来源:http://my.oschina.net/u/1434348/blog/193374
1 概况
YARN是Hadoop系统上的资源统一管理平台,其主要作用是实现集群资源的统一管理和调度。YARN是一个高速发展中的资源管理与调度平台,目前还不是很完善,当前只支持CPU和内存的分配。作为资源调度器,YARN支持如下几个资源调度语义:
- 获取指定节点的特定资源量,如node1上4个虚拟CPU核,1GB内存(YARN上的资源使用容器包装);
- 获取指定机架上的特定资源量;
- 支持资源黑名单(添加/删除);
- 要求某些应用归还指定的资源,通常用于抢占场景。
YARN目前不支持的调度语义有(或者说支持得不是很好):
- 获取任意节点上的特定资源量;
- 获取任意机架上的特定资源量;
- 获取一组或几组符合特定规则的资源量;
- 细粒度资源分配,如获取主频大于2.4G的CPU等;
- 动态调整资源容器容量(对长应用比较重要)。
YARN上的应用按其运行的生命周期长短,可以分为长应用和短应用,短应用通常是分析作业,作业从提交到完成,所耗的时间是有限的,作业完成后,其占用的资源就会被释放,归还给YARN进行再次分配。长应用通常是一些服务,应用启动后除非意外或人为终止,将一直运行下去。长应用通常长期占用集群上的一些资源,且运行期间对资源的需求也时常变化,因此,动态调整资源对长应用来说比较重要。目前,YARN对长应用的支持还不是很好,从社区讨论来看,受hortonworks的Hoya项目推动,YARN在2.20版本后加强了对长应用的支持。
2 应用开发
2.1 概述
YARN的应用开发主要过程如下:
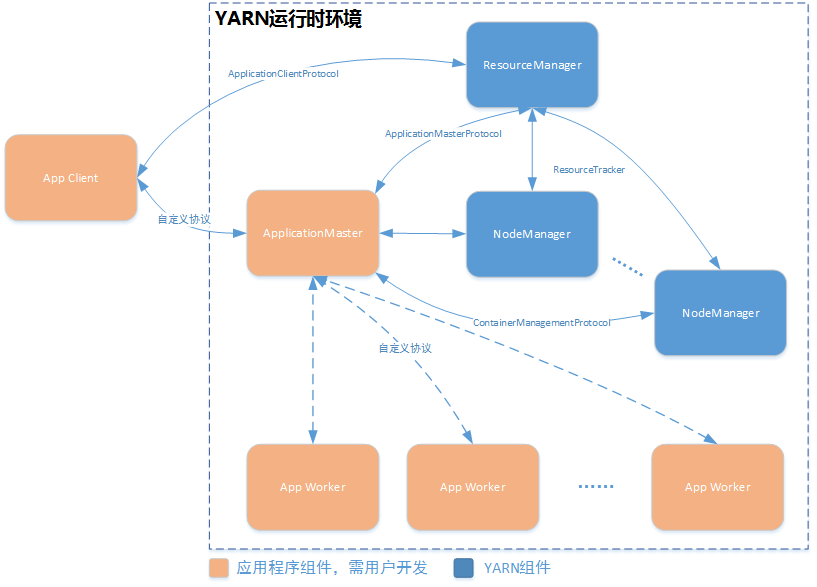
图2.1 YARN应用开发流程
YARN主要由ResourceManager和NodeManager组成,ResourceManager负责资源的管理与分配,NodeManager则负责具体资源的隔离。YARN中,资源使用容器进行封装。用户在YARN上开发应用时,需要实现如下三个模块:
- Application Client: 应用客户端用于将应用提交到YARN上,使应用运行在YARN上,同时,监控应用的运行状态,控制应用的运行;
- Application Master: AM负责整个应用的运行控制,包括向YARN注册应用、申请资源、启动容器等,应用的实际工作在容器中进行;
- Application Worker: 应用的实际工作,并不是所有的应用都需要编写worker。NodeManager启动AM发送过来的容器,容器内部封装了该应用worker运行所需的资源和启动命令。
实现上述模块,涉及如下2个RPC协议:
- ApplicationClientProtocol: Client-RM之间的协议,主要用于应用的提交;
- ApplicationMasterProtocol: AM-RM之间的协议,AM通过该协议向RM注册并申请资源;
- ContainerManagementProtocol: AM-NM之间的协议,AM通过该协议控制NM启动容器。
