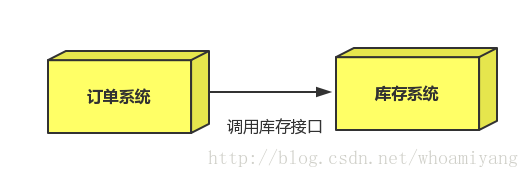
- 商品的原始数据保存在数据库中,增删改查都在数据库中完成。
- 搜索服务数据来源是索引库(Elasticsearch),如果数据库商品发生变化,索引库数据不能及时更新。
- 商品详情做了页面静态化处理,静态页面数据也不会随着数据库商品更新而变化。
如果我们在后台修改了商品的价格,搜索页面和商品详情页显示的依然是旧的价格,这样显然不对。该如何解决?
我们可能会想到这么做:
- 方案1:每当后台对商品做增删改操作,同时修改索引库数据及更新静态页面。
- 方案2:搜索服务和商品页面静态化服务对外提供操作接口,后台在商品增删改后,调用接口。
这两种方案都有个严重的问题:就是代码耦合,后台服务中需要嵌入搜索和商品页面服务,违背了微服务的独立原则。
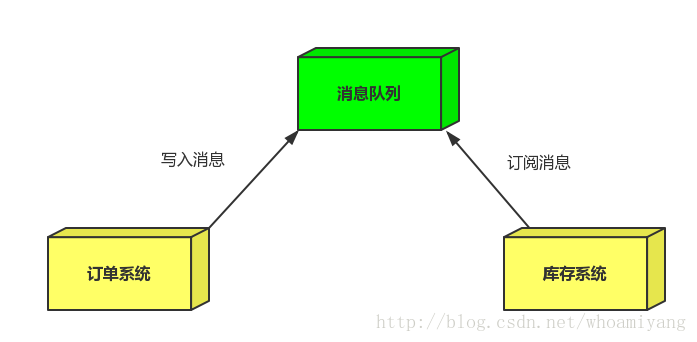
这时,我们就会采用另外一种解决办法,那就是消息队列!
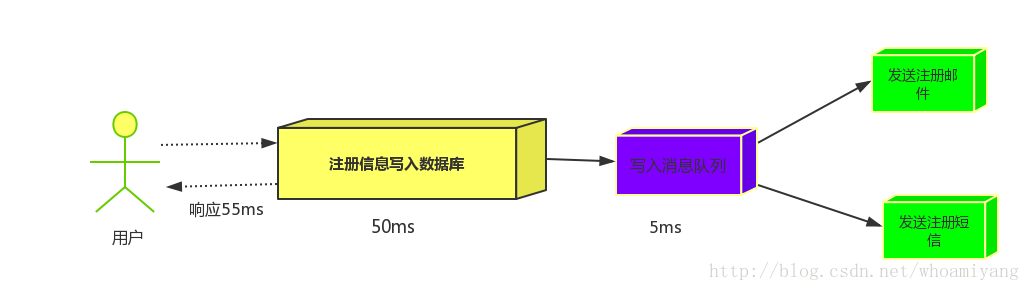
商品服务对商品增删改以后,无需去操作索引库和静态页面,只需向MQ发送一条消息(比如包含商品id的消息),也不关心消息被谁接收。 搜索服务和静态页面服务监听MQ,接收消息,然后分别去处理索引库和静态页面(根据商品id去更新索引库和商品详情静态页面)。
什么是消息队列
MQ全称为Message Queue,即消息队列。“消息队列”是在消息的传输过程中保存消息的容器。它是典型的:生产者、消费者模型。生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息。因为消息的生产和消费都是异步的,而且只关心消息的发送和接收,没有业务逻辑的侵入,这样就实现了生产者和消费者的解耦。
开发中消息队列通常有如下应用场景:
1、任务异步处理:
高并发环境下,由于来不及同步处理,请求往往会发生堵塞,比如说,大量的insert,update之类的请求同时到达MySQL,直接导致无数的行锁表锁,甚至最后请求会堆积过多,从而触发too many connections错误。通过使用消息队列,我们可以异步处理请求,从而缓解系统的压力。将不需要同步处理的并且耗时长的操作由消息队列通知消息接收方进行异步处理。减少了应用程序的响应时间。
2、应用程序解耦合:
MQ相当于一个中介,生产方通过MQ与消费方交互,它将应用程序进行解耦合。
AMQP和JMS
MQ是消息通信的模型,并发具体实现。现在实现MQ的有两种主流方式:AMQP、JMS。
两者间的区别和联系:
- JMS是定义了统一的接口,来对消息操作进行统一;AMQP是通过规定协议来统一数据交互的格式
- JMS限定了必须使用Java语言;AMQP只是协议,不规定实现方式,因此是跨语言的。
- JMS规定了两种消息模型;而AMQP的消息模型更加丰富
常见MQ产品
- ActiveMQ:基于JMS
- RabbitMQ:基于AMQP协议,erlang语言开发,稳定性好
- RocketMQ:基于JMS,阿里巴巴产品,目前交由Apache基金会
- Kafka:分布式消息系统,高吞吐量
RabbitMQ快速入门
RabbitMQ是由erlang语言开发,基于AMQP(Advanced Message Queue 高级消息队列协议)协议实现的消息队列,它是一种应用程序之间的通信方法,消息队列在分布式系统开发中应用非常广泛。RabbitMQ官方地址:http://www.rabbitmq.com
下载与安装
RabbitMQ由Erlang语言开发,需要安装与RabbitMQ版本对应的Erlang语言环境,具体的就不解释了,自行搜索教程。RabbitMQ官网下载地址:http://www.rabbitmq.com/download.html
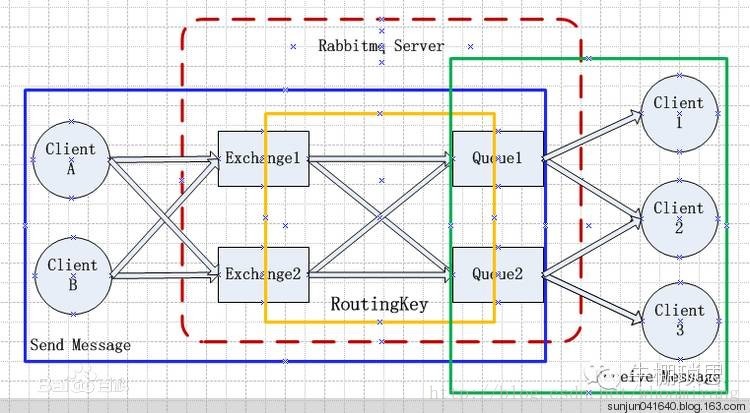
RabbitMQ的工作原理
下图是RabbitMQ的基本结构:
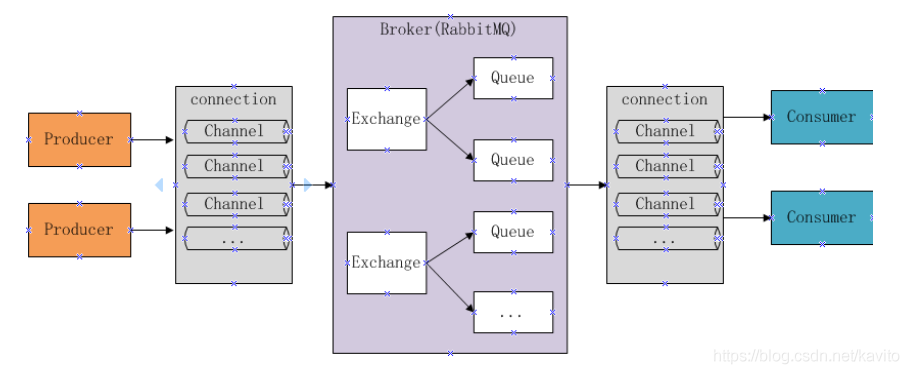
组成部分说明:
- Broker:消息队列服务进程,此进程包括两个部分:Exchange和Queue
- Exchange:消息队列交换机,按一定的规则将消息路由转发到某个队列,对消息进行过虑。
- Queue:消息队列,存储消息的队列,消息到达队列并转发给指定的
- Producer:消息生产者,即生产方客户端,生产方客户端将消息发送
- Consumer:消息消费者,即消费方客户端,接收MQ转发的消息。
生产者发送消息流程:
1、生产者和Broker建立TCP连接。
2、生产者和Broker建立通道。
3、生产者通过通道消息发送给Broker,由Exchange将消息进行转发。
4、Exchange将消息转发到指定的Queue(队列)
消费者接收消息流程:
1、消费者和Broker建立TCP连接
2、消费者和Broker建立通道
3、消费者监听指定的Queue(队列)
4、当有消息到达Queue时Broker默认将消息推送给消费者。
5、消费者接收到消息。
6、ack回复
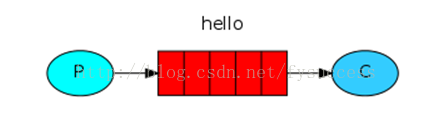
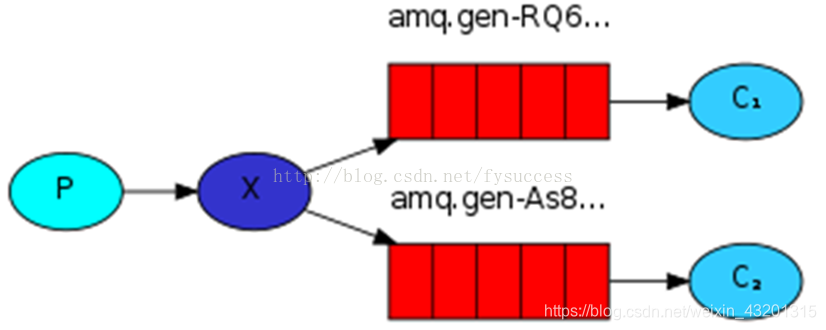
①基本消息模型:

