概述
最近我们的TaaS平台遇到很多的网络问题,事实证明“contiv + ovs + vlan”的方案并不适合TaaS这种大规模高并发的场景,填不完的坑,当然DevOps场景下是没什么问题的。时间紧迫,只能使用“Flannel + host-gw”这个简单、稳定的网络方案搭建一个小规模的集群来作为紧急备选方案。趁这个机会,也学习一下前两年因性能差,广为诟病而一直不敢碰的Flannel如今是怎么个样子。经过春节半个月的稳定测试、压力测试证明确实很稳定。当然,calico(bgp)才是我们后续的主要网络方案。
Flannel支持多种Backend协议,但是不支持运行时修改Backend。官方推荐使用以下Backend:
- VXLAN,性能损耗大概在20~30%;
- host-gw, 性能损耗大概10%,要求Host之间二层直连,因此只适用于小集群;
- UDP, 建议只用于debug,因为性能烂到家了,如果网卡支持 enable udp offload,直接由网卡进行拆包解包,性能还是很棒的。
- AliVPC。
实验性的Backend,不建议上生产:
- Alloc
- AWS VPC
- GCE
- IPIP
- IPSec
Flannel的配置
Flannel在官方配置可以在https://github.com/coreos/flannel/blob/master/Documentation/configuration.md找到,但是注意文档中的配置不是最新的,是不完整的。
通过命令行配置
目前最新版的Flannel v0.10.0的命令行配置及说明如下:
Usage: /opt/bin/flanneld [OPTION]...
-etcd-cafile string
SSL Certificate Authority file used to secure etcd communication
-etcd-certfile string
SSL certification file used to secure etcd communication
-etcd-endpoints string
a comma-delimited list of etcd endpoints (default "http://127.0.0.1:4001,http://127.0.0.1:2379")
-etcd-keyfile string
SSL key file used to secure etcd communication
-etcd-password string
password for BasicAuth to etcd
-etcd-prefix string
etcd prefix (default "/coreos.com/network")
-etcd-username string
username for BasicAuth to etcd
-healthz-ip string
the IP address for healthz server to listen (default "0.0.0.0")
-healthz-port int
the port for healthz server to listen(0 to disable)
-iface value
interface to use (IP or name) for inter-host communication. Can be specified multiple times to check each option in order. Returns the first match found.
-iface-regex value
regex expression to match the first interface to use (IP or name) for inter-host communication. Can be specified multiple times to check each regex in order. Returns the first match found. Regexes are checked after specific interfaces specified by the iface option have already been checked.
-ip-masq
setup IP masquerade rule for traffic destined outside of overlay network
-kube-api-url string
Kubernetes API server URL. Does not need to be specified if flannel is running in a pod.
-kube-subnet-mgr
contact the Kubernetes API for subnet assignment instead of etcd.
-kubeconfig-file string
kubeconfig file location. Does not need to be specified if flannel is running in a pod.
-log_backtrace_at value
when logging hits line file:N, emit a stack trace
-public-ip string
IP accessible by other nodes for inter-host communication
-subnet-file string
filename where env variables (subnet, MTU, ... ) will be written to (default "/run/flannel/subnet.env")
-subnet-lease-renew-margin int
subnet lease renewal margin, in minutes, ranging from 1 to 1439 (default 60)
-v value
log level for V logs
-version
print version and exit
-vmodule value
comma-separated list of pattern=N settings for file-filtered logging
需要说明如下:
- 我们是通过
-kube-subnet-mgr配置Flannel从Kubernetes APIServer中读取对应的ConfigMap来获取配置的。-kubeconfig-file, -kube-api-url我们也没有配置,因为我们是使用DaemonSet通过Pod来部署的Flannel,所以Flannel与Kubernetes APIServer是通过ServiceAccount来认证通信的。 - 另外一种方式是直接从etcd中读取Flannel配置,需要配置对应的
-etcd开头的Flag。 -subnet-file默认为/run/flannel/subnet.env,一般无需改动。Flannel会将本机的subnet信息对应的环境变量注入到该文件中,Flannel真正是从这里获取subnet信息的,比如:FLANNEL_NETWORK=10.244.0.0/16 FLANNEL_SUBNET=10.244.26.1/24 FLANNEL_MTU=1500 FLANNEL_IPMASQ=true-subnet-lease-renew-margin表示etcd租约到期前多少时间就可以重新自动续约,默认是1h。因为ttl时间是24h,所以这项配置自然不允许超过24h,即[1, 1439] min.
