg 属性包含我们希望在文档中对其执行 grep 查询的模式;该值被作为 arg 参数传递给 map 函数。
清单 13 中显示了对样例数据运行 Map/Reduce 作业所产生的输出。
清单 13. 清单 13. 运行 Map/Reduce 作业的样例输出
[["1. Project Gutenberg's The Adventures of Sherlock Holmes, by Arthur Conan
Doyle","9. Title: The Adventures of Sherlock Holmes","62. To Sherlock Holmes
she is always THE woman. I have seldom heard","819. as I had pictured it from
Sherlock Holmes' succinct description,","1017. \"Good-night, Mister Sherlock
Holmes.\"","1034. \"You have really got it!\" he cried, grasping Sherlock
Holmes by" …]]
流化 Map/Reduce
在关于 Map/Reduce 的最后部分中,我们将简单地了解 Riak 的 Map/Reduce 流化 (streaming) 特性。该特性对于包含 map 阶段并需要花一些时间完成这些阶段的作业非常有用,因为对结果进行流化允许您在生成每个 map 阶段的结果后立即访问它们,并且在执行 reduce 阶段之前访问它们。
我们可以对分布式 grep 查询应用这个特性。本例中的 reduce 步骤并没有多少实际操作。事实上,我们完全可以去掉 reduce 阶段,只需要将每个 map 阶段的结果直接发送到客户端即可。为了实现此目标,需要对查询进行修改,删除 reduce 步骤,将 ?chunked=true 添加到 URL 末尾,表示我们希望对结果进行流化(参见 清单 14)。
清单 14. 清单 14. 修改查询以流化结果
$ curl -X POST -H "Content-Type: application/json" \
http://localhost:8098/mapred?chunked=true --data @-<<\EOF
{
"inputs": [["documents","s1"],["documents","s2"]],
"query": [
{ "map": {
"language": "javascript",
"name": "GrepUtils.map",
"keep": true, "arg": "[s|S]herlock" } }
]
}
EOF在完成 map 阶段后,会将每个 map 阶段的结果(在本例中为匹配查询字符串的行)返回给客户端。该方法可用于需要在查询的中间结果可用时就对它们进行处理的应用程序。
Riak 是基于 Amazon 的 Dynamo 文件中记载的规则的一种开源的、高度可扩展的键值存储库。Riak 非常易于部署和扩展。可以无缝地向群集添加额外的节点。link walking 之类的特性以及对 Map/Reduce 的支持允许实现更加复杂的查询。除了 HTTP API 外,Riak 还提供了一个原生 Erlang API 以及对 Protocol Buffer 的支持。在本系列的第 2 部分中,我们将探讨各种不同语言中的大量客户端库,并展示如何将 Riak 用作一种高度可扩展的缓存。
二. Riak 应用
来源:http://www.ibm.com/developerworks/cn/opensource/os-riak2/
将 Riak 集成为 Web 应用程序的重负荷缓存服务器, 使用 Riak 作为一个缓存服务器,帮助缓解应用程序和数据库服务器上的负载
某些类型的数据表现出使自己适合于被缓存的访问模式。例如,在线投注站点具有一个有趣的负载特征:用户常常请求提供赔率和投注单,而这些信息相对来说很少被更新。
这些情况需要具有以下特征的高度可扩展的系统,以应对高负荷的要求:
- 该系统充当一个可靠的缓存,以减少对应用服务器和数据库的需求
- 缓存项目是可搜索的,所以您可以更新它们或使它们失效
- 任何解决方案都能被轻松地集成到现有站点
Riak 对于这样的解决方案是一个不错的选择。
