已经不记得最早接触到 Disruptor 是什么时候了,只记得发现它的时候它是以具有闪电般的速度被介绍的。于是在脑子里, Disruptor 和“闪电”一词关联了起来,然而却一直没有时间去探究一下。
最近正在进行一项对性能有很高要求的产品项目的研究,自然想起了闪电般的 Disruptor ,这必有它的用武之地,于是进行了一番探查,将成果和体会记录在案。
一、什么是 Disruptor
从功能上来看,Disruptor 是实现了“队列”的功能,而且是一个有界队列。那么它的应用场景自然就是“生产者-消费者”模型的应用场合了。
可以拿 JDK 的 BlockingQueue 做一个简单对比,以便更好地认识 Disruptor 是什么。
我们知道 BlockingQueue 是一个 FIFO 队列,生产者(Producer)往队列里发布(publish)一项事件(或称之为“消息”也可以)时,消费者(Consumer)能获得通知;如果没有事件时,消费者被堵塞,直到生产者发布了新的事件。
这些都是 Disruptor 能做到的,与之不同的是,Disruptor 能做更多:
- 同一个“事件”可以有多个消费者,消费者之间既可以并行处理,也可以相互依赖形成处理的先后次序(形成一个依赖图);
- 预分配用于存储事件内容的内存空间;
- 针对极高的性能目标而实现的极度优化和无锁的设计;
以上的描述虽然简单地指出了 Disruptor 是什么,但对于它“能做什么”还不是那么直截了当。一般性地来说,当你需要在两个独立的处理过程(两个线程)之间交换数据时,就可以使用 Disruptor 。当然使用队列(如上面提到的 BlockingQueue)也可以,只不过 Disruptor 做得更好。
拿队列来作比较的做法弱化了对 Disruptor 有多强大的认识,如果想要对此有更多的了解,可以仔细看看 Disruptor 在其东家 LMAX 交易平台(也是实现者) 是如何作为核心架构来使用的,这方面就不做详述了,问度娘或谷哥都能找到。
二、Disruptor 的核心概念
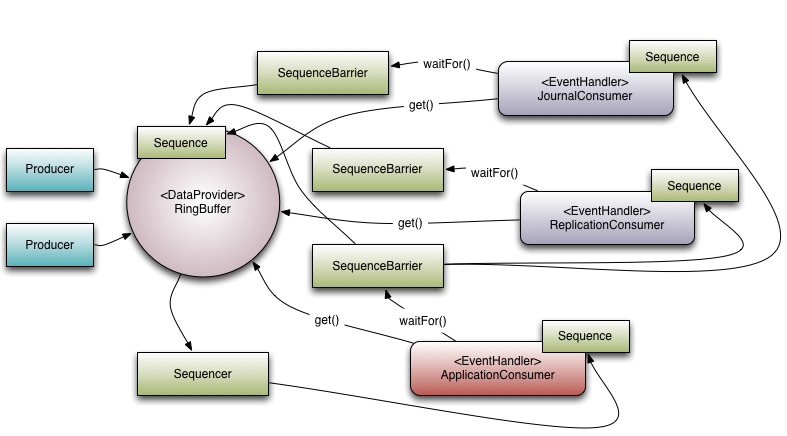
先从了解 Disruptor 的核心概念开始,来了解它是如何运作的。下面介绍的概念模型,既是领域对象,也是映射到代码实现上的核心对象。
- Ring Buffer
如其名,环形的缓冲区。曾经 RingBuffer 是 Disruptor 中的最主要的对象,但从3.0版本开始,其职责被简化为仅仅负责对通过 Disruptor 进行交换的数据(事件)进行存储和更新。在一些更高级的应用场景中,Ring Buffer 可以由用户的自定义实现来完全替代。 - Sequence Disruptor
通过顺序递增的序号来编号管理通过其进行交换的数据(事件),对数据(事件)的处理过程总是沿着序号逐个递增处理。一个 Sequence 用于跟踪标识某个特定的事件处理者( RingBuffer/Consumer )的处理进度。虽然一个 AtomicLong 也可以用于标识进度,但定义 Sequence 来负责该问题还有另一个目的,那就是防止不同的 Sequence 之间的CPU缓存伪共享(Flase Sharing)问题。
(注:这是 Disruptor 实现高性能的关键点之一,网上关于伪共享问题的介绍已经汗牛充栋,在此不再赘述)。 - Sequencer
Sequencer 是 Disruptor 的真正核心。此接口有两个实现类 SingleProducerSequencer、MultiProducerSequencer ,它们定义在生产者和消费者之间快速、正确地传递数据的并发算法。 - Sequence Barrier
用于保持对RingBuffer的 main published Sequence 和Consumer依赖的其它Consumer的 Sequence 的引用。 Sequence Barrier 还定义了决定 Consumer 是否还有可处理的事件的逻辑。 - Wait Strategy
定义 Consumer 如何进行等待下一个事件的策略。 (注:Disruptor 定义了多种不同的策略,针对不同的场景,提供了不一样的性能表现) - Event
在 Disruptor 的语义中,生产者和消费者之间进行交换的数据被称为事件(Event)。它不是一个被 Disruptor 定义的特定类型,而是由 Disruptor 的使用者定义并指定。 - EventProcessor
EventProcessor 持有特定消费者(Consumer)的 Sequence,并提供用于调用事件处理实现的事件循环(Event Loop)。 - EventHandler
Disruptor 定义的事件处理接口,由用户实现,用于处理事件,是 Consumer 的真正实现。 - Producer
即生产者,只是泛指调用 Disruptor 发布事件的用户代码,Disruptor 没有定义特定接口或类型。
三、如何使用 Disruptor
Disruptor 的 API 十分简单,主要有以下几个步骤:
- 定义事件
事件(Event)就是通过 Disruptor 进行交换的数据类型。public class LongEvent { private long value; public void set(long value) { this.value = value; } } - 定义事件工厂
事件工厂(Event Factory)定义了如何实例化前面第1步中定义的事件(Event),需要实现接口 com.lmax.disruptor.EventFactory<T>。
Disruptor 通过 EventFactory 在 RingBuffer 中预创建 Event 的实例。
一个 Event 实例实际上被用作一个“数据槽”,发布者发布前,先从 RingBuffer 获得一个 Event 的实例,然后往 Event 实例中填充数据,之后再发布到 RingBuffer 中,之后由 Consumer 获得该 Event 实例并从中读取数据。import com.lmax.disruptor.EventFactory; public class LongEventFactory implements EventFactory<LongEvent> { public LongEvent newInstance() { return new LongEvent(); } } - 定义事件处理的具体实现