通过环境变量配置
上面的命令行配置项,都可以通过改成大写,下划线变中划线,再加上FLANNELD_前缀转成对应的环境变量的形式来设置。
比如--etcd-endpoints=http://10.0.0.2:2379对应的环境变量为FLANNELD_ETCD_ENDPOINTS=http://10.0.0.2:2379。
部署Flannel
通过Kubernetes DaemonSet部署Flannel,这一点毫无争议。同时创建对应的ClusterRole,ClusterRoleBinding,ServiceAccount,ConfigMap。完整的Yaml描述文件可参考如下:
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: flannel
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- apiGroups:
- ""
resources:
- nodes
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: flannel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: flannel
subjects:
- kind: ServiceAccount
name: flannel
namespace: kube-system
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: flannel
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kube-flannel-cfg
namespace: kube-system
labels:
tier: node
k8s-app: flannel
data:
cni-conf.json: |
{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
}
]
}
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "host-gw"
}
}
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: kube-flannel
namespace: kube-system
labels:
tier: node
k8s-app: flannel
spec:
template:
metadata:
labels:
tier: node
k8s-app: flannel
spec:
imagePullSecrets:
- name: harborsecret
serviceAccountName: flannel
containers:
- name: kube-flannel
image: registry.vivo.xyz:4443/coreos/flannel:v0.10.0-amd64
command: [ "/opt/bin/flanneld", "--ip-masq", "--kube-subnet-mgr"]
securityContext:
privileged: true
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
volumeMounts:
- name: run
mountPath: /run
- name: cni
mountPath: /etc/cni/net.d
- name: flannel-cfg
mountPath: /etc/kube-flannel/
- name: install-cni
image: registry.vivo.xyz:4443/coreos/flannel-cni:v0.3.0
command: ["/install-cni.sh"]
#command: ["sleep","10000"]
env:
# The CNI network config to install on each node.
- name: CNI_NETWORK_CONFIG
valueFrom:
configMapKeyRef:
name: kube-flannel-cfg
key: cni-conf.json
volumeMounts:
#- name: cni
# mountPath: /etc/cni/net.d
- name: cni
mountPath: /host/etc/cni/net.d
- name: host-cni-bin
mountPath: /host/opt/cni/bin/
hostNetwork: true
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
volumes:
- name: run
hostPath:
path: /run
#- name: cni
# hostPath:
# path: /etc/kubernetes/cni/net.d
- name: cni
hostPath:
path: /etc/cni/net.d
- name: flannel-cfg
configMap:
name: kube-flannel-cfg
- name: host-cni-bin
hostPath:
path: /etc/cni/net.d
updateStrategy:
rollingUpdate:
maxUnavailable: 1
type: RollingUpdate
工作原理
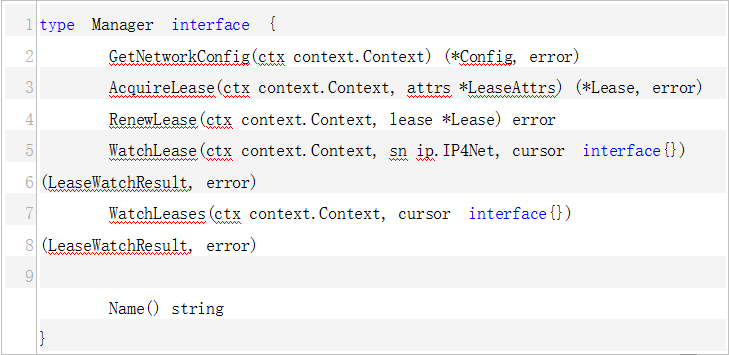
很容易混淆几个东西。我们通常说的Flannel(coreos/flannel),其实说的是flanneld。大家都知道Kubernetes是通过CNI标准对接网络插件的,但是当你去看Flannel(coreos/flannel)的代码时,并没有发现它实现了CNI的接口。如果你玩过其他CNI插件,你会知道还有一个二进制文件用来供kubele调用,并且会调用后端的网络插件。对于Flannel(coreos/flannel)来说,这个二进制文件是什么呢?git repo在哪里呢?