Riak 对于实现这样一个缓存解决方案并非惟一的候选者;有许多不同的缓存可用。其中较为流行的一种是 memcached;然而,与 Riak 不同,memcached 不提供任何类型的数据复制,这意味着,如果保存特定项目的服务器停机,该项目会变得不可用。另一种流行的键/值存储是 Redis,它也可作为缓存使用,通过主从配置支持复制;Riak 没有一个主人(节点)的概念,因此,这使系统对故障更有弹性。
回页首
网站集成
任 何解决方案都需要很容易地被集成到现有网站。能够做到这一点很重要,因为并不一定有可能(或者甚至有需要)将您现有的全部数据迁移到 Riak。如前所述,某些类型的数据适合缓存,在一个键/值存储的情况下,如果您通过一个主键访问数据则更是如此。这是一种更适合迁移到 Riak 的数据。
正如在本系列的有关 Riak 的 Riak 简介,第 1 部分:与语言无关的 HTTP API 所述,PHP、Ruby 和 Java™ 等语言中提供了大量客户端库;这些库提供一个 API,使集成 Riak 非常简单。在本例中,我演示了 PHP 库的使用,以展示如何将 Riak 与现有网站集成。
图 1 显示了本例需要考虑的设置。我忽略了负载均衡、防火墙等细节。在本例中,服务器本身只是安装了一个 LAMP 堆栈的简单的前端箱。
我将假设,Riak 仅在内部使用(不能从外面访问它),且在一个非敌对的环境中运行,所以不存在身份验证等与安全相关的问题。该假设并不是像它看起来那么差劲,因为不管怎样 Riak 并没有任何内置的授权;您真的应该将身份验证等安全措施委托给应用程序。
图 1. 一个简单的网站集成
 下面是一个基本示例,演示您可以如何将 Riak 集成到您的现有网站。您将创建一个简单的表单,在提交表单时,根据在表单中输入的值,该表单将使用 PHP 客户端存储 Riak 中的对象。
下面是一个基本示例,演示您可以如何将 Riak 集成到您的现有网站。您将创建一个简单的表单,在提交表单时,根据在表单中输入的值,该表单将使用 PHP 客户端存储 Riak 中的对象。
图 2 显示了一个简单的表单示例,管理员可能会使用它在系统中创建一个投注项。用 HTML 创建该表单,并让它对 清单 1 中的 PHP 脚本执行一个 POST;您可以将本文所附的 源代码 中的类似表单作为一个起点。表单中输入的 “key” 字段将被用作在桶中存储的对象的键。
图 2. 创建投注的示例表单
 清单 1 的示例 PHP 代码显示了如何使用 PHP 客户端库来集成 Riak。将 PHP 客户端库路径(在 require_once 中指定)更改为您安装它的位置。在本例中,我只是将它与 PHP 脚本放在同一目录中。默认情况下,所有的客户端库都期待在端口 8098 上提供 Riak。
清单 1 的示例 PHP 代码显示了如何使用 PHP 客户端库来集成 Riak。将 PHP 客户端库路径(在 require_once 中指定)更改为您安装它的位置。在本例中,我只是将它与 PHP 脚本放在同一目录中。默认情况下,所有的客户端库都期待在端口 8098 上提供 Riak。
清单 1. 集成 Riak 的示例 PHP 代码
<?php
require_once('./riak.php');
# Could do check here to see if the current user has the
# appropriate credentials ? delegated to application.
$client = new RiakClient('192.168.1.1', 8098);
$bucket = $client->bucket('odds');
$bet = $bucket->newObject($_POST['key']);
$data = array(
'odds' => $_POST['odds'],
'description' => $_POST['description']
);
$bet->setData($data);
# Save the object to Riak
$bet->store();
echo "Thanks!";
?>将代码保存为一个 PHP 文件(按您喜欢的方式命名),将其和表单上传到您的网站上的某个位置,例如,http://www.yoursite.com/riak- test.php。填写示例表单,并提交它。为了证明它有效,尝试使用您在创建项目时在表单中输入的键直接从 Riak 中检索(参见 清单 2)。
清单 2. 从 Riak 中检索项目
$ curl -i http://localhost:8098/riak/odds/<key>
...
