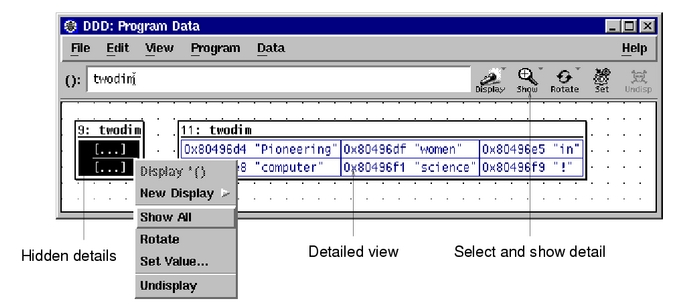
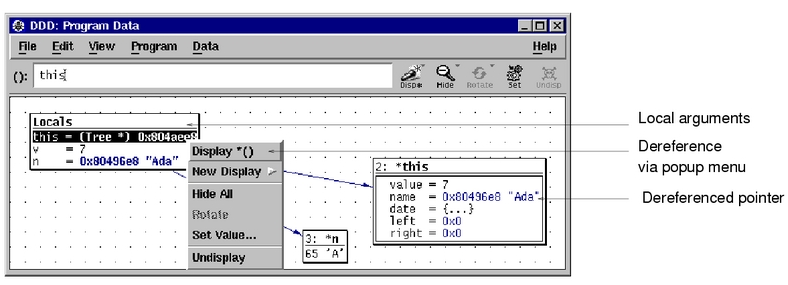
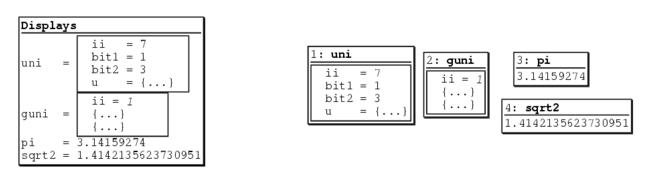
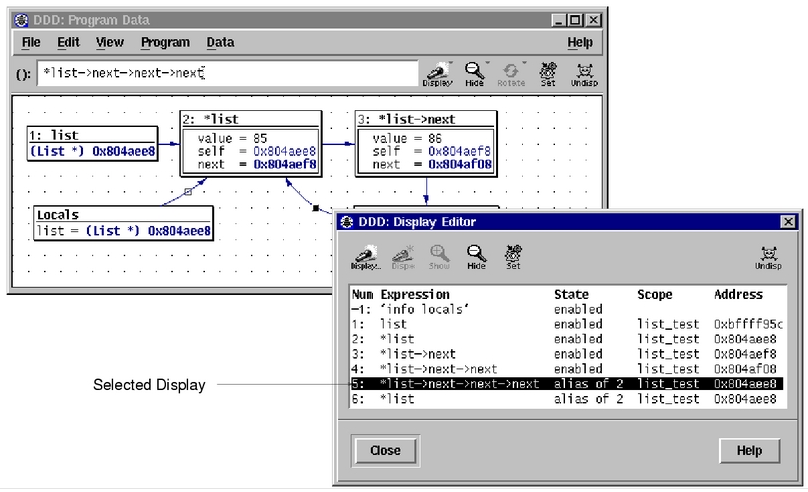
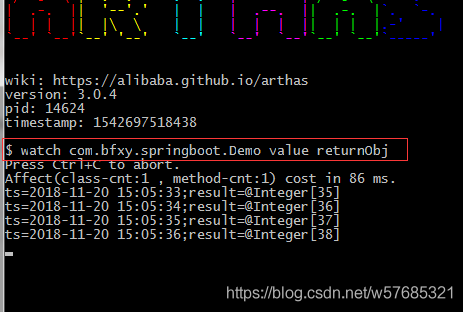
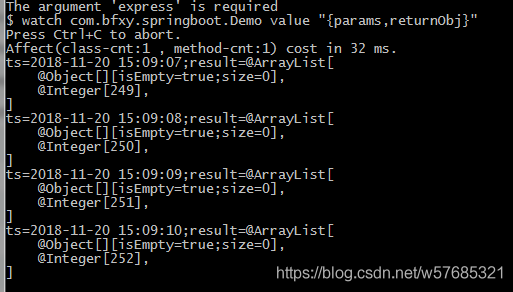
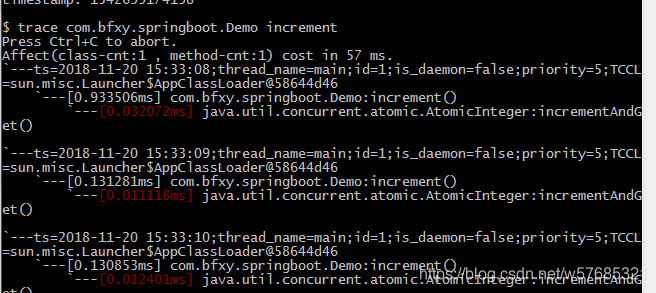
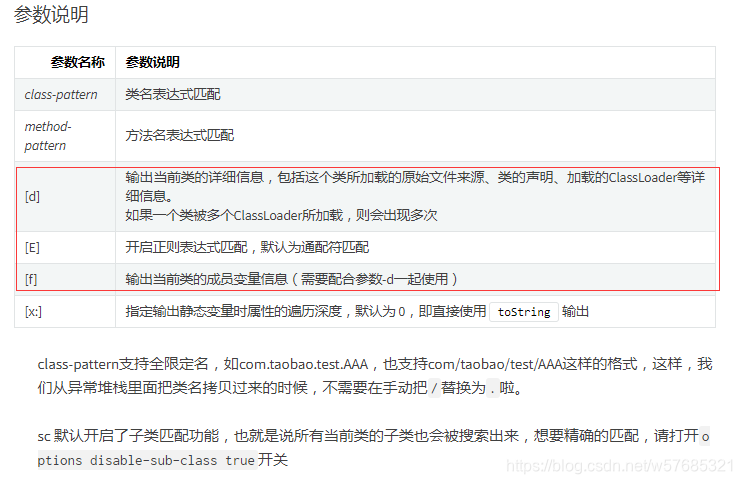
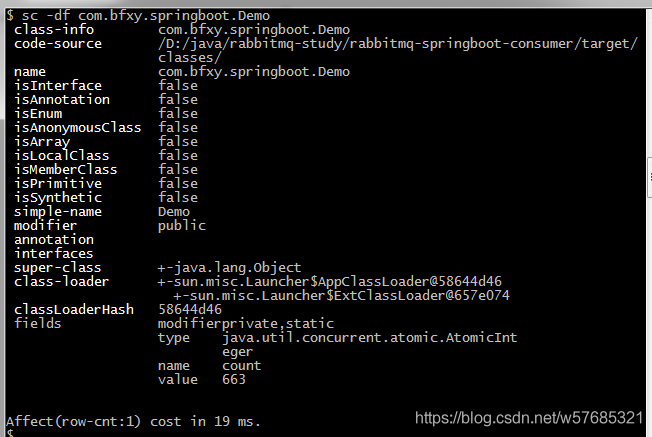
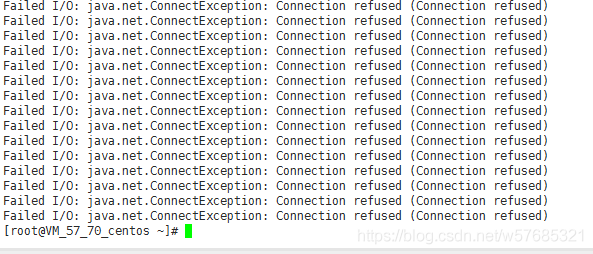
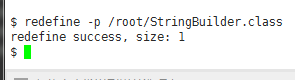
在嵌入式程序开发过程中,程序员要进行大量的调试,以此验证程序的正确性,修改潜在的错误。调试器对于程序员来说是不可或缺的必备工具。在Linux环境 中,有很多调试工具和调试辅助工具,例如GDB、XXGDB、RHIDE、XWPE、GVD和DDD等。其中,DDD是命令行调试器的图形前端,除了一般 的程序调试功能以外,还具有交互式图形数据显示的功能。它在嵌入式应用开发中也十分出色。本文主要讲述DDD(Data Display Debugger)的使用方法。
