下面是tcc事物的介绍
一个TCC事务框架需要解决的当然是分布式事务的管理。关于TCC事务机制的介绍,可以参考TCC事务机制简介。
TCC事务模型虽然说起来简单,然而要基于TCC实现一个通用的分布式事务框架,却比它看上去要复杂的多,不只是简单的调用一下Confirm/Cancel业务就可以了的。
下文将以Spring容器为例,试图分析一下,实现一个通用的TCC分布式事务框架需要注意的一些问题。
一、TCC全局事务必须基于RM本地事务来实现全局事务
TCC服务是由Try/Confirm/Cancel业务构成的,其Try/Confirm/Cancel业务在执行时,会访问资源管理器(Resource Manager,下文简称RM)来存取数据。这些存取操作,必须要参与RM本地事务,以使其更改的数据要么全部commit,要么全部rollback。
这一点不难理解,考虑一下如下场景:
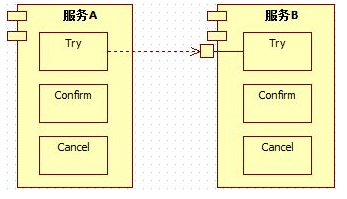
假设图中的服务B没有基于RM本地事务(以RDBS为例,可通过设置auto-commit为true来模拟),那么一旦[B:Try]操作中途执行出错,TCC事务框架后续决定回滚全局事务时,该[B:Cancel]则需要判断[B:Try]中哪些操作已经写到DB、哪些操作还没有写到DB:如果[B:Try]业务有5个写库操作,[B:Cancel]业务则需要逐个判断这5个操作是否生效,并将生效的操作执行反向操作。
不幸的是,由于[B:Cancel]业务也有n(0<=n<=5)个反向的写库操作,此时一旦[B:Cancel]也中途出错,则后续的[B:Cancel]执行任务更加繁重。因为,相比第一次[B:Cancel]操作,后续的[B:Cancel]操作还需要判断先前的[B:Cancel]操作的n(0<=n<=5)个写库中哪几个已经执行、哪几个还没有执行,这就涉及到了幂等性问题。
然而,对幂等性的保障,很可能也需要涉及额外的写库操作,该写库操作又会因为没有RM本地事务的支持而存在类似问题。。。
可想而知,如果不基于RM本地事务,TCC事务框架是无法有效的管理TCC全局事务的。
反之,基于RM本地事务的TCC事务,这种情况则会很容易处理:[B:Try]操作中途执行失败,TCC事务框架将其参与RM本地事务直接rollback即可。后续TCC事务框架决定回滚全局事务时,在知道“[B:Try]操作涉及的RM本地事务已经rollback”的情况下,根本无需执行[B:Cancel]操作。
换句话说,基于RM本地事务实现TCC事务框架时,一个TCC型服务的Cancel业务要么执行,要么不执行,不需要考虑部分执行的情况。
二、TCC事务框架应该接管Spring容器的TransactionManager
基于RM本地事务的TCC事务框架,可以将各Try/Confirm/Cancel业务看着一个原子服务:一个RM本地事务提交,参与该RM本地事务的所有Try/Confirm/Cancel业务操作都生效;反之,则都不生效。
掌握每个RM本地事务的状态以及它们与Try/Confirm/Cancel业务方法之间的对应关系,以此为基础,TCC事务框架才能有效的构建TCC全局事务。
TCC服务的Try/Confirm/Cancel业务方法在RM上的数据存取操作,其RM本地事务是由Spring容器的PlatformTransactionManager来commit/rollback的,TCC事务框架想要了解RM本地事务的状态,只能通过接管Spring的事务管理器功能。
2.1. 为什么TCC事务框架需要掌握RM本地事务的状态?
首先,根据TCC机制的定义,TCC事务是通过执行Cancel业务来达到回滚效果的。仔细分析一下,这里暗含一个事实:只有生效的Try业务操作才需要执行对应的Cancel业务操作。换句话说,只有Try业务操作所参与的RM本地事务被commit了,后续TCC全局事务回滚时才需要执行其对应的Cancel业务操作;否则,如果Try业务操作所参与的RM本地事务被rollback了,后续TCC全局事务回滚时就不能执行其Cancel业务,此时若盲目执行Cancel业务反而会导致数据不一致。
其次,Confirm/Cancel业务操作必须保证生效。Confirm/Cancel业务操作也会涉及RM数据存取操作,其参与的RM本地事务也必须被commit。TCC事务框架需要在确切的知道所有Confirm/Cancel业务操作参与的RM本地事务都被成功commit后,才能将标记该TCC全局事务为完成。如果TCC事务框架误判了Confirm/Cancel业务参与RM本地事务的状态,就会造成全局事务不一致。
最后,未完成的TCC全局,TCC事务框架必须重新尝试提交/回滚操作。重试时会再次调用各TCC服务的Confirm/Cancel业务方法。如果某个服务的Confirm/Cancel业务之前已经生效(其参与的RM本地事务已经提交),重试时就不应该再次被调用。否则,其Confirm/Cancel业务方法被多次调用,就会有“服务幂等性”的问题。
2.2. 拦截TCC服务的Try/Confirm/Cancel业务方法的执行,根据其异常信息可否知道其RM本地事务是否commit/rollback了呢?