在上图的模型中,有以下概念:
- P:生产者,也就是要发送消息的程序
- C:消费者:消息的接受者,会一直等待消息到来。
- queue:消息队列,图中红色部分。可以缓存消息;生产者向其中投递消息,消费者从其中取出消息。
生产者
新建一个maven工程,添加amqp-client依赖
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
连接工具类:
public class ConnectionUtil {
public static Connection getConnection() throws Exception {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.1.103");
factory.setVirtualHost("/kavito");
factory.setUsername("kavito");
factory.setPassword("123456");
Connection connection = factory.newConnection();
生产者发送消息:
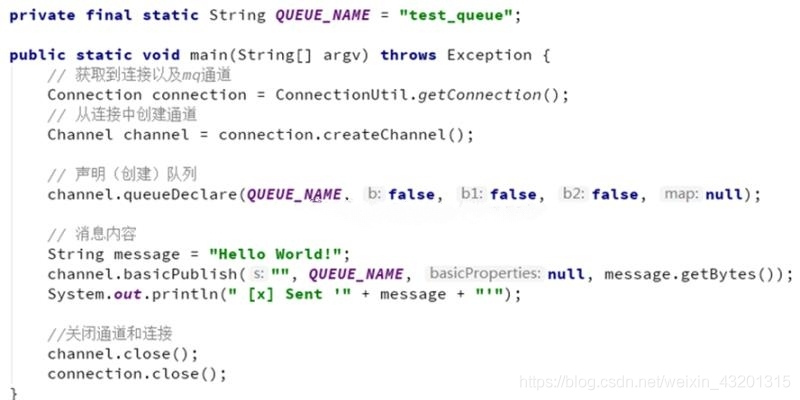
private final static String QUEUE_NAME = "simple_queue";
public static void main(String[] argv) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
String message = "Hello World!";
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
控制台:

web管理页面:服务器地址/端口号 (本地:127.0.0.1:15672,默认用户及密码:guest guest)
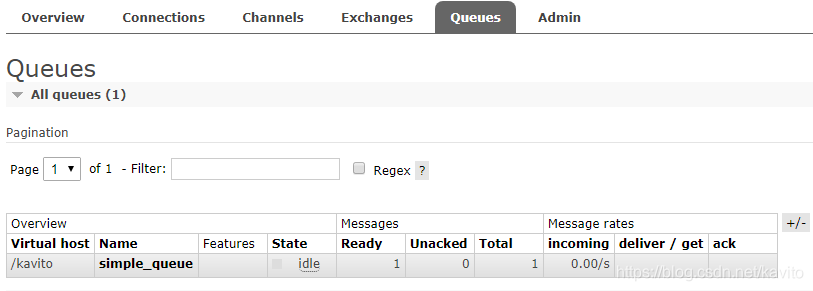
点击队列名称,进入详情页,可以查看消息:
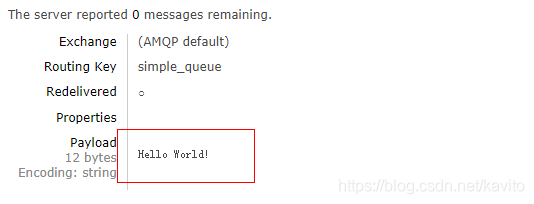
消费者接收消息
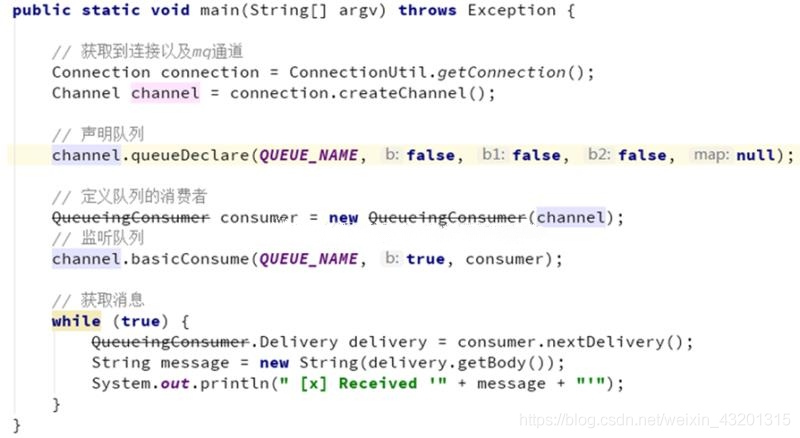
private final static String QUEUE_NAME = "simple_queue";
public static void main(String[] argv) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
DefaultConsumer consumer = new DefaultConsumer(channel){
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String exchange = envelope.getExchange();
long deliveryTag = envelope.getDeliveryTag();
String msg = new String(body,"utf-8");
System.out.println(" [x] received : " + msg + "!");
channel.basicConsume(QUEUE_NAME, true, consumer);
控制台打印:

再看看队列的消息,已经被消费了

我们发现,消费者已经获取了消息,但是程序没有停止,一直在监听队列中是否有新的消息。一旦有新的消息进入队列,就会立即打印.
消息确认机制(ACK)
通过刚才的案例可以看出,消息一旦被消费者接收,队列中的消息就会被删除。
那么问题来了:RabbitMQ怎么知道消息被接收了呢?
如果消费者领取消息后,还没执行操作就挂掉了呢?或者抛出了异常?消息消费失败,但是RabbitMQ无从得知,这样消息就丢失了!
因此,RabbitMQ有一个ACK机制。当消费者获取消息后,会向RabbitMQ发送回执ACK,告知消息已经被接收。不过这种回执ACK分两种情况:
- 自动ACK:消息一旦被接收,消费者自动发送ACK
- 手动ACK:消息接收后,不会发送ACK,需要手动调用
大家觉得哪种更好呢?
这需要看消息的重要性:
- 如果消息不太重要,丢失也没有影响,那么自动ACK会比较方便
- 如果消息非常重要,不容丢失。那么最好在消费完成后手动ACK,否则接收消息后就自动ACK,RabbitMQ就会把消息从队列中删除。如果此时消费者宕机,那么消息就丢失了。
我们之前的测试都是自动ACK的,如果要手动ACK,需要改动我们的代码:
private final static String QUEUE_NAME = "simple_queue";
public static void main(String[] argv) throws Exception {
Connection connection = ConnectionUtil.getConnection();
final Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
DefaultConsumer consumer = new DefaultConsumer(channel) {
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String msg = new String(body);
System.out.println(" [x] received : " + msg + "!");
channel.basicAck(envelope.getDeliveryTag(), false);
channel.basicConsume(QUEUE_NAME, false, consumer);
最后一行代码设置第二个参数为false
channel.basicConsume(QUEUE_NAME, false, consumer);
自动ACK存在的问题
修改消费者,添加异常,如下:
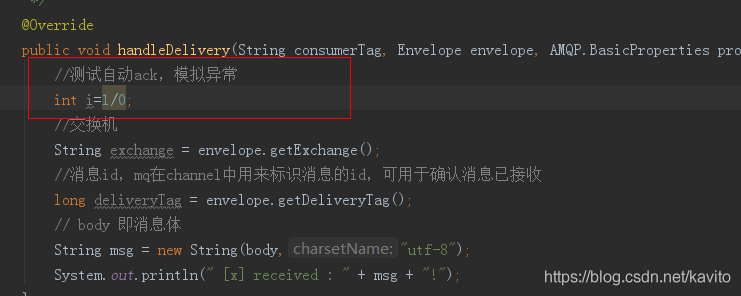
生产者不做任何修改,直接运行,消息发送成功:

运行消费者,程序抛出异常:

管理界面:

消费者抛出异常,但是消息依然被消费,实际上我们还没获取到消息。
演示手动ACK
重新运行生产者发送消息:
同样,在手动进行ack前抛出异常,运行Recv2
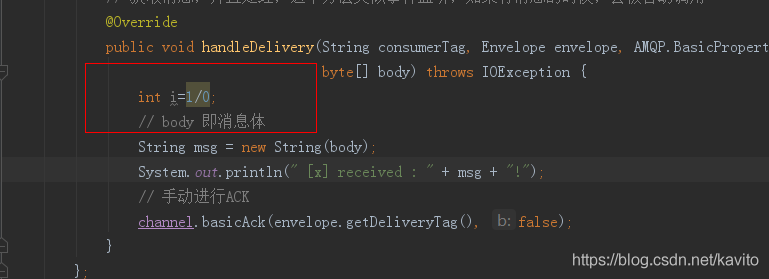
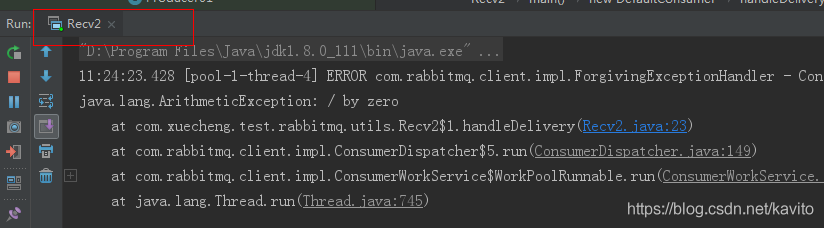
再看看管理界面:

消息没有被消费掉!
还有另外一种情况:修改消费者Recv2,把监听队列第二个参数自动改成手动,(去掉之前制造的异常) ,并且消费方法中没手动进行ACK
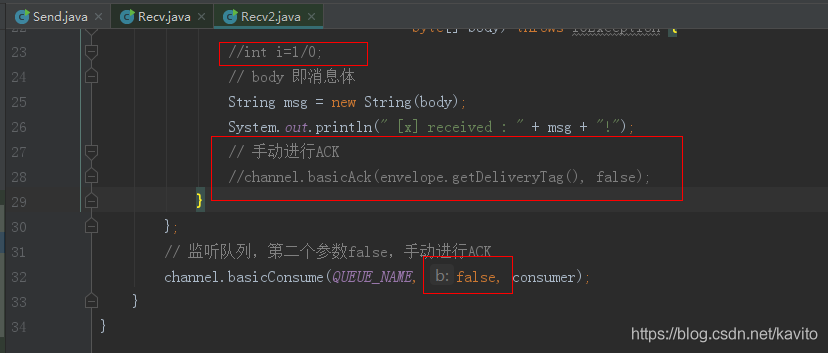
生产者代码不变,再次运行:
运行消费者 :

但是,查看管理界面,发现:

停掉消费者的程序,发现:

这是因为虽然我们设置了手动ACK,但是代码中并没有进行消息确认!所以消息并未被真正消费掉。当我们关掉这个消费者,消息的状态再次变为Ready。
正确的做法是:
我们要在监听队列时设置第二个参数为false,代码中手动进行ACK
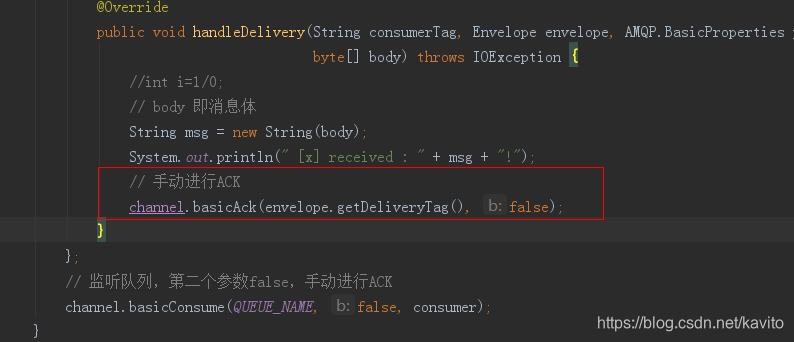
再次运行消费者,查看web管理页面:

消费者消费成功!
生产者避免数据丢失:https://www.cnblogs.com/vipstone/p/9350075.html
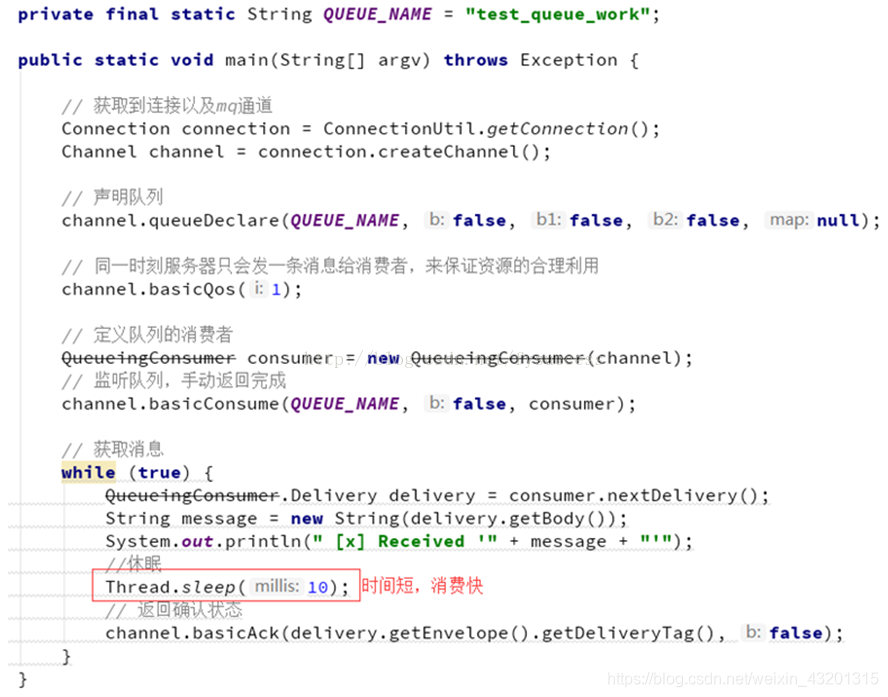
②work消息模型
工作队列或者竞争消费者模式

work queues与入门程序相比,多了一个消费端,两个消费端共同消费同一个队列中的消息,但是一个消息只能被一个消费者获取。
这个消息模型在Web应用程序中特别有用,可以处理短的HTTP请求窗口中无法处理复杂的任务。
接下来我们来模拟这个流程:
P:生产者:任务的发布者
C1:消费者1:领取任务并且完成任务,假设完成速度较慢(模拟耗时)
C2:消费者2:领取任务并且完成任务,假设完成速度较快
生产者
生产者循环发送50条消息
private final static String QUEUE_NAME = "test_work_queue";
public static void main(String[] argv) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
for (int i = 0; i < 50; i++) {
String message = "task .. " + i;
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
消费者1
private final static String QUEUE_NAME = "test_work_queue";
public static void main(String[] argv) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
DefaultConsumer consumer = new DefaultConsumer(channel){
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String msg = new String(body,"utf-8");
System.out.println(" [消费者1] received : " + msg + "!");
try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { e.printStackTrace(); }
channel.basicConsume(QUEUE_NAME, true, consumer);
消费者2
代码不贴了,与消费者1基本类似,只是消费者2没有设置消费耗时时间。
接下来,两个消费者一同启动,然后发送50条消息:
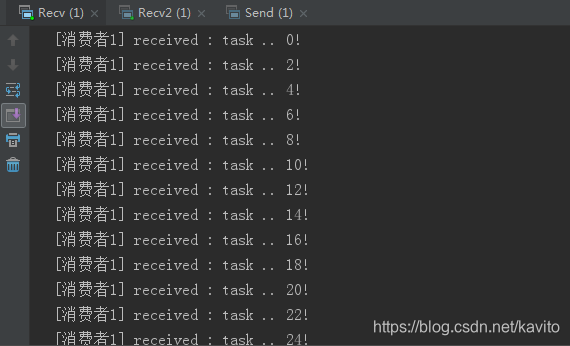
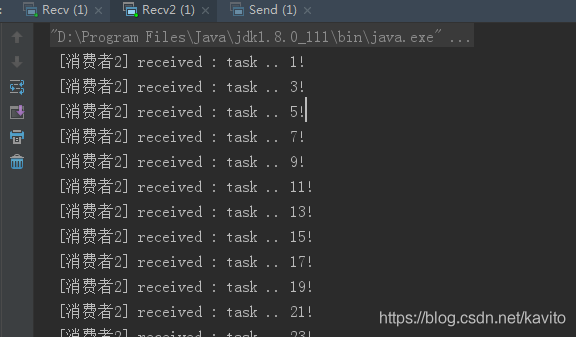
可以发现,两个消费者各自消费了不同25条消息,这就实现了任务的分发。
能者多劳
刚才的实现有问题吗?
- 消费者1比消费者2的效率要低,一次任务的耗时较长
- 然而两人最终消费的消息数量是一样的
- 消费者2大量时间处于空闲状态,消费者1一直忙碌
现在的状态属于是把任务平均分配,正确的做法应该是消费越快的人,消费的越多。
怎么实现呢?
通过 BasicQos 方法设置prefetchCount = 1。这样RabbitMQ就会使得每个Consumer在同一个时间点最多处理1个Message。换句话说,在接收到该Consumer的ack前,他它不会将新的Message分发给它。相反,它会将其分派给不是仍然忙碌的下一个Consumer。
值得注意的是:prefetchCount在手动ack的情况下才生效,自动ack不生效。

再次测试:

订阅模型分类
说明下:
1、一个生产者多个消费者
2、每个消费者都有一个自己的队列
3、生产者没有将消息直接发送给队列,而是发送给exchange(交换机、转发器)
4、每个队列都需要绑定到交换机上
5、生产者发送的消息,经过交换机到达队列,实现一个消息被多个消费者消费
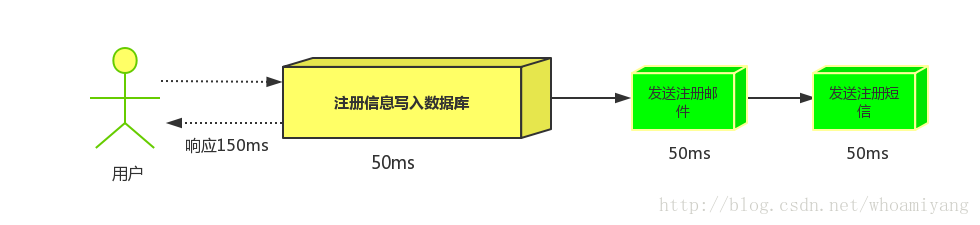
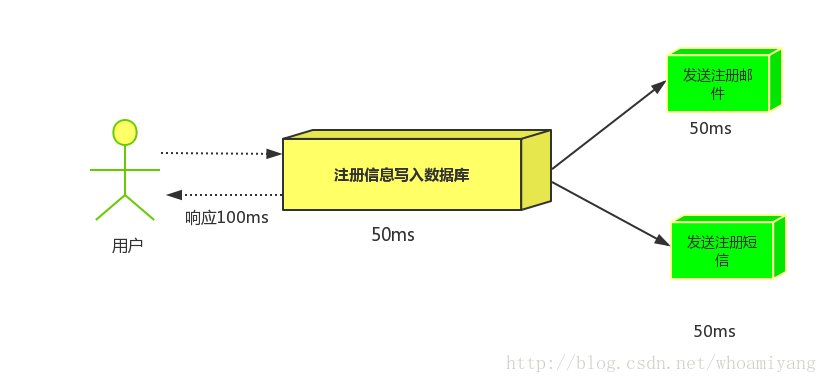
例子:注册->发邮件、发短信
X(Exchanges):交换机一方面:接收生产者发送的消息。另一方面:知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。
Exchange类型有以下几种:
Fanout:广播,将消息交给所有绑定到交换机的队列
Direct:定向,把消息交给符合指定routing key 的队列
Topic:通配符,把消息交给符合routing pattern(路由模式) 的队列
Header:header模式与routing不同的地方在于,header模式取消routingkey,使用header中的 key/value(键值对)匹配队列。
Header模式不展开了,感兴趣可以参考这篇文章https://blog.csdn.net/zhu_tianwei/article/details/40923131
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!
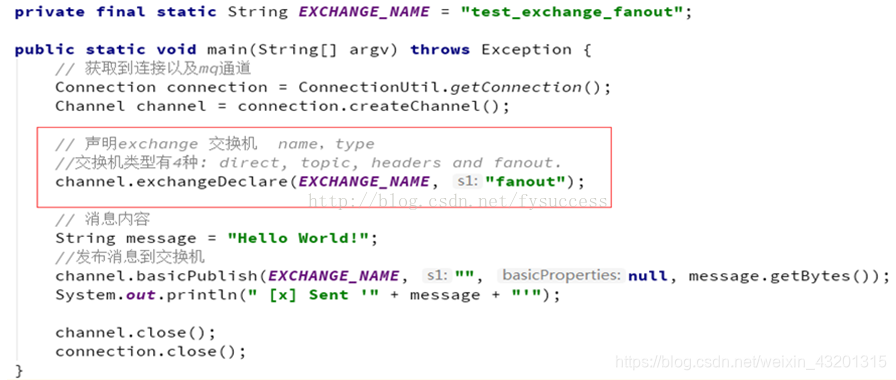
③Publish/subscribe(交换机类型:Fanout,也称为广播 )
Publish/subscribe模型示意图 :

