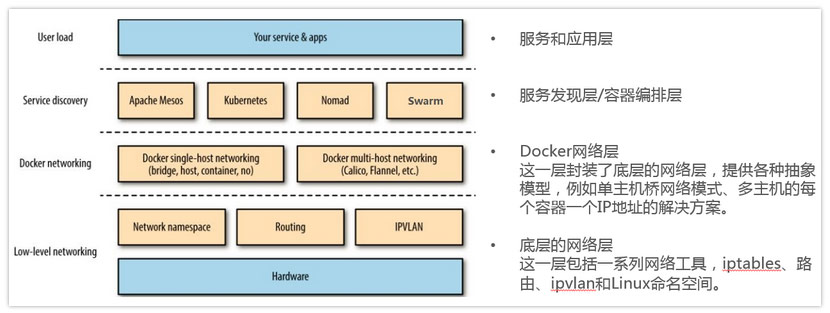
阿里云是国内非常受欢迎的基础云平台,随着Kubernetes的普及,越来越多的企业开始筹划在阿里云上部署自己的Kubernetes集群。 本文将结合实战中总结的经验,分析和归纳一套在阿里云上部署生产级别Kubernetes集群的方法。 文中所采取的技术方案具有一定的主观性,供各位读者参考。在实践中可以根据具体使用场景进行优化。
目标 当我们刚接触Kubernetes进行测试集群的搭建时,往往会选择一篇已有的教程,照着教程完成集群搭建。我们很少去质疑教程作者每一步操作的合理性, 只想快点把集群搭建起来,早点开始实际的上手体验。
与测试集群不同,对于生产级别的部署,我们会有更加严格的要求,更加强调合理的规划以及每个步骤的合理性以及可管理性。以下是我们设定的目标:
没有单点故障。任何一台服务器离线不会影响到整个集群的正常运转 充分利用阿里云原生提供的SLB,云盘等工具,支持Volume挂载,LoadBalancer类型的Service等Kubernetes基础功能。 获得完整的Kubernetes使用体验。 在不牺牲安全性和稳定性的前提下,尽可能降低日常运维所需要的投入,将可以由程序完成的重复性工作自动化 支持随着业务规模扩展的动态集群规模扩展 因为篇幅的原因,以下内容将不作为本文的目标,留待日后再做分享:
集群运行成本控制 监控、日志等运维系统的搭建 安全防护以及权限设计 现状 目前Kubernetes主要支持的云平台还是海外的几大主流平台,但是对比阿里云提供的基础设施,我们已经具有了基本相同的底层环境。 阿里云提供的VPC,云盘,SLB,NAS等组件,都为搭建生成级别Kubernetes集群提供了很好的支持。充分利用这些组件, 我们应该可以搭建出完整可用的Kubernetes集群。但是仔细研究Kubernetes的代码我们会发现,阿里云的CloudProvider暂时没有被合并到上游当中, 所以我们需要设计方案来解决Kubernetes暂时还没有原生阿里云支持的问题。
Kubernetes生态圈发展迅速,目前已经有了像kops这种集群自动创建工具帮助运维工程师创建集群。但是目前已有的集群创建工具均只支持国外的云平台, 使得国内云平台的用户只能采取手动搭建的办法。像kubeadm这种半自动工具还可以使用,也算是减轻了不少负担。从目前状况来看, 运维的负担依然很严重,为我们实现生产级别部署所追求的自动化、规模化的目标带来了不小的障碍。
由于网络原因造成的镜像拉取困难也给我们创建Kubernetes集群制造了不小的麻烦,好在阿里云一直在致力于解决这个问题,为用户提供了镜像拉取加速服务以及重要镜像的Mirror。
另一个问题是操作系统镜像的问题,在后面分析操作系统的时候再详细展开。
