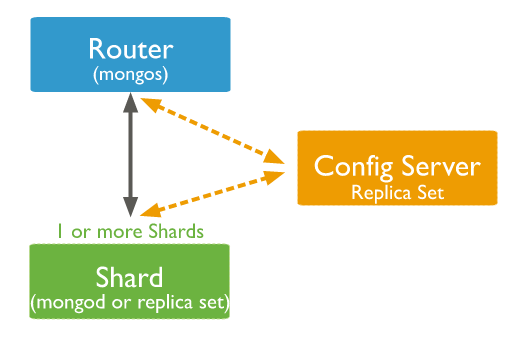
前言
本文参照互联网上一篇文章进行实际操作, 但是在搭建elk平台过程中, 采用docker方式进行, 因此节省了部属的繁琐过程,因此把基于docker的操作过程, 穿插到原文中。
为了, 获取一个docker环境, 取决于您的操作系统, 对于linux本身大部分新版本的都支持docker了, 对于windows和mac os系统, 您需要安装一定的虚拟机, 或者docker tools(其实也是虚拟机,只是操作方便)。
这里是在windows上安装了vmware, 然后在vm中安装了centos系统, 然后在centos7中安装了docker系统
ELK(ElasticSearch, Logstash, Kibana)平台恰好可以同时实现日志收集、日志搜索和日志分析的功能
ELK平台介绍
在搜索ELK资料的时候,发现这篇文章比较好,于是摘抄一小段:
以下内容来自:http://baidu.blog.51cto.com/71938/1676798
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
通常,日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
开源实时日志分析ELK平台能够完美的解决我们上述的问题,ELK由ElasticSearch、Logstash和Kiabana三个开源工具组成。官方网站:https://www.elastic.co/products
- Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
- Logstash是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用(如,搜索)。
- Kibana 也是一个开源和免费的工具,它Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
画了一个ELK工作的原理图:
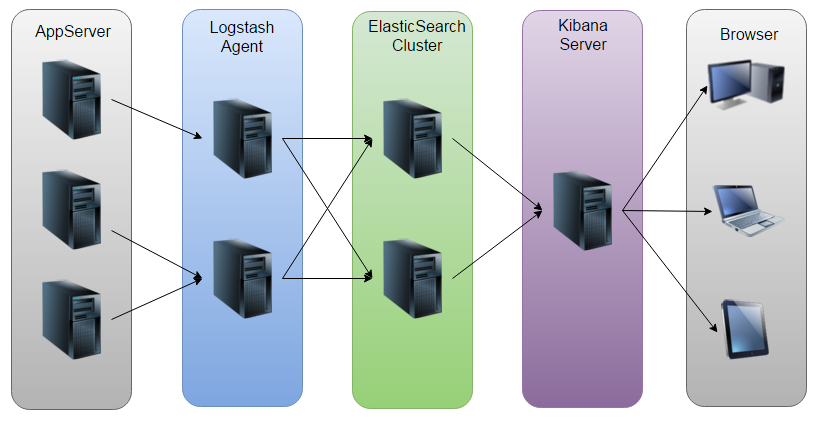
如图:Logstash收集AppServer产生的Log,并存放到ElasticSearch集群中,而Kibana则从ES集群中查询数据生成图表,再返回给Browser。
准备elk环境
首先您要搭建好您的docker环境, 然后按照下面的步骤进行操作
1. 下载elk的 镜像
执行下面的命令下载相关的docker镜像 docker pull qnib/elk
由于网络原因, 这个镜像下载的比较慢, 建议找个合适时间下载备用。这个没办法解决, 或者自己翻墙解决吧。
2. 安装docker-compose程序
由于本程序需要 docker-compose 软件, 因此我们需要安装这个软件
安装文档在https://docs.docker.com/compose/install/中,
文档中,有几种安装方法,基本都是下载文件进行安装, 本文采用docker的方式安装它, 其实就是, 下载一个docker镜像, 然后在有一个配合的shell程序, 运行是shell程序, 将相关内容转发到容器里面进行运行等, 相关安装方法如下:
$ curl -L --fail https://github.com/docker/compose/releases/download/1.13.0/run.sh > /usr/local/bin/docker-compose
上面命令其实, 就是先用curl下载文件, 然后, 将下载内容从定向到一个文件中。
$ sudo chmod +x /usr/local/bin/docker-compose 然后修改下载后文件的可执行属性。
由于翻墙的原因, 直接下载可能下载不了, 因此可以先翻墙下载脚本,然后将内容从命名后, 直接拷贝到目标文件处, 然后在修改文件的属性就完成了。
3. 下载 elk的服务配置文件
打开页面https://github.com/ChristianKniep/docker-elk, 选择下载master文件
由于需要翻墙, 因此把下载好的, 放到这里(这个文件比较小就放了, 其他的太大, 没空间, 抱歉)docker-elk-master
其实我们就是需要里面的一个文件, docker-compose.yml
4. 获取本机的ip地址, 然后根据您的喜好可以选择给本机设置一个合适的名称,在hosts文件中, 这样就不需要直接使用ip地址了, 当然使用ip地址也可以。
5. 解压下载回来的zip文件, 提取docker-compose.yml文件, 并将这个文件拷贝到vm的centos中
6. 在centos中 打开文件 vi docker-compose.yml 在文件最后添加如下配置
[root@localhost elk]# cat docker-compose.yml
elk:
image: qnib/elk
ports:
- "9200:9200"
- "5514:5514"
- "55514:55514/udp"
- "5601:5601"
- "8080:80"
- "8500:8500"
environment:
- DC_NAME=dc1
- RUN_SERVER=true
- BOOTSTRAP_CONSUL=true
- COLLECT_METRICS=false
- FORWARD_TO_LOGSTASH=false
dns: 127.0.0.1
hostname: elk
volumes:
- /var/lib/elasticsearch
privileged: true
extra_hosts:
- "myelk:192.168.128.189"
- "otherhost:50.31.209.229"
请注意红色字体部分, 是原来文件中没有的, 是新添加家的, 这个两个 设置是在 启动docker服务时, 在容器内部的hosts文件中添加相关配置的设置, 因此请根据您的配置和ip地址灵活处理。
注意, 由于是yml文件, 空格是有含义的, 拷贝要带空格拷贝, 否则不工作啦!!