通过实现接口 com.lmax.disruptor.EventHandler<T> 定义事件处理的具体实现。import com.lmax.disruptor.EventHandler; public class LongEventHandler implements EventHandler<LongEvent> { public void onEvent(LongEvent event, long sequence, boolean endOfBatch) { System.out.println("Event: " + event); } } - 定义用于事件处理的线程池
Disruptor 通过 java.util.concurrent.ExecutorService 提供的线程来触发 Consumer 的事件处理。例如:ExecutorService executor = Executors.newCachedThreadPool();
- 指定等待策略
Disruptor 定义了 com.lmax.disruptor.WaitStrategy 接口用于抽象 Consumer 如何等待新事件,这是策略模式的应用。
Disruptor 提供了多个 WaitStrategy 的实现,每种策略都具有不同性能和优缺点,根据实际运行环境的 CPU 的硬件特点选择恰当的策略,并配合特定的 JVM 的配置参数,能够实现不同的性能提升。
例如,BlockingWaitStrategy、SleepingWaitStrategy、YieldingWaitStrategy 等,其中,
BlockingWaitStrategy 是最低效的策略,但其对CPU的消耗最小并且在各种不同部署环境中能提供更加一致的性能表现;
SleepingWaitStrategy 的性能表现跟 BlockingWaitStrategy 差不多,对 CPU 的消耗也类似,但其对生产者线程的影响最小,适合用于异步日志类似的场景;
YieldingWaitStrategy 的性能是最好的,适合用于低延迟的系统。在要求极高性能且事件处理线数小于 CPU 逻辑核心数的场景中,推荐使用此策略;例如,CPU开启超线程的特性。WaitStrategy BLOCKING_WAIT = new BlockingWaitStrategy(); WaitStrategy SLEEPING_WAIT = new SleepingWaitStrategy(); WaitStrategy YIELDING_WAIT = new YieldingWaitStrategy();
- 启动 Disruptor
EventFactory<LongEvent> eventFactory = new LongEventFactory(); ExecutorService executor = Executors.newSingleThreadExecutor(); int ringBufferSize = 1024 * 1024; // RingBuffer 大小,必须是 2 的 N 次方; Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(eventFactory, ringBufferSize, executor, ProducerType.SINGLE, new YieldingWaitStrategy()); EventHandler<LongEvent> eventHandler = new LongEventHandler(); disruptor.handleEventsWith(eventHandler); disruptor.start(); - 发布事件
Disruptor 的事件发布过程是一个两阶段提交的过程:
第一步:先从 RingBuffer 获取下一个可以写入的事件的序号;
第二步:获取对应的事件对象,将数据写入事件对象;
第三部:将事件提交到 RingBuffer;
事件只有在提交之后才会通知 EventProcessor 进行处理;// 发布事件; RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer(); long sequence = ringBuffer.next();//请求下一个事件序号; try { LongEvent event = ringBuffer.get(sequence);//获取该序号对应的事件对象; long data = getEventData();//获取要通过事件传递的业务数据; event.set(data); } finally{ ringBuffer.publish(sequence);//发布事件; }注意,最后的 ringBuffer.publish 方法必须包含在 finally 中以确保必须得到调用;如果某个请求的 sequence 未被提交,将会堵塞后续的发布操作或者其它的 producer。
Disruptor 还提供另外一种形式的调用来简化以上操作,并确保 publish 总是得到调用。
static class Translator implements EventTranslatorOneArg<LongEvent, Long>{ @Override public void translateTo(LongEvent event, long sequence, Long data) { event.set(data); } } public static Translator TRANSLATOR = new Translator(); public static void publishEvent2(Disruptor<LongEvent> disruptor) { // 发布事件; RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer(); long data = getEventData();//获取要通过事件传递的业务数据; ringBuffer.publishEvent(TRANSLATOR, data); }此外,Disruptor 要求 RingBuffer.publish 必须得到调用的潜台词就是,如果发生异常也一样要调用 publish ,那么,很显然这个时候需要调用者在事件处理的实现上来判断事件携带的数据是否是正确的或者完整的,这是实现者应该要注意的事情。