上述协议的定义在hadoop-yarn-api工程中。
从业务的角度看,一个应用需要分两部分进行开发,一个是接入YARN平台,实现上述3个协议,通过YARN实现对集群资源的访问和利用;另一个是业务功能的实现,这个与YARN本身没有太大关系。下面主要阐述如何将一个应用接入YARN平台。
2.2 客户端开发
客户端开发流程如图2.2所示:
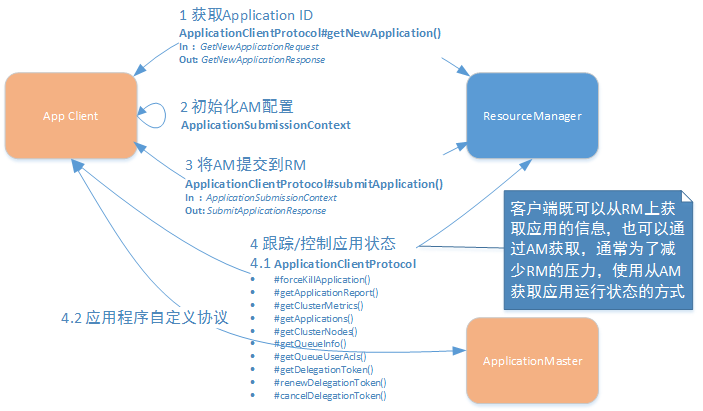
图2.2 YARN应用程序客户端开发
从上图可以看出,客户端的主要作用是提交(部署)应用和监控应用运行两个部分。
2.2.1 提交应用
提交应用涉及ApplicationClientProtocol协议中的两个方法:
GetNewApplicationResponse getNewApplication(GetNewApplicationRequest request)
SubmitApplicationResponse submitApplication(SubmitApplicationRequest request)
具体步骤如下:
- 客户端通过getNewApplication方法从RM上获取应用ID;
- 客户端将应用相关的运行配置封装到ApplicationSubmissionContext中,通过submitApplication方法将应用提交到RM上;
- RM根据ApplicationSubmissionContext上封装的内容启动AM;
- 客户端通过AM或RM获取应用的运行状态,并控制应用的运行过程。
通过getNewApplication可从RM上获取全局唯一的应用ID和最大可申请的资源量(内存和虚拟CPU核数),如下所示:

图2.3 getNewApplication方法的输入输出
在获取应用程序ID后,客户端封装应用相关的配置到ApplicationSubmissionContext中,通过submitApplication方法提交到RM上。
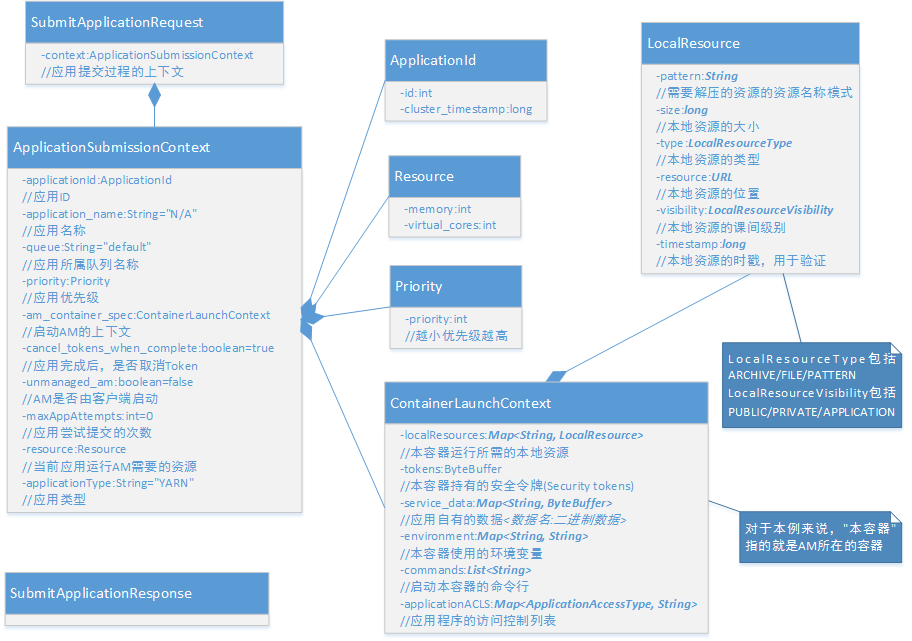
图2.4 submitApplication方法的输入输出
ApplicationSubmissionContext主要包括如下几个部分:
- applicationId: 通过getNewApplication获取的应用ID;
- applicationName: 应用名称,将显示在YARN的web界面上;
- applicationType: 应用类型,默认为”YARN”;
- priority: 应用优先级,数值越小,优先级越高;
- queue: 应用所属队列,不同应用可以属于不同的队列,使用不同的调度算法;
- unmanagedAM: 布尔类型,表示AM是否由客户端启动(AM既可以运行在YARN平台之上,也可以运行在YARN平台之外。运行在YARN平台之上的AM通过RM启动,其运行所需的资源受YARN控制);
- cancelTokensWhenComplete: 应用完成后,是否取消安全令牌;