这个二进制文件就对应宿主机的/etc/cni/net.d/flannel,它的代码地址是https://github.com/containernetworking/plugins,最可恨的它的名字就叫做flannel,为啥不类似contiv netplugin对应的contivk8s一样,取名flannelk8s之类的。
上面的Flannel Pod中还有一个容器叫做install-cni,它对应的脚本在https://github.com/coreos/flannel-cni。
- /opt/bin/flanneld --> https://github.com/coreos/flannel
- /etc/cni/net.d/flannel --> https://github.com/containernetworking/plugins
- /install-cni.sh --> https://github.com/coreos/flannel-cni
kube-flannel容器
在kube-flannel容器里面运行的是我们的主角flanneld,我们需要关注的这个容器里面的目录/文件:
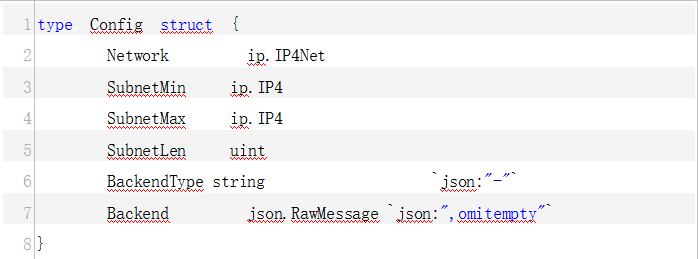
- /etc/kube-flannel/cni-conf.json
- /etc/kube-flannel/net-conf.json
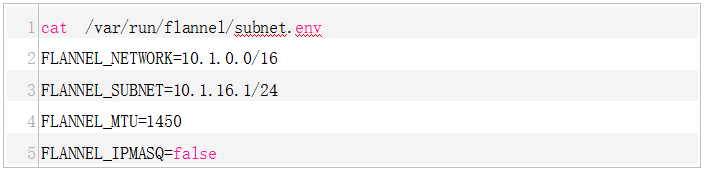
- /run/flannel/subnet.env
- /opt/bin/flanneld
下面是我的环境对应的内容:
/run/flannel # ls /etc/kube-flannel/
cni-conf.json net-conf.json
/run/flannel # cat /etc/kube-flannel/cni-conf.json
{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
}
]
}
/run/flannel # cat /etc/kube-flannel/net-conf.json
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "host-gw"
}
}
/run/flannel # cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.244.0.0/16
FLANNEL_SUBNET=10.244.26.1/24
FLANNEL_MTU=1500
FLANNEL_IPMASQ=true
/run/flannel # ls /opt/bin/
flanneld mk-docker-opts.sh
/run/flannel # cat /opt/bin/mk-docker-opts.sh
#!/bin/sh
usage() {
echo "$0 [-f FLANNEL-ENV-FILE] [-d DOCKER-ENV-FILE] [-i] [-c] [-m] [-k COMBINED-KEY]
Generate Docker daemon options based on flannel env file
OPTIONS:
-f Path to flannel env file. Defaults to /run/flannel/subnet.env
-d Path to Docker env file to write to. Defaults to /run/docker_opts.env
-i Output each Docker option as individual var. e.g. DOCKER_OPT_MTU=1500
