Cassandra简介(注:该段介绍来自baidu百科)
Cassandra是一个混合型的非关系的数据库,类似于Google的BigTable。其主要功能比Dynomite(分布式的Key-Value存储系统)更丰富,但支持度却不如文档存储MongoDB(介于关系数据库和非关系数据库之间的开源产品,是非关系数据库当中功能最丰富,最像关系数据库的。支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型。)Cassandra最初由Facebook开发,后转变成了开源项目。它是一个网络社交云计算方面理想的数据库。以Amazon专有的完全分布式的Dynamo为基础,结合了Google BigTable基于列族(Column Family)的数据模型。P2P去中心化的存储。很多方面都可以称之为Dynamo 2.0。
功能
Cassandra的主要特点就是它不是一个数据库,而是由一堆数据库节点共同构成的一个分布式网络服务,对Cassandra 的一个写操作,会被复制到其他节点上去,对Cassandra的读操作,也会被路由到某个节点上面去读取。对于一个Cassandra群集来说,扩展性能是比较简单的事情,只管在群集里面添加节点就可以了。
这里有很多理由来选择Cassandra用于您的网站。和其他数据库比较,有三个突出特点:
模式灵活 :使用Cassandra,像文档存储,你不必提前解决记录中的字段。你可以在系统运行时随意的添加或移除字段。这是一个惊人的效率提升,特别是在大型部署上。
真正的可扩展性 :Cassandra是纯粹意义上的水平扩展。为给集群添加更多容量,可以指向另一台电脑。你不必重启任何进程,改变应用查询,或手动迁移任何数据。
多数据中心识别 :你可以调整你的节点布局来避免某一个数据中心起火,一个备用的数据中心将至少有每条记录的完全复制。
一些使Cassandra提高竞争力的其他功能:
范围查询 :如果你不喜欢全部的键值查询,则可以设置键的范围来查询。
列表数据结构 :在混合模式可以将超级列添加到5维。对于每个用户的索引,这是非常方便的。
分布式写操作 :有可以在任何地方任何时间集中读或写任何数据。并且不会有任何单点失败。
应用客户:twitter、facebook等
Cassandra安装:
第一步: 下载Cassandra http://cassandra.apache.org/
第二步:解压缩与配置
将压缩包解压后复制你想安装的目录下,这里我安装在D:/apache-cassandra-0.6.1/目录中

打开conf文件夹,可以对下面的相关配置文件进行配置,也可以使用默认.
你可以根据自己需要更改日志、数据库存放目录等参数
1) 修改conf目录下的log4j.properties文件:
log4j.appender.R.File=D:/apache-cassandra-0.6.1/logs
2) 修改conf目录下的storage-conf.xml文件:
<CommitLogDirectory>D:/apache-cassandra-0.6.1/commitlog</CommitLogDirectory>
<DataFileDirectories>
<DataFileDirectory>D:/apache-cassandra-0.6.1/data</DataFileDirectory>
</DataFileDirectories>
第三步:环境变量的配置
1)如果你的机子没有安装Java,请先下载并配置java的环境变量
2)设置环境变量"我的电脑"--"高级"选项卡--"环境变量"--"系统变量--新增",根据自己cassandra的位置来设置系统变量的值
cassandra 安装在:D:/apache-cassandra-0.6.1

3)免重启激活环境变量
在cmd中键入命令 " set Cassandra_Home=任意字符",这样环境变量可以在不重启的情况下被激活了。
为了确认是否被激活,重新开启新的cmd窗口,记住,一定要新开cmd才可以查看到被激活的环境变量。
你可以在新的cmd窗口中输入"echo %Cassandra_Home%"输出环境变量的值,我们会发现,可以获取到我们设置的值。

每四步: 正式的启动Cassandra服务
同样打开cmd窗口,在cmd窗口中执行D:/apache-cassandra-0.6.1/bin下面的cassandra.bat启动cassandra服务

出现上面的图后表示服务启动成功了,记住,这个cmd的窗口不要关闭,关闭了好像服务就被一起关闭了,接下来客端的连接好像就不行了。