{ "odds":"", "description":"" }虽然该集成示例使用了 PHP 客户端,但其方法与 Java 或 Ruby on Rails 等其他语言或应用程序框架类似。
回页首
直接向请求提供服务
除了使用客户端库将 Riak 集成到当前设置外,还可以从 Riak 向用户请求直接提供服务,并将它用作一个简单的 HTTP 引擎。为了演示这一点,我将创建一个简单的演示,向您展示如何从 Riak 直接请求页面。
下载本文的 源代码。请确保 Riak 正在运行,然后执行脚本 load.sh。这个脚本会将所有的 HTML 和 JavaScript 文件复制到一个名称为 demo 的桶中。本例使用 JavaScript 客户端。
要查看演示,请在您的浏览器中打开以下 URL:http://localhost:8098/riak/demo/demo.html。
如果您在表单中输入了一些值来创建一个投注,并提交了表单,则会将一个 JSON 对象存储在 Riak 中。对象的属性将与表单中的字段对应。您会被重定向到一个显示您刚刚创建的对象值的页面。
清单 3 显示通过您输入的值来创建对象的代码。key、odds 和 description 等值来自在表单中输入的值。
清单 3. JavaScript 客户端库在 Riak 中的示例用法
client.bucket("odds", function(bucket) {
var key = $('#key').val();
bucket.get_or_new(key, function(status, object) {
object.contentType = 'application/json';
object.body = { 'odds': $('#odds').val(), 'description': $('#desc').val() };
object.store(function(status, object, request) {
if (status == 'ok') {
window.location = "http://localhost:8098/riak/odds/"+key;
} else {
alert("Failed to create object.");
}
});
});
});如前所述,我假设,Riak 在一个可信的环境中运行。在这种情况下,Riak 中用于存储和检索项目所添加的页面就不会产生安全问题;但是,您并不希望这种功能在没有某种形式的身份验证的前提下就完全暴露在 Internet 中。
虽 然这是一个简单的示例,但它使您了解到了 Riak 如何可以直接向页面请求提供服务。例如,您可以使用 JSONP 或跨源资源共享(AJAX 请求被相同的域策略限制在页面所驻留的同一台服务器上)等技术,也可以代理通过服务器向 Riak 发送的请求,从而在您现有的 Web 页面中直接包括存储在 Riak 中的数据,以获取所需的数据。
回页首
使用 Riak 作为缓存
缓 存用于提供数据的快速访问。如果缓存中包含了请求的数据(缓存命中),应用程序可以通过从缓存中读取值来快速向请求提供服务,这比从数据库中检索值更快。 如果缓存中没有数据(缓存未命中),那么应用程序通常必须在数据库中检索数据。一般情况下,您可以从缓存中服务的请求越多,系统将会越快。Riak 具有多项特性,这使其成为缓存解决方案实现的一个不错的选择。
其中一个这样的 Riak 特性是其可插拔的 (pluggable) 存储后端;存储后端决定如何存储数据。有若干个可用的存储后端,但我不打算在这里全部一一介绍(有关更多信息,请参阅 参考资料)。默认存储后端是 Bitcask,这是一个 Erlang 应用程序,提供一个 API,用于存储和检索受散列表支持的数据,该散列表提供了数据的快速访问;数据是永久性的。
有 一个后端也许与本文关系更紧密:Memory 后端。Memory 后端使用一个内存表来存储其所有的数据(它在内部使用 Erlang 的 ets 表),并且,在启用时,使 Riak 的行为像一个设定了有效期的 LRU 缓存。比起必须在磁盘上检索数据,使用内存存储的优势在于它明显快得多。当数据被存储在内存中(它不是永久的)且一个节点出现故障时,在该节点中存储的数 据将丢失。若您将它用作缓存,这就不是一个问题了(应用程序总是可以从数据库检索数据),就像您将 Riak 用作主数据存储一样。Riak 在集群中跨多个节点复制数据,因此它仍然是可用的。
Riak 自带 Memory 后端。为了使用 Memory 后端,请打开集群中每个节点的 app.config,定位属性 storage_backend,并将其从 riak_kv_bitcask_backend 更改为 riak_kv_memory_backend。现在将 清单 4 中的代码添加到文件的末尾。
清单 4. 使用 Memory 后端
{memory_backend, [
{max_memory, 4096}, %% 4GB of memory
{ttl, 86400} %% Time in seconds
]}将值更改为适合于您的设置的值。重新启动集群中的节点。
在 Riak 集群内也可以运行多个存储后端。这非常有用,因为这意味着可以针对不同的桶使用不同的后端。例如,您可以配置一个桶(让我们称之为 cache)来使用 Memory 后端,但对于其他桶(那些应当保存数据的桶),则使用 Bitcask。
既然您已经让 Riak 设置的行为像缓存一样,那么您需要一些方法来访问集群中的数据,以便更新它,或出于某种原因使它失效(在它的有效期结束前)。
回页首
查找什么内容吗?
正如您已经看到的,当使用 HTTP 界面检索在 Riak 中存储的数据时,您要构造一个 URL,其中包括桶的名称以及您要检索的对象的键,然后在该 URL 上执行一个 HTTP GET。当您知道键是什么时,这就完全足够了!但是,有时您并不知道要检索的对象的键,或者您要检索满足一定条件的一组对象。那么,您需要一种方法来搜索在集群中保存的对象。
您 已经看到如何通过存储在集群中的文档运行一个 Map/Reduce 作业来查询数据。一般来说,执行查询的时间与集群中的文档数量成正比;文档越多,查询这些文档所需要的时间越长。对于时间不敏感的查询,这不是一个问题。 我这样说的意思是,用户并不指望立即得到答复的查询。对于像搜索这样的操作,每次都(动态)搜索所有文档是不可行的;获得结果的时间可能是几分钟,也可能 是几小时!
