Hazelcast简介
Github地址:https://github.com/hazelcast/hazelcast
官方网站:https://hazelcast.org/
API文档:https://docs.hazelcast.org/docs/latest/manual/html-single/index.html
Hazelcast特性:
1.强大的分布式计算:允许任意业务逻辑执行位置引用,并支持跨集群的分布式扩展。作为完全内存数据存储,Hazelcast IMDG可以在几微秒内转换和提取数据,提供吞吐量和查询。在Hazelcast里所有的数据结构都是分布式的,把多个节点当作一个节点使用,最常用的是map,其它的有Queue(队列),MultiMap,Set,List,跟java里的是一样的,因为实现了java里的泛型接口。
2.支持多种语言:Java, C++, .NET/C#, Python, Scala, and NodeJs
3.持久化:Hazelcast主要是解决访问分布式数据和进行分布式计算时保持低延迟。默认情况下,Hazelcast不涉及磁盘或其它持久化的存储。
4.简易性: Hazelcast 功能只需引用一个jar包,除此之外,不依赖任何第三方包。因此可以非常便捷高效的将其嵌入到各种应用服务器中,而不必担心带来额外的问题(jar包冲突、类型冲突等等)。他仅仅提供一系列分布式功能,而不需要绑定任何框架来使用,因此适用于任何场景。扩展,故障处理和恢复都是自动化的,以便于操作管理
5.自治集群(无中心化):Hazelcast 没有任何中心节点,在运行的过程中,它自己选定集群中的某个节点作为中心点来管理所有的节点
Hazelcast客户端(管理中心)下载
下载地址:https://hazelcast.org/download/
下载完解压即可,双击start.bat即可启动
这个是管理中心的登录URL
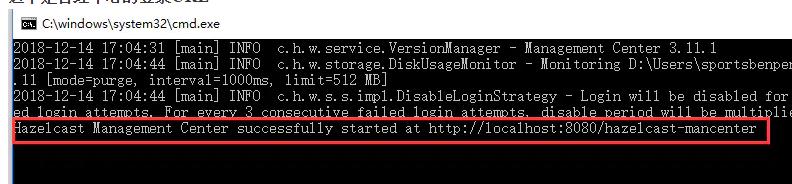
需要先设置账户密码,密码需要字母大小写还有数字
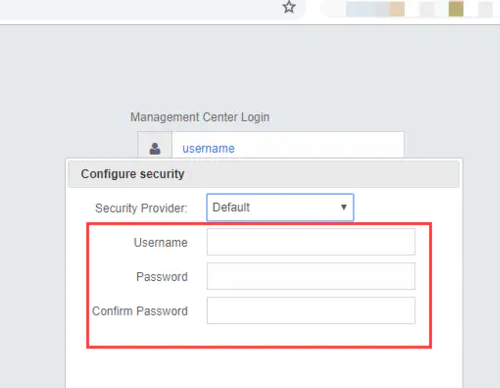
登录页面
与springboot进行集成
SpringBoot官方明确表示支持Hazelcast
https://docs.spring.io/spring-boot/docs/current/reference/html/boot-features-hazelcast.html
引入依赖
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>3.11</version>
</dependency>
引入Hazelcast.xml配置文件
模板可以在Github上找的:https://github.com/hazelcast/hazelcast/blob/master/hazelcast/src/main/resources/hazelcast-default.xml
<?xml version="1.0" encoding="UTF-8"?>
<hazelcast xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.hazelcast.com/schema/config
http://www.hazelcast.com/schema/config/hazelcast-config-3.11.xsd">
<group>
<name>dev</name>
<password>dev-pass</password>
</group>
<management-center enabled="true">http://localhost:8080/hazelcast-mancenter</management-center>
<network>
<port auto-increment="true" port-count="100">5701</port>
<outbound-ports>
<ports>0</ports>
</outbound-ports>
<join>
<multicast enabled="true">
<multicast-group>224.2.2.3</multicast-group>
<multicast-port>54327</multicast-port>
</multicast>
<tcp-ip enabled="false">
<interface>127.0.0.1</interface>
<member-list>
<member>127.0.0.1</member>
</member-list>
</tcp-ip>
<aws enabled="false">
<access-key>my-access-key</access-key>
<secret-key>my-secret-key</secret-key>
<region>us-west-1</region>
<host-header>ec2.amazonaws.com</host-header>
<security-group-name>hazelcast-sg</security-group-name>
<tag-key>type</tag-key>
<tag-value>hz-nodes</tag-value>
</aws>
<gcp enabled="false">
<zones>us-east1-b,us-east1-c</zones>
</gcp>
<azure enabled="false">
<client-id>CLIENT_ID</client-id>
<client-secret>CLIENT_SECRET</client-secret>
<tenant-id>TENANT_ID</tenant-id>
<subscription-id>SUB_ID</subscription-id>
<cluster-id>HZLCAST001</cluster-id>
<group-name>GROUP-NAME</group-name>
</azure>
<kubernetes enabled="false">
<namespace>MY-KUBERNETES-NAMESPACE</namespace>
<service-name>MY-SERVICE-NAME</service-name>
<service-label-name>MY-SERVICE-LABEL-NAME</service-label-name>
<service-label-value>MY-SERVICE-LABEL-VALUE</service-label-value>
</kubernetes>
<eureka enabled="false">
<self-registration>true</self-registration>
<namespace>hazelcast</namespace>
</eureka>
<discovery-strategies>
</discovery-strategies>