- maxAppAttempts: AM启动失败后,最大的尝试重启次数;
- resource: 启动AM所需的资源(虚拟CPU数/内存),虚拟CPU核数是一个归一化的值;
- amContainerSpec: 启动AM容器的上下文,主要包括如下内容:
- tokens: AM所持有的安全令牌;
- serviceData: 应用私有的数据,是一个Map,键为数据名,值为数据的二进制块;
- environment: AM使用的环境变量;
- commands: 启动AM的命令列表;
- applicationACLs:应程序访问控制列表;
- localResource: AM启动需要的本地资源列表,主要是一些外部文件、压缩包等。
监控应用运行状态
应用监控涉及ApplicationClientProtocol协议中的如下几个方法:
//强制杀死一个应用
KillApplicationResponse forceKillApplication(KillApplicationRequest request)
//获取应用状态,如进度等
GetApplicationReportResponse getApplicationReport(GetApplicationReportRequest request)
//获取集群度量
GetClusterMetricsResponse getClusterMetrics(GetClusterMetricsRequest request)
//获取符合条件的应用的状态(列表)
GetApplicationsResponse getApplications(GetApplicationsRequest request)
//获取集群中各个节点的状态
GetClusterNodesResponse getClusterNodes(GetClusterNodesRequest request)
//获取RM中的队列信息
GetQueueInfoResponse getQueueInfo(GetQueueInfoRequest request)
//获取当前用户的访问控制信息
GetQueueUserAclsInfoResponse getQueueUserAcls(GetQueueUserAclsInfoRequest request)
//获取委托令牌,使得容器可以使用这些令牌与服务通信
GetDelegationTokenResponse getDelegationToken(GetDelegationTokenRequest request)
//更新已存在的委托令牌
RenewDelegationTokenResponse renewDelegationToken(RenewDelegationTokenRequest request)
//需要已存在的委托令牌
CancelDelegationTokenResponse cancelDelegationToken(CancelDelegationTokenRequest request)