幸运的是,Riak 对该问题已经有一个解决方案:Riak Search。Riak Search 提供搜索存储在整个集群中的文档时所需要的功能。搜索这个主题对于本文来说过于庞大,无法深入讨论,但从高层次来说,它的工作方式是这样的:文档被标记化 (Riak Search 使用标准的 Lucene 分析器),并被添加到一个反向索引。然后,根据用户输入的搜索项查询该索引。当新文件被添加时,它们也被索引并添加到索引中。
Riak Search 默认被禁用。在您可以使用它之前,您需要先启用它。在集群中的每个节点上,打开 rel/riakN/etc/app.config,定位属性 riak_search 并将它设置为 true。您需要重新启动集群中的节点。
Riak 通过使用提交前 (pre-commit) 和提交后 (post-commit) 挂钩,允许您指定文档被添加到桶之前和之后要运行的函数的名称。例如,在将文档添加到桶之前,您可能要检查文档是否有特定的必需字段。要搜索一个文档,需 要先对其进行索引。要做到这一点,需在存储文档的桶上安装一个 pre-commit 挂钩。要做到这一点,请运行以下命令:$ rel/riak/bin/search-cmd install <bucket name>
这将在桶上安装一个提交前挂钩 riak_search_kv_hook。现在,每当文档被添加到该桶,它就会被分析,并被添加到索引。空白分析器是默认的分析器;它基于空白将字符处理成标记,然后标记被索引。有一些不同的分析器可供使用,您也可以定义自己的分析器。
在许多情况下,Riak Search 知道如何索引您的数据。例如,开箱即用的,如果一个 JSON 对象被添加到某个桶,每个属性的值将被索引,并且可以在查询字符串中使用属性名称来查询。搜索示例请参见 清单 5。对于更复杂的结构,您可以定义自己的模式,告诉 Riak Search 如何索引数据。
当您已索引一些文档后,您需要能够对它们发出查询。一种方法是从 Erlang shell 运行查询。例如,在 清单 5 中的查询搜索与赛马有关的所有投注的赔率桶;您通过查询存储项的 description 属性完成该搜索。
清单 5. 搜索与赛马有关的投注的赔率桶
$ rel/riak/bin/riak attach
search:search(<<"odds">>, <<"description:horse">>).
此 外,Riak Search 还为文档搜索提供了一个 Solr 兼容的 HTTP API。Apache Solr 是一个流行的企业搜索服务器,带有一个类似于 REST 的 API。通过使 API 与 Solr 兼容,应该可以断开 Solr(如果您使用它),并改为使用 Riak Search 支持搜索。例如,要使用 Solr 界面搜索特定活动的赔率,您可以这样做:$ curl "http:localhost:8098/solr/odds/select?start=0&q=description:horse"
利用搜索设置,您现在即使不知道正在查找的项目的主键,也可以在数据存储中定位这些项目。
三. riak的安装和使用
参考:http://blog.csdn.net/freewebsys/article/details/12609995
来源:http://blog.csdn.net/freewebsys/article/details/12615047
1. Riak的接口访问有两种方式:
HTTP
Protocol Buffers 基于http的和pb的类似。
2,基于PB方式的调用
工程采用 maven,引入依赖:
代码放在github上面了:
https://github.com/freewebsys/riak_demo
<dependencies>
<dependency>
<groupId>com.basho.riak</groupId>
<artifactId>riak-client</artifactId>
<version>1.4.0</version>
</dependency>
<dependency>
<groupId>com.basho.riak.protobuf</groupId>
<artifactId>riak-pb</artifactId>
<version>1.4.0</version>
</dependency>
</dependencies>
3,简单的做一个表的CRUD
创建一个UserInfo类:
/**
* 用户信息.