GNU DDD是命令行调试程序,如GDB、DBX、WDB、Ladebug、JDB、XDB、Perl Debugger或Python Debugger的可视化图形前端。它特有的图形数据显示功能(Graphical Data Display)可以把数据结构按照图形的方式显示出来。DDD最初源于1990年Andreas Zeller编写的VSL结构化语言,后来经过一些程序员的努力,演化成今天的模样。DDD的功能非常强大,可以调试用C\C++、Ada、 Fortran、Pascal、Modula-2和Modula-3编写的程序;可以超文本方式浏览源代码;能够进行断点设置、回溯调试和历史纪录编辑;具有程序在终端运行的仿真窗口,并在远程主机上进行调试的能力;图形数据显示功能(Graphical Data Display)是创建该调试器的初衷之一,能够显示各种数据结构之间的关系,并将数据结构以图形化形式显示;具有GDB/DBX/XDB的命令行界面,包括完全的文本编辑、历史纪录、搜寻引擎。
DDD是开源软件,用户可以去http://www.cs.tubs.de/softech/ddd/下载.rpm格式的DDD源码文件。
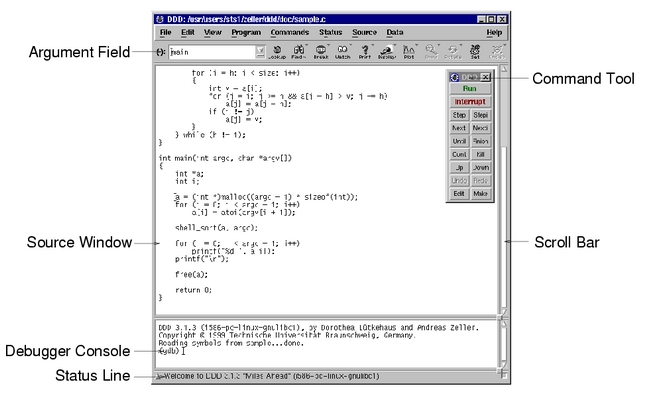
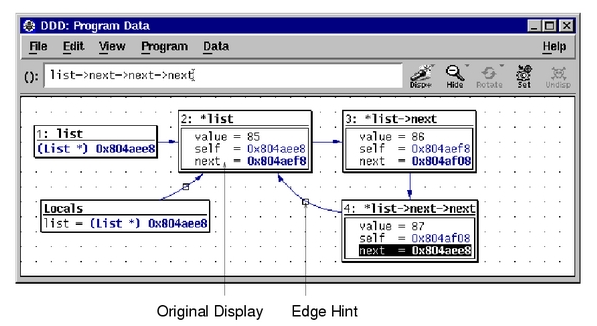
图1显示的是DDD的主窗口。它主要由选单栏、工具条、数据窗口、源文件窗口、机器码窗口、控制台和命令工具窗口等几部分组成。其中,数据窗口用于观察复杂的数据结构,在删除数据之后,显示仍然有效;源文件窗口显示源代码、断点和当前执行到达的位置,选择该窗口中的“Display”项,可以显示任意表达式的值;机器码窗口显示当前所选函数的机器代码,但仅对于GDB来说是可用的;在Debugger控制台里,用户可以与DDD内置调试器的命令行接口进行交互,等同于执行命令工具栏中的命令。