架构 基于消除单点故障以及降低复杂度的考虑,我们设计了由5台服务器,分两个服务器组构成的Kubernetes集群的控制节点,并视业务需求情况由N台服务器, 分多个服务器组,构成集群的运行节点。如下图所示:
在设计这一架构时,我们考虑了以下几点:
整个集群的主要构成元素为服务器组。一组服务器具有相同的硬件配置,服务相同的功能,在软件配置上也基本相同。这样为服务器的自动化管理打下了很好的基础。 由3台服务器组成的etcd集群,在其中任何一台服务器离线时,均可以正常工作。为整个Kubernetes集群的数据持久化保存提供了稳定可靠的基础 2台同时运行着Kubernetes核心组件kube-apiserver,kube-controller-manager,kube-scheduler的服务器,为整个集群的控制平面提供了高可用性。 多个运行节点服务器组,有着不同的CPU,内存,磁盘配置。让我们可以灵活的根据业务对运行环境的要求来选择不同的服务器组。 集群搭建 在有了架构蓝图后,接下来让我们来实际搭建这个集群。
操作系统选型 搭建集群首先会面临的问题是,选什么配置的服务器,用什么操作系统。服务器硬件配置相对好解决,控制节点在业务量不大的时候选择入门级别的配置再随着业务增长不断提升即可, 运行节点应当根据业务需要来选择,可能要做一些尝试才能定下来最适合的硬件配置。比较困难的选择是操作系统的选型。
只要是使用较新的Kernel的Linux主机,均可以用来运行Kubernetes集群,但是发行版的选择却需要从多个方面来考虑。在这里我们选择了CoreOS作为最基础的操作系统。 做出这一选择是基于以下这些因素:
CoreOS是专门为运行容器设计的操作系统,非常适合用来运行Kubernetes集群 CoreOS去除了包管理,使用镜像升级的方式,大大简化了运维的复杂度 CoreOS可以使用cloud-init,方便的对服务器进行初始化 阿里云提供了CoreOS的支持 CoreOS的详细介绍,大家可以参考官方的文档,在这里就不展开了。需要指出的是阿里云提供的CoreOS镜像版本较低,需要先进行升级才能正常使用,增加了不少麻烦。 希望以后阿里云能够提供最新版本的CoreOS镜像,改善这一问题。
CoreOS版本升级 由于网络的原因,CoreOS在国内不能正常进行升级。我们需要在国内搭建升级服务器。CoreRoller是一个可选项。具体的搭建可以参考相关文档,在这里就略过了。
在顺利搭建好升级服务器之后,可以修改/etc/coreos/update.conf,添加SERVER=https://YOUR_SERVER/v1/update/这一条配置,然后使用以下指令来升级服务器:
sudo systemctl restart update - engine
update_engine_client - update 我们搭建了自己的升级服务器,如果有需要的朋友可以联系我们获得服务器地址。后面所有启动的CoreOS服务器,我们均假设管理员已经提前完成了版本升级的工作, 在流程中不再重复。如果阿里云开始提供最新的CoreOS镜像,那这一步可以省略掉。