基本上很难做到。为什么这么说呢?
第一,事务是可以在多个(本地/远程)服务之间互相传播其事务上下文的,一个业务方法(Try/Confirm/Cancel)执行完毕并不一定会触发当前事务的commit/rollback操作。比如,被传播事务上下文的业务方法,在它开始执行时,容器并不会为其创建新的事务,而是它的调用方参与的事务,使得二者操作在同一个事务中;同样,在它执行完毕时,容器也不会提交/回滚它参与的事务的。因此,这类业务方法上的异常情况并不能反映他们是否生效。不接管Spring的TransactionManager,就无法了解事务于何时被创建,也无法了解它于何时被提交/回滚。
第二、一个业务方法可能会包含多个RM本地事务。比如:A(REQUIRED)->B(REQUIRES_NEW)->C(REQUIRED),这种情况下,A服务所参与的RM本地事务被提交时,B服务和C服务参与的RM本地事务则可能会被回滚。
第三、并不是抛出了异常的业务方法,其参与的事务就回滚了。Spring容器的声明式事务定义了两类异常,其事务完成方向都不一样:系统异常(一般为Unchecked异常,默认事务完成方向是rollback)、应用异常(一般为Checked异常,默认事务完成方向是commit)。二者的事务完成方向又可以通过@Transactional配置显式的指定,如rollbackFor/noRollbackFor等。
第四、Spring容器还支持使用setRollbackOnly的方式显式的控制事务完成方向;
最后、自行拦截业务方法的拦截器和Spring的事务处理的拦截器还会存在执行先后、拦截范围不同等问题。例如,如果自行拦截器执行在前,就会出现业务方法虽然已经执行完毕但此时其参与的RM本地事务还没有commit/rollback。
TCC事务框架的定位应该是一个TransactionManager,其职责是负责commit/rollback事务。而一个事务应该被commit还是被rollback,则应该是由Spring容器来决定的:Spring决定提交事务时,会调用TransactionManager来完成commit操作;Spring决定回滚事务时,会调用TransactionManager来完成rollback操作。
接管Spring容器的TransactionManager,TCC事务框架可以明确的得到Spring的事务性指令,并管理Spring容器中各服务的RM本地事务。否则,如果通过自行拦截的机制,则使得业务系统存在TCC事务处理、RM本地事务处理两套事务处理逻辑,二者互不通信,各行其是。这种情况下要协调TCC全局事务,基本上可以说是缘木求鱼,本地事务尚且无法管理,更何谈管理分布式事务?
三、TCC事务框架应该具备故障恢复机制
一个TCC事务框架,若是没有故障恢复的保障,是不成其为分布式事务框架的。
分布式事务管理框架的职责,不是做出全局事务提交/回滚的指令,而是管理全局事务提交/回滚的过程。它需要能够协调多个RM资源、多个节点的分支事务,保证它们按全局事务的完成方向各自完成自己的分支事务。
这一点,是不容易做到的。因为,实际应用中,会有各种故障出现,很多都会造成事务的中断,从而使得统一提交/回滚全局事务的目标不能达到,甚至出现”一部分分支事务已经提交,而另一部分分支事务则已回滚”的情况。
比较常见的故障,比如:业务系统服务器宕机、重启;数据库服务器宕机、重启;网络故障;断电等。这些故障可能单独发生,也可能会同时发生。作为分布式事务框架,应该具备相应的故障恢复机制,无视这些故障的影响是不负责任的做法。
一个完整的分布式事务框架,应该保障即使在最严苛的条件下也能保证全局事务的一致性,而不是只能在最理想的环境下才能提供这种保障。退一步说,如果能有所谓“理想的环境”,那也无需使用分布式事务了。
TCC事务框架要支持故障恢复,就必须记录相应的事务日志。事务日志是故障恢复的基础和前提,它记录了事务的各项数据。TCC事务框架做故障恢复时,可以根据事务日志的数据将中断的事务恢复至正确的状态,并在此基础上继续执行先前未完成的提交/回滚操作。
四、TCC事务框架应该提供Confirm/Cancel服务的幂等性保障
一般认为,服务的幂等性,是指针对同一个服务的多次(n>1)请求和对它的单次(n=1)请求,二者具有相同的副作用。
在TCC事务模型中,Confirm/Cancel业务可能会被重复调用,其原因很多。比如,全局事务在提交/回滚时会调用各TCC服务的Confirm/Cancel业务逻辑。执行这些Confirm/Cancel业务时,可能会出现如网络中断的故障而使得全局事务不能完成。因此,故障恢复机制后续仍然会重新提交/回滚这些未完成的全局事务,这样就会再次调用参与该全局事务的各TCC服务的Confirm/Cancel业务逻辑。
既然Confirm/Cancel业务可能会被多次调用,就需要保障其幂等性。
那么,应该由TCC事务框架来提供幂等性保障?还是应该由业务系统自行来保障幂等性呢?