-c Output combined Docker options into DOCKER_OPTS var
-k Set the combined options key to this value (default DOCKER_OPTS=)
-m Do not output --ip-masq (useful for older Docker version)
" >&2
exit 1
}
flannel_env="/run/flannel/subnet.env"
docker_env="/run/docker_opts.env"
combined_opts_key="DOCKER_OPTS"
indiv_opts=false
combined_opts=false
ipmasq=true
while getopts "f:d:icmk:?h" opt; do
case $opt in
f)
flannel_env=$OPTARG
;;
d)
docker_env=$OPTARG
;;
i)
indiv_opts=true
;;
c)
combined_opts=true
;;
m)
ipmasq=false
;;
k)
combined_opts_key=$OPTARG
;;
[\?h])
usage
;;
esac
done
if [ $indiv_opts = false ] && [ $combined_opts = false ]; then
indiv_opts=true
combined_opts=true
fi
if [ -f "$flannel_env" ]; then
. $flannel_env
fi
if [ -n "$FLANNEL_SUBNET" ]; then
DOCKER_OPT_BIP="--bip=$FLANNEL_SUBNET"
fi
if [ -n "$FLANNEL_MTU" ]; then
DOCKER_OPT_MTU="--mtu=$FLANNEL_MTU"
fi
if [ -n "$FLANNEL_IPMASQ" ] && [ $ipmasq = true ] ; then
if [ "$FLANNEL_IPMASQ" = true ] ; then
DOCKER_OPT_IPMASQ="--ip-masq=false"
elif [ "$FLANNEL_IPMASQ" = false ] ; then
DOCKER_OPT_IPMASQ="--ip-masq=true"
else
echo "Invalid value of FLANNEL_IPMASQ: $FLANNEL_IPMASQ" >&2
exit 1
fi
fi
eval docker_opts="\$${combined_opts_key}"
if [ "$docker_opts" ]; then
docker_opts="$docker_opts ";
fi
echo -n "" >$docker_env
for opt in $(set | grep "DOCKER_OPT_"); do
OPT_NAME=$(echo $opt | awk -F "=" '{print $1;}');
OPT_VALUE=$(eval echo "\$$OPT_NAME");
if [ "$indiv_opts" = true ]; then
echo "$OPT_NAME=\"$OPT_VALUE\"" >>$docker_env;
fi
docker_opts="$docker_opts $OPT_VALUE";
done
if [ "$combined_opts" = true ]; then
echo "${combined_opts_key}=\"${docker_opts}\"" >>$docker_env
fi
install-cni容器