6. 运行 docker-compose up 编译并启动程序
在包括docker-compose.yml 文件的目录中, 运行 docker-compose up 命令, 启动这程序, 然后就基本安装完成了, 然后就可以参照后面的步骤慢慢调整这个系统了。
ELK平台搭建
系统环境
System: Centos release 6.7 (Final)
ElasticSearch: 2.1.0
Logstash: 2.1.1
Kibana: 4.3.0
Java: openjdk version "1.8.0_65"
注:由于Logstash的运行依赖于Java环境, 而Logstash 1.5以上版本不低于java 1.7,因此推荐使用最新版本的Java。因为我们只需要Java的运行环境,所以可以只安装JRE,不过这里我依然使用JDK,请自行搜索安装。
ELK下载:https://www.elastic.co/downloads/
ElasticSearch
配置ElasticSearch:
以下是原文的安装方法, 由于我们本次采用了, docker的方式, 因此这些都省了, 但是作为文档保留, 以后需要手动安装,时参考。
tar -zxvf elasticsearch-2.1.0.tar.gz
cd elasticsearch-2.1.0安装Head插件(Optional):
这个插件可以安装也可以不安装, 不影响后面演示, 只是查看es中数据等, 方便些(若是安装), 另外直接下载不方便, 还是翻墙下载, 然后拷贝到插件目录中为好。
./bin/plugin install mobz/elasticsearch-head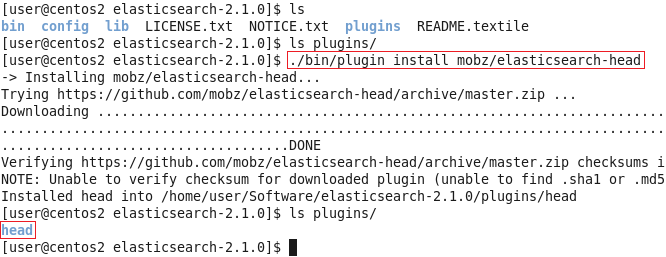
然后编辑ES的配置文件:
vi config/elasticsearch.yml修改以下配置项:
以下配置项目在docker中也是配置好的, 基本不需要修改
cluster.name=es_cluster
node.name=node0
path.data=/tmp/elasticsearch/data
path.logs=/tmp/elasticsearch/logs
#当前hostname或IP,我这里是centos2
network.host=centos2
network.port=9200其他的选项保持默认,然后启动ES:
./bin/elasticsearch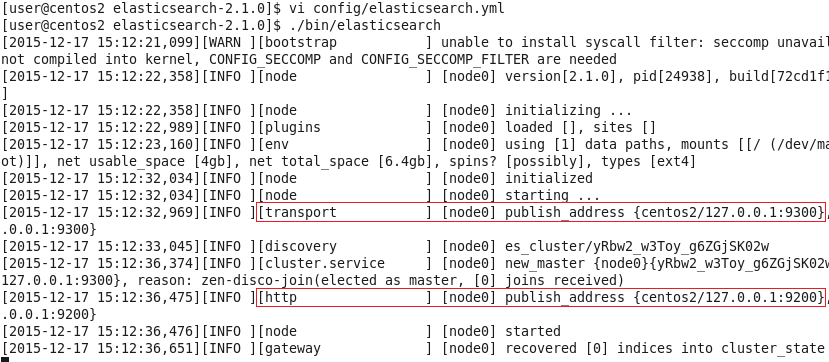
可以看到,它跟其他的节点的传输端口为9300,接受HTTP请求的端口为9200。
使用ctrl+C停止。当然,也可以使用后台进程的方式启动ES:
./bin/elasticsearch &然后可以打开页面localhost:9200,将会看到以下内容:
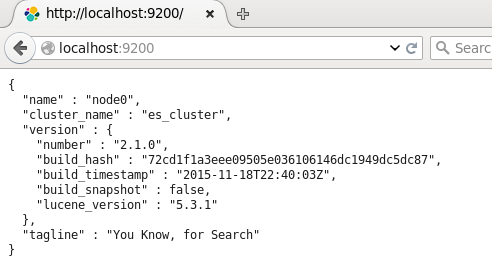
返回展示了配置的cluster_name和name,以及安装的ES的版本等信息。
刚刚安装的head插件,它是一个用浏览器跟ES集群交互的插件,可以查看集群状态、集群的doc内容、执行搜索和普通的Rest请求等。现在也可以使用它打开localhost:9200/_plugin/head页面来查看ES集群状态:

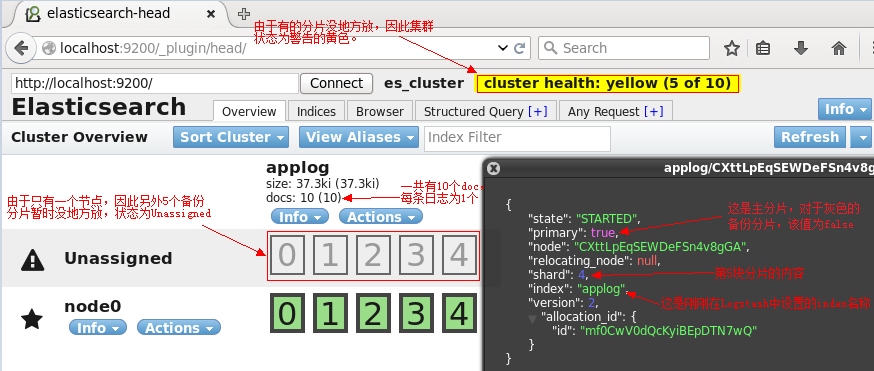
可以看到,现在,ES集群中没有index,也没有type,因此这两条是空的。
Logstash
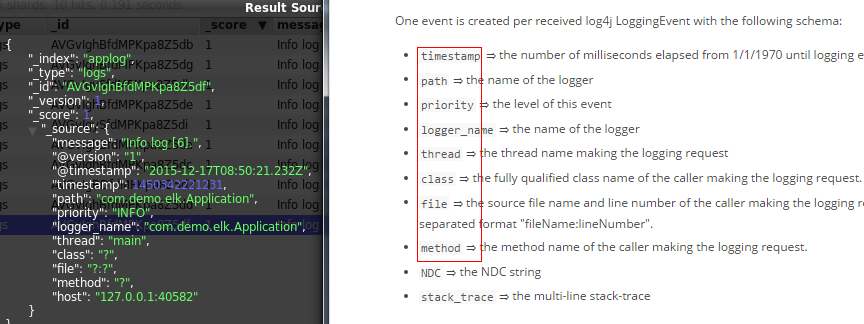
Logstash的功能如下:
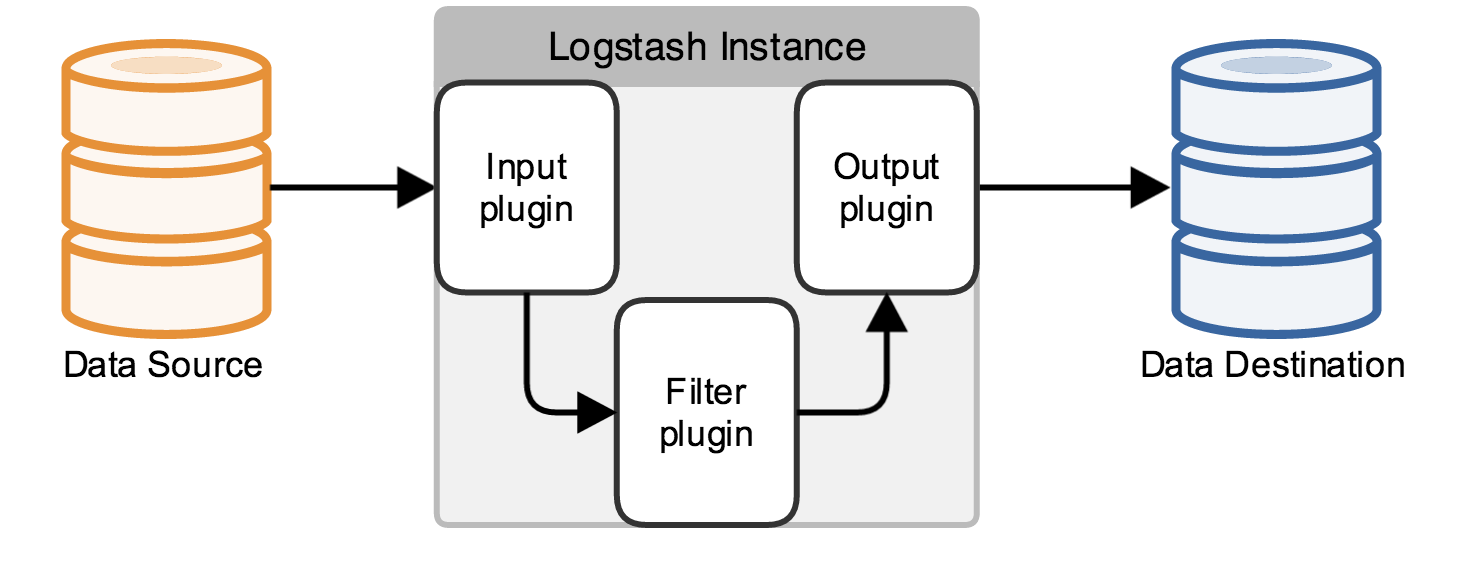
其实它就是一个收集器而已,我们需要为它指定Input和Output(当然Input和Output可以为多个)。由于我们需要把Java代码中Log4j的日志输出到ElasticSearch中,因此这里的Input就是Log4j,而Output就是ElasticSearch。
配置Logstash:
tar -zxvf logstash-2.1.1.tar.gz
cd logstash-2.1.1编写配置文件(名字和位置可以随意,这里我放在config目录下,取名为log4j_to_es.conf):
