最近研究amq发现了Apache Artemis, 感觉很好, 仔细看了些, 最后发现他来源于HornetQ
信息如下:
HornetQ Apache donation and Apache Artemis 1.0.0 release
The HornetQ code base was donated to the Apache ActiveMQ community late last year and now resides as a sub project under the ActiveMQ umbrella named 'Artemis'. Since the code donation, the developers have been working tirelessly to get an initial release of Artemis out the door; to allow folks to give it a whirl and to finalise the donation process. With the release of Apache Artemis 1.0.0, that process has come to a close and the code donation has now been completed.
The active developer community has migrated across to Artemis; all of the developers that were active on HornetQ are now committers to the Artemis project; working on the code base as part of the ActiveMQ umbrella. The hope is that the union of the two great communities HornetQ and ActiveMQ will provide a path for a next generation of message broker with more advanced features, better performance and greater stability. We feel we can achieve these goals using the Artemis core with it's superior performance in combination with the vast feature offering of ActiveMQ. As Aristotle once put it "The whole is greater than the sum of it's parts". Let's hope this holds true for this union and great things will happen.
The Artemis project is targeted to house this next generation of message broker, as such any new feature requests or contributions from the HornetQ community should now be placed into the Artemis stream of development. HornetQ will of course have bugs fixed on its active branches (2.3 and 2.4) but will be mostly in maintenance only mode. For those HornetQ users who are wishing to migrate to Artemis 1.0.0, your job should be easy, Artemis is already compatible with HornetQ clients and supports a number of other protocols such as AMQP, Stomp, ActiveMQ's native messaging protocol 'OpenWire' (at Alpha with support for ActiveMQ JMS clients and basic transport) and also JMS 2. In addition we have already started development on support for MQTT.
To find out more on the Artemis project and how to subscribe to the Artemis mailing lists and get involved, please visit the Artemis website here: http://activemq.apache.org/artemis.
We look forward to seeing you all very soon
HornetQ 参考手册:
http://wenku.baidu.com/view/2f19b1557fd5360cba1adbd9.html?from=search
HornetQ 是一个支持集群和多种协议,可嵌入、高性能的异步消息系统。HornetQ完全支持JMS,HornetQ不但支持JMS1.1 API同时也定义属于自己的消息API,这可以最大限度的提升HornetQ的性能和灵活性。在不久的将来更多的协议将被HornetQ支持。
异步消息系统
功 能 完全支持JMS,HornetQ
特 点 定义属于自己的消息API
HornetQ拥有超高的性能,HornetQ在持久化消息方面的性能可以轻易的超于其它常见的非持久化消息引擎的性能。当然,HornetQ的非持久化消息的性能会表现的更好!
HornetQ完全使用POJO,纯POJO的设计让HornetQ可以尽可能少的依赖第三方的包。从设计模式来说,HornetQ这样的设计入侵性也最小。HornetQ既可以独立运行,也可以与其它Java应用程序服务器集成使用。
HornetQ拥有完善的错误处理机制,HornetQ提供服务器复制和故障自动转移功能,该功能可以消除消息丢失或多个重复信息导致服务器出错。
HornetQ提供了灵活的集群功能,通过创建HornetQ集群,您可以享受到到消息的负载均衡带来的性能提升。您也可以通过集群,组成一个全球性的消息网络。您也可以灵活的配置消息路由。
HornetQ拥有强大的管理功能。HornetQ提供了大量的管理API和监控服务器。它可以无缝的与应用程序服务器整合,并共同工作在一个HA环境中。
这款JBoss的MQ相当出色。发现国内关于HornetQ的资料很少,国外有一部分,但是版本都很久了。
自己写了一个例子,环境如下:
1、HornetQ的版本是 hornetq-2.2.5.Final
2、JDK1.6.0_30-b12
3、HornetQ自带example里面的config/stand-alone/non-clustered的配置文件
4、HornetQ作为独立的服务器,运行在一台Dell1950(2CPU,16G内存)上
5、自己写了两个小例子,很简单,就是一个Producer和Consumer
6、发送Person类的实例(必须实现Serializable接口)
7、注意:Producer和Consumer用到的Person类,必须在各个项目的相同的package下面,具有相同的serialVersionUID
8、在classpath下面有jndi.properties文件,里面放置着寻找服务器上面JNDI Server必须的配置
9、在classpath下面有个log4j的配置文件,用来答应日志
代码如下:
public class Producer {
private static Logger logger = Logger.getLogger(Producer.class);
/**
* @param args
*/
public static void main(String[] args) {
try {
runExample();
} catch (Exception e) {
e.printStackTrace();