install-cni容器顾名思义就是负责安装cni插件的,把镜像里的flannel等二进制文件复制到宿主机的/etc/cni/net.d,注意这个目录要匹配kubelet对应的cni配置项,如果你没改kubelet默认配置,那么kubelet默认也是配置的这个cni目录。我们需要关注install-cni容器内的目录/文件:
- /host/etc/cni/net.d/
- /host/opt/cni/bin/
- /host/etc/cni/net.d/10-flannel.conflist
下面是我的环境对应的内容:
/host/etc/cni/net.d # pwd
/host/etc/cni/net.d
/host/etc/cni/net.d # ls
10-flannel.conflist dhcp ipvlan noop tuning
bridge flannel loopback portmap vlan
cnitool host-local macvlan ptp
/host/etc/cni/net.d # cd /host/opt/cni/bin/
/host/opt/cni/bin # ls
10-flannel.conflist dhcp ipvlan noop tuning
bridge flannel loopback portmap vlan
cnitool host-local macvlan ptp
/opt/cni/bin # ls
bridge dhcp host-local loopback noop ptp vlan
cnitool flannel ipvlan macvlan portmap tuning
/opt/cni/bin # cat /host/etc/cni/net.d/10-flannel.conflist
{
"name": "cbr0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
}
]
}
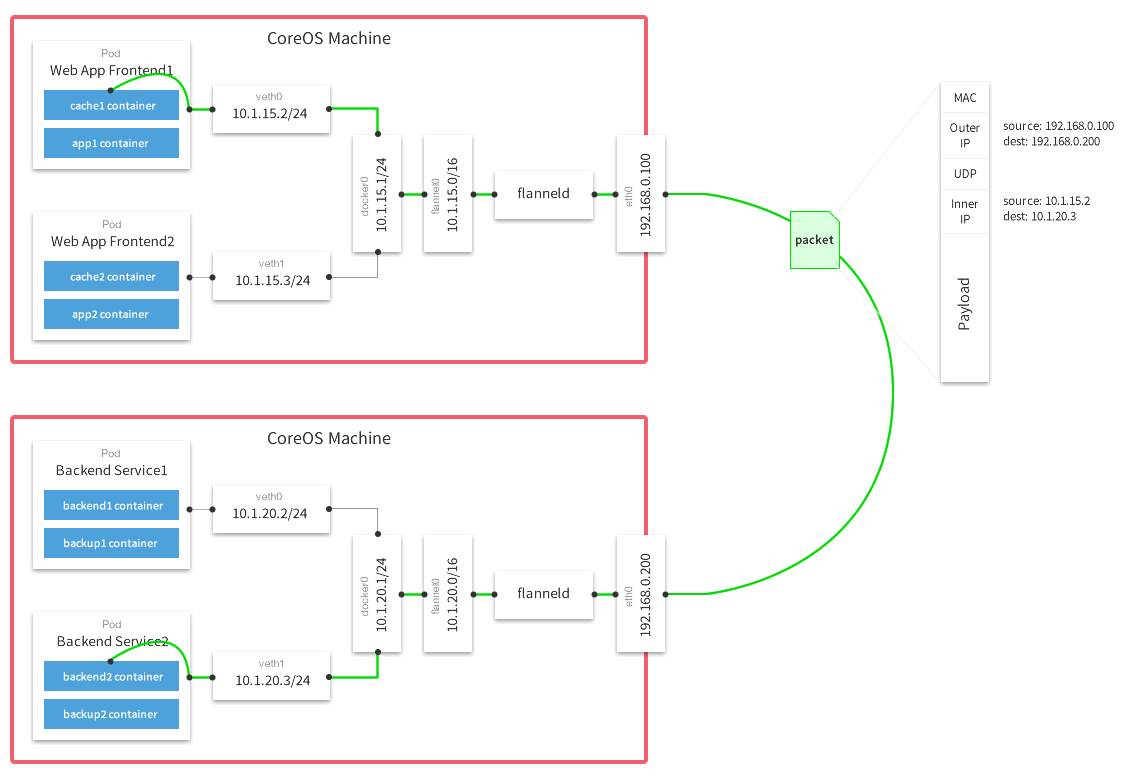
Flannel工作原理图
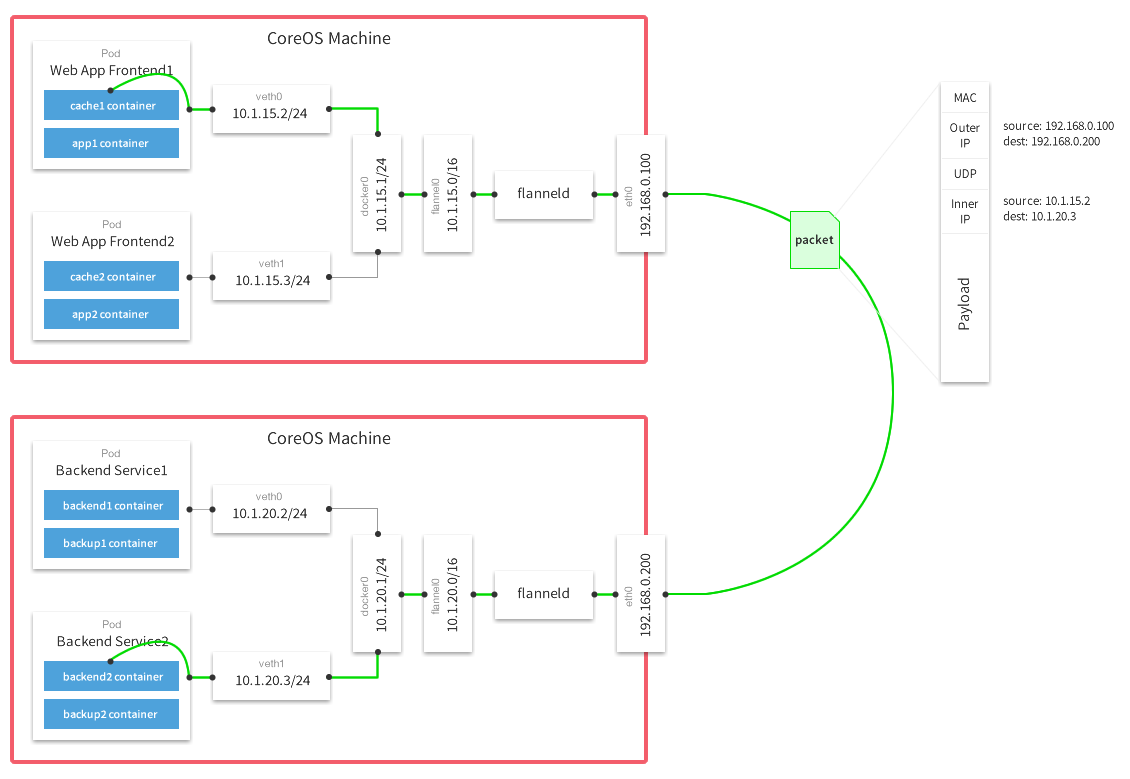
画一个图,应该就很清晰了。注意带颜色的部分是Volume对应的信息,可重点关注。
创建容器网络的流程就是:kubelet ——> flannel ——> flanneld。如果宿主机上并发创建Pod,则你会看到有多个flannel进程在后台,不过正常几秒钟就会结束,而flanneld是常驻进程。

Flannel host-gw Data Flow
Openshift默认也是使用Flannel host-gw容器网络方案,其官网也清晰的画出了host-gw的data flow diagram:

- Node 1中对应的ip routes:
default via 192.168.0.100 dev eth0 proto static metric 100 10.1.15.0/24 dev docker0 proto kernel scope link src 10.1.15.1 10.1.20.0/24 via 192.168.0.200 dev eth0 - Node 2中对应的ip routes:
default via 192.168.0.200 dev eth0 proto static metric 100 10.1.20.0/24 dev docker0 proto kernel scope link src 10.1.20.1 10.1.15.0/24 via 192.168.0.100 dev eth0
Kubernetes集群中使用Flannel的注意事项
在我的集群中是使用kube-subnet-mgr来管理subnet的,而不是直接通过etcd v2来管理的。