客户端既可以从RM上获取应用的信息,也可以通过AM获取。通常为了减少RM的压力,使用从AM获取应用运行状态的方式。客户端与AM之间的通信使用应用内部的私有协议,与YARN无关。
2.3 AM开发
AM的主要功能是按照业务需求,从RM处申请资源,并利用这些资源完成业务逻辑。因此,AM既需要与RM通信,又需要与NM通信。这里涉及两个协议,分别是AM-RM协议(ApplicationMasterProtocol)和AM-NM协议(ContainerManagementProtocol),如图2.5所示:

图2.5 AM-YARN接口协议
2.3.1 AM-RM协议
AM-RM之间使用ApplicationMasterProtocol协议进行通信,该协议提供如下几个方法:
//向RM注册AM
RegisterApplicationMasterResponse registerApplicationMaster(RegisterApplicationMasterRequest request)
//告知RM,应用已经结束
FinishApplicationMasterResponse finishApplicationMaster(FinishApplicationMasterRequest request)
//向RM申请/归还资源,维持心跳
AllocateResponse allocate(AllocateRequest request)
客户端向RM提交应用后,RM会根据提交的信息,分配一定的资源来启动AM,AM启动后调用ApplicationMasterProtocol协议的registerApplicationMaster方法主动向RM注册。完成注册后,AM通过ApplicationMasterProtocol协议的allocate方法向RM申请运行任务的资源,获取资源后,通过ContainerManagementProtocol在NM上启动资源容器,完成任务。应用完成后,AM通过ApplicationMasterProtocol协议的finishApplicationMaster方法向RM汇报应用的最终状态,并注销AM。主要过程如图2.6所示:
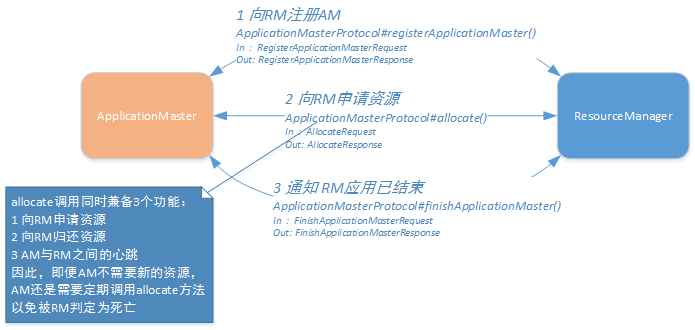
图2.6 AM-RM交互流程
需要注意的是,ApplicationMasterProtocol#allocate()方法还兼顾维持AM-RM心跳的作用,因此,即便应用运行过程中有一段时间无需申请任何资源,AM都需要周期性的调用相应该方法,以避免触发RM的容错机制。下面具体看一下每一步所传递的信息:
1 AM向RM注册
AM启动后会主动调用registerApplicationMaster方法向RM注册,注册信息中包括该AM所在节点和开放的RPC服务端口,以及一个应用状态跟踪Web接口(将在RM的Web页面上显示)。RM向AM返回一个对象,里面包含了应用最大可申请的单个容器容量、应用访控制列表和一个用于与客户端通信的安全令牌。