生产者
和前面两种模式不同:
- 1) 声明Exchange,不再声明Queue
- 2) 发送消息到Exchange,不再发送到Queue
private final static String EXCHANGE_NAME = "test_fanout_exchange";
public static void main(String[] argv) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, "fanout");
String message = "注册成功!!";
channel.basicPublish(EXCHANGE_NAME, "", null, message.getBytes());
System.out.println(" [生产者] Sent '" + message + "'");
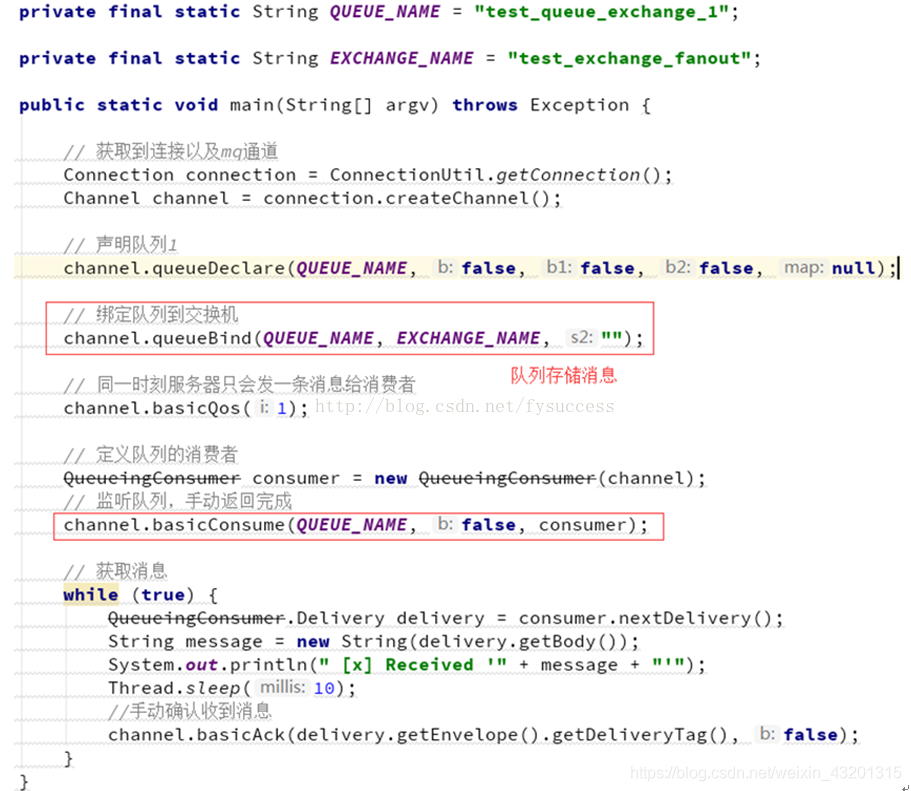
消费者1 (注册成功发给短信服务)
private final static String QUEUE_NAME = "fanout_exchange_queue_sms";
private final static String EXCHANGE_NAME = "test_fanout_exchange";
public static void main(String[] argv) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "");
DefaultConsumer consumer = new DefaultConsumer(channel) {
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,
byte[] body) throws IOException {
String msg = new String(body);
System.out.println(" [短信服务] received : " + msg + "!");
channel.basicConsume(QUEUE_NAME, true, consumer);
消费者2(注册成功发给邮件服务)
private final static String QUEUE_NAME = "fanout_exchange_queue_email";
private final static String EXCHANGE_NAME = "test_fanout_exchange";
public static void main(String[] argv) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "");
DefaultConsumer consumer = new DefaultConsumer(channel) {
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,
byte[] body) throws IOException {
String msg = new String(body);
System.out.println(" [邮件服务] received : " + msg + "!");
channel.basicConsume(QUEUE_NAME, true, consumer);
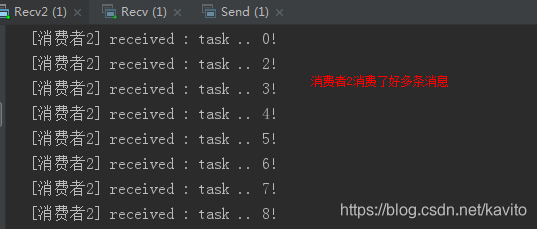
我们运行两个消费者,然后发送1条消息:


思考:
1、publish/subscribe与work queues有什么区别。
区别:
1)work queues不用定义交换机,而publish/subscribe需要定义交换机。
2)publish/subscribe的生产方是面向交换机发送消息,work queues的生产方是面向队列发送消息(底层使用默认交换机)。
3)publish/subscribe需要设置队列和交换机的绑定,work queues不需要设置,实际上work queues会将队列绑定到默认的交换机 。
相同点:
所以两者实现的发布/订阅的效果是一样的,多个消费端监听同一个队列不会重复消费消息。
2、实际工作用 publish/subscribe还是work queues。
建议使用 publish/subscribe,发布订阅模式比工作队列模式更强大(也可以做到同一队列竞争),并且发布订阅模式可以指定自己专用的交换机。
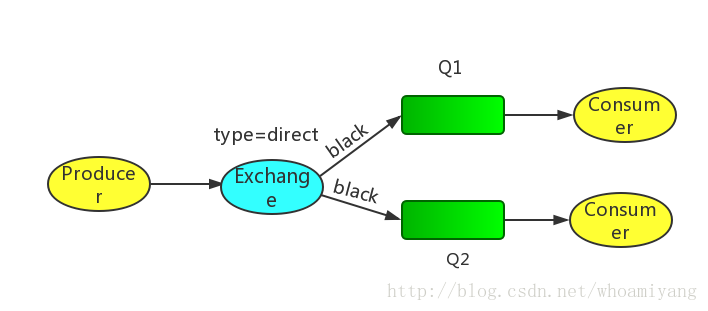
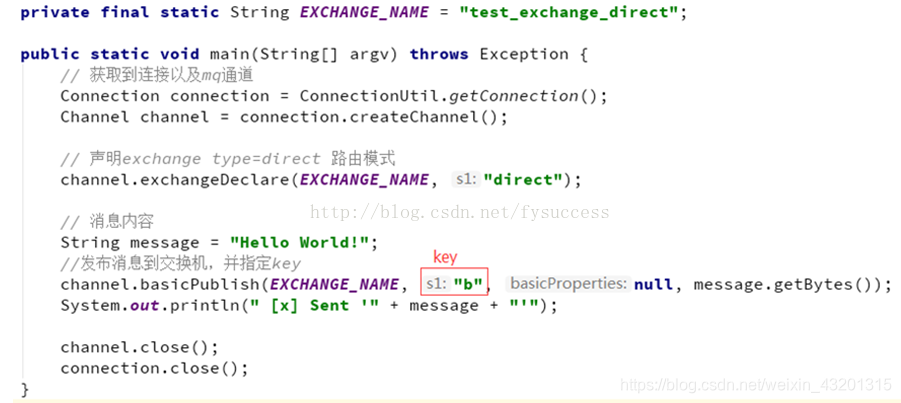
④Routing 路由模型(交换机类型:direct)
Routing模型示意图:

P:生产者,向Exchange发送消息,发送消息时,会指定一个routing key。
X:Exchange(交换机),接收生产者的消息,然后把消息递交给 与routing key完全匹配的队列
C1:消费者,其所在队列指定了需要routing key 为 error 的消息
C2:消费者,其所在队列指定了需要routing key 为 info、error、warning 的消息
接下来看代码:
生产者
private final static String EXCHANGE_NAME = "test_direct_exchange";
public static void main(String[] argv) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT);
String message = "注册成功!请短信回复[T]退订";
channel.basicPublish(EXCHANGE_NAME, "sms", null, message.getBytes());
System.out.println(" [x] Sent '" + message + "'");
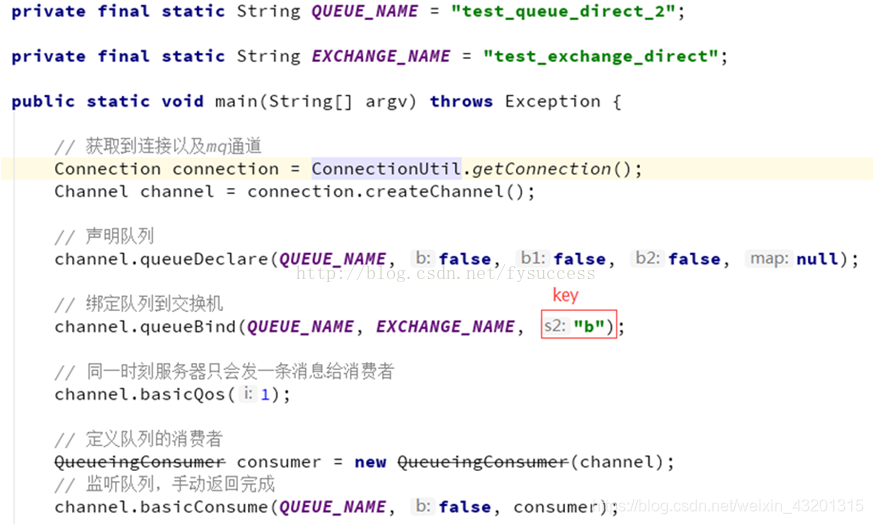
消费者1
private final static String QUEUE_NAME = "direct_exchange_queue_sms";
private final static String EXCHANGE_NAME = "test_direct_exchange";
public static void main(String[] argv) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "sms");
DefaultConsumer consumer = new DefaultConsumer(channel) {
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,
byte[] body) throws IOException {
String msg = new String(body);
System.out.println(" [短信服务] received : " + msg + "!");
channel.basicConsume(QUEUE_NAME, true, consumer);
消费者2
private final static String QUEUE_NAME = "direct_exchange_queue_email";
private final static String EXCHANGE_NAME = "test_direct_exchange";
public static void main(String[] argv) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "email");
DefaultConsumer consumer = new DefaultConsumer(channel) {
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,
byte[] body) throws IOException {
String msg = new String(body);
System.out.println(" [邮件服务] received : " + msg + "!");
channel.basicConsume(QUEUE_NAME, true, consumer);
我们发送sms的RoutingKey,发现结果:只有指定短信的消费者1收到消息了

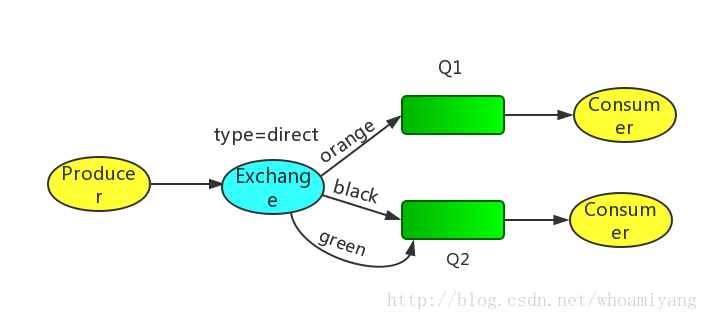
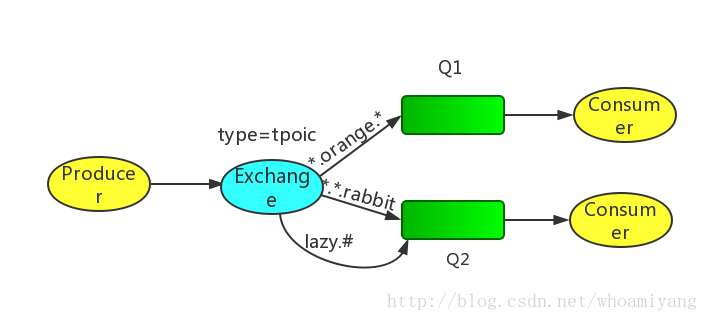
⑤Topics 通配符模式(交换机类型:topics)
Topics模型示意图:

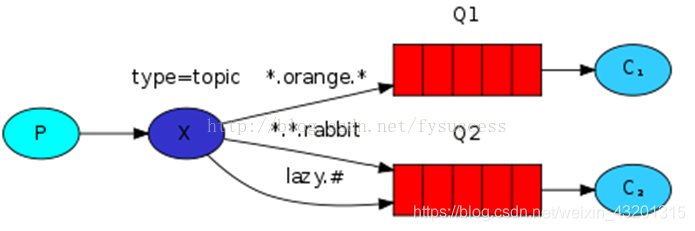
每个消费者监听自己的队列,并且设置带统配符的routingkey,生产者将消息发给broker,由交换机根据routingkey来转发消息到指定的队列。
Routingkey一般都是有一个或者多个单词组成,多个单词之间以“.”分割,例如:inform.sms
通配符规则:
#:匹配一个或多个词
*:匹配不多不少恰好1个词
举例:
audit.#:能够匹配audit.irs.corporate 或者 audit.irs
audit.*:只能匹配audit.irs
从示意图可知,我们将发送所有描述动物的消息。消息将使用由三个字(两个点)组成的Routing key发送。路由关键字中的第一个单词将描述速度,第二个颜色和第三个种类:“<speed>.<color>.<species>”。
我们创建了三个绑定:Q1绑定了“*.orange.*”,Q2绑定了“.*.*.rabbit”和“lazy.#”。
Q1匹配所有的橙色动物。
Q2匹配关于兔子以及懒惰动物的消息。
下面做个小练习,假如生产者发送如下消息,会进入哪个队列:
quick.orange.rabbit Q1 Q2 routingKey="quick.orange.rabbit"的消息会同时路由到Q1与Q2
lazy.orange.elephant Q1 Q2
quick.orange.fox Q1
lazy.pink.rabbit Q2 (值得注意的是,虽然这个routingKey与Q2的两个bindingKey都匹配,但是只会投递Q2一次)
quick.brown.fox 不匹配任意队列,被丢弃
quick.orange.male.rabbit 不匹配任意队列,被丢弃
orange 不匹配任意队列,被丢弃
下面我们以指定Routing key="quick.orange.rabbit"为例,验证上面的答案
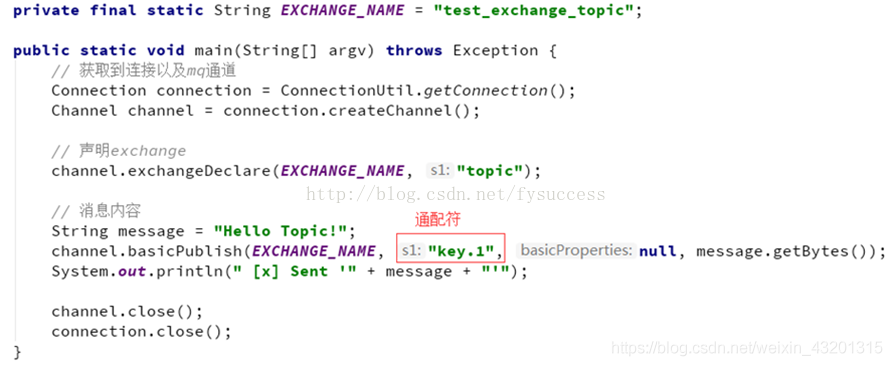
生产者
private final static String EXCHANGE_NAME = "test_topic_exchange";
public static void main(String[] argv) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.TOPIC);
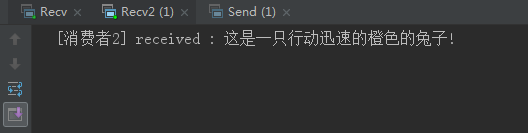
String message = "这是一只行动迅速的橙色的兔子";
channel.basicPublish(EXCHANGE_NAME, "quick.orange.rabbit", null, message.getBytes());
System.out.println(" [动物描述:] Sent '" + message + "'");
消费者1
private final static String QUEUE_NAME = "topic_exchange_queue_Q1";
private final static String EXCHANGE_NAME = "test_topic_exchange";
public static void main(String[] argv) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "*.orange.*");
DefaultConsumer consumer = new DefaultConsumer(channel) {
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,
byte[] body) throws IOException {
String msg = new String(body);
System.out.println(" [消费者1] received : " + msg + "!");
channel.basicConsume(QUEUE_NAME, true, consumer);
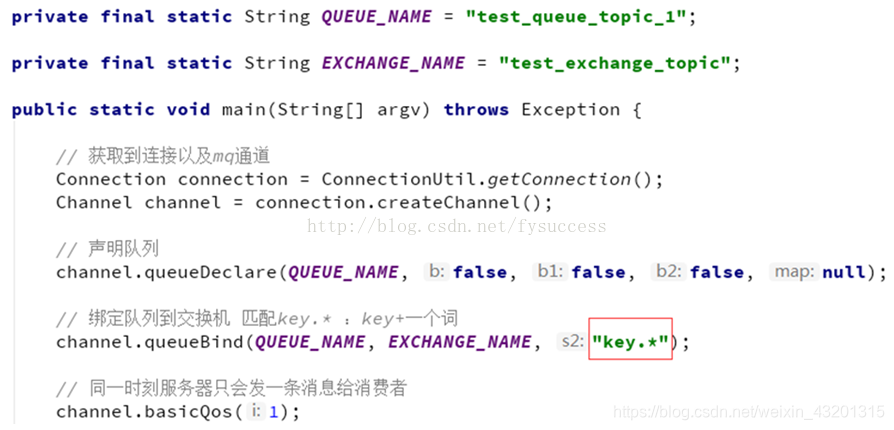
消费者2
private final static String QUEUE_NAME = "topic_exchange_queue_Q2";
private final static String EXCHANGE_NAME = "test_topic_exchange";
public static void main(String[] argv) throws Exception {
Connection connection = ConnectionUtil.getConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "*.*.rabbit");
channel.queueBind(QUEUE_NAME, EXCHANGE_NAME, "lazy.#");
DefaultConsumer consumer = new DefaultConsumer(channel) {
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,
byte[] body) throws IOException {
String msg = new String(body);
System.out.println(" [消费者2] received : " + msg + "!");
channel.basicConsume(QUEUE_NAME, true, consumer);
结果C1、C2是都接收到消息了:

⑥RPC
RPC模型示意图:

基本概念:
Callback queue 回调队列,客户端向服务器发送请求,服务器端处理请求后,将其处理结果保存在一个存储体中。而客户端为了获得处理结果,那么客户在向服务器发送请求时,同时发送一个回调队列地址reply_to。
Correlation id 关联标识,客户端可能会发送多个请求给服务器,当服务器处理完后,客户端无法辨别在回调队列中的响应具体和那个请求时对应的。为了处理这种情况,客户端在发送每个请求时,同时会附带一个独有correlation_id属性,这样客户端在回调队列中根据correlation_id字段的值就可以分辨此响应属于哪个请求。
流程说明:
- 当客户端启动的时候,它创建一个匿名独享的回调队列。
- 在 RPC 请求中,客户端发送带有两个属性的消息:一个是设置回调队列的 reply_to 属性,另一个是设置唯一值的 correlation_id 属性。
- 将请求发送到一个 rpc_queue 队列中。
- 服务器等待请求发送到这个队列中来。当请求出现的时候,它执行他的工作并且将带有执行结果的消息发送给 reply_to 字段指定的队列。
- 客户端等待回调队列里的数据。当有消息出现的时候,它会检查 correlation_id 属性。如果此属性的值与请求匹配,将它返回给应用
分享两道面试题:
面试题:
避免消息堆积?
1) 采用workqueue,多个消费者监听同一队列。
2)接收到消息以后,而是通过线程池,异步消费。
如何避免消息丢失?
1) 消费者的ACK机制。可以防止消费者丢失消息。
但是,如果在消费者消费之前,MQ就宕机了,消息就没了?
2)可以将消息进行持久化。要将消息持久化,前提是:队列、Exchange都持久化
交换机持久化

队列持久化

消息持久化

Spring整合RibbitMQ
下面还是模拟注册服务当用户注册成功后,向短信和邮件服务推送消息的场景
搭建SpringBoot环境
创建两个工程 mq-rabbitmq-producer和mq-rabbitmq-consumer,分别配置1、2、3(第三步本例消费者用注解形式,可以不用配)
1、添加AMQP的启动器:
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
<groupId>org.springframework.boot</groupId>
<artifactId>spring‐boot‐starter‐test</artifactId>
2、在application.yml中添加RabbitMQ的配置:
name: mq-rabbitmq-producer
initial-interval: 10000ms
属性说明:
- template:有关
AmqpTemplate的配置- retry:失败重试
- enabled:开启失败重试
- initial-interval:第一次重试的间隔时长
- max-interval:最长重试间隔,超过这个间隔将不再重试
- multiplier:下次重试间隔的倍数,此处是2即下次重试间隔是上次的2倍
- exchange:缺省的交换机名称,此处配置后,发送消息如果不指定交换机就会使用这个
- publisher-confirms:生产者确认机制,确保消息会正确发送,如果发送失败会有错误回执,从而触发重试
当然如果consumer只是接收消息而不发送,就不用配置template相关内容。
3、定义RabbitConfig配置类,配置Exchange、Queue、及绑定交换机。
public class RabbitmqConfig {
public static final String QUEUE_EMAIL = "queue_email";
public static final String QUEUE_SMS = "queue_sms";
public static final String EXCHANGE_NAME="topic.exchange";
public static final String ROUTINGKEY_EMAIL="topic.#.email.#";
public static final String ROUTINGKEY_SMS="topic.#.sms.#";
public Exchange exchange(){
return ExchangeBuilder.topicExchange(EXCHANGE_NAME).durable(true).build();
public Queue emailQueue(){
return new Queue(QUEUE_EMAIL);
return new Queue(QUEUE_SMS);
public Binding bindingEmail(@Qualifier(QUEUE_EMAIL) Queue queue,
@Qualifier(EXCHANGE_NAME) Exchange exchange){
return BindingBuilder.bind(queue).to(exchange).with(ROUTINGKEY_EMAIL).noargs();
public Binding bindingSMS(@Qualifier(QUEUE_SMS) Queue queue,
@Qualifier(EXCHANGE_NAME) Exchange exchange){
return BindingBuilder.bind(queue).to(exchange).with(ROUTINGKEY_SMS).noargs();
生产者(mq-rabbitmq-producer)
为了方便测试,我直接把生产者代码放工程测试类:发送routing key是"topic.sms.email"的消息,那么mq-rabbitmq-consumer下那些监听的(与交换机(topic.exchange)绑定,并且订阅的routingkey中匹配了"topic.sms.email"规则的) 队列就会收到消息。
@RunWith(SpringRunner.class)
RabbitTemplate rabbitTemplate;
public void sendMsgByTopics(){
String message = "恭喜您,注册成功!userid="+i;
rabbitTemplate.convertAndSend(RabbitmqConfig.EXCHANGE_NAME,"topic.sms.email",message);
System.out.println(" [x] Sent '" + message + "'");
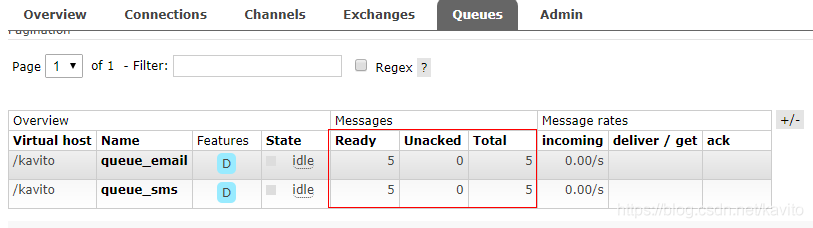
运行测试类发送5条消息:

web管理界面: 可以看到已经创建了交换机以及queue_email、queue_sms 2个队列,并且向这两个队列分别发送了5条消息

消费者(mq-rabbitmq-consumer)
编写一个监听器组件,通过注解配置消费者队列,以及队列与交换机之间绑定关系。(也可以像生产者那样通过配置类配置)
在SpringAmqp中,对消息的消费者进行了封装和抽象。一个JavaBean的方法,只要添加@RabbitListener注解,就可以成为了一个消费者。
public class ReceiveHandler {
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "queue_email", durable = "true"),
value = "topic.exchange",
ignoreDeclarationExceptions = "true",
type = ExchangeTypes.TOPIC
key = {"topic.#.email.#","email.*"}))
public void rece_email(String msg){
System.out.println(" [邮件服务] received : " + msg + "!");
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "queue_sms", durable = "true"),
value = "topic.exchange",
ignoreDeclarationExceptions = "true",
type = ExchangeTypes.TOPIC
key = {"topic.#.sms.#"}))
public void rece_sms(String msg){
System.out.println(" [短信服务] received : " + msg + "!");
属性说明:
@Componet:类上的注解,注册到Spring容器@RabbitListener:方法上的注解,声明这个方法是一个消费者方法,需要指定下面的属性:bindings:指定绑定关系,可以有多个。值是@QueueBinding的数组。@QueueBinding包含下面属性:value:这个消费者关联的队列。值是@Queue,代表一个队列exchange:队列所绑定的交换机,值是@Exchange类型key:队列和交换机绑定的RoutingKey,可指定多个
启动mq-rabbitmq-comsumer项目
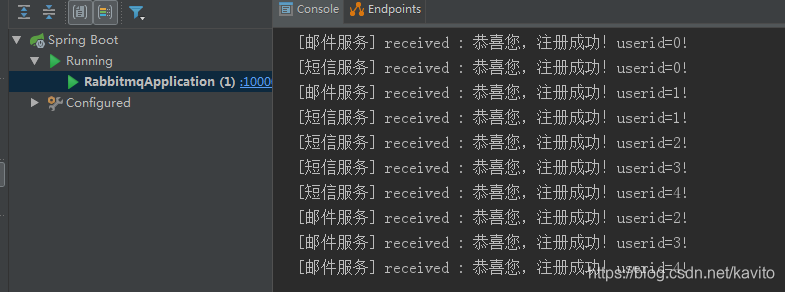
ok,邮件服务和短息服务接收到消息后,就可以各自开展自己的业务了。
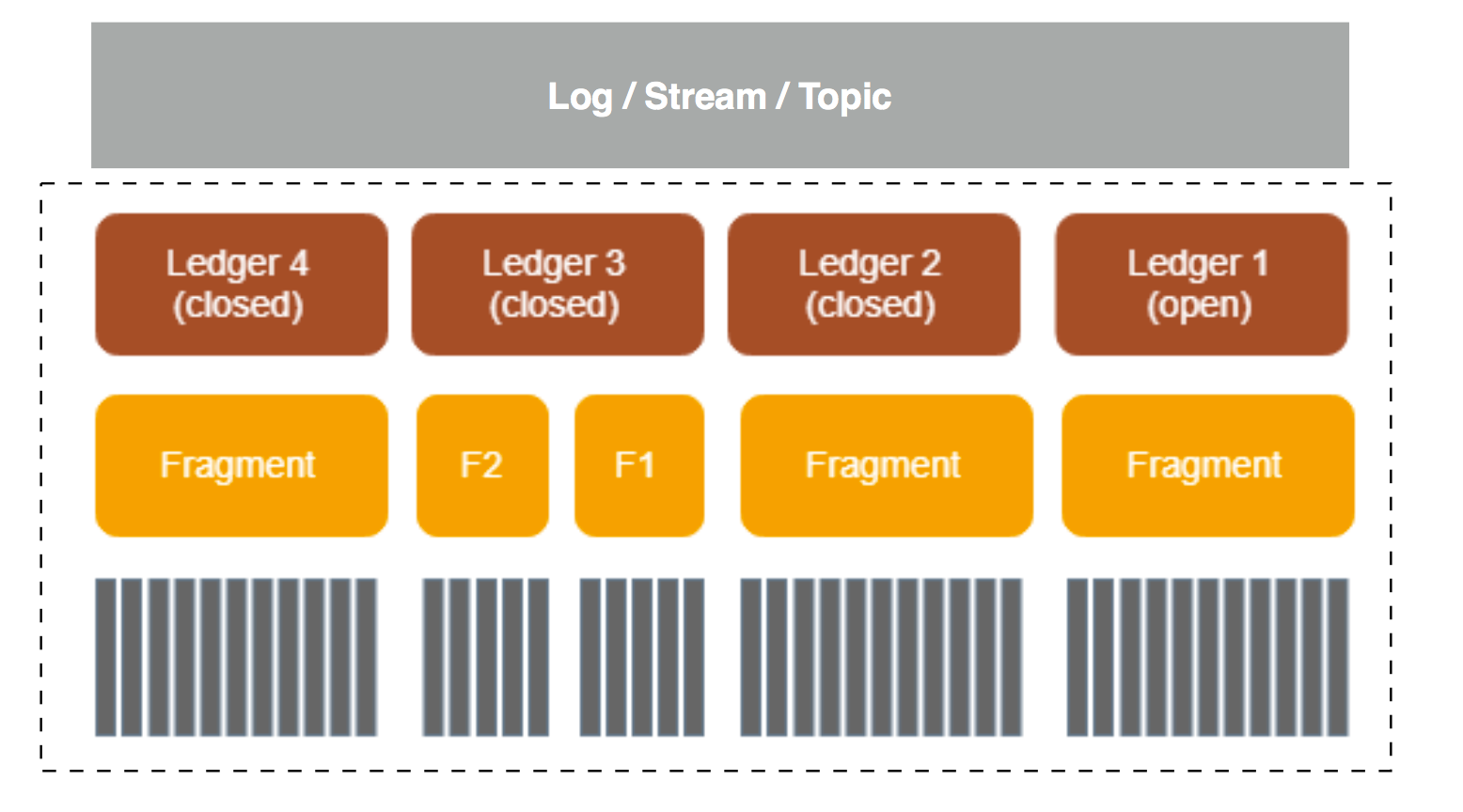 BookKeeper 中的基本概念
BookKeeper 中的基本概念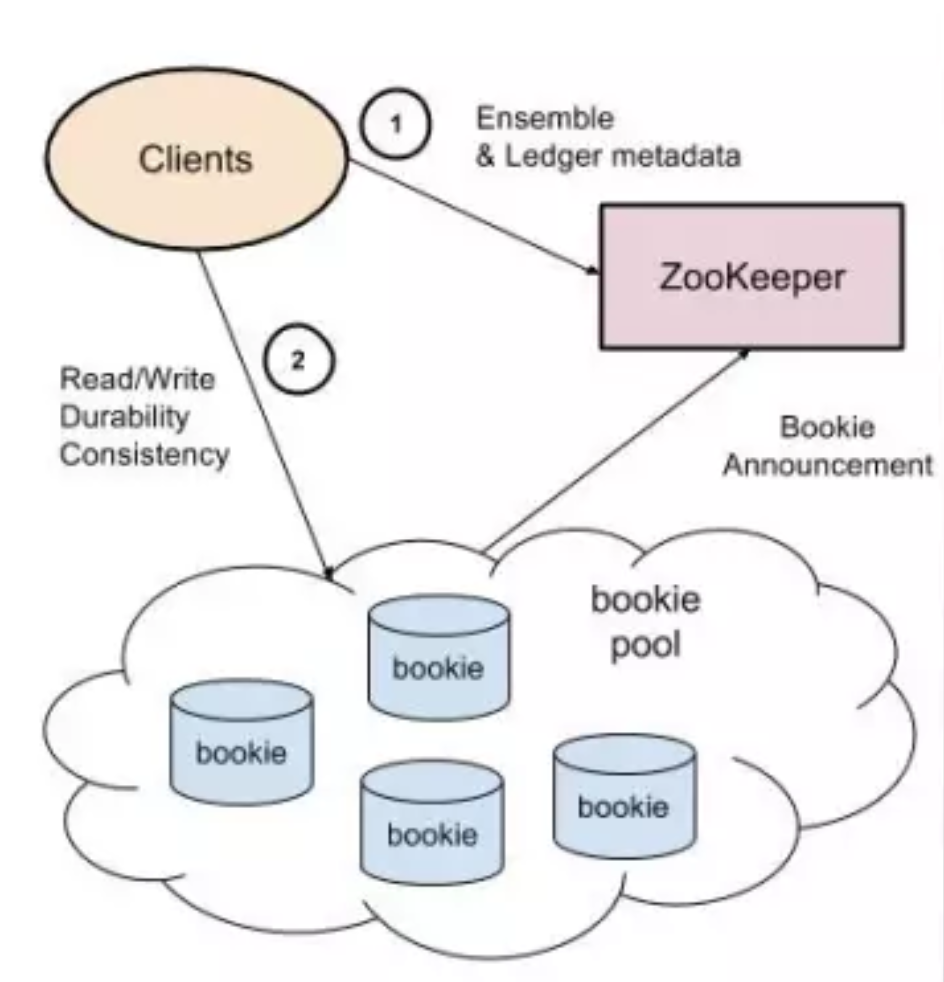 Apache BookKeeper 架构
Apache BookKeeper 架构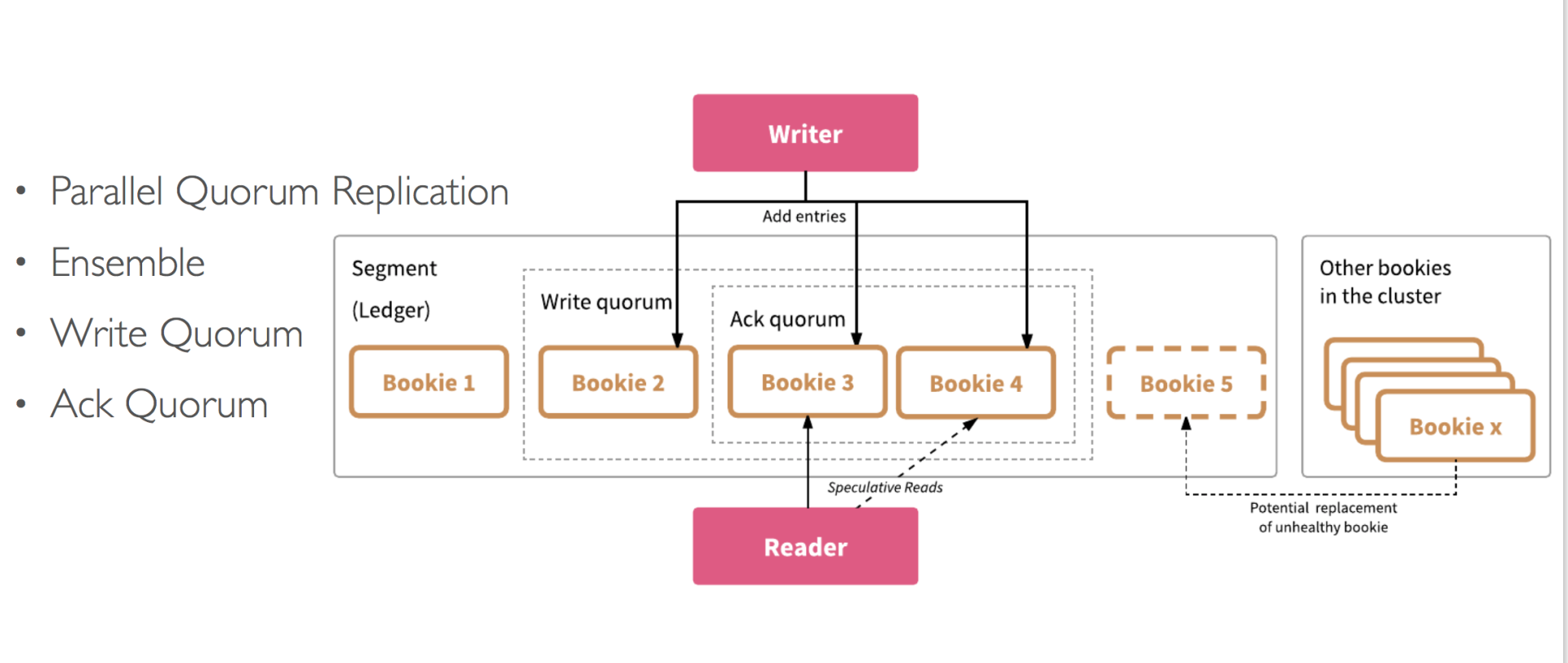 BookKeeper Ledger 的创建
BookKeeper Ledger 的创建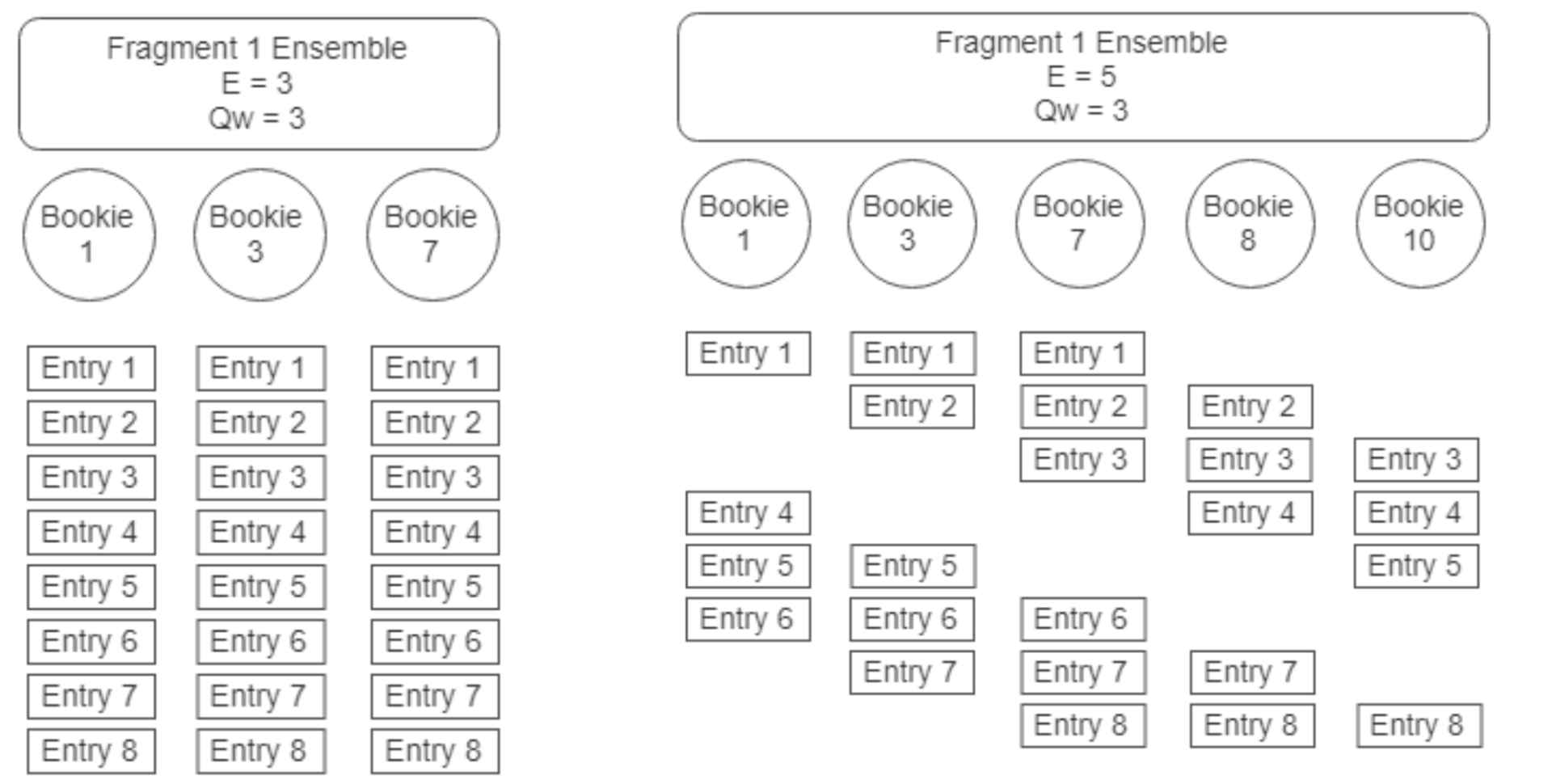 BookKeeper Ledger 多副本复制