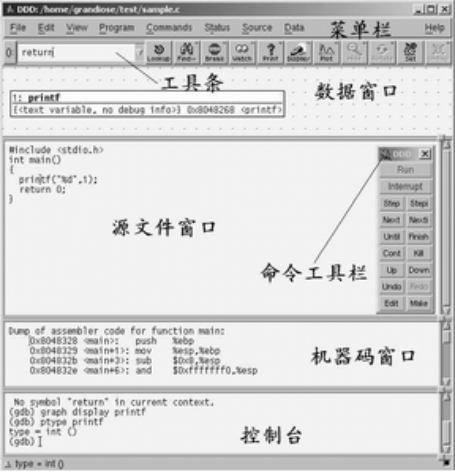
图1 DDD的主窗口
2.DDD运行机理
在设计DDD的时候,主创人员决定把它与GDB之间的耦合度尽可能降小。因为像GDB这样的开源软件,更新要比商业软件快。所以为了使GDB的变化不会影响到DDD,在DDD中,GDB是作为独立的进程运行的,通过命令行接口与DDD进行交互。
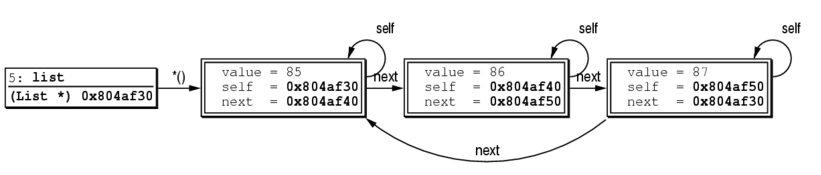
DDD 的运行机理如图2所示。它显示了用户、DDD、GDB和被调试进程之间的关系。为了使响应时间变小,DDD和GDB之间的所有通信都是异步进行的。在 DDD中发出的GDB命令都会与一个回调例程相连,放入命令队列中。这个回调例程在合适的时间会处理GDB的输出。例如,如果用户手动输入一条GDB的命令,DDD就会把这条命令与显示GDB输出的一个回调例程连起来。一旦GDB命令完成,就会触发回调例程,GDB的输出就会显示在DDD的命令窗口中。
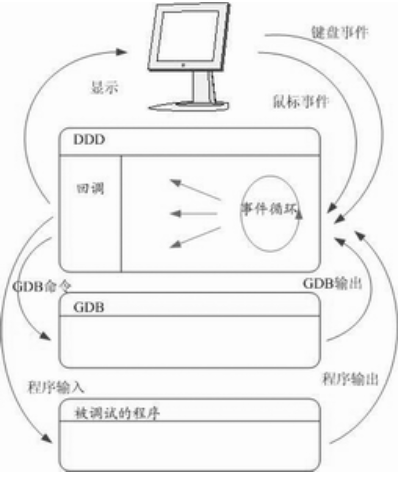
图2 DDD的运行机理
DDD 在事件循环时等待用户输入和GDB输出,同时等着GDB进入等待输入状态。当GDB可用时,下一条命令就会从命令队列中取出,送给GDB。GDB到达的输出由上次命令的回调过程来处理。这种异步机制避免了DDD在等待GDB输出时发生阻塞现象,到达的事件可以在任何时间得到处理。
DDD和GDB的分离使得DDD运行速度变慢,但这种方法还有很多好处。例如,用户可以把GDB调试器换成其它调试器,如DBX等。另外,还可以在不同的机器上运行GDB和DDD。
3. DDD调试示例
现在就用DDD来实际调试下面sample.c这段程序,为了节省空间,去掉了所有的注释。