图2.7 registerApplicationMaster方法输入输出
2 AM向RM申请资源
AM通过allocate方法向RM申请或释放资源。AM向RM发送的信息被封装在AllocateRequest里,包括如下内容:
- responseId: 相应ID,用于区分重复的响应;
- askList:AM向RM申请的资源列表,是一个List<ResourceRequest>对象,其中ResourceRequest中一个资源请求的详细参数,包括优先级、容器个数、单个容器容量和分配策略(是否放宽本地化约束);
- releaseList: AM主动释放的资源容器列表;
- resourceBlacklistRequest: 要添加或删除的资源黑名单;
- progress:应用的运行进度。

图2.8 AllocateRequest
RM接受到AM的请求后,扫描其上的资源镜像,按照调度算法分配全部或部分申请的资源给AM,返回一个AllocateResponse对象,里面内容包括:
- responseId: 相应ID,用于区分重复的响应;
- numClusterNodes: 集群规模大小;
- updatedNodes: 状态被更新过的所有节点列表,每个节点的状态更新信息被分装在NodeReport对象中,包括以下内容:
- nodeId: 节点唯一标识;
- httpAddress: 节点的Web页面地址;
- rackName: 节点所在机架名;
- numContainers: 节点上当前运行的容器个数;
- nodeState: 节点运行状态,是一个枚举类型;
- used: 节点上已经使用的资源量;
- capability: 节点总的资源量;
- healthReport: 节点的健康诊断信息;
- lastHealthReportTime: 最新的节点的健康诊断时戳;
- availableResources: 集群的资源净空量;
- AMCommand: RM给AM发送的控制命令,包括重连和关闭;
- NMTokens: AM与NM之间的通信令牌;
- allocatedContainers: RM新分配给AM的资源容器列表,这些资源被封装在资源容器(Container)中:
- id: 容器ID,每个容器都具有全局唯一的ID;
- priority: 优先级;
- nodeId: 容器所在节点的ID;
- nodeHttpAddress: 节点的Web页面地址;
- containerToken: 容器的安全令牌;
- resource: 该容器所持有的资源,包括内存和CPU。
- completedContainersStatuses: 已完成的容器状态列表;
- preemptionMessage: 资源抢占信息,包括两部分,强制收回部分和可自主调配部分:
- strictContract: 强制收回部分,AM必须释放的容器列表;
- preemptionContract: 可自主调配的部分,该部分包含了两个内容,分别是抢占资源需求和可抢占的资源列表,AM需要从可抢占的资源列表中选出部分资源进行释放,以满足抢占资源需求;