- flanneld启动时,需要对应Node上已经配置好PodCIDR,可通过get node信息查看
.spec.PodCIDR字段是否有值。 - 配置Node的CIDR可有两种方式:
- 手动配置每个Node上kubelet的
--pod-cidr; - 配置kube-controller-manager的
--allocate-node-cidrs=true --cluster-cidr=xx.xx.xx.xx/yy,由CIDR Controller自动给每个节点配置PodCIDR。
- 手动配置每个Node上kubelet的
- 另外,你还会发现每个Node都被打上了很多flannel开头的Annotation,这些Annotation会在每次flanneld启动时RegisterNetwork的时候进行更新。这些Annotation主要用于Node Lease。
- flannel.alpha.coreos.com/backend-data: "null"
- flannel.alpha.coreos.com/backend-type: host-gw
- flannel.alpha.coreos.com/kube-subnet-manager: "true"
- flannel.alpha.coreos.com/public-ip: xx.xx.xx.xx
- flannel.alpha.coreos.com/public-ip-overwrite:yy.yy.yy.yy (ps:optional)
下面是我的环境中某个节点的信息:
# kubectl get no 10.21.36.79 -o yaml
apiVersion: v1
kind: Node
metadata:
annotations:
flannel.alpha.coreos.com/backend-data: "null"
flannel.alpha.coreos.com/backend-type: host-gw
flannel.alpha.coreos.com/kube-subnet-manager: "true"
flannel.alpha.coreos.com/public-ip: 10.21.36.79
node.alpha.kubernetes.io/ttl: "0"
volumes.kubernetes.io/controller-managed-attach-detach: "true"
creationTimestamp: 2018-02-09T07:18:06Z
labels:
beta.kubernetes.io/arch: amd64
beta.kubernetes.io/os: linux
kubernetes.io/hostname: 10.21.36.79
name: 10.21.36.79
resourceVersion: "45074326"
selfLink: /api/v1/nodes/10.21.36.79
uid: 5f91765e-0d69-11e8-88cb-f403434bff24
spec:
externalID: 10.21.36.79
podCIDR: 10.244.29.0/24
status:
addresses:
- address: 10.21.36.79
type: InternalIP
- address: 10.21.36.79
type: Hostname
allocatable:
alpha.kubernetes.io/nvidia-gpu: "0"
cpu: "34"
memory: 362301176Ki
pods: "200"
capacity:
alpha.kubernetes.io/nvidia-gpu: "0"
cpu: "40"
memory: 395958008Ki
pods: "200"