---------------------
两个---中间的部分是我们的操作, 其他的是原文的操作, 提供参考的
1. 首先用xshell登录centos中
2. 采用docker ps查看那个docker容器在工作
经过查看
[root@localhost elk]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
78a0f3a1b8f6 qnib/elk "/opt/qnib/bin/start_" 17 hours ago Up 17 hours 0.0.0.0:5514->5514/tcp, 0.0.0.0:5601->5601/tcp, 0.0.0.0:8500->8500/tcp, 0.0.0.0:9200->9200/tcp, 0.0.0.0:55514->55514/udp, 0.0.0.0:8080->80/tcp elk_elk_1
上面容器id是 78a0f3a1b8f6
3. 执行 docker exec -t -i 78a0f3a1b8f6 /bin/bash 进入容器内部进行操作, 其中红色部分, 请根据您的容器id进行替换
4. 进入容器内部后, 执行 ps -ef 获取全部的进程信息
[root@elk opt]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 May30 ? 00:00:00 /bin/bash /opt/qnib/bin/start_supervisor.sh -n
root 9 1 0 May30 ? 00:03:00 /usr/bin/python /usr/bin/supervisord -n -c /etc/supervisord.conf
root 12 9 2 May30 ? 00:25:54 /usr/lib/jvm/jre-1.8.0/bin/java -Xms2g -Xmx2g -Djava.awt.headless=true -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFract
root 13 9 0 May30 ? 00:01:17 /bin/bash /opt/qnib/bin/start_logstash.sh
root 14 9 0 May30 ? 00:00:54 statsd
采用ps -ef | grep logstash | grep agent
[root@elk opt]# ps -ef | grep logstash | grep agent
root 268 9 1 May30 ? 00:16:16 /usr/lib/jvm/jre-1.8.0/bin/java -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -Djava.awt.headless=true -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -Xmx500m -Xss2048k -Djffi.boot.library.path=/opt/logstash/vendor/jruby/lib/jni -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -Djava.awt.headless=true -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -Xbootclasspath/a:/opt/logstash/vendor/jruby/lib/jruby.jar -classpath : -Djruby.home=/opt/logstash/vendor/jruby -Djruby.lib=/opt/logstash/vendor/jruby/lib -Djruby.script=jruby -Djruby.shell=/bin/sh org.jruby.Main --1.9 /opt/logstash/lib/bootstrap/environment.rb logstash/runner.rb agent -f /etc/logstash/conf.d/