#include <stdio.h>
#include <stdlib.h>
#define MAXINPUTSTRINGSIZE 5
int n;
int factn;
char resultstring[100];
int getInt()
{
char * inputString;
int inputInt;
inputString = (char *) malloc (MAXINPUTSTRINGSIZE * sizeof(char));
printf("Enter the value:");
fgets(inputString, MAXINPUTSTRINGSIZE, stdin);
printf("You entered %s\n", inputString);
inputInt = atoi(inputString);
return inputInt;
}
int computeFact(int n)
{
int accum=0;
while(n>1) {
accum *= n;
n--;
}
return accum;
}
char * buildResultString(int x, int factx)
{
char * resultString = (char *) malloc(100 * sizeof(char));
sprintf(resultString, "The factorial of %d is %d\n", x, factx);
return resultString;
}
void main(int argc, char * argv[])
{
char * outString; // The string we will print out
n = getInt();
factn = computeFact(n);
outString = buildResultString(n, factn);
printf("%s\n",outString);
} |
首先,使用下面的命令编译sample.c,切记要使用“-g”选项生成调试信息:
#gcc -g -o sample sample.c
接着运行sample程序,输入数值“5”后,可以看到如下结果:
You entered 5
The factorial of 5 is 0
可以看出,上面程序中是有错误的,需要进行调试。输入下面的命令启动DDD调试器,调试这个可执行程序:
#ddd sample
一段时间之后,DDD的主窗口就会出现。找到怀疑出错的地方,在相应的代码上设置断点(在有怀疑的行上单击鼠标左键,然后单击工具栏中的“Break”按钮)。然后单击命令工具栏上的运行按钮或在选单栏“Commands”里选择运行相关命令,如图3所示。
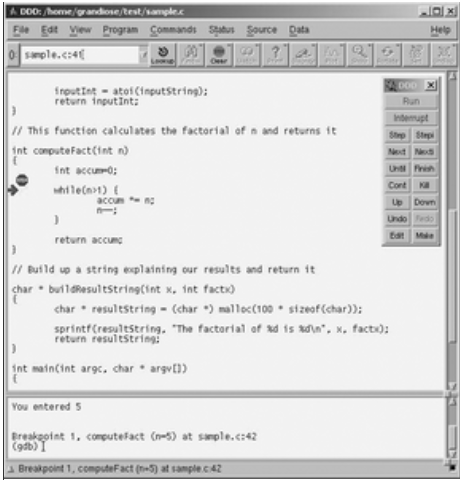
图3 使用DDD进行调试
在控制台中提示符下输入数字“5”后按回车键,就会运行到图3中箭头指示的位置。这时候检查可疑变量accum的值,在控制台提示后输入下面的命令:
(gdb) display accum
接着往下单步运行,多次点击工具栏中的“Step”按钮,观察变量accum的结果。具体参考如下:
(gdb) step
43 while(n>1) {
1: accum = 0
(gdb)
44 accum *= n;
1: accum = 0
(gdb)
45 n--;
1: accum = 0
(gdb)
43 while(n>1) {