</join>
<interfaces enabled="false">
<interface>10.10.1.*</interface>
</interfaces>
<ssl enabled="false"/>
<socket-interceptor enabled="false"/>
<symmetric-encryption enabled="false">
<algorithm>PBEWithMD5AndDES</algorithm>
<salt>thesalt</salt>
<password>thepass</password>
<iteration-count>19</iteration-count>
</symmetric-encryption>
<failure-detector>
<icmp enabled="false"/>
</failure-detector>
</network>
<partition-group enabled="false"/>
<executor-service name="default">
<pool-size>16</pool-size>
<queue-capacity>0</queue-capacity>
</executor-service>
<security>
<client-block-unmapped-actions>true</client-block-unmapped-actions>
</security>
<queue name="default">
<max-size>0</max-size>
<backup-count>1</backup-count>
<async-backup-count>0</async-backup-count>
<empty-queue-ttl>-1</empty-queue-ttl>
<merge-policy batch-size="100">com.hazelcast.spi.merge.PutIfAbsentMergePolicy</merge-policy>
</queue>
<map name="default">
<in-memory-format>BINARY</in-memory-format>
<backup-count>1</backup-count>
<async-backup-count>0</async-backup-count>
<time-to-live-seconds>0</time-to-live-seconds>
<max-idle-seconds>0</max-idle-seconds>
<eviction-policy>NONE</eviction-policy>
<max-size policy="PER_NODE">0</max-size>
<eviction-percentage>25</eviction-percentage>
<min-eviction-check-millis>100</min-eviction-check-millis>
<merge-policy batch-size="100">com.hazelcast.spi.merge.PutIfAbsentMergePolicy</merge-policy>
<cache-deserialized-values>INDEX-ONLY</cache-deserialized-values>
</map>
<event-journal enabled="false">
<mapName>mapName</mapName>
<capacity>10000</capacity>
<time-to-live-seconds>0</time-to-live-seconds>
</event-journal>
<event-journal enabled="false">
<cacheName>cacheName</cacheName>
<capacity>10000</capacity>
<time-to-live-seconds>0</time-to-live-seconds>
</event-journal>
<merkle-tree enabled="false">
<mapName>mapName</mapName>
<depth>10</depth>
</merkle-tree>
<multimap name="default">
<backup-count>1</backup-count>
<value-collection-type>SET</value-collection-type>
<merge-policy batch-size="100">com.hazelcast.spi.merge.PutIfAbsentMergePolicy</merge-policy>
</multimap>
<replicatedmap name="default">
<in-memory-format>OBJECT</in-memory-format>
<async-fillup>true</async-fillup>
<statistics-enabled>true</statistics-enabled>
<merge-policy batch-size="100">com.hazelcast.spi.merge.PutIfAbsentMergePolicy</merge-policy>
</replicatedmap>
<list name="default">
<backup-count>1</backup-count>
<merge-policy batch-size="100">com.hazelcast.spi.merge.PutIfAbsentMergePolicy</merge-policy>
</list>
<set name="default">
<backup-count>1</backup-count>
<merge-policy batch-size="100">com.hazelcast.spi.merge.PutIfAbsentMergePolicy</merge-policy>
</set>
<jobtracker name="default">
<max-thread-size>0</max-thread-size>
<!-- Queue size 0 means number of partitions * 2 -->
<queue-size>0</queue-size>
<retry-count>0</retry-count>
<chunk-size>1000</chunk-size>
<communicate-stats>true</communicate-stats>
<topology-changed-strategy>CANCEL_RUNNING_OPERATION</topology-changed-strategy>
</jobtracker>
<semaphore name="default">
<initial-permits>0</initial-permits>