- 关闭 Disruptor
disruptor.shutdown();//关闭 disruptor,方法会堵塞,直至所有的事件都得到处理; executor.shutdown();//关闭 disruptor 使用的线程池;如果需要的话,必须手动关闭, disruptor 在 shutdown 时不会自动关闭;
四、性能对比测试
为了直观地感受 Disruptor 有多快,设计了一个性能对比测试:Producer 发布 100 万次事件,从发布第一个事件开始计时,捕捉 Consumer 处理完所有事件的耗时。
测试用例在 Producer 如何将事件通知到 Consumer 的实现方式上,设计了三种不同的实现:
- Producer 的事件发布和 Consumer 的事件处理都在同一个线程,Producer 发布事件后立即触发 Consumer 的事件处理;
- Producer 的事件发布和 Consumer 的事件处理在不同的线程,通过 ArrayBlockingQueue 传递给 Consumer 进行处理;
- Producer 的事件发布和 Consumer 的事件处理在不同的线程,通过 Disruptor 传递给 Consumer 进行处理;
此次测试用例仅做了只有一个 Producer 和一个 Consumer 的情形,测试用例的代码如下:
CounterTracer tracer = tracerFactory.newInstance(DATA_COUNT);//计数跟踪到达指定的数值;
TestHandler handler = new TestHandler(tracer);//Consumer 的事件处理;
EventPublisher publisher = publisherFactory.newInstance(new PublisherCreationArgs(DATA_COUNT, handler));//通过工厂对象创建不同的 Producer 的实现;
publisher.start();
tracer.start();
//发布事件;
for (int i = 0; i < DATA_COUNT; i++) {
publisher.publish(i);
}
//等待事件处理完成;
tracer.waitForReached();
publisher.stop();
//输出结果;
printResult(tracer);事件处理的实现只是调用一个计数器(CounterTracer)加1,该计数器跟踪从开始到达到总的事件次数时所耗的时间。
public class TestHandler {
private CounterTracer tracer;
public TestHandler(CounterTracer tracer) {
this.tracer = tracer;
}
/**
* 如果返回 true,则表示处理已经全部完成,不再处理后续事件;
*
* @param event
* @return
*/
public boolean process(TestEvent event){
return tracer.count();
}
}针对单一Producer 和单一 Consumer 的测试场景,CounterTracer 的实现如下:
/**
* 测试结果跟踪器,计数器不是线程安全的,仅在单线程的 consumer 测试中使用;
*
* @author haiq
*
*/
public class SimpleTracer implements CounterTracer {
private long startTicks;
private long endTicks;
private long count = 0;
private boolean end = false;
private final long expectedCount;
private CountDownLatch latch = new CountDownLatch(1);
public SimpleTracer(long expectedCount) {
this.expectedCount = expectedCount;
}
@Override
public void start() {
startTicks = System.currentTimeMillis();
end = false;
}
@Override
public long getMilliTimeSpan() {
return endTicks - startTicks;
}
@Override
public boolean count() {
if (end) {
return end;
}
count++;
end = count >= expectedCount;
if (end) {
endTicks = System.currentTimeMillis();
latch.countDown();
}
return end;
}
@Override
public void waitForReached() throws InterruptedException {
latch.await();
}
}第一种 Producer 的实现:直接触发事件处理;
public class DirectingPublisher implements EventPublisher {
private TestHandler handler;
private TestEvent event = new TestEvent();
public DirectingPublisher(TestHandler handler) {
this.handler = handler;
}
@Override
public void publish(int data) throws Exception {
event.setValue(data);
handler.process(event);
}
//省略其它代码;
}第二种 Producer 的实现:通过 ArrayBlockinigQueue 实现;
public class BlockingQueuePublisher implements EventPublisher {
private ArrayBlockingQueue<TestEvent> queue ;
private TestHandler handler;