BookKeeper Ledger 多副本复制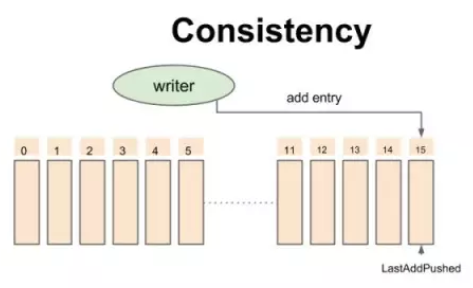 BookKeeper 一致性模型-开始时的状态
BookKeeper 一致性模型-开始时的状态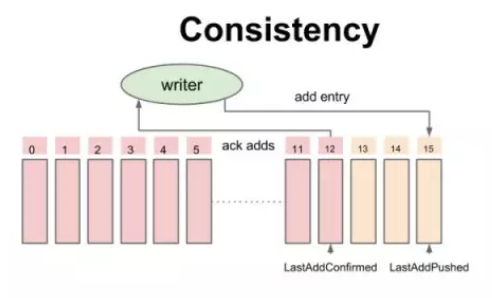 BookKeeper 一致性模型-追加数据时的中间状态
BookKeeper 一致性模型-追加数据时的中间状态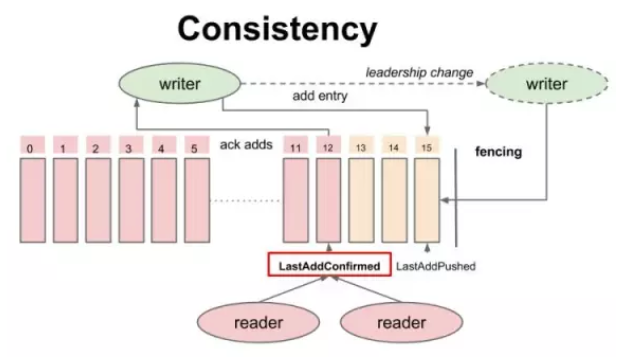 BookKeeper 一致性模型-读的一致性
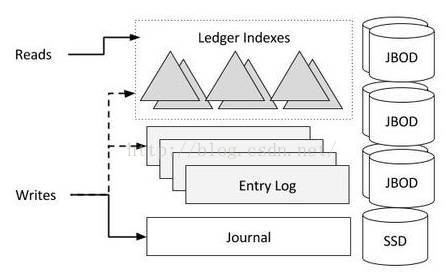
BookKeeper 一致性模型-读的一致性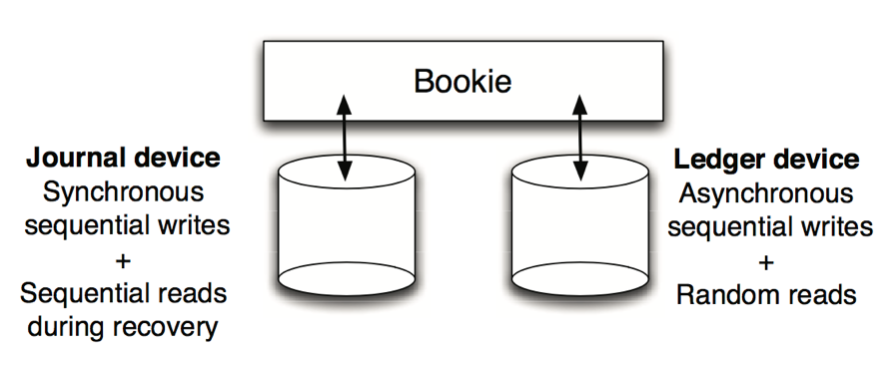 BookKeeper 读写分离
BookKeeper 读写分离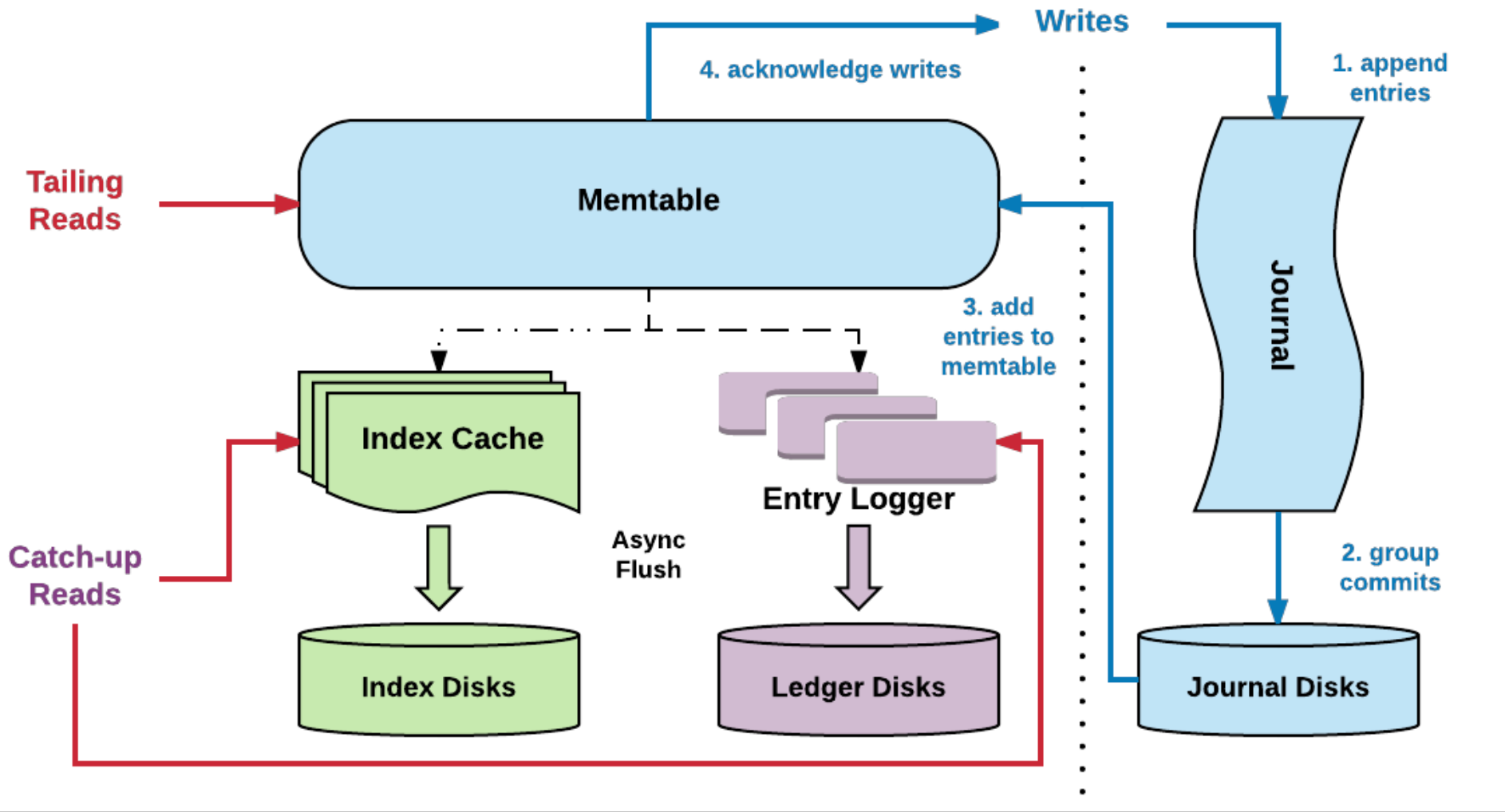 BookKeeper 读写分离
BookKeeper 读写分离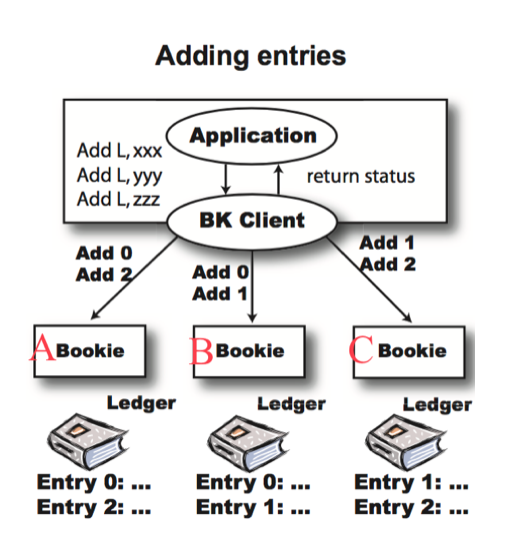 BookKeeper Entry 写入流程
BookKeeper Entry 写入流程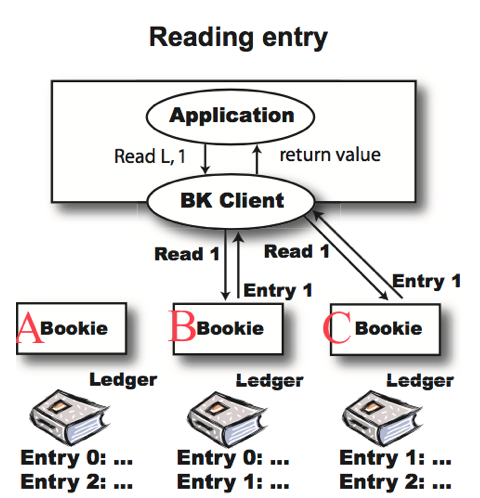 BookKeeper Entry 读取流程
BookKeeper Entry 读取流程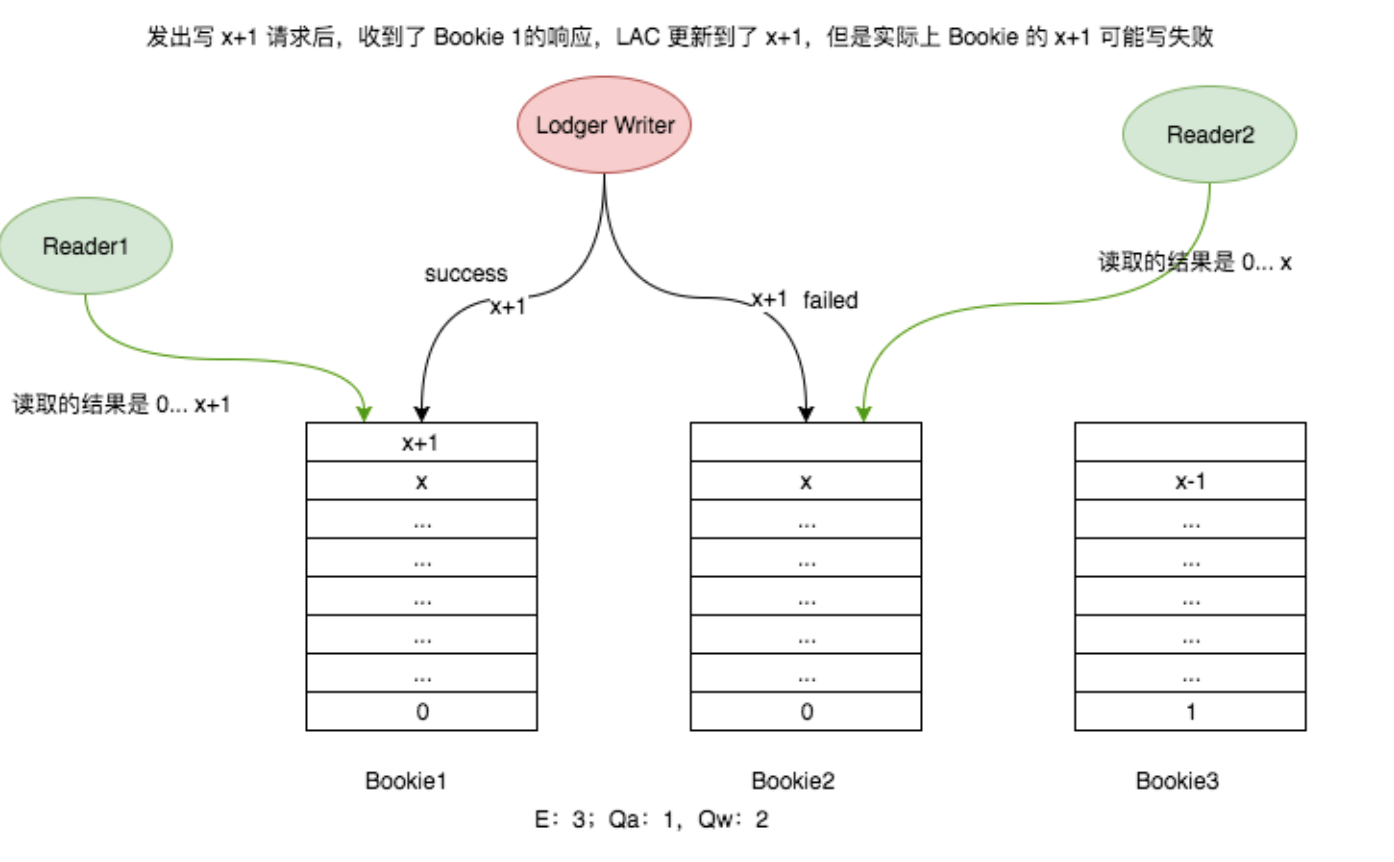 不同 Reader 读取不一致的情况
不同 Reader 读取不一致的情况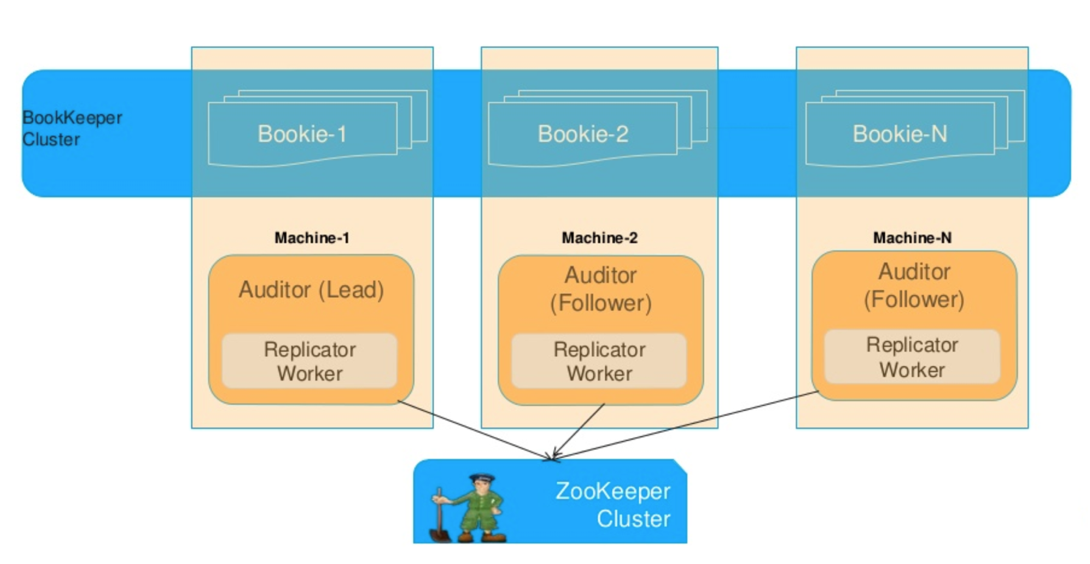 Bookie 容错机制
Bookie 容错机制