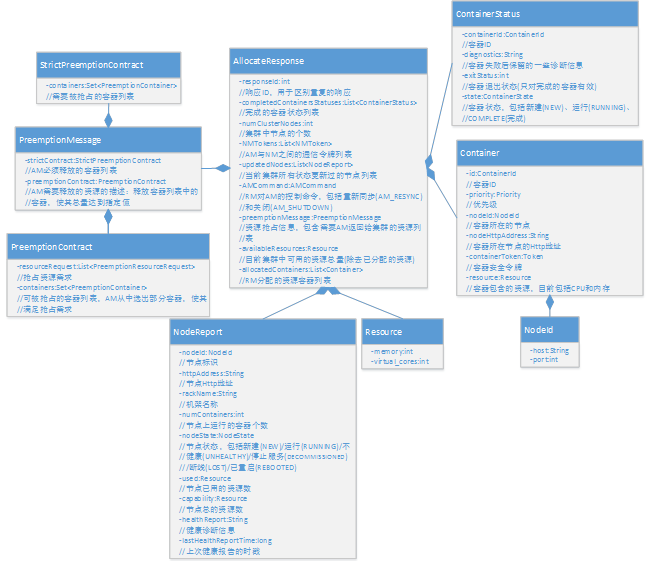
图2.9 AllocateResponse
3 AM通知RM应用已结束
在应用完成后,AM通知RM应用结束的消息,同时向RM提供应用的最终状态(成功/失败等)、一些失败时的诊断信息和应用跟踪地址,RM收到通知后注销相应的AM,并将注销结果发送给AM,AM收到注销成功的消息后,退出进程。AM通过调用ApplicationMasterProtocol#finishApplicationMaster方法通知RM,该方法的输入输出如下所示:
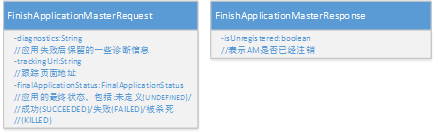
图2.10 finishApplicationMaster方法的I/O
2.3.2 AM-NM协议
AM通过ContainerManagementProtocol协议与NM交互,包括3个方面的功能:启动容器、查询容器状态、停止容器,分别对应协议中的三个方法:
//启动容器
StartContainersResponse startContainers(StartContainersRequest request)
//查询容器状态
GetContainerStatusesResponse getContainerStatuses(GetContainerStatusesRequest request)
//停止容器
StopContainersResponse stopContainers(StopContainersRequest request)、
AM-NM交互过程如图2.11所示:

图2.11 AM-NM交互流程
1 AM在NM上启动容器
AM通过ContainerManagementProtocol# startContainers()方法启动一个NM上的容器,AM通过该接口向NM提供启动容器的必要配置,包括分配到的资源、安全令牌、启动容器的环境变量和命令等,这些信息都被封装在StartContainersRequest中。NM收到请求后,会启动相应的容器,并返回启动成功的容器列表和失败的容器列表,同时还返回其上相应的辅助服务元数据。startContainers方法的输入输出如图2.12所示:
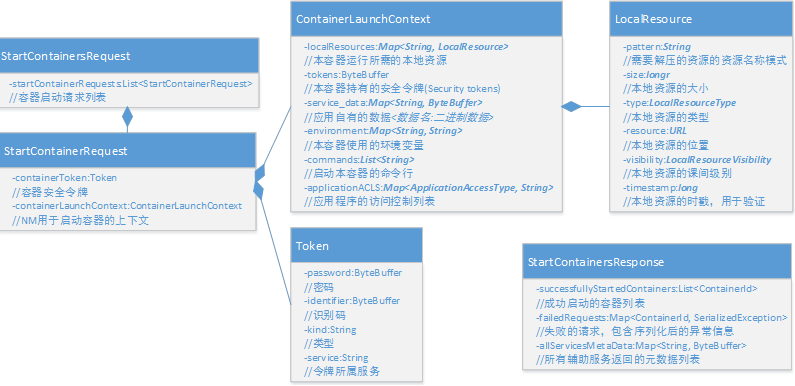
图2.12 startContainers的I/O
2 AM查询NM上的容器运行状态
在应用运行期间,AM需要实时掌握各个Container的运行状态,以便及时响应一些异常,如容器运行失败等。AM通过ContainerManagementProtocol# getContainerStatuses ()方法获取各个容器的运行状态,其输入输出如下图所示:

图2.13 getContainerStatuses I/O
3 AM停止NM上的容器