引入kube-aliyun解决兼容问题 在前面分析现状时,我们提到了阿里云的CloudProvider暂时还未被并入Kubernetes,所以我们需要额外的工具来解决原生Kubernetes与阿里云之间的兼容问题。
针对这一问题,我们开发了一款名为kube-aliyun的工具。kube-aliyun以controller的形式运行在集群内部,提供以下的功能:
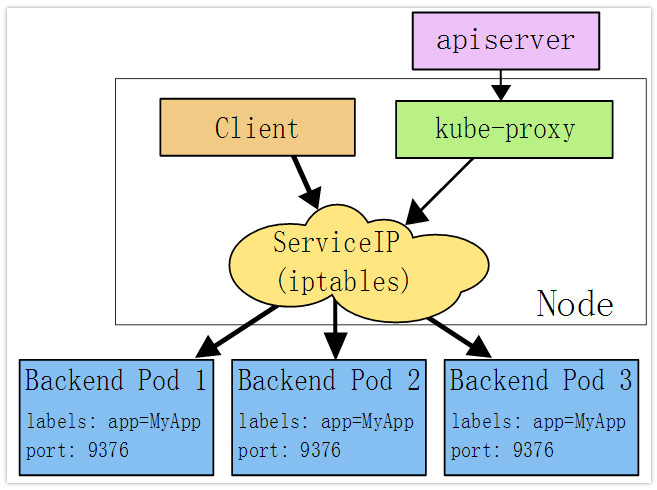
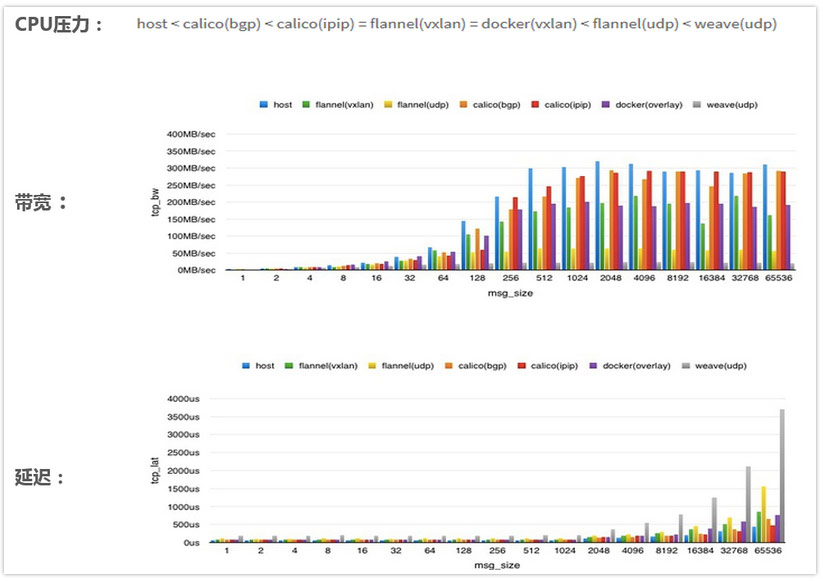
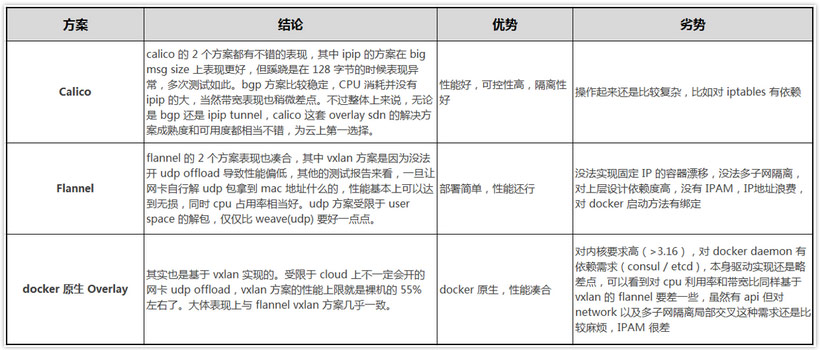
配置VPC路由,使得集群内的Pod网络互通 使用SLB支持LoadBalancer类型的Service 使用flexv支持云盘类型的Volume的动态挂载以及解除挂载 容器网络方案选型 Kubernetes要求所有集群内部的Pod可以不经过NAT互访,所以我们需要在服务器网络之上再搭建一层容器网络。容器网络的实现方案有多种,比如常见的flannel,calico等。 在这里我们选择了更加简单的kubenet +hostroutes方案。hostroutes是我们专门配合kubenet开发的路由配置工具, 详细的信息可以参考它的Github主页,以及这篇文档。
如果集群规模较小,我们还可以使用kube-aliyun的VPC路由配置功能。这样主机上不用对路由做任何的配置,所有的网络路由交给了VPC来完成,也不失为一种简单易用的方案。
SSL证书管理 SSL证书和配置是使用Kubernetes过程中非常容易出问题的点。这里推荐使用cfssl来做证书的生成和管理,主要看重了cfssl简单易用的特点,比起openssl更加容易操作和自动化。 cfssl的使用方法请参考官方的文档,这里不再重复。
在Kubernetes集群当中,我们一共需要生成4种类型的证书。另外etcd也可以通过证书进行验证和保护。出于复杂度考虑今天暂时不使用。
API Server证书 API Server证书主要用于客户端程序连接apiserver时进行加密和验证。可以使用以下模板作为CSR,填入相应的参数后生成:
{
"CN" : "${CLUSTER_NAME}" ,
"hosts" : [
"kubernetes" ,
"kubernetes.default" ,
"kubernetes.default.svc" ,
"kubernetes.default.svc.cluster.local" ,
"10.3.0.1" ,
"${SERVER_PRIVATE_IP}" ,
"${SERVER_PUBLIC_IP}" ,
"${LOAD_BALANCER_IP}"
],
"key" : {
"algo" : "ecdsa" ,