root 7678 7517 1 May30 ? 00:12:33 /usr/lib/jvm/jre-1.8.0/bin/java -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -Djava.awt.headless=true -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -Xmx500m -Xss2048k -Djffi.boot.library.path=/opt/logstash/vendor/jruby/lib/jni -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -Djava.awt.headless=true -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -Xbootclasspath/a:/opt/logstash/vendor/jruby/lib/jruby.jar -classpath : -Djruby.home=/opt/logstash/vendor/jruby -Djruby.lib=/opt/logstash/vendor/jruby/lib -Djruby.script=jruby -Djruby.shell=/bin/sh org.jruby.Main --1.9 /opt/logstash/lib/bootstrap/environment.rb logstash/runner.rb agent -f /etc/logstash/conf.d/a.conf
[root@elk opt]#
如上图, 红色字体部分
---------------------
mkdir config
vi config/log4j_to_es.conf输入以下内容:
# For detail structure of this file
# Set: https://www.elastic.co/guide/en/logstash/current/configuration-file-structure.html
input {
# For detail config for log4j as input,
# See: https://www.elastic.co/guide/en/logstash/current/plugins-inputs-log4j.html
log4j {
mode => "server"
host => "centos2"
port => 4567
}
}
filter {
#Only matched data are send to output.
}
output {
# For detail config for elasticsearch as output,
# See: https://www.elastic.co/guide/en/logstash/current/plugins-outputs-elasticsearch.html
elasticsearch {
action => "index" #The operation on ES
hosts => "centos2:9200" #ElasticSearch host, can be array.
index => "applog" #The index to write data to.
}
}logstash命令只有2个参数:
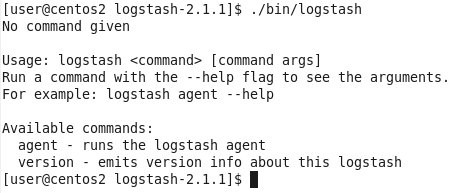
因此使用agent来启动它(使用-f指定配置文件):
./bin/logstash agent -f config/log4j_to_es.conf
到这里,我们已经可以使用Logstash来收集日志并保存到ES中了,下面来看看项目代码。
Java项目
照例先看项目结构图:
pom.xml,很简单,只用到了Log4j库:
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
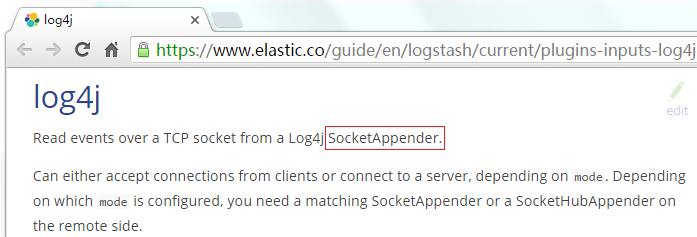
</dependency>log4j.properties,将Log4j的日志输出到SocketAppender,因为官网是这么说的:
log4j.rootLogger=INFO,console
# for package com.demo.elk, log would be sent to socket appender.
log4j.logger.com.demo.elk=DEBUG, socket
# appender socket
log4j.appender.socket=org.apache.log4j.net.SocketAppender
log4j.appender.socket.Port=4567
log4j.appender.socket.RemoteHost=centos2
log4j.appender.socket.layout=org.apache.log4j.PatternLayout
log4j.appender.socket.layout.ConversionPattern=%d [%-5p] [%l] %m%n
log4j.appender.socket.ReconnectionDelay=10000
# appender console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d [%-5p] [%l] %m%n注意:这里的端口号需要跟Logstash监听的端口号一致,这里是4567。
Application.java,使用Log4j的LOGGER打印日志即可:
package com.demo.elk;
import org.apache.log4j.Logger;
public class Application {
private static final Logger LOGGER = Logger.getLogger(Application.class);
public static void main(String[] args) throws Exception {
for (int i = 0; i < 10; i++) {
LOGGER.error("Info log [" + i + "].");
Thread.sleep(500);
}
}
}用Head插件查看ES状态和内容
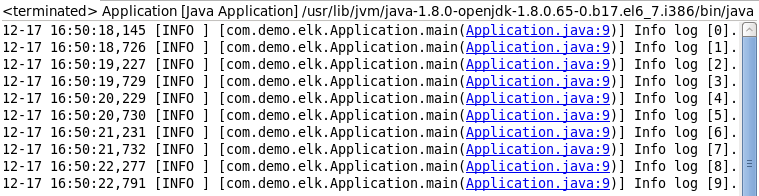
运行Application.java,先看看console的输出(当然,这个输出只是为了做验证,不输出到console也可以的):
再来看看ES的head页面:
切换到Browser标签:
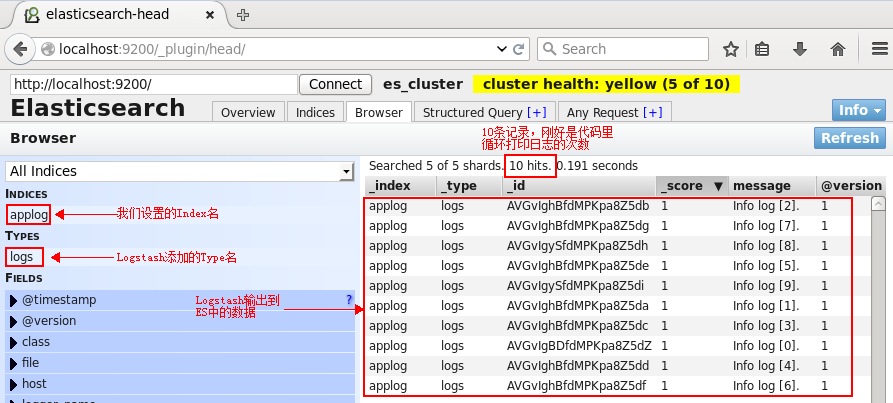
单击某一个文档(doc),则会展示该文档的所有信息:
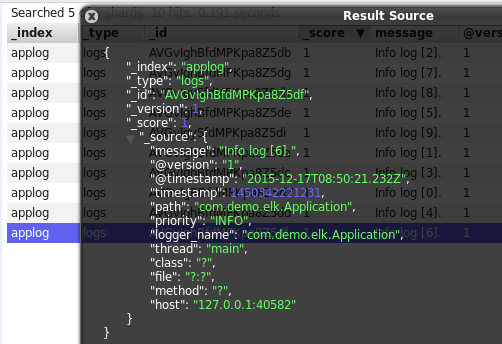
可以看到,除了基础的message字段是我们的日志内容,Logstash还为我们增加了许多字段。而在https://www.elastic.co/guide/en/logstash/current/plugins-inputs-log4j.html中也明确说明了这一点:
上面使用了ES的Head插件观察了ES集群的状态和数据,但这只是个简单的用于跟ES交互的页面而已,并不能生成报表或者图表什么的,接下来使用Kibana来执行搜索并生成图表。