当一个容器运行完成后,分配给它的资源需要被回收。AM通过ContainerManagementProtocol# stopContainers()方法停止NM上的容器,释放相关资源,然后通过AM-RM协议,将释放的资源上报给RM,RM完成最终的资源回收。stopContainers的输入输出如下图所示:

图2.14 stopContainers I/O
2.4 使用YARN编程库开发应用
如2.3节所述,YARN上的应用开发分为平台接入和业务开发两个部分,其中平台接入就是实现上述三个RPC协议。直接实现上述协议的开发难度较高,需要处理很多细节和性能问题,如系统并发等。为此,YARN提供了一套应用程序编程库来简化应用的开发过程,该编程库是基于事件驱动机制的,利用了YARN内部的服务库、事件库和状态机库,分为三个部分,与上述三个协议一一对应。
2.4.1 YARN基础库
1 服务库
YARN中普遍采用基于服务的对象管理模型,将一些生命周期较长的对应服务化,YARN提供一套抽象的接口对服务进行了统一描述,该服务具有如下特点:
- 具有标准状态,所有服务都具有4个状态,NOTINITED、INITED、STARTED、STOPPED;
- 状态驱动,服务状态变化将触发一些动作,使其转变成另一种状态;
- 服务嵌套,一个服务可以由其他服务组合嵌套而来。
YARN服务库如下所示:
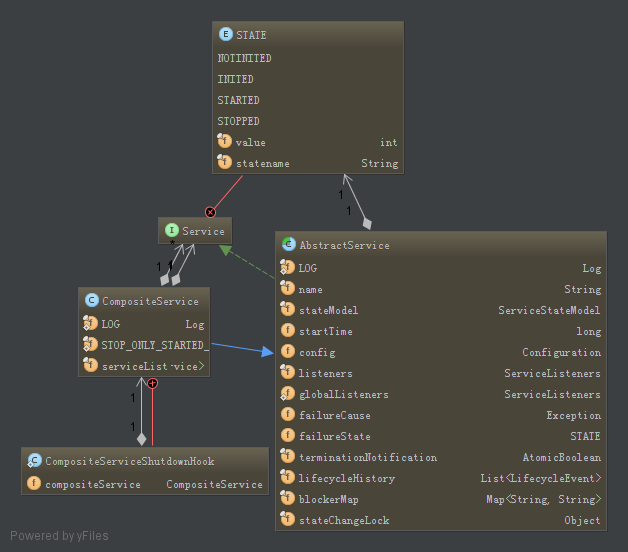
图2.15 YARN服务库
2 事件库
YARN中大量采用了基于事件驱动的并发模型,该模型由事件、异步调度器和事件处理器三个模块组成。处理请求被抽象为事件,放入异步调度器的事件队列中,调度线程从事件队列中取出事件分发给不同的事件处理器,事件处理器处理事件,产生新的事件放入事件队列,如此循环,直到处理完成(完成事件)。
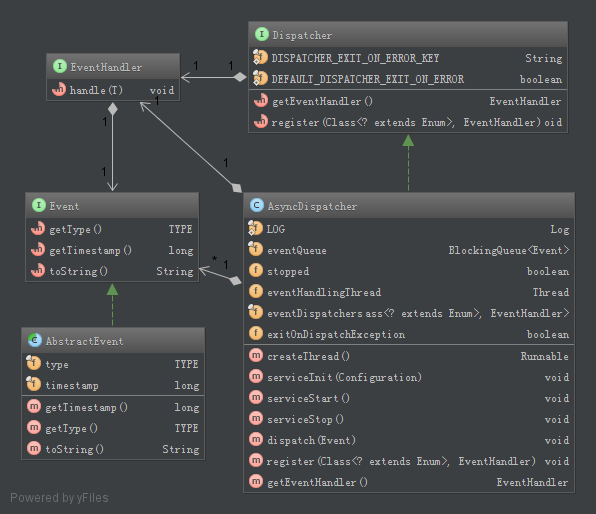
图2.16 YARN事件库
3 状态机库
YARN中使用{转换前状态、转换后状态、事件、回调函数}四元组来表示一个状态变换,一个或多个事件的到来,触发绑定在对象上状态转移函数,使对象的状态发生变化。状态机使得事件处理变得简单可控。
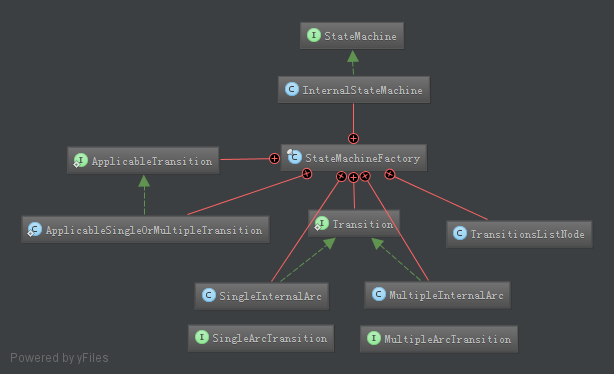
图2.17 状态机库
总的来说,YARN中的服务由一个或多个含有有限状态机的事件处理系统组成,总体框架如下图所示。
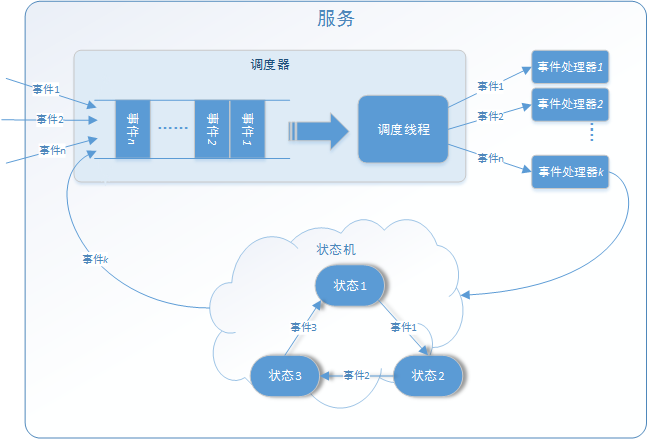
图2.18 YARN服务通用模型
2.4.2 YARN应用客户端库(CLIENT-RM编程库)
YARN的Client-RM编程库位于org.apache.hadoop.yarn.client.YarnClient(Hadoop-yarn-api项目),该库实现了通用的ApplicationClientProtocol协议,提供了重试机制。用户利用该库可以快速开发YARN应用的客户端程序,而不需要关心RPC等底层接口。如图所示:
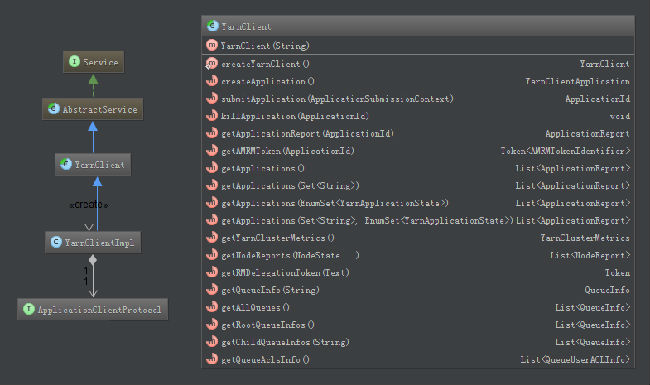
图2.19 YarnClient