个人认为,应该是由TCC事务框架来提供幂等性保障。如果仅仅只是极个别服务存在这个问题的话,那么由业务系统来负责也是可以的;然而,这是一类公共问题,毫无疑问,所有TCC服务的Confirm/Cancel业务存在幂等性问题。TCC服务的公共问题应该由TCC事务框架来解决。
而且,考虑一下由业务系统来负责幂等性需要考虑的问题,就会发现,这无疑增大了业务系统的复杂度。
五、TCC事务框架不能盲目的依赖Cancel业务来回滚事务
前文以及提到过,TCC事务通过Cancel业务来对Try业务进行回撤的机制暗含了一个事实:Try操作已经生效。
也就是说,只有Try操作所参与的RM本地事务已经提交的情况下,才需要执行其Cancel操作进行回撤。没有执行、或者执行了但是其RM本地事务被rollback的Try业务,是一定不能执行其Cancel业务进行回撤的。
因此,TCC事务框架在全局事务回滚时,应该根据TCC服务的Try业务的执行情况选择合适的处理机制。而不能盲目的执行Cancel业务,否则就会导致数据不一致。
一个TCC服务的Try操作是否生效,这是TCC事务框架应该知道的,因为其Try业务所参与的RM事务也是由TCC事务框架所commit/rollbac的(前提是TCC事务框架接管了Spring的事务管理器)。所以,TCC事务回滚时,TCC事务框架可考虑如下处理策略:
1)如果TCC事务框架发现某个服务的Try操作的本地事务尚未提交,应该直接将其回滚,而后就不必再执行该服务的cancel业务;
2)如果TCC事务框架发现某个服务的Try操作的本地事务已经回滚,则不必再执行该服务的cancel业务;
3)如果TCC事务框架发现某个服务的Try操作尚未被执行过,那么,也不必再执行该服务的cancel业务。
总之,TCC事务框架应该保障:
1)已生效的Try操作应该被其Cancel操作所回撤;
2)尚未生效的Try操作,则不应该执行其Cancel操作。
这一点,不是幂等性所能解决的问题。如上文所述,幂等性是指服务被执行一次和被执行n(n>0)次所产生的影响相同。但是,未被执行和被执行过,二者效果肯定是不一样的,这不属于幂等性的范畴。
六、Cancel业务与Try业务并行,甚至先于Try操作完成
这应该算TCC事务机制特有的一个不可思议的陷阱。一般来说,一个特定的TCC服务,其Try操作的执行,是应该在其Confirm/Cancel操作之前的。Try操作执行完毕之后,Spring容器再根据Try操作的执行情况,指示TCC事务框架提交/回滚全局事务。然后,TCC事务框架再去逐个调用各TCC服务的Confirm/Cancel操作。
然而,超时、网络故障、服务器的重启等故障的存在,使得这个顺序会被打乱。比如: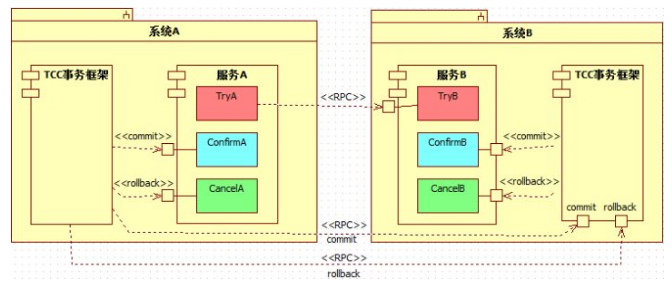
上图中,假设[B:Try]操作执行过程中,网络闪断,[A:Try]会收到一个RPC远程调用异常。A不处理该异常,导致全局事务决定回滚,TCC事务框架就会去调用[B:Cancel],而此刻A、B之间网络刚好已经恢复。如果[B:Try]操作耗时较长(网络阻塞/数据库操作阻塞),就会出现[B:Try]和[B:Cancel]二者并行处理的现象,甚至[B:Cancel]先完成的现象。
这种情况下,由于[B:Cancel]执行时,[B:Try]尚未生效(其RM本地事务尚未提交),因此,[B:Cancel]是不能执行的,至少是不能生效(执行了其RM本地事务也要rollback)的。
然而,当[B:Cancel]处理完毕(跳过执行、或者执行后rollback其RM本地事务)后,[B:Try]操作完成又生效了(其RM本地事务成功提交),这就使得[B:Cancel]虽然提供了,但却没有起到回撤[B:Try]的作用,导致数据的不一致。
所以,TCC框架在这种情况下,需要:
1)将[B:Try]的本地事务标注为Marked_ReadOnly,阻止其后续生效;
2)禁止其再次将事务上下文传递给其他远程分支,否则该问题将在其他分支上出现;
3)相应地,[B:Cancel]也不必执行,至少不能生效。
当然,TCC事务框架也可以简单的选择阻塞[B:Cancel],待[B:Try]执行完毕后,再根据它的执行情况判断是否需要执行[B:Cancel]。不过,这种处理方式因为需要等待,所以,处理效率上会有所不及。
同样的情况也会出现在confirm业务上,只不过,发生在Confirm业务上的处理逻辑与发生在Cancel业务上的处理逻辑会不一样,TCC框架必须保证:
1)Confirm业务在Try业务之后执行,若发现并行,则只能阻塞相应的Confirm业务操作;
2)在进入Confirm执行阶段之后,也不可以再提交同一全局事务内的新的Try操作的RM本地事务。
七、TCC服务是否需要对外暴露三个服务接口?