1: accum = 0
(gdb)
44 accum *= n;
1: accum = 0
(gdb)
45 n--;
1: accum = 0 |
可以看出问题出在accum上。这时点击命令工具栏上的“Kill”按钮将程序断掉,把初始化accum的那一句改为“int accum = 1;”。重新运行之后,发现结果正确。至此,调试过程完毕。
4. 特殊功能
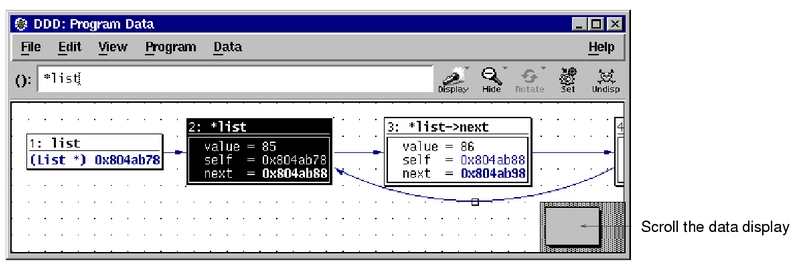
上面只是粗略地介绍了DDD调试的方法。实际上,DDD还有一些与众不同的功能,例如可视化显示数据结构(单个结构体、二叉树、链表等)和绘制数据集等。
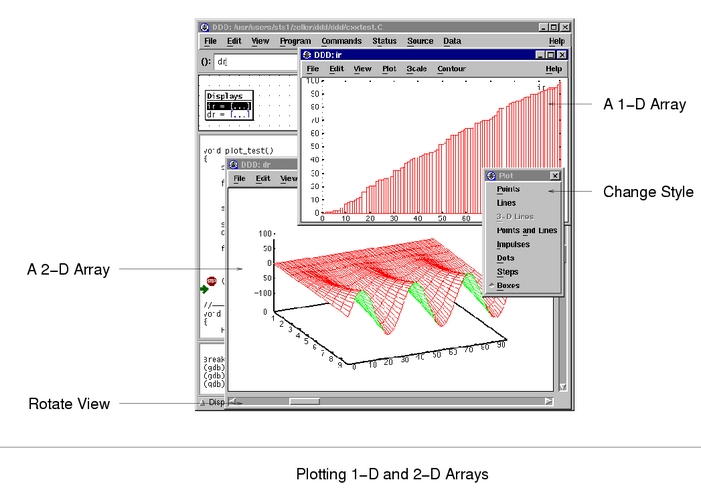
图4就是按点集绘制的数组sval中保存的数据(首先在源码窗口选中要显示的数组,然后点击工具栏中的“Plot”按钮,即会出现绘制窗口)。用户也可以不按数据点集显示,在弹出窗口选单“Plot”下选择“Lines”,就可以显示成连线段。这个功能非常直观,对于程序员调试程序来说是有很大帮助作用的。
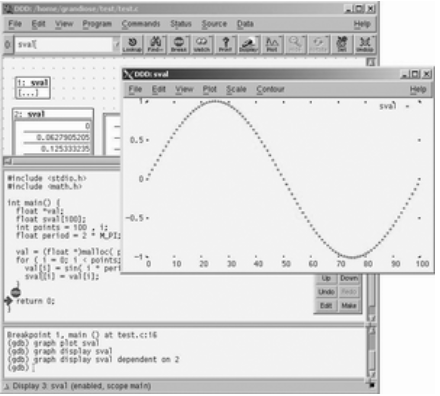
图4 绘制数据集
DDD包含的内容不止这些,由于篇幅的限制,这里就不多说了。希望能起到抛砖引玉的作用。如果用户想进一步学习,可以参考DDD的用户手册。
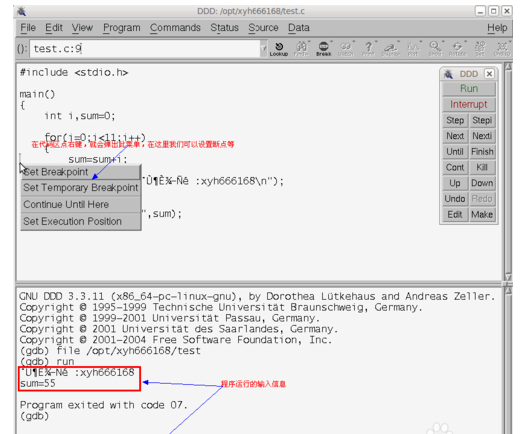
调试前的准备工作:制作一个程序文档,作为我们后面调试的对象
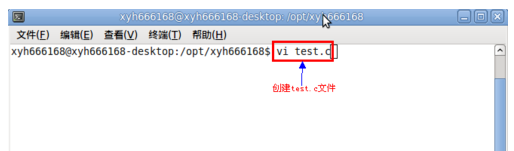
打开终端命令行窗口,输入命令vi test.c,建立test.c文件