第五步:客户端的连接
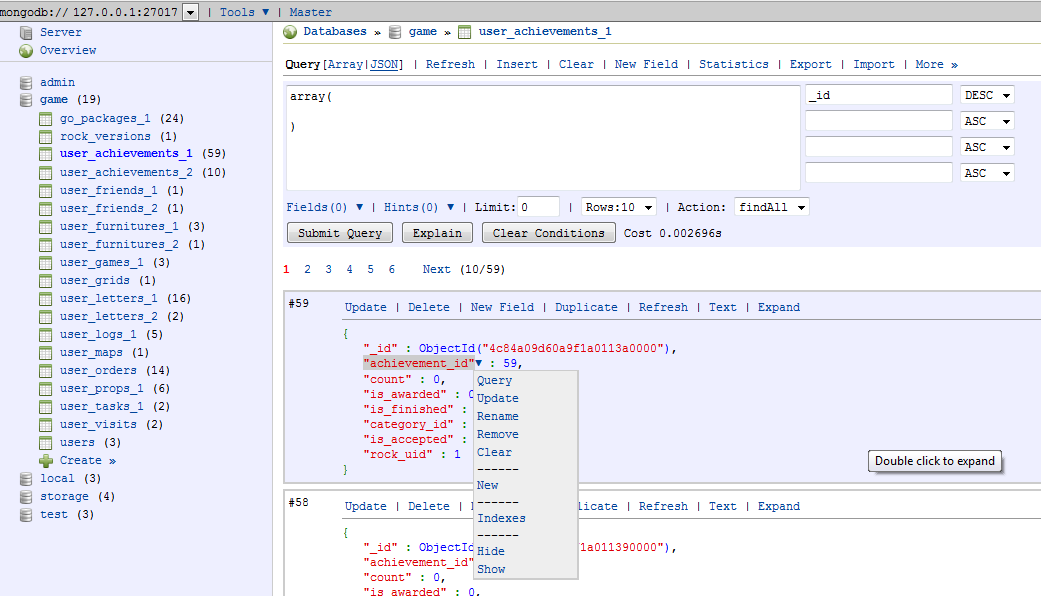
服务启动成功之后,cassandra里面默认有一个测试数据库,访问的方式是在cmd窗口中执行D:/apache-cassandra-0.6.1/bin下面的cassandra-cli.bat批处理文件,然后出现cassandra提示符,在提示符后面输入connect localhost/9160就可以连上默认的数据库。下图是连接成功后的界面。

再接着我们试着插入一条新记录,并读出这条记录的值。
插入的命令是"set"关键字
在命令提示符下输入
" set Keyspace1.Standard1['jsmith']['first']" = 'john'
如果提示"Value inserted"表示插入成功。
同样我们把插入的值读出来,使用的关键字是"get"
“get Keyspace1.Standard1['jsmith']”
如图,我们把刚才插入的数据给读了出来。OK,就介绍到这。下面的东西自己也在摸索。学习中……

其他:cassandra默认使用8080端口,在bin目录下cassandra.bat文件中我们找到 -Dcom.sun.management.jmxremote.port=8080^,如果在你的机子上没有和8080冲突的东西的话,那你可以保留默认的8080,但很多时候会有冲突,比如oracle,tomcat等等,这时候就需要修改下。
Apache Cassandra是一套开源分布式Key-Value存储系统。它最初由Facebook开发,用于储存特别大的数据。
主要特性:分布式、基于column的结构化、高伸展性
Cassandra的主要特点就是它不是一个数据库,而是由一堆数据库节点共同构成的一个分布式网络服务,对Cassandra 的一个写操作,会被复制到其他节点上去,对Cassandra的读操作,也会被路由到某个节点上面去读取。对于一个Cassandra群集来说,扩展性能 是比较简单的事情,只管在群集里面添加节点就可以了。
Cassandra是一个混合型的非关系的数据库,类似于Google的BigTable。其主要功能比 Dynomite(分布式的Key-Value存 储系统)更丰富,但支持度却不如文档存储MongoDB(介于关系数据库和非关系数据库之间的开源产品,是非关系数据库当中功能最丰富,最像关系数据库 的。支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型。)Cassandra最初由Facebook开发,后转变成了开源项目。它是一个网络社交云计算方面理想的数据库。以Amazon专有的完全分布式的Dynamo为基础,结合了Google BigTable基于列族(Column Family)的数据模型。P2P去中心化的存储。很多方面都可以称之为Dynamo 2.0。
和其他数据库比较,有几个突出特点:
模式灵活 :使用Cassandra,像文档存储,你不必提前解决记录中的字段。你可以在系统运行时随意的添加或移除字段。这是一个惊人的效率提升,特别是在大型部署上。
真正的可扩展性 :Cassandra是纯粹意义上的水平扩展。为给集群添加更多容量,可以指向另一台电脑。你不必重启任何进程,改变应用查询,或手动迁移任何数据。
多数据中心识别 :你可以调整你的节点布局来避免某一个数据中心起火,一个备用的数据中心将至少有每条记录的完全复制。
Cassandra 中数据存储策略:
1. CommitLog:主要记录下客户端提交过来的数据以及操作。这个数据将被持久化到磁盘中,以便数据没有被持久化到磁盘时可以用来恢复。数据库中的commit log 分为 undo-log, redo-log 以及 undo-redo-log 三类,由于 cassandra采用时间戳识别新老数据而不会覆盖已有的数据,所以无须使用 undo 操作,因此它的 commit log 使用的是 redo log。
2. Memtable:用户写的数据在内存中的形式,Memtable中的数据是按照key排序好的,Memtable是一种内存结构,满足一定条件后批量刷新(flush)到磁盘上。其实还有另外一种形式是 BinaryMemtable 这个格式目前 Cassandra 并没有使用。