不需要。
TCC服务与普通的服务一样,只需要暴露一个接口,也就是它的Try业务。Confirm/Cancel业务逻辑,只是因为全局事务提交/回滚的需要才提供的,因此Confirm/Cancel业务只需要被TCC事务框架发现即可,不需要被调用它的其他业务服务所感知。
换句话说,业务系统的其他服务在需要调用TCC服务时,根本不需要知道它是否为TCC型服务。因为,TCC服务能被其他业务服务调用的也仅仅是其Try业务,Confirm/Cancel业务是不能被其他业务服务直接调用的。
八、TCC服务A的Confirm/Cancel业务方法中能否调用它依赖的TCC服务B的Confirm/Cancel业务方法?
最好是不要这样做。
首先,没有必要。TCC服务A依赖TCC服务B,那么[A:Try]已经将事务上下文传播给[B:Try]了,后续由TCC事务框架来调用各自的Confirm/Cancel业务即可;
其次,Confirm/Cancel业务如果被允许调用其他服务,那么它就有可能再次发起新的TCC全局事务。如此递归下去,将会导致全局事务关系混乱且不可控。
TCC全局事务,应该尽量在Try操作阶段传播事务上下文。Confirm/Cancel操作阶段仅需要完成各自Try业务操作的确认操作/补偿操作即可,不适合再做远程调用,更不能再对外传播事务上下文。
综上所述,本文倾向于认为,实现一个通用的TCC分布式事务管理框架,还是相对比较复杂的。一般业务系统如果需要使用TCC事务机制,并不推荐自行设计实现。
这里,给大家推荐一款开源的TCC分布式事务管理器ByteTCC。ByteTCC基于Try/Confirm/Cancel机制实现,可与Spring容器无缝集成,兼容Spring的声明式事务管理。提供对dubbo框架、Spring Cloud的开箱即用的支持,可满足多数据源、跨应用、跨服务器等各种分布式事务场景的需求。
上面内容来源:https://www.zhihu.com/question/48627764/answer/259103512
另外 tcc 同两阶段事物区别如下:
TCC和两阶段分布式事务处理的区别
经常在网络上看见有人介绍TCC时,都提一句,”TCC是两阶段提交的一种”。其理由是TCC将业务逻辑分成try、confirm/cancel在两个不同的阶段中执行。其实这个说法,是不正确的。可能是因为既不太了解两阶段提交机制、也不太了解TCC机制的缘故,于是将两阶段提交机制的prepare、commit两个事务提交阶段和TCC机制的try、confirm/cancel两个业务执行阶段互相混淆,才有了这种说法。
两阶段提交(Two Phase Commit,下文简称2PC),简单的说,是将事务的提交操作分成了prepare、commit两个阶段。其事务处理方式为:
1、 在全局事务决定提交时,a)逐个向RM发送prepare请求;b)若所有RM都返回OK,则逐个发送commit请求最终提交事务;否则,逐个发送rollback请求来回滚事务;
2、 在全局事务决定回滚时,直接逐个发送rollback请求即可,不必分阶段。
* 需要注意的是:2PC机制需要RM提供底层支持(一般是兼容XA),而TCC机制则不需要。
TCC(Try-Confirm-Cancel),则是将业务逻辑分成try、confirm/cancel两个阶段执行,具体介绍见TCC事务机制简介。其事务处理方式为:
1、 在全局事务决定提交时,调用与try业务逻辑相对应的confirm业务逻辑;
2、 在全局事务决定回滚时,调用与try业务逻辑相对应的cancel业务逻辑。
可见,TCC在事务处理方式上,是很简单的:要么调用confirm业务逻辑,要么调用cancel逻辑。这里为什么没有提到try业务逻辑呢?因为try逻辑与全局事务处理无关。
当讨论2PC时,我们只专注于事务处理阶段,因而只讨论prepare和commit,所以,可能很多人都忘了,使用2PC事务管理机制时也是有业务逻辑阶段的。正是因为业务逻辑的执行,发起了全局事务,这才有其后的事务处理阶段。实际上,使用2PC机制时————以提交为例————一个完整的事务生命周期是:begin -> 业务逻辑 -> prepare -> commit。
再看TCC,也不外乎如此。我们要发起全局事务,同样也必须通过执行一段业务逻辑来实现。该业务逻辑一来通过执行触发TCC全局事务的创建;二来也需要执行部分数据写操作;此外,还要通过执行来向TCC全局事务注册自己,以便后续TCC全局事务commit/rollback时回调其相应的confirm/cancel业务逻辑。所以,使用TCC机制时————以提交为例————一个完整的事务生命周期是:begin -> 业务逻辑(try业务) -> commit(comfirm业务)。
综上,我们可以从执行的阶段上将二者一一对应起来:
1、 2PC机制的业务阶段 等价于 TCC机制的try业务阶段;
2、 2PC机制的提交阶段(prepare & commit) 等价于 TCC机制的提交阶段(confirm);