}
}
private static void runExample() throws NamingException, JMSException {
InitialContext ic = new InitialContext();
ConnectionFactory cf = (ConnectionFactory) ic
.lookup("/ConnectionFactory");
Queue orderQueue = (Queue) ic.lookup("/queue/ExpiryQueue");
Connection connection = cf.createConnection();
Session session = connection.createSession(false,
Session.AUTO_ACKNOWLEDGE);
MessageProducer producer = session.createProducer(orderQueue);
connection.start();
int count = 0;
try {
while (true) {
Person one = new Person(count++, "xuepeng_" + count);
ObjectMessage msg = session.createObjectMessage(one);
producer.send(msg);
logger.info(Producer.class.getName()
+ " start to sent message: " + one);
}
} finally {
session.close();
}
}
}
Java代码 收藏代码
public class Person implements Serializable {
private static final long serialVersionUID = 2670718766927459001L;
private Integer id;
private String name;
private SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
private String time = format.format(new Date());
/**
* @param id
* @param name
*/
public Person(Integer id, String name) {
super();
this.id = id;
this.name = name;
}
/**
* @return the id
*/
public Integer getId() {
return id;
}
/**
* @param id
* the id to set
*/
public void setId(Integer id) {
this.id = id;
}
/**
* @return the name
*/
public String getName() {
return name;
}
/**
* @param name
* the name to set
*/
public void setName(String name) {
this.name = name;
}
/* (non-Javadoc)
* @see java.lang.Object#toString()
*/
@Override
public String toString() {
return "Person [id=" + id + ", name=" + name + ", time=" + time + "]";
}
/*
* (non-Javadoc)
*
* @see java.lang.Object#hashCode()
*/
@Override
public int hashCode() {
final int prime = 37;
int result = 17;
result = prime * result + ((id == null) ? 0 : id.hashCode());
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
/*
* (non-Javadoc)
*
* @see java.lang.Object#equals(java.lang.Object)
*/
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (id == null) {
if (other.id != null)
return false;
} else if (!id.equals(other.id))
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
Java代码 收藏代码
public class Consumer {
private static Logger logger = Logger.getLogger(Consumer.class);
/**
* @param args
*/
public static void main(String[] args) {
try {
runExample();
} catch (Exception e) {
e.printStackTrace();
}
}
private static void runExample() throws NamingException, JMSException {
InitialContext ic = new InitialContext();
ConnectionFactory cf = (ConnectionFactory) ic
.lookup("/ConnectionFactory");
Queue orderQueue = (Queue) ic.lookup("/queue/ExpiryQueue");
Connection connection = cf.createConnection();
Session session = connection.createSession(false,
Session.AUTO_ACKNOWLEDGE);
MessageConsumer consumer = session.createConsumer(orderQueue);
connection.start();
try {
while (true) {
ObjectMessage messageReceived = (ObjectMessage) consumer.receive();
org.hornetq.jms.example.Person one = (org.hornetq.jms.example.Person)messageReceived.getObject();
logger.info(Consumer.class.getName()
+ " start to receive message: " + one);
}
} finally {
session.close();
}
}
}
启动Linux上面的HorneQ服务之后,运行上面的Producer和Consumer均可以实现通讯。





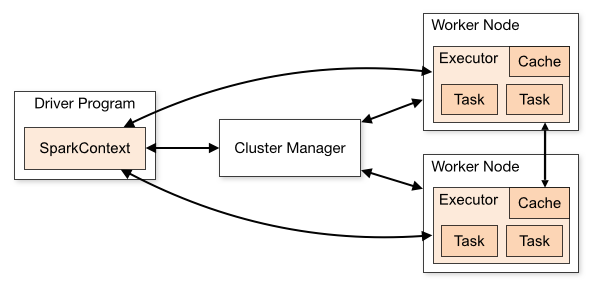 无论是在本地模式、Standalone模式,还是在Mesos或YARN模式下,整个Spark集群的结构都可以用上图抽象表示,只是各个组件的运行环 境不同,导致组件可能是分布式的,或本地的,或单个JVM实例的。如在本地模式,则上图表现为在同一节点上的单个进程之内的多个组件;而在YARN Client模式下,Driver程序是在YARN集群之外的一个节点上提交Spark Application,其他的组件都运行在YARN集群管理的节点上。
无论是在本地模式、Standalone模式,还是在Mesos或YARN模式下,整个Spark集群的结构都可以用上图抽象表示,只是各个组件的运行环 境不同,导致组件可能是分布式的,或本地的,或单个JVM实例的。如在本地模式,则上图表现为在同一节点上的单个进程之内的多个组件;而在YARN Client模式下,Driver程序是在YARN集群之外的一个节点上提交Spark Application,其他的组件都运行在YARN集群管理的节点上。