3. SSTable:数据被持久化到磁盘,这又分为 Data、Index 和 Filter 三种数据格式。SSTable一旦完成写入,就不可变更,只能读取。SSTable是不可修改的,且一般情况下一个CF可能会对应多个SSTable,这样,当用户检索数据时,如果每个SSTable均扫描一遍,将大大增加工作量。Cassandra为了减少没有必要的SSTable扫描,使用了BloomFilter,即通过多个hash函数将key映射到一个位图中,来快速判断这个key属于哪个SSTable。为了减少大量SSTable带来的开销,Cassandra会定期进行compaction,简单的说,compaction就是将同一个CF的多个SSTable合并成一个SSTable。
Cassandra 中数据分区策略:
将key/value按照key存放到不同的节点上。Partitioner会按照某种策略给每个cassandra节点分配一个token,每个key/value进行某种计算后,将被分配到器对应的节点上。
提供了以下几个分布策略:
org.apache.cassandra.dht.RandomPartitioner:
将key/value按照(key的)md5值均匀的存放到各个节点上。由于key是无序的,所有该策略无法支持针对Key的范围查询。
org.apache.cassandra.dht.ByteOrderedPartitioner(BOP):
将key/value按照key(byte)排序后存放到各个节点上。该Partitioner允许用户按照key的顺序扫描数据。该方法可能导致负载不均衡。
org.apache.cassandra.dht.OrderPreservingPartitioner:
该策略是一种过时的BOP,仅支持key为UTF8编码的字符串。
org.apache.cassandra.dht.CollatingOrderPreservingPartitioner:
该策略支持在EN或者US环境下的key排序方式。
Cassandra 中备份策略:
为了保证可靠性,一般要将数据写N份,其中一份写在其对应的节点上(由数据分片策略决定),另外N-1份如何存放,需要有相应的备份策略。
SimpleStrategy (以前称为RackUnawareStrategy,对应org.apache.cassandra.locator.RackUnawareStrategy):
不考虑数据中心,将Token按照从小到大的顺序,从第一个Token位置处依次取N个节点作为副本。
OldNetworkTopologyStrategy (以前称为RackAwareStrategy,对应org.apache.cassandra.locator.RackAwareStrategy):
考虑数据中心,首先,在primary Token所在的数据中心的不同rack上存储N-1份数据,然后在另外一个不同数据中心的节点存储一份数据。该策略特别适合多个数据中心的应用场景,这样可以牺牲部分性能(数据延迟)的前提下,提高系统可靠性。
NetworkTopologyStrategy (以前称为DatacenterShardStrategy,对应org.apache.cassandra.locator.DataCenterShardStrategy):
这需要复制策略属性文件,在该文件中定义在每个数据中心的副本数量。在各数据中心副本数量的总和应等于Keyspace的副本数量。
Cassandra 中网络拓扑策略:
主要用于计算不同host的相对距离,进而告诉Cassandra你的网络拓扑结构,以便更高效地对用户请求进行路由。
org.apache.cassandra.locator.SimpleSnitch:
将不同host逻辑上的距离(cassandra ring)作为他们之间的相对距离。
org.apache.cassandra.locator.RackInferringSnitch:
相对距离是由rack和data center决定的,分别对应ip的第3和第2个八位组。即,如果两个节点的ip的前3个八位组相同,则认为它们在同一个rack(同一个rack中不同节点,距离相同);如果两个节点的ip的前两个八位组相同,则认为它们在同一个数据中心(同一个data center中不同节点,距离相同)。
org.apache.cassandra.locator.PropertyFileSnitch:
相对距离是由rack和data center决定的,且它们是在配置文件cassandra-topology.properties中设置的。
Cassandra 中一致性策略:
Cassandra采用了最终一致性。最终一致性是指分布式系统中的一个数据对象的多个副本尽管在短时间内可能出现不一致,但是经过一段时间之后,这些副本最终会达到一致。