3、 2PC机制的回滚阶段(rollback) 等价于 TCC机制的回滚阶段(cancel)。
因此,可以看出,虽然TCC机制中有两个阶段都存在业务逻辑的执行,但其中try业务阶段其实是与全局事务处理无关的。认清了这一点,当我们再比较TCC和2PC时,就会很容易地发现,TCC不是两阶段提交,而只是它对事务的提交/回滚是通过执行一段confirm/cancel业务逻辑来实现,仅此而已。
上述内容来源:https://blog.csdn.net/zhangjq520/article/details/78433686
下面的内容很好, 值得一看
聊聊分布式事务,再说说解决方案
最近很久没有写博客了,一方面是因为公司事情最近比较忙,另外一方面是因为在进行 CAP 的下一阶段的开发工作,不过目前已经告一段落了。
接下来还是开始我们今天的话题,说说分布式事务,或者说是我眼中的分布式事务,因为每个人可能对其的理解都不一样。
分布式事务是企业集成中的一个技术难点,也是每一个分布式系统架构中都会涉及到的一个东西,特别是在微服务架构中,几乎可以说是无法避免,本文就分布式事务来简单聊一下。
数据库事务
在说分布式事务之前,我们先从数据库事务说起。 数据库事务可能大家都很熟悉,在开发过程中也会经常使用到。但是即使如此,可能对于一些细节问题,很多人仍然不清楚。比如很多人都知道数据库事务的几个特性:原子性(Atomicity )、一致性( Consistency )、隔离性或独立性( Isolation)和持久性(Durabilily),简称就是ACID。但是再往下比如问到隔离性指的是什么的时候可能就不知道了,或者是知道隔离性是什么但是再问到数据库实现隔离的都有哪些级别,或者是每个级别他们有什么区别的时候可能就不知道了。
本文并不打算介绍这些数据库事务的这些东西,有兴趣可以搜索一下相关资料。不过有一个知识点我们需要了解,就是假如数据库在提交事务的时候突然断电,那么它是怎么样恢复的呢? 为什么要提到这个知识点呢? 因为分布式系统的核心就是处理各种异常情况,这也是分布式系统复杂的地方,因为分布式的网络环境很复杂,这种“断电”故障要比单机多很多,所以我们在做分布式系统的时候,最先考虑的就是这种情况。这些异常可能有 机器宕机、网络异常、消息丢失、消息乱序、数据错误、不可靠的TCP、存储数据丢失、其他异常等等...
我们接着说本地事务数据库断电的这种情况,它是怎么保证数据一致性的呢?我们使用SQL Server来举例,我们知道我们在使用 SQL Server 数据库是由两个文件组成的,一个数据库文件和一个日志文件,通常情况下,日志文件都要比数据库文件大很多。数据库进行任何写入操作的时候都是要先写日志的,同样的道理,我们在执行事务的时候数据库首先会记录下这个事务的redo操作日志,然后才开始真正操作数据库,在操作之前首先会把日志文件写入磁盘,那么当突然断电的时候,即使操作没有完成,在重新启动数据库时候,数据库会根据当前数据的情况进行undo回滚或者是redo前滚,这样就保证了数据的强一致性。
接着,我们就说一下分布式事务。
分布式理论
当我们的单个数据库的性能产生瓶颈的时候,我们可能会对数据库进行分区,这里所说的分区指的是物理分区,分区之后可能不同的库就处于不同的服务器上了,这个时候单个数据库的ACID已经不能适应这种情况了,而在这种ACID的集群环境下,再想保证集群的ACID几乎是很难达到,或者即使能达到那么效率和性能会大幅下降,最为关键的是再很难扩展新的分区了,这个时候如果再追求集群的ACID会导致我们的系统变得很差,这时我们就需要引入一个新的理论原则来适应这种集群的情况,就是 CAP 原则或者叫CAP定理,那么CAP定理指的是什么呢?
CAP定理
CAP定理是由加州大学伯克利分校Eric Brewer教授提出来的,他指出WEB服务无法同时满足一下3个属性:
- 一致性(Consistency) : 客户端知道一系列的操作都会同时发生(生效)
- 可用性(Availability) : 每个操作都必须以可预期的响应结束
- 分区容错性(Partition tolerance) : 即使出现单个组件无法可用,操作依然可以完成
具体地讲在分布式系统中,在任何数据库设计中,一个Web应用至多只能同时支持上面的两个属性。显然,任何横向扩展策略都要依赖于数据分区。因此,设计人员必须在一致性与可用性之间做出选择。
这个定理在迄今为止的分布式系统中都是适用的! 为什么这么说呢?
这个时候有同学可能会把数据库的2PC(两阶段提交)搬出来说话了。OK,我们就来看一下数据库的两阶段提交。
对数据库分布式事务有了解的同学一定知道数据库支持的2PC,又叫做 XA Transactions。
MySQL从5.5版本开始支持,SQL Server 2005 开始支持,Oracle 7 开始支持。
其中,XA 是一个两阶段提交协议,该协议分为以下两个阶段:
- 第一阶段:事务协调器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交.