public BlockingQueuePublisher(int maxEventSize, TestHandler handler) {
this.queue = new ArrayBlockingQueue<TestEvent>(maxEventSize);
this.handler = handler;
}
public void start(){
Thread thrd = new Thread(new Runnable() {
@Override
public void run() {
handle();
}
});
thrd.start();
}
private void handle(){
try {
TestEvent evt ;
while (true) {
evt = queue.take();
if (evt != null && handler.process(evt)) {
//完成后自动结束处理线程;
break;
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public void publish(int data) throws Exception {
TestEvent evt = new TestEvent();
evt.setValue(data);
queue.put(evt);
}
//省略其它代码;
}第三种 Producer 的实现:通过 Disruptor 实现;
public class DisruptorPublisher implements EventPublisher {
private class TestEventHandler implements EventHandler<TestEvent> {
private TestHandler handler;
public TestEventHandler(TestHandler handler) {
this.handler = handler;
}
@Override
public void onEvent(TestEvent event, long sequence, boolean endOfBatch)
throws Exception {
handler.process(event);
}
}
private static final WaitStrategy YIELDING_WAIT = new YieldingWaitStrategy();
private Disruptor<TestEvent> disruptor;
private TestEventHandler handler;
private RingBuffer<TestEvent> ringbuffer;
private ExecutorService executor;
public DisruptorPublisher(int bufferSize, TestHandler handler) {
this.handler = new TestEventHandler(handler);
executor = Executors.newSingleThreadExecutor();
disruptor = new Disruptor<TestEvent>(EVENT_FACTORY, bufferSize,
executor, ProducerType.SINGLE,
YIELDING_WAIT);
}
@SuppressWarnings("unchecked")
public void start() {
disruptor.handleEventsWith(handler);
disruptor.start();
ringbuffer = disruptor.getRingBuffer();
}
@Override
public void publish(int data) throws Exception {
long seq = ringbuffer.next();
try {
TestEvent evt = ringbuffer.get(seq);
evt.setValue(data);
} finally {
ringbuffer.publish(seq);
}
}
//省略其它代码;
}Producer 第一种实现并没有线程间的交换,实际上就是直接调用计数器,因此以此种实现的测试结果作为基准,对比其它的两种实现的测试结果。
在我的CPU CORE i5 / 4G 内存 / Win7 64 位的笔记本上,数据量(DATA_COUNT)取值为 1024 * 1024 时的测试结果如下:
【基准测试】 [1]--每秒吞吐量:--;(1048576/0ms) [2]--每秒吞吐量:--;(1048576/0ms) [3]--每秒吞吐量:--;(1048576/0ms) [4]--每秒吞吐量:69905066;(1048576/15ms) [5]--每秒吞吐量:--;(1048576/0ms) 【对比测试1: ArrayBlockingQueue 实现】 [1]--每秒吞吐量:4788018;(1048576/219ms) [2]--每秒吞吐量:5165399;(1048576/203ms) [3]--每秒吞吐量:4809981;(1048576/218ms) [4]--每秒吞吐量:5165399;(1048576/203ms) [5]--每秒吞吐量:5577531;(1048576/188ms) 【对比测试2: Disruptor实现】 [1]--每秒吞吐量:33825032;(1048576/31ms) [2]--每秒吞吐量:65536000;(1048576/16ms) [3]--每秒吞吐量:65536000;(1048576/16ms) [4]--每秒吞吐量:69905066;(1048576/15ms) [5]--每秒吞吐量:33825032;(1048576/31ms)
从测试结果看, Disruptor 的性能比 ArrayBlockingQueue 高出了几乎一个数量级,操作耗时也只有平均20毫秒左右。
由于篇幅有限,关于 Disruptor 实现高性能的原理,留待以后再做探讨。
六、参考资料
- Diruptor 页面:https://github.com/LMAX-Exchange/disruptor
来源:https://www.cnblogs.com/haiq/p/4112689.html