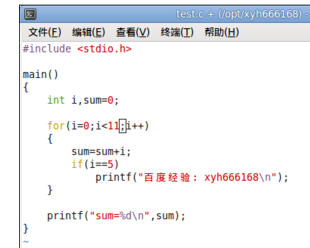
在test.c文件中输入一些C语言的程序数据,DDD工具可以调试很多种程序设置基于的代码,本文只以C语言作为说明对象,其它的有兴趣的可以去参考研究
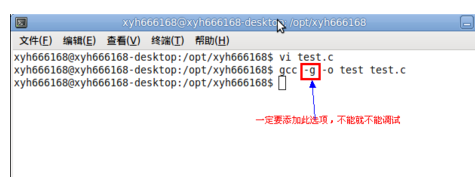
把test.c文件编译成可以执行的文件test,命令:gcc -g -o test test.c,注意一定要带-g参数,否则生成的可执行文件中没有必要的调试信息,最终使用DDD工具不能调试
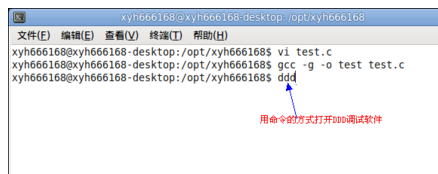
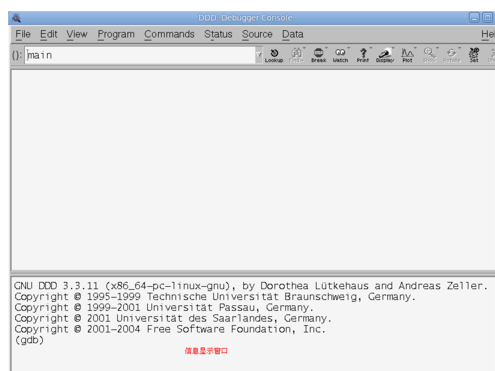
运行DDD调试工具,直接输入命令ddd就可以打开DDD工具
DDD工具打开后如下图所示,上面空白部分为代码区,和工具区,分割线下面是调试生成信息区
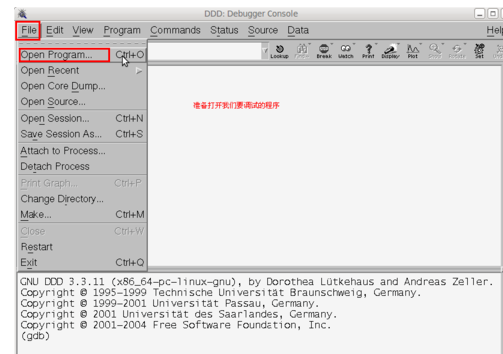
点击菜单栏上的“文件”----->“打开程序”,准备打开我们上面准备的test.c文件
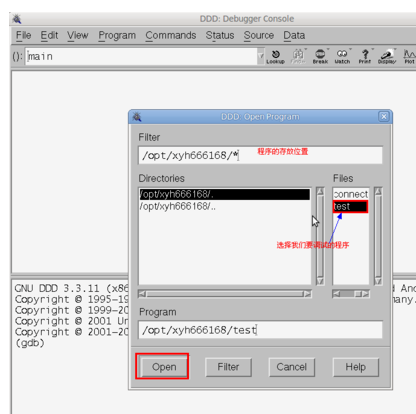
在打开程序框中,定位到我们要调试的程序的目录下,在Files列表下选择我们要调试 信息,之后点击左下方的打开按钮
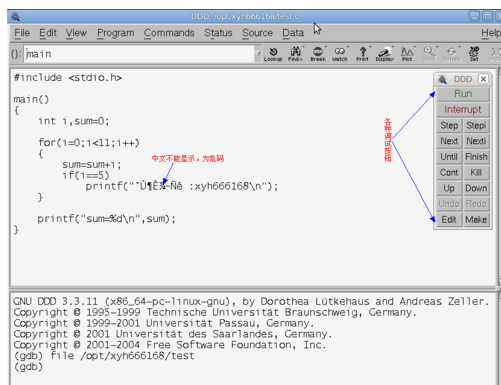
调试程序打开后,在代码区可以看到我们的代码,因为中文显示有点问题,其它都正常,右边的一些按钮是我们调试要用的工具
在代码区点鼠标右键,会弹出如图所示的菜单,我们可以给程序设置断点等,点击工具区里面的Run按钮,可以执行程序,在下面的调试信息区可以看到程序的执行结果。