- 第二阶段:事务协调器要求每个数据库提交数据。
其中,如果有任何一个数据库否决此次提交,那么所有数据库都会被要求回滚它们在此事务中的那部分信息。这样做的缺陷是什么呢? 咋看之下我们可以在数据库分区之间获得一致性。
如果CAP 定理是对的,那么它一定会影响到可用性。
如果说系统的可用性代表的是执行某项操作相关所有组件的可用性的和。那么在两阶段提交的过程中,可用性就代表了涉及到的每一个数据库中可用性的和。我们假设两阶段提交的过程中每一个数据库都具有99.9%的可用性,那么如果两阶段提交涉及到两个数据库,这个结果就是99.8%。根据系统可用性计算公式,假设每个月43200分钟,99.9%的可用性就是43157分钟, 99.8%的可用性就是43114分钟,相当于每个月的宕机时间增加了43分钟。
以上,可以验证出来,CAP定理从理论上来讲是正确的,CAP我们先看到这里,等会再接着说。
BASE理论
在分布式系统中,我们往往追求的是可用性,它的重要程序比一致性要高,那么如何实现高可用性呢? 前人已经给我们提出来了另外一个理论,就是BASE理论,它是用来对CAP定理进行进一步扩充的。BASE理论指的是:
- Basically Available(基本可用)
- Soft state(软状态)
- Eventually consistent(最终一致性)
BASE理论是对CAP中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
有了以上理论之后,我们来看一下分布式事务的问题。
分布式事务
在分布式系统中,要实现分布式事务,无外乎那几种解决方案。
一、两阶段提交(2PC)
和上一节中提到的数据库XA事务一样,两阶段提交就是使用XA协议的原理,我们可以从下面这个图的流程来很容易的看出中间的一些比如commit和abort的细节。
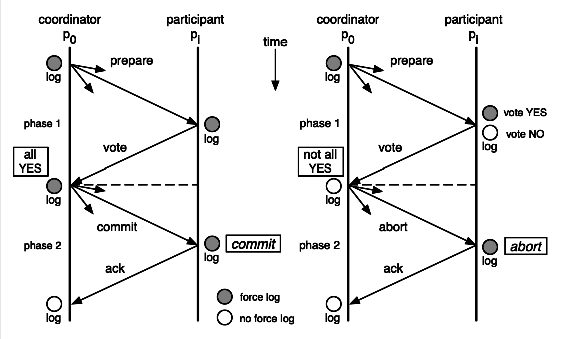
两阶段提交这种解决方案属于牺牲了一部分可用性来换取的一致性。在实现方面,在 .NET 中,可以借助 TransactionScop 提供的 API 来编程实现分布式系统中的两阶段提交,比如WCF中就有实现这部分功能。不过在多服务器之间,需要依赖于DTC来完成事务一致性,Windows下微软搞的有MSDTC服务,Linux下就比较悲剧了。
另外说一句,TransactionScop 默认不能用于异步方法之间事务一致,因为事务上下文是存储于当前线程中的,所以如果是在异步方法,需要显式的传递事务上下文。
优点: 尽量保证了数据的强一致,适合对数据强一致要求很高的关键领域。(其实也不能100%保证强一致)
缺点: 实现复杂,牺牲了可用性,对性能影响较大,不适合高并发高性能场景,如果分布式系统跨接口调用,目前 .NET 界还没有实现方案。
二、补偿事务(TCC)
TCC 其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。它分为三个阶段:
- Try 阶段主要是对业务系统做检测及资源预留
- Confirm 阶段主要是对业务系统做确认提交,Try阶段执行成功并开始执行 Confirm阶段时,默认 Confirm阶段是不会出错的。即:只要Try成功,Confirm一定成功。
- Cancel 阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。
举个例子,假入 Bob 要向 Smith 转账,思路大概是:
我们有一个本地方法,里面依次调用
1、首先在 Try 阶段,要先调用远程接口把 Smith 和 Bob 的钱给冻结起来。
2、在 Confirm 阶段,执行远程调用的转账的操作,转账成功进行解冻。
3、如果第2步执行成功,那么转账成功,如果第二步执行失败,则调用远程冻结接口对应的解冻方法 (Cancel)。
优点: 跟2PC比起来,实现以及流程相对简单了一些,但数据的一致性比2PC也要差一些
缺点: 缺点还是比较明显的,在2,3步中都有可能失败。TCC属于应用层的一种补偿方式,所以需要程序员在实现的时候多写很多补偿的代码,在一些场景中,一些业务流程可能用TCC不太好定义及处理。
三、本地消息表(异步确保)
本地消息表这种实现方式应该是业界使用最多的,其核心思想是将分布式事务拆分成本地事务进行处理,这种思路是来源于ebay。我们可以从下面的流程图中看出其中的一些细节:
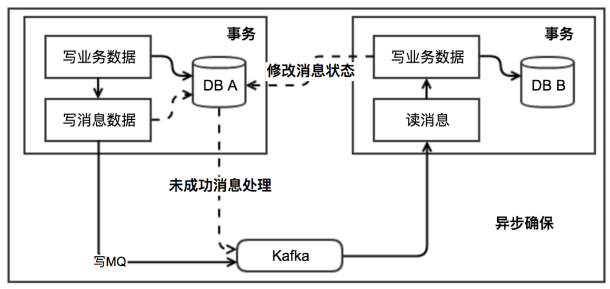
基本思路就是:
消息生产方,需要额外建一个消息表,并记录消息发送状态。消息表和业务数据要在一个事务里提交,也就是说他们要在一个数据库里面。然后消息会经过MQ发送到消息的消费方。如果消息发送失败,会进行重试发送。
消息消费方,需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么就会重试执行。如果是业务上面的失败,可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。
生产方和消费方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。如果有靠谱的自动对账补账逻辑,这种方案还是非常实用的。
这种方案遵循BASE理论,采用的是最终一致性,笔者认为是这几种方案里面比较适合实际业务场景的,即不会出现像2PC那样复杂的实现(当调用链很长的时候,2PC的可用性是非常低的),也不会像TCC那样可能出现确认或者回滚不了的情况。
优点: 一种非常经典的实现,避免了分布式事务,实现了最终一致性。在 .NET中 有现成的解决方案。
缺点: 消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理。
四、MQ 事务消息
有一些第三方的MQ是支持事务消息的,比如RocketMQ,他们支持事务消息的方式也是类似于采用的二阶段提交,但是市面上一些主流的MQ都是不支持事务消息的,比如 RabbitMQ 和 Kafka 都不支持。
以阿里的 RocketMQ 中间件为例,其思路大致为:
第一阶段Prepared消息,会拿到消息的地址。
第二阶段执行本地事务,第三阶段通过第一阶段拿到的地址去访问消息,并修改状态。
也就是说在业务方法内要想消息队列提交两次请求,一次发送消息和一次确认消息。如果确认消息发送失败了RocketMQ会定期扫描消息集群中的事务消息,这时候发现了Prepared消息,它会向消息发送者确认,所以生产方需要实现一个check接口,RocketMQ会根据发送端设置的策略来决定是回滚还是继续发送确认消息。这样就保证了消息发送与本地事务同时成功或同时失败。
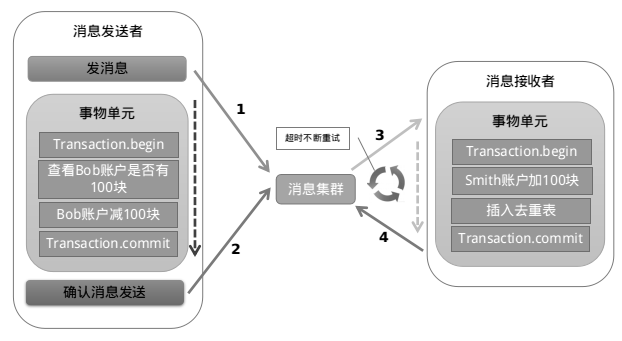
遗憾的是,RocketMQ并没有 .NET 客户端。有关 RocketMQ的更多消息,大家可以查看这篇博客
优点: 实现了最终一致性,不需要依赖本地数据库事务。
缺点: 实现难度大,主流MQ不支持,没有.NET客户端,RocketMQ事务消息部分代码也未开源。
五、Sagas 事务模型
Saga事务模型又叫做长时间运行的事务(Long-running-transaction), 它是由普林斯顿大学的H.Garcia-Molina等人提出,它描述的是另外一种在没有两阶段提交的的情况下解决分布式系统中复杂的业务事务问题。你可以在这里看到 Sagas 相关论文。
我们这里说的是一种基于 Sagas 机制的工作流事务模型,这个模型的相关理论目前来说还是比较新的,以至于百度上几乎没有什么相关资料。
该模型其核心思想就是拆分分布式系统中的长事务为多个短事务,或者叫多个本地事务,然后由 Sagas 工作流引擎负责协调,如果整个流程正常结束,那么就算是业务成功完成,如果在这过程中实现失败,那么Sagas工作流引擎就会以相反的顺序调用补偿操作,重新进行业务回滚。
比如我们一次关于购买旅游套餐业务操作涉及到三个操作,他们分别是预定车辆,预定宾馆,预定机票,他们分别属于三个不同的远程接口。可能从我们程序的角度来说他们不属于一个事务,但是从业务角度来说是属于同一个事务的。
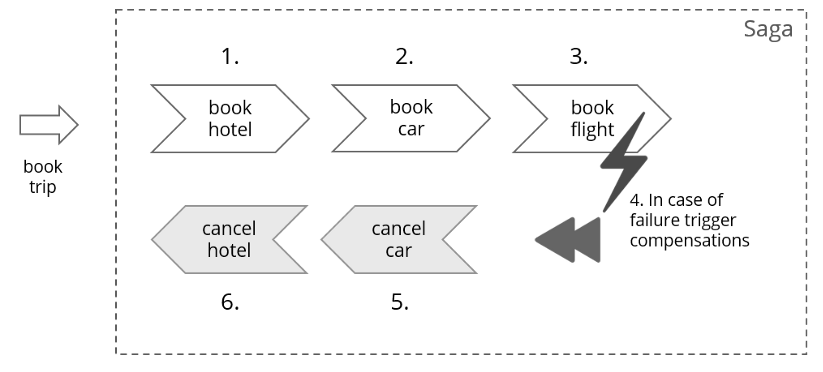
他们的执行顺序如上图所示,所以当发生失败时,会依次进行取消的补偿操作。
因为长事务被拆分了很多个业务流,所以 Sagas 事务模型最重要的一个部件就是工作流或者你也可以叫流程管理器(Process Manager),工作流引擎和Process Manager虽然不是同一个东西,但是在这里,他们的职责是相同的。在选择工作流引擎之后,最终的代码也许看起来是这样的
SagaBuilder saga = SagaBuilder.newSaga("trip")
.activity("Reserve car", ReserveCarAdapter.class)
.compensationActivity("Cancel car", CancelCarAdapter.class)
.activity("Book hotel", BookHotelAdapter.class)