Cassandra 的一个特性是可以让用户指定每个读/插入/删除操作的一致性级别(consistency level)。Casssandra API 目前支持以下几种一致性级别:
ZERO:只对插入或者删除操作有意义。负责执行操作的节点把该修改发送给所有的备份节点,但是不会等待任何一个节点回复确认,因此不能保证任何的一致性。
ONE:对于插入或者删除操作,执行节点保证该修改已经写到一个存储节点的 commit log 和 Memtable 中;对于读操作,执行节点在获得一个存储节点上的数据之后立即返回结果。
QUORUM:假设该数据对象的备份节点数目为 n。对于插入或者删除操作,保证至少写到 n/2+1 个存储节点上;对于读操作,向 n/2+1 个存储节点查询,并返回时间戳最新的数据。
ALL:对于插入或者删除操作,执行节点保证n(n为replication factor)个节点插入或者删除成功后才向client返回成功确认消息,任何一个节点没有成功,该操作均失败;对于读操作,会向n个节点查询,返回时间戳最新的数据,同样,如果某个节点没有返回数据,则认为读失败。
Cassandra默认的读写模式W(QUORUM)/R(QUORUM),事实上,只要保证W+R>N(N为副本数),即写的节点和读的节点重叠,则是强一致性. 如果W+R<=N ,则是弱一致性.(其中,W是写节点数目,R是读节点数目)。
Cassandra 通过4个技术来维护数据的最终一致性,分别为逆熵(Anti-Entropy),读修复(Read Repair),提示移交(Hinted Handoff)和分布式删除。
(1) 逆熵
这是一种备份之间的同步机制。节点之间定期互相检查数据对象的一致性,这里采用的检查不一致的方法是 Merkle Tree;
(2) 读修复
客户端读取某个对象的时候,触发对该对象的一致性检查;
举例:读取Key A的数据时,系统会读取Key A的所有数据副本,如果发现有不一致,则进行一致性修复。
如果读一致性要求为ONE,会立即返回离客户端最近的一份数据副本。然后会在后台执行Read Repair。这意味着第一次读取到的数据可能不是最新的数据;如果读一致性要求为QUORUM,则会在读取超过半数的一致性的副本后返回一份副本给客户端,剩余节点的一致性检查和修复则在后台执行;如果读一致性要求高(ALL),则只有Read Repair完成后才能返回一致性的一份数据副本给客户端。可见,该机制有利于减少最终一致的时间窗口。
(3) 提示移交
对写操作,如果其中一个目标节点不在线,先将该对象中继到另一个节点上,中继节点等目标节点上线再把对象给它;
举例:Key A按照规则首要写入节点为N1,然后复制到N2。假如N1宕机,如果写入N2能满足ConsistencyLevel要求,则Key A对应的RowMutation将封装一个带hint信息的头部(包含了目标为N1的信息),然后随机写入一个节点N3,此副本不可读。同时正常复制一份数据到N2,此副本可以提供读。如果写N2不满足写一致性要求,则写会失败。 等到N1恢复后,原本应该写入N1的带hint头的信息将重新写回N1。
(4) 分布式删除
单机删除非常简单,只需要把数据直接从磁盘上去掉即可,而对于分布式,则不同,分布式删除的难点在于:如果某对象的一个备份节点 A 当前不在线,而其他备份节点删除了该对象,那么等 A 再次上线时,它并不知道该数据已被删除,所以会尝试恢复其他备份节点上的这个对象,这使得删除操作无效。Cassandra 的解决方案是:本地并不立即删除一个数据对象,而是给该对象标记一个hint,定期对标记了hint的对象进行垃圾回收。在垃圾回收之前,hint一直存在,这使得其他节点可以有机会由其他几个一致性保证机制得到这个hint。Cassandra 通过将删除操作转化为一个插入操作,巧妙地解决了这个问题。
Cassandra引入的是轻量级事务处理机制,或者说是通过CAS(Compare And Set)来处理或满足最终的一致性。比如在INSERT、UPDATE中使用IF语义来调用这种轻量级事务:
INSERT INTO customer_account (customerID, customer_email)
VALUES (‘LauraS’, ‘lauras@gmail.com’)
IF NOT EXISTS;
UPDATE customer_account
SET customer_email='laurass@gmail.com'
IF customer_email='lauras@gmail.com';