Kibana
配置Kibana:
tar -zxvf kibana-4.3.0-linux-x86.tar.gz
cd kibana-4.3.0-linux-x86
vi config/kibana.yml修改以下几项(由于是单机版的,因此host的值也可以使用localhost来代替,这里仅仅作为演示):
server.port: 5601
server.host: “centos2”
elasticsearch.url: http://centos2:9200
kibana.index: “.kibana”启动kibana:
./bin/kibana
用浏览器打开该地址:
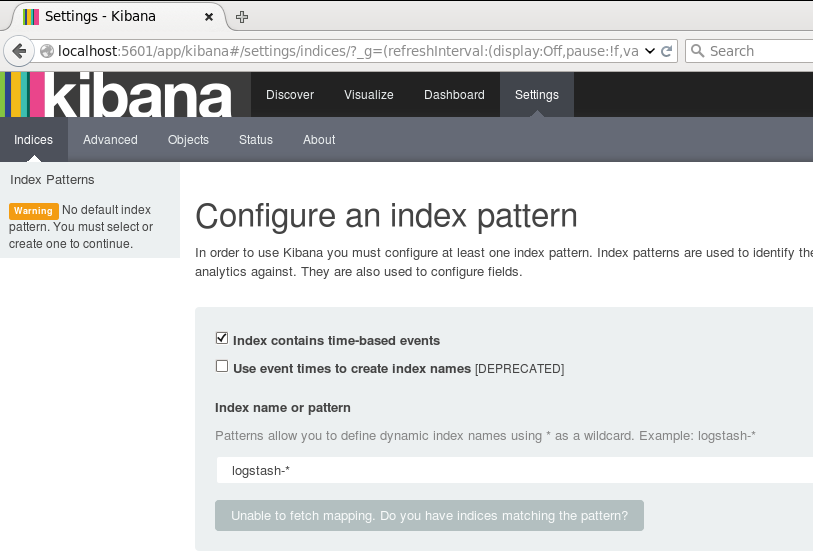
为了后续使用Kibana,需要配置至少一个Index名字或者Pattern,它用于在分析时确定ES中的Index。这里我输入之前配置的Index名字applog,Kibana会自动加载该Index下doc的field,并自动选择合适的field用于图标中的时间字段:
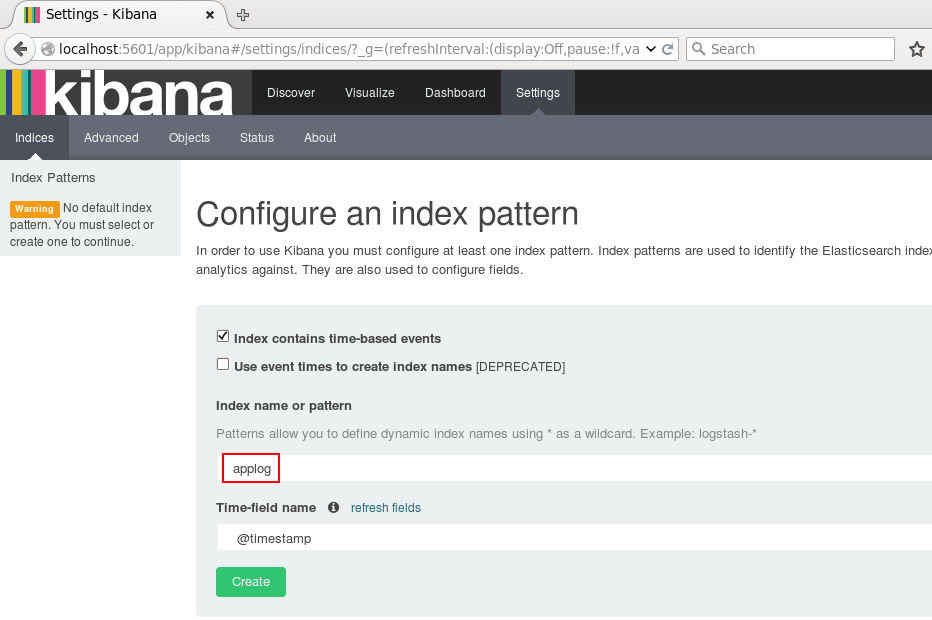
点击Create后,可以看到左侧增加了配置的Index名字:
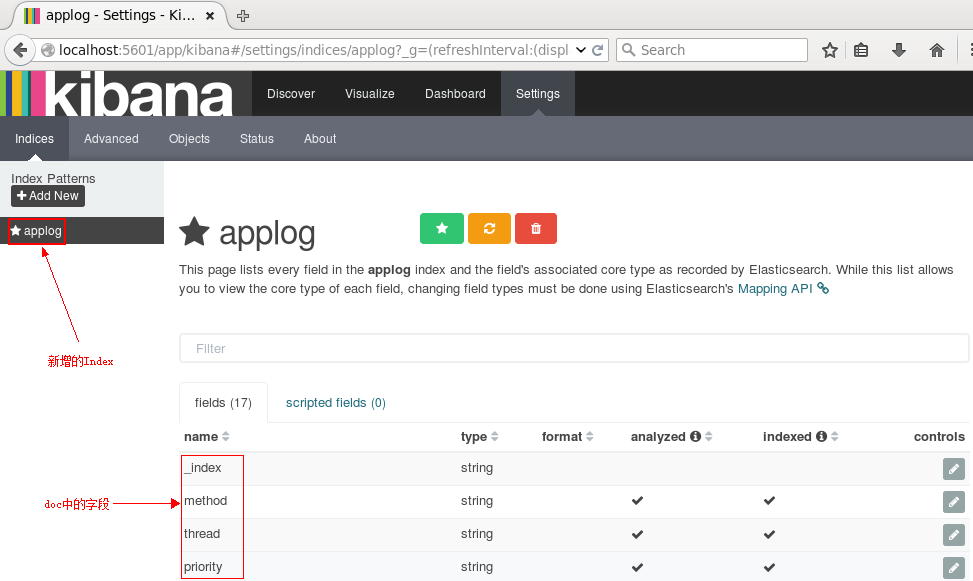
接下来切换到Discover标签上,注意右上角是查询的时间范围,如果没有查找到数据,那么你就可能需要调整这个时间范围了,这里我选择Today:

接下来就能看到ES中的数据了:
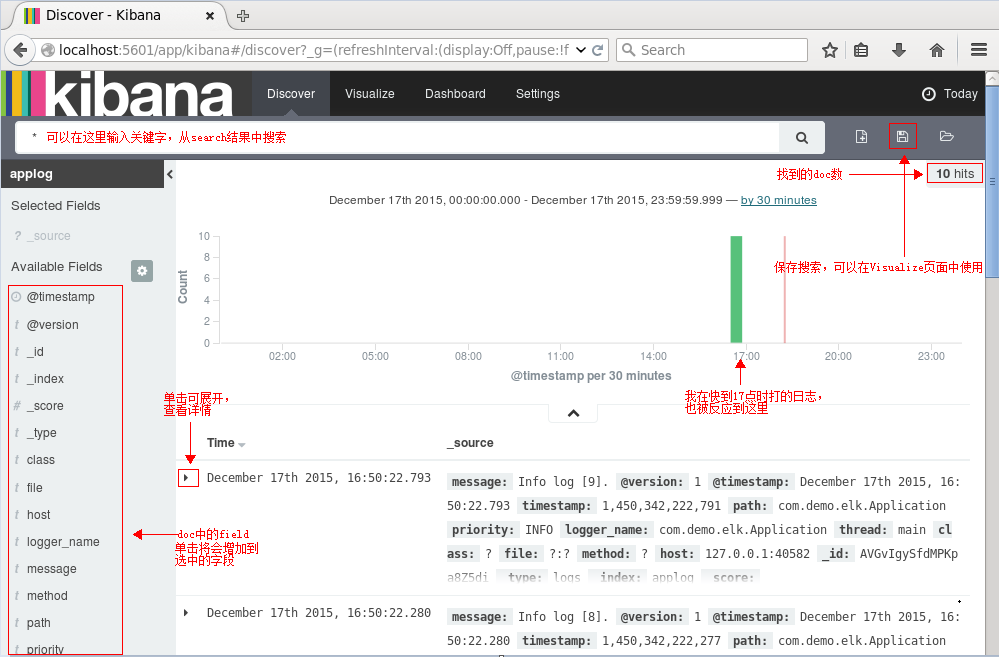
执行搜索看看呢:
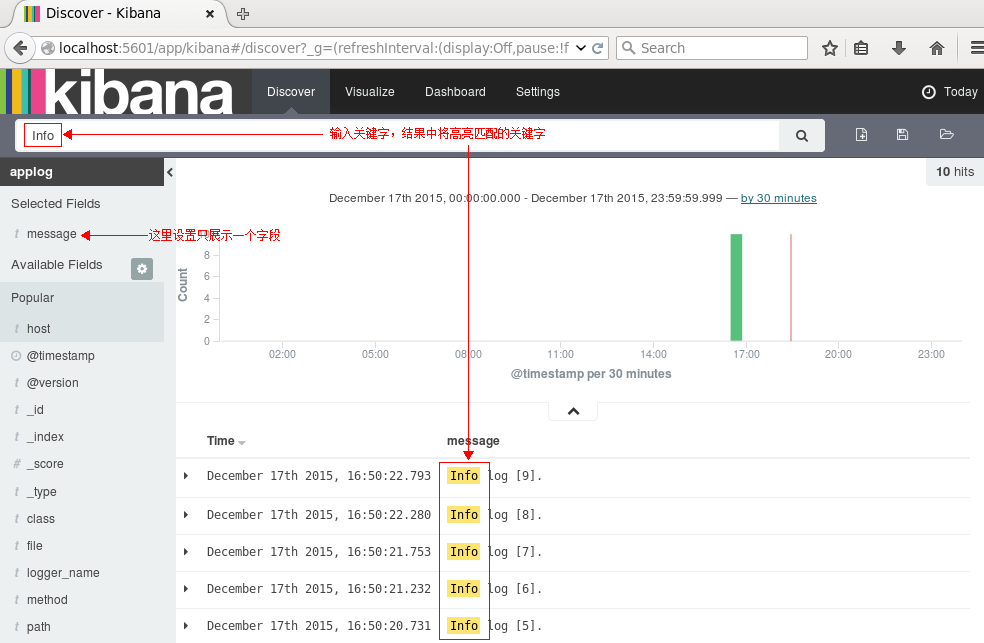
点击右边的保存按钮,保存该查询为search_all_logs。接下来去Visualize页面,点击新建一个柱状图(Vertical Bar Chart),然后选择刚刚保存的查询search_all_logs,之后,Kibana将生成类似于下图的柱状图(只有10条日志,而且是在同一时间段的,比较丑,但足可以说明问题了:) ):
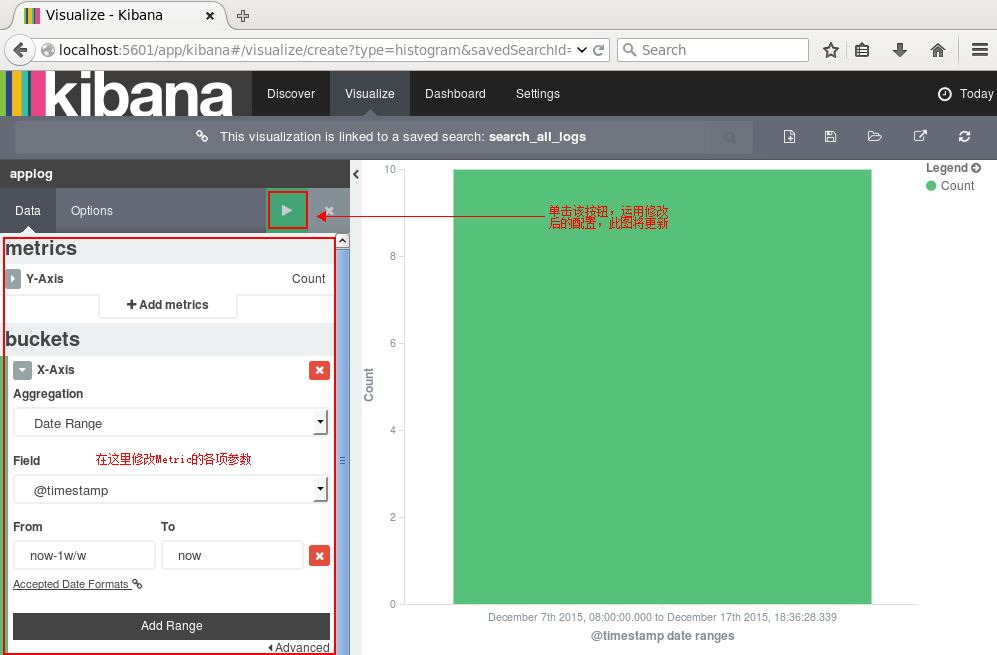
你可以在左边设置图形的各项参数,点击Apply Changes按钮,右边的图形将被更新。同理,其他类型的图形都可以实时更新。
点击右边的保存,保存此图,命名为search_all_logs_visual。接下来切换到Dashboard页面:
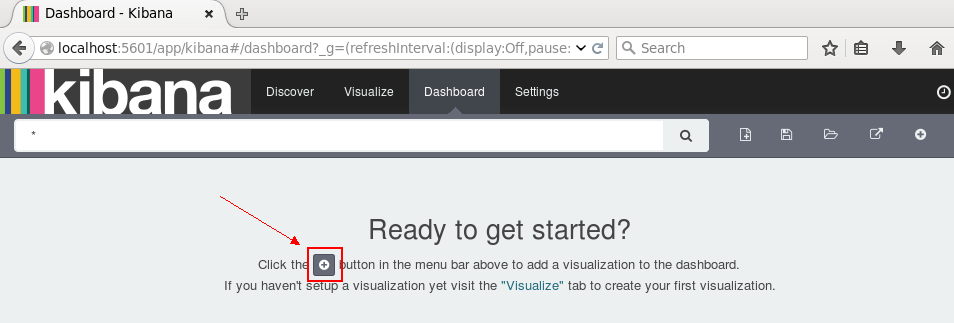
单击新建按钮,选择刚刚保存的search_all_logs_visual图形,面板上将展示该图:
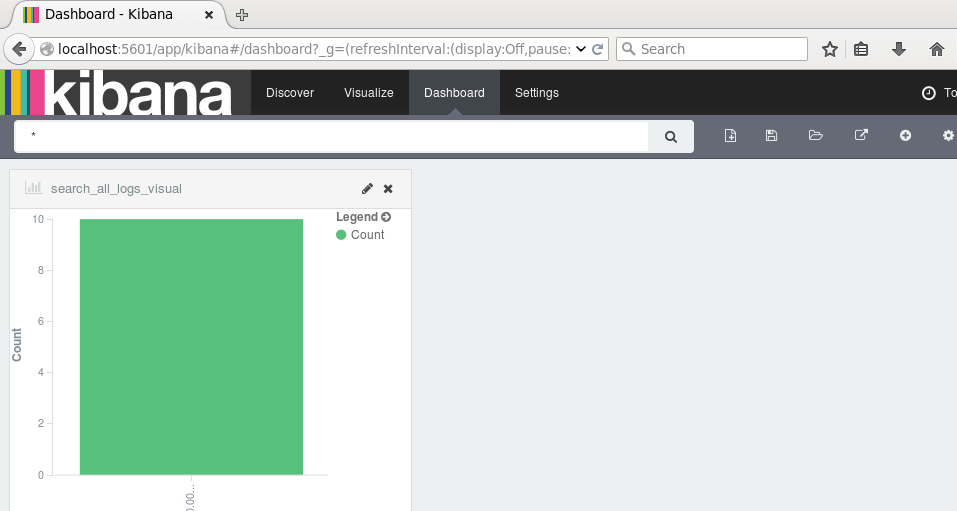
如果有较多数据,我们可以根据业务需求和关注点在Dashboard页面添加多个图表:柱形图,折线图,地图,饼图等等。当然,我们可以设置更新频率,让图表自动更新:
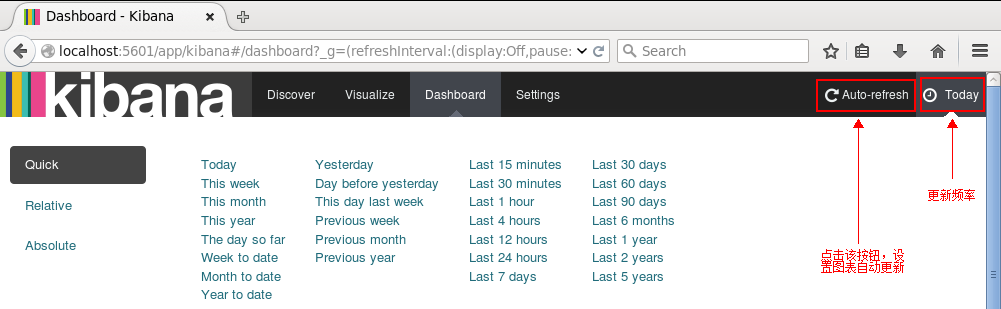
如果设置的时间间隔够短,就很趋近于实时分析了。
到这里,ELK平台部署和基本的测试已完成。