*/
public class UserInfo {
private String uid;
private String name;
private String city;
private String nickName;
...get set 方法忽略
使用Riak进行CRUD:只是简单的将uid作为key存储,没有创建索引。
package com.demo;
import java.io.IOException;
import com.basho.riak.client.IRiakClient;
import com.basho.riak.client.RiakException;
import com.basho.riak.client.RiakFactory;
import com.basho.riak.client.RiakRetryFailedException;
import com.basho.riak.client.bucket.Bucket;
public class ClientTest {
public static void main(String[] args) throws IOException {
IRiakClient client = null;
try {// 使用pbc方式连接,而不是http,在/etc/riak/app.config
client = RiakFactory.pbcClient("127.0.0.1", 8087);
} catch (RiakException e) {
e.printStackTrace();
}
// 显示.
System.out.println(client);
Bucket myBucket = null;
String bucketName = "userInfo";
try {
myBucket = client.fetchBucket(bucketName).execute();
if (myBucket == null) {
myBucket = client.createBucket(bucketName).execute();
}
} catch (RiakRetryFailedException e) {
e.printStackTrace();
}
// ################保存数据 .
UserInfo info = new UserInfo();
info.setUid("001");
info.setName("张三");
info.setCity("北京");
try {
myBucket.store(info.getUid(), info).execute();
} catch (Exception e) {
e.printStackTrace();
}
// ################查询数据.
UserInfo fetchedUserInfo = null;
try {
fetchedUserInfo = myBucket.fetch("001", UserInfo.class).execute();
System.out.println(fetchedUserInfo);
} catch (Exception e) {
e.printStackTrace();
}
// ################修改数据.
try {
fetchedUserInfo = myBucket.fetch("001", UserInfo.class).execute();
fetchedUserInfo.setName("李四");
fetchedUserInfo.setNickName("老李");
myBucket.store(info.getUid(), info).execute();
// 保存 新数据
fetchedUserInfo = myBucket.fetch("001", UserInfo.class).execute();
System.out.println("新数据:" + fetchedUserInfo);
} catch (Exception e) {
e.printStackTrace();
}
// ################删除数据.
try {
myBucket.delete("001").execute();
fetchedUserInfo = myBucket.fetch("001", UserInfo.class).execute();
System.out.println("删除收数据." + fetchedUserInfo);
} catch (Exception e) {
e.printStackTrace();
}
// 关闭。
client.shutdown();
}
}
运行结果:
com.basho.riak.client.DefaultRiakClient@145edcf5
UserInfo [uid=001, name=张三, city=北京, nickName=null]
新数据:UserInfo [uid=001, name=张三, city=北京, nickName=null]
删除收数据.null
4,代码分析
在Riak当中,可以简单的把Bucket理解成一个表。
首先要创建一个这样的Bucket,然后把数据按照key放进去。
数据类型可以是字符串,基本类型,或是对象(如UserInfo)。
每次操作的时候都是通过执行Bucket的方法执行达到CRUD的操作。