.compensationActivity("Cancel hotel", CancelHotelAdapter.class)
.activity("Book flight", BookFlightAdapter.class)
.compensationActivity("Cancel flight", CancelFlightAdapter.class)
.end()
.triggerCompensationOnAnyError();
camunda.getRepositoryService().createDeployment()
.addModelInstance(saga.getModel())
.deploy();这里有一个 C# 相关示例,有兴趣的同学可以看一下。
优缺点这里我们就不说了,因为这个理论比较新,目前市面上还没有什么解决方案,即使是 Java 领域,我也没有搜索的太多有用的信息。
分布式事务解决方案:CAP
上面介绍的那些分布式事务的处理方案你在其他地方或许也可以看到,但是并没有相关的实际代码或者是开源代码,所以算不上什么干货,下面就放干货了。
在 .NET 领域,似乎没有什么现成的关于分布式事务的解决方案,或者说是有但未开源。具笔者了解,有一些公司内部其实是有这种解决方案的,但是也是作为公司的一个核心产品之一,并未开源...
鉴于以上原因,所以博主就打算自己写一个并且开源出来,所以从17年初就开始做这个事情,然后花了大半年的时间在一直不断完善,就是下面这个 CAP。
Github CAP:这里的 CAP 就不是 CAP 理论了,而是一个 .NET 分布式事务解决方案的名字。
详细介绍:
http://www.cnblogs.com/savorboard/p/cap.html
相关文档:
http://www.cnblogs.com/savorboard/p/cap-document.html
夸张的是,这个解决方案是具有可视化界面(Dashboard)的,你可以很方面的看到哪些消息执行成功,哪些消息执行失败,到底是发送失败还是处理失败,一眼便知。
最夸张的是,这个解决方案的可视化界面还提供了实时动态图表,这样不但可以看到实时的消息发送及处理情况,连当前的系统处理消息的速度都可以看到,还可以看到过去24小时内的历史消息吞吐量。
最最夸张的是,这个解决方案的还帮你集成了 Consul 做分布式节点发现和注册还有心跳检查,你随时可以看到其他的节点的状况。
最最最夸张的是,你以为你看其他节点的数据要登录到其他节点的Dashboard控制台看?错了,你随便打开其中任意一个节点的Dashboard,点一下就可以切换到你想看的节点的控制台界面了,就像你看本地的数据一样,他们是完全去中心化的。
你以为这些就够了?不,远远不止:
- CAP 同时支持 RabbitMQ,Kafka 等消息队列
- CAP 同时支持 SQL Server, MySql, PostgreSql 等数据库
- CAP Dashboard 同时支持中文和英文界面双语言,妈妈再也不用担心我看不懂了
- CAP 提供了丰富的接口可以供扩展,什么序列化了,自定义处理了,自定义发送了统统不在话下
- CAP 基于MIT开源,你可以尽管拿去做二次开发。(记得保留MIT的License)
这下你以为我说完了? 不!
你完全可以把 CAP 当做一个 EventBus 来使用,CAP具有优秀的消息处理能力,不要担心瓶颈会在CAP,那是永远不可能, 因为你随时可以在配置中指定CAP处理的消息使用的进程数, 只要你的数据库配置足够高...
说了这么多,口干舌燥的,你不 Star 一下给个精神上的支持说不过去吧? ^_^
2号传送门: https://github.com/dotnetcore/CAP
不 Star 也没关系,我选择原谅你~
总结
通过本文我们了解到两个分布式系统的理论,他们分别是CAP和BASE 理论,同时我们也总结并对比了几种分布式分解方案的优缺点,分布式事务本身是一个技术难题,是没有一种完美的方案应对所有场景的,具体还是要根据业务场景去抉择吧。 然后我们介绍了一种基于本地消息的的分布式事务解决方案CAP。
如果你觉得本篇文章对您有帮助的话,感谢您的【推荐】。
如果你对 .NET Core 有兴趣的话可以关注我,我会定期的在博客分享我的学习心得。
来源:https://www.cnblogs.com/savorboard/p/distributed-system-transaction-consistency.html