conditions:
- lastHeartbeatTime: 2018-02-27T14:07:30Z
lastTransitionTime: 2018-02-13T13:05:57Z
message: kubelet has sufficient disk space available
reason: KubeletHasSufficientDisk
status: "False"
type: OutOfDisk
- lastHeartbeatTime: 2018-02-27T14:07:30Z
lastTransitionTime: 2018-02-13T13:05:57Z
message: kubelet has sufficient memory available
reason: KubeletHasSufficientMemory
status: "False"
type: MemoryPressure
- lastHeartbeatTime: 2018-02-27T14:07:30Z
lastTransitionTime: 2018-02-13T13:05:57Z
message: kubelet has no disk pressure
reason: KubeletHasNoDiskPressure
status: "False"
type: DiskPressure
- lastHeartbeatTime: 2018-02-27T14:07:30Z
lastTransitionTime: 2018-02-13T13:05:57Z
message: kubelet is posting ready status
reason: KubeletReady
status: "True"
type: Ready
daemonEndpoints:
kubeletEndpoint:
Port: 10250
images:
- names:
- registry.vivo.xyz:4443/bigdata_release/tensorflow1.5.0@sha256:6d61595c8e85d3724ec42298f8f97cdc782c5d83dd8f651c2eb037c25f525071
- registry.vivo.xyz:4443/bigdata_release/tensorflow1.5.0:v2.0
sizeBytes: 3217838862
- names:
- registry.vivo.xyz:4443/bigdata_release/tensorflow1.3.0@sha256:d14b7776578e3e844bab203b17ae504a0696038c7106469504440841ce17e85f
- registry.vivo.xyz:4443/bigdata_release/tensorflow1.3.0:v1.9
sizeBytes: 2504726638
- names:
- registry.vivo.xyz:4443/coreos/flannel-cni@sha256:dc5b5b370700645efcacb1984ae1e48ec9e297acbb536251689a239f13d08850
- registry.vivo.xyz:4443/coreos/flannel-cni:v0.3.0
sizeBytes: 49786179
- names:
- registry.vivo.xyz:4443/coreos/flannel@sha256:2a1361c414acc80e00514bc7abdbe0cd3dc9b65a181e5ac7393363bcc8621f39
- registry.vivo.xyz:4443/coreos/flannel:v0.10.0-amd64