StoreObject<IRiakObject> store(String key, byte[] value);
StoreObject<IRiakObject> store(String key, String value);
<T> StoreObject<T> store(T o);
<T> StoreObject<T> store(String key, T o);
FetchObject<IRiakObject> fetch(String key);
<T> FetchObject<T> fetch(String key, Class<T> type);
<T> FetchObject<T> fetch(T o);
MultiFetchObject<IRiakObject> multiFetch(String[] keys);
<T> MultiFetchObject<T> multiFetch(List<String> keys, Class<T> type);
<T> MultiFetchObject<T> multiFetch(List<T> o);
CounterObject counter(String counter);
<T> DeleteObject delete(T o);
DeleteObject delete(String key);
StreamingOperation<String> keys() throws RiakException;
<T> FetchIndex<T> fetchIndex(RiakIndex<T> index);
5,总结
java通过使用Protocol Buffers方式调用Riak服务,直接操作对象进行CRUD。
有了这些,可以做一个简单的评论系统了。评论系统上面不需要事物,并且数量会随着业务增长,使用Rick可以平稳的进行扩展。
这个只是简单的,对Rick服务进行CRUD。最没有用到其他功能,同时没有关于key的设计。
Rick的其他功能,以后继续研究。


 它 持久化的策略也很简单,就是首先将用户提交的数据所在的对象 RowMutation 序列化成 byte 数组,然后把这个对象和 byte 数组传给 LogRecordAdder 对象,由 LogRecordAdder 对象调用 CommitLogSegment 的 write 方法去完成写操作,这个 write 方法的代码如下:
它 持久化的策略也很简单,就是首先将用户提交的数据所在的对象 RowMutation 序列化成 byte 数组,然后把这个对象和 byte 数组传给 LogRecordAdder 对象,由 LogRecordAdder 对象调用 CommitLogSegment 的 write 方法去完成写操作,这个 write 方法的代码如下: 上图中每个不同的 columnFamily 的 id 都包含在 header 中,这样做的目的是更容易的判断那些数据没有被序列化。
上图中每个不同的 columnFamily 的 id 都包含在 header 中,这样做的目的是更容易的判断那些数据没有被序列化。
 Memtable 中的数据会根据配置文件中的相应配置参数刷到本地磁盘中。这些参数在上一篇中已经做了详细说明。
Memtable 中的数据会根据配置文件中的相应配置参数刷到本地磁盘中。这些参数在上一篇中已经做了详细说明。
 Memtable 的条件满足后,它会创建一个 SSTableWriter 对象,然后取出 Memtable 中所有的 <DecoratedKey, ColumnFamily> 集合,将 ColumnFamily 对象的序列化结构写到 DataOutputBuffer 中。接下去 SSTableWriter 根据 DecoratedKey 和 DataOutputBuffer 分别写到 Date、Index 和 Filter 三个文件中。
Memtable 的条件满足后,它会创建一个 SSTableWriter 对象,然后取出 Memtable 中所有的 <DecoratedKey, ColumnFamily> 集合,将 ColumnFamily 对象的序列化结构写到 DataOutputBuffer 中。接下去 SSTableWriter 根据 DecoratedKey 和 DataOutputBuffer 分别写到 Date、Index 和 Filter 三个文件中。 Data 文件就是按照上述 byte 数组来组织文件的,数据被写到 Data 文件中是接着就会往 Index 文件中写,Index 中到底写什么数据呢?
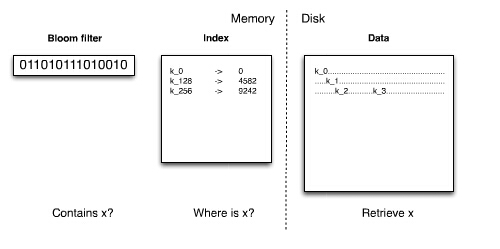
Data 文件就是按照上述 byte 数组来组织文件的,数据被写到 Data 文件中是接着就会往 Index 文件中写,Index 中到底写什么数据呢? Index 文件实际上就是 Key 的一个索引文件,目前只对 Key 做索引,对 super column 和 column 都没有建索引,所以要匹配 column 相对来说要比 Key 更慢。
Index 文件实际上就是 Key 的一个索引文件,目前只对 Key 做索引,对 super column 和 column 都没有建索引,所以要匹配 column 相对来说要比 Key 更慢。 BloomFilter 对象实际上对应一个 Hash 算法,这个算法能够快速的判断给定的某个 Key 在不在当前这个 SSTable 中,而且每个 SSTable 对应的 BloomFilter 对象都在内存中,Filter 文件指示 BloomFilter 持久化的一个副本。三个文件对应的数据格式可以用下图来清楚的表示:
BloomFilter 对象实际上对应一个 Hash 算法,这个算法能够快速的判断给定的某个 Key 在不在当前这个 SSTable 中,而且每个 SSTable 对应的 BloomFilter 对象都在内存中,Filter 文件指示 BloomFilter 持久化的一个副本。三个文件对应的数据格式可以用下图来清楚的表示:
 大慨的写入逻辑是这样的:
大慨的写入逻辑是这样的:
 根 据上面的类图读取的逻辑是,CassandraServer 创建 ReadCommand 对象,这个对象保存了用户要获取记录的所有必须指定的条件。然后交给 weakReadLocalCallable 这个线程去到 ColumnFamilyStore 对象中去搜索数据,包括 Memtable 和 SSTable。将找到的数据组装成 Row 返回,这样一个查询过程就结束了。这个查询逻辑可以用下面的时序图来表示:
根 据上面的类图读取的逻辑是,CassandraServer 创建 ReadCommand 对象,这个对象保存了用户要获取记录的所有必须指定的条件。然后交给 weakReadLocalCallable 这个线程去到 ColumnFamilyStore 对象中去搜索数据,包括 Memtable 和 SSTable。将找到的数据组装成 Row 返回,这样一个查询过程就结束了。这个查询逻辑可以用下面的时序图来表示: 在 上图中还一个地方要说明的是,取得 key 对应的 ColumnFamily 要至少在三个地方查询,第一个就是 Memtable 中,第二个是 MemtablesPendingFlush,这个是将 Memtable 转化为 SSTable 之前的一个临时 Memtable。第三个是 SSTable。在 SSTable 中查询最为复杂,它首先将要查询的 key 与每个 SSTable 所对应的 Filter 做比较,这个 Filter 保存了所有这个 SSTable 文件中含有的所有 key 的 Hash 值,这个 Hsah 算法能快速判断指定的 key 在不在这个 SSTable 中,这个 Filter 的值在全部保存在内存中,这样能快速判断要查询的 key 在那个 SSTable 中。接下去就要在 SSTable 所对应的 Index 中查询 key 所对应的位置,从前面的 Index 文件的存储结构知道,Index 中保存了具体数据在 Data 文件中的 Offset。,拿到这个 Offset 后就可以直接到 Data 文件中取出相应的长度的字节数据,反序列化就可以达到目标的 ColumnFamily。由于 Cassandra 的存储方式,同一个 key 所对应的值可能存在于多个 SSTable 中,所以直到查找完所有的 SSTable 文件后再与前面的两个 Memtable 查找出来的结果合并,最终才是要查询的值。
在 上图中还一个地方要说明的是,取得 key 对应的 ColumnFamily 要至少在三个地方查询,第一个就是 Memtable 中,第二个是 MemtablesPendingFlush,这个是将 Memtable 转化为 SSTable 之前的一个临时 Memtable。第三个是 SSTable。在 SSTable 中查询最为复杂,它首先将要查询的 key 与每个 SSTable 所对应的 Filter 做比较,这个 Filter 保存了所有这个 SSTable 文件中含有的所有 key 的 Hash 值,这个 Hsah 算法能快速判断指定的 key 在不在这个 SSTable 中,这个 Filter 的值在全部保存在内存中,这样能快速判断要查询的 key 在那个 SSTable 中。接下去就要在 SSTable 所对应的 Index 中查询 key 所对应的位置,从前面的 Index 文件的存储结构知道,Index 中保存了具体数据在 Data 文件中的 Offset。,拿到这个 Offset 后就可以直接到 Data 文件中取出相应的长度的字节数据,反序列化就可以达到目标的 ColumnFamily。由于 Cassandra 的存储方式,同一个 key 所对应的值可能存在于多个 SSTable 中,所以直到查找完所有的 SSTable 文件后再与前面的两个 Memtable 查找出来的结果合并,最终才是要查询的值。



 创建每个 Table 的实例
创建每个 Table 的实例 一 个 Keyspace 对应一个 Table,一个 Table 持有多个 ColumnFamilyStore,而一个 ColumnFamily 对应一个 ColumnFamilyStore。Table 并没有直接持有 ColumnFamily 的引用而是持有 ColumnFamilyStore,这是因为 ColumnFamilyStore 类中不仅定义了对 ColumnFamily 的各种操作而且它还持有 ColumnFamily 在各种状态下数据对象的引用,所以持有了 ColumnFamilyStore 就可以操作任何与 ColumnFamily 相关的数据了。与 ColumnFamilyStore 相关的类如图 6 所示
一 个 Keyspace 对应一个 Table,一个 Table 持有多个 ColumnFamilyStore,而一个 ColumnFamily 对应一个 ColumnFamilyStore。Table 并没有直接持有 ColumnFamily 的引用而是持有 ColumnFamilyStore,这是因为 ColumnFamilyStore 类中不仅定义了对 ColumnFamily 的各种操作而且它还持有 ColumnFamily 在各种状态下数据对象的引用,所以持有了 ColumnFamilyStore 就可以操作任何与 ColumnFamily 相关的数据了。与 ColumnFamilyStore 相关的类如图 6 所示 CommitLog 日志恢复