<backup-count>1</backup-count>
<async-backup-count>0</async-backup-count>
</semaphore>
<reliable-topic name="default">
<read-batch-size>10</read-batch-size>
<topic-overload-policy>BLOCK</topic-overload-policy>
<statistics-enabled>true</statistics-enabled>
</reliable-topic>
<ringbuffer name="default">
<capacity>10000</capacity>
<backup-count>1</backup-count>
<async-backup-count>0</async-backup-count>
<time-to-live-seconds>0</time-to-live-seconds>
<in-memory-format>BINARY</in-memory-format>
<merge-policy batch-size="100">com.hazelcast.spi.merge.PutIfAbsentMergePolicy</merge-policy>
</ringbuffer>
<flake-id-generator name="default">
<prefetch-count>100</prefetch-count>
<prefetch-validity-millis>600000</prefetch-validity-millis>
<id-offset>0</id-offset>
<node-id-offset>0</node-id-offset>
<statistics-enabled>true</statistics-enabled>
</flake-id-generator>
<atomic-long name="default">
<merge-policy batch-size="100">com.hazelcast.spi.merge.PutIfAbsentMergePolicy</merge-policy>
</atomic-long>
<atomic-reference name="default">
<merge-policy batch-size="100">com.hazelcast.spi.merge.PutIfAbsentMergePolicy</merge-policy>
</atomic-reference>
<count-down-latch name="default"/>
<serialization>
<portable-version>0</portable-version>
</serialization>
<services enable-defaults="true"/>
<lite-member enabled="false"/>
<cardinality-estimator name="default">
<backup-count>1</backup-count>
<async-backup-count>0</async-backup-count>
<merge-policy batch-size="100">HyperLogLogMergePolicy</merge-policy>
</cardinality-estimator>
<scheduled-executor-service name="default">
<capacity>100</capacity>
<durability>1</durability>
<pool-size>16</pool-size>
<merge-policy batch-size="100">com.hazelcast.spi.merge.PutIfAbsentMergePolicy</merge-policy>
</scheduled-executor-service>
<crdt-replication>
<replication-period-millis>1000</replication-period-millis>
<max-concurrent-replication-targets>1</max-concurrent-replication-targets>
</crdt-replication>
<pn-counter name="default">
<replica-count>2147483647</replica-count>
<statistics-enabled>true</statistics-enabled>
</pn-counter>
</hazelcast>
<management-center>中enabled属性需要设置为true才能开启Hazelcast管理中心,默认为false
<outbound-ports>表示允许连接到其他节点的端口范围。 0或*表示使用系统提供的端口。
<network>是非常重要的元素,指定Hazelcast的网络环境。
<port>指定Hazelcast将用于在集群成员之间进行通信的端口。
<multicast >组播,不建议将生成多播机制用于生产,因为UDP通常在生产环境中被阻止,而其他发现机制更明确。
<tcp-ip>TCP / IP群集
<queue name="default">队列名
<max-size>队列的最大大小。当JVM的本地队列大小达到最大值时,所有put / offer操作都将被阻塞,直到JVM的队列大小低于最大值。 0到Integer.MAX_VALUE之间的任何整数。
<backup-count>备份数量。例如,如果将1设置为备份计数,则映射的所有条目都将复制到另一个JVM以实现故障安全。 0表示没有备份
<async-backup-count>异步备份的数量。 0表示没有备份
具体的配置说明可以参考:
https://docs.hazelcast.org/docs/latest/manual/html-single/#understanding-configuration
测试代码
@Component
public class HazelcastGetStartServerMaster {
private HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance();
@PostConstruct
public void put(){
Map map = hazelcastInstance.getMap("hello");
map.put("hello","world");
}
}
启动测试之前需要先启动Hazelcast管理中心
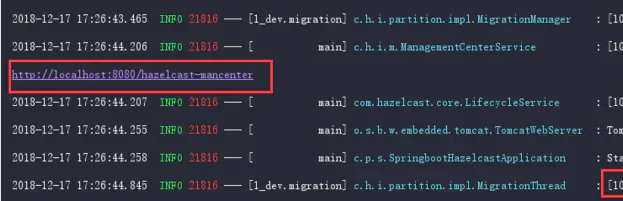
启动成功会显示管理中心的URL
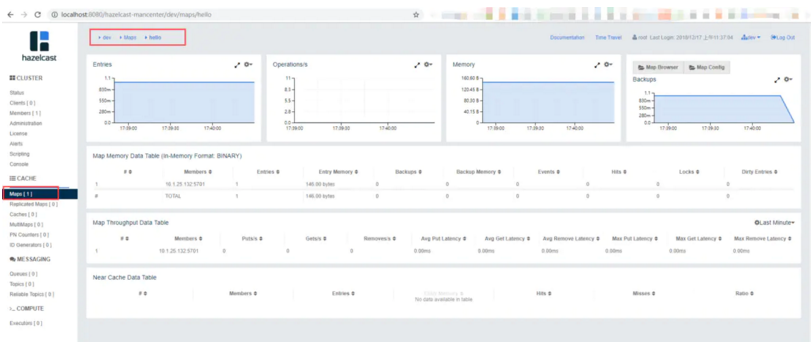
在管理中心可以看到