sizeBytes: 44577768
- names:
- registry.vivo.xyz:4443/google_containers/pause-amd64@sha256:3b3a29e3c90ae7762bdf587d19302e62485b6bef46e114b741f7d75dba023bd3
- registry.vivo.xyz:4443/google_containers/pause-amd64:3.0
sizeBytes: 746888
nodeInfo:
architecture: amd64
bootID: bc7a36a4-2d9b-4caa-b852-445a5fb1b0b9
containerRuntimeVersion: docker://1.12.6
kernelVersion: 3.10.0-514.el7.x86_64
kubeProxyVersion: v1.7.4+793658f2d7ca7
kubeletVersion: v1.7.4+793658f2d7ca7
machineID: edaf7dacea45404b9b3cfe053181d317
operatingSystem: linux
osImage: CentOS Linux 7 (Core)
systemUUID: 30393137-3136-4336-5537-3335444C4C30© 著作权归作者所有
来源: https://my.oschina.net/jxcdwangtao/blog/1624486?nocache=1519707925759
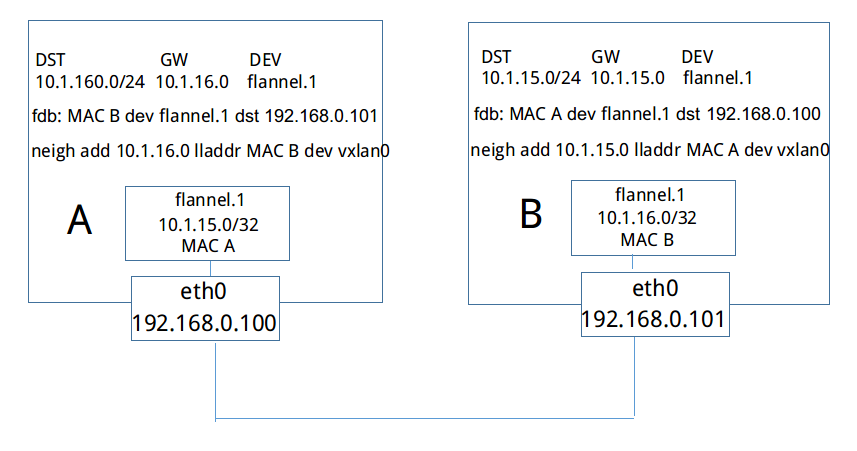
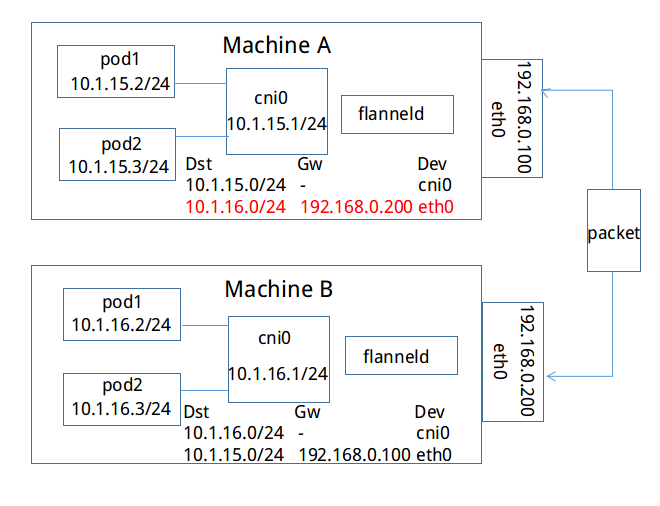 如果上方Machine A中IP地址为10.1.15.2/24的容器要与下方Machine B中IP地址为10.1.16.2/24的容器进行通信,封包是如何进行转发的。从上文可知,每个主机的flanneld会将自己与所获取subnet的关联信息存入etcd中,例如,subnet 10.1.15.0/24所在主机可通过IP 192.168.0.100访问,subnet 10.1.16.0/24可通过IP 192.168.0.200访问。反之,每台主机上的flanneld通过监听etcd,也能够知道其他的subnet与哪些主机相关联。如上图,Machine A上的flanneld通过监听etcd已经知道subnet 10.1.16.0/24所在的主机可以通过Public 192.168.0.200访问,而且熟悉docker桥接模式的同学肯定知道,目的地址为10.1.16.2/24的封包一旦到达Machine B,就能通过cni0网桥转发到相应的pod,从而达到跨宿主机通信的目的。
如果上方Machine A中IP地址为10.1.15.2/24的容器要与下方Machine B中IP地址为10.1.16.2/24的容器进行通信,封包是如何进行转发的。从上文可知,每个主机的flanneld会将自己与所获取subnet的关联信息存入etcd中,例如,subnet 10.1.15.0/24所在主机可通过IP 192.168.0.100访问,subnet 10.1.16.0/24可通过IP 192.168.0.200访问。反之,每台主机上的flanneld通过监听etcd,也能够知道其他的subnet与哪些主机相关联。如上图,Machine A上的flanneld通过监听etcd已经知道subnet 10.1.16.0/24所在的主机可以通过Public 192.168.0.200访问,而且熟悉docker桥接模式的同学肯定知道,目的地址为10.1.16.2/24的封包一旦到达Machine B,就能通过cni0网桥转发到相应的pod,从而达到跨宿主机通信的目的。