CommitLog 日志恢复 以上是 AutoBootstrap 模式启动,如果是以非 AutoBootstrap 模式启动,那么启动将会非常简单,这个过程如下:
以上是 AutoBootstrap 模式启动,如果是以非 AutoBootstrap 模式启动,那么启动将会非常简单,这个过程如下: 当组装成一个 message 后,再将这个消息按照 Gossip 协议组装成一个 pocket 发送到目的地址。关于这个 pocket 数据包的结构如下:
当组装成一个 message 后,再将这个消息按照 Gossip 协议组装成一个 pocket 发送到目的地址。关于这个 pocket 数据包的结构如下: 当 另外一个节点接受到 Syn 消息后,反序列化 message 的 byte 数组,它会取出这个消息的 verb 执行相应的动作,Syn 的 verb 就是解析出发送节点传过来的节点的状态信息与本地节点的状态信息进行比对,看哪边的状态信息更新,如果发送方更新,将这个更新的状态所对应的节点加入请求 列表,如果本地更新,则将本地的状态再回传给发送方。回送的消息是 Ack,当发送方接受到这个 Ack 消息后,将接受方的状态信息更新的本地对应的节点。再将接收方请求的节点列表的状态发送给接受方,这个消息是 Ack2,接受方法接受到这个 Ack2 消息后将请求的节点的状态更新到本地,这样一次状态同步就完成了。
当 另外一个节点接受到 Syn 消息后,反序列化 message 的 byte 数组,它会取出这个消息的 verb 执行相应的动作,Syn 的 verb 就是解析出发送节点传过来的节点的状态信息与本地节点的状态信息进行比对,看哪边的状态信息更新,如果发送方更新,将这个更新的状态所对应的节点加入请求 列表,如果本地更新,则将本地的状态再回传给发送方。回送的消息是 Ack,当发送方接受到这个 Ack 消息后,将接受方的状态信息更新的本地对应的节点。再将接收方请求的节点列表的状态发送给接受方,这个消息是 Ack2,接受方法接受到这个 Ack2 消息后将请求的节点的状态更新到本地,这样一次状态同步就完成了。 节点的状态同步操作有点复杂,如果前面描述的还不是很清楚的话,再结合下面的时序图,你就会更加明白了,如图 11 所示:
节点的状态同步操作有点复杂,如果前面描述的还不是很清楚的话,再结合下面的时序图,你就会更加明白了,如图 11 所示: 上图中省去了一部分重复的消息,还有节点是如何更新状态也没有在图中反映出来,这些部分在后面还有介绍,这里也无法完整的描述出来。
上图中省去了一部分重复的消息,还有节点是如何更新状态也没有在图中反映出来,这些部分在后面还有介绍,这里也无法完整的描述出来。 从 上图可以看出节点的状态信息由 ApplicationState 表示,并保存在 EndPointState 的集合中。状态的修改将会通知 IendPointStateChangeSubscriber,继而再更新 Subscriber 的具体实现类修改相应的状态。
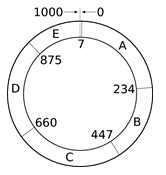
从 上图可以看出节点的状态信息由 ApplicationState 表示,并保存在 EndPointState 的集合中。状态的修改将会通知 IendPointStateChangeSubscriber,继而再更新 Subscriber 的具体实现类修改相应的状态。 上 图基本描述了 Cassandra 更新状态的过程,需要说明的点是,Cassandra 为何要更新节点的状态,这实际上就是关于 Cassandra 对集群中节点的管理,它不是集中管理的方式,所以每个节点都必须保存集群中所有其它节点的最新状态,所以将本节点所持有的其它节点的状态与另外一个节点交 换,这样做有一个好处就是,并不需要和某个节点通信就能从其它节点获取它的状态信息,这样就加快了获取状态的时间,同时也减少了集群中节点交换信息的频 度。另外,节点状态信息的交换的根本还是为了控制集群中 Cassandra 所维护的一个 Token 环,这个 Token 是 Cassandra 集群管理的基础。因为数据的存储和数据流动都在这个 Token 环上进行,一旦环上的节点发生变化,Cassandra 就要马上调整这个 Token 环,只有这样才能始终保持整个集群正确运行。
上 图基本描述了 Cassandra 更新状态的过程,需要说明的点是,Cassandra 为何要更新节点的状态,这实际上就是关于 Cassandra 对集群中节点的管理,它不是集中管理的方式,所以每个节点都必须保存集群中所有其它节点的最新状态,所以将本节点所持有的其它节点的状态与另外一个节点交 换,这样做有一个好处就是,并不需要和某个节点通信就能从其它节点获取它的状态信息,这样就加快了获取状态的时间,同时也减少了集群中节点交换信息的频 度。另外,节点状态信息的交换的根本还是为了控制集群中 Cassandra 所维护的一个 Token 环,这个 Token 是 Cassandra 集群管理的基础。因为数据的存储和数据流动都在这个 Token 环上进行,一旦环上的节点发生变化,Cassandra 就要马上调整这个 Token 环,只有这样才能始终保持整个集群正确运行。