用户开发自己的应用客户端时,只要设置好ApplicationSubmissionContext对象,调用YarnClient的相关接口,即可实现应用的提交。
2.4.3 AM-RM编程库
AM-RM编程库主要简化了AM向RM申请资源过程的开发。YARN提供了两套AM-RM编程库,分别为阻塞式和非阻塞式模式。如图2.20所示。
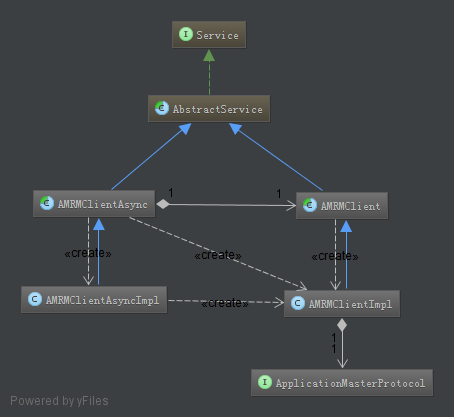
图2.20 AM-RM编程库
其中,AMRMClient是阻塞式的,实现了ApplicationMasterProtocol协议,用户调用该类的相应接口,可实现AM与RM的通信。而AMRMClientAsync是AMRMClient的非阻塞式封装,所有响应通过回调函数的形式返回给用户,用户实现自己的AM时,只需要实现AMRMClientAsync的CallbackHandler即可。如图2.21所示:
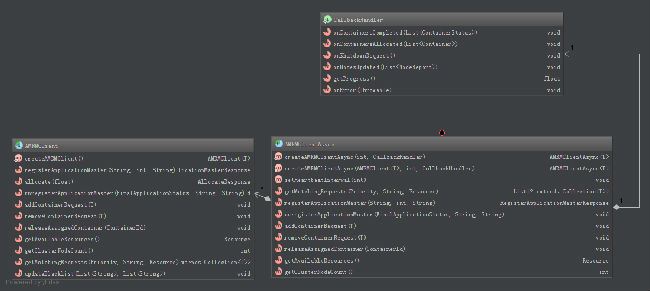
图2.21 AM-RM编程库
2.4.4 NM编程库
NM编程库对AM和RM与NM之间的交互进行了封装,同样有阻塞式和非阻塞式两种封装(AM与NM和RM与NM的交互逻辑相似),如图2.22所示。

图2.22 NM编程库
同样的,对于异步编程库NMClientAsync,用户只需要在自己的AM上实现相应的回调函数,就可以控制NM上Container的启动/停止和状态监控了。如图2.23所示。
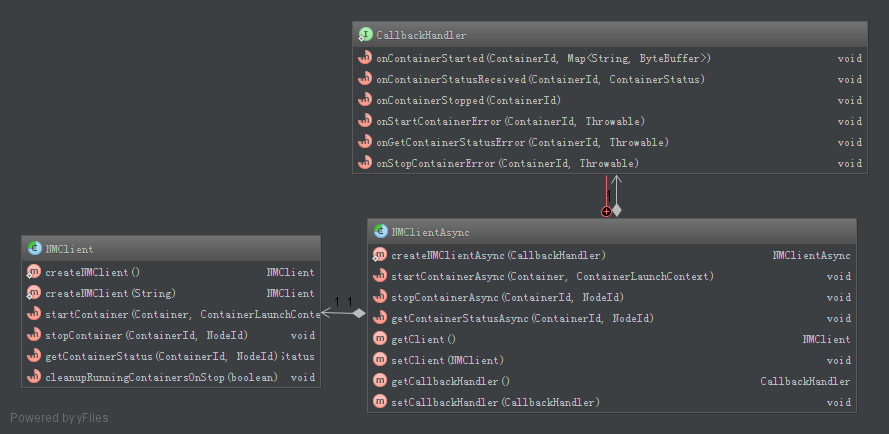
图2.23 NM编程库
2.5 总结
本文介绍了YARN平台应用开发的基本流程,总结如下:
- YARN平台应用开发主要有两个工作:YARN平台接入和业务逻辑实现;
- YARN平台应用开发主要需要开发三个组件:客户端、AM和worker;
- YARN平台接入主要涉及三个协议,分别为ApplicationClientProtocol、ApplicationMasterProtocol和ContainerManagementProtocol,其中,客户端通过ApplicationClientProtocol协议与RM交互,提交(部署)应用并监控应用的运行;AM通过ApplicationMasterProtocol协议维持AM-RM心跳,并向RM申请YARN上的资源;AM通过ContainerManagementProtocol协议控制NM启动、停止申请到的容器,并监控容器的运行状态。容器是YARN对资源的封装,应用的Worker在容器中运行,只能使用容器中的资源,从而实现资源隔离;
- YARN提供了Client-RM编程库、AM-RM编程库和NM编程库,从而简化了YARN上的应用开发(当然还不是很简单),需要注意的是,该编程库的接口还不是很稳定,以后还有可能发生变化(hadoop2.0与hadoop2.2.0中YARN的这些编程库不兼容)。
总得来说,YARN是一个资源管理平台,并不涉及业务逻辑,具体的业务逻辑需要用户自己去实现。YARN的核心作用就是分配资源、保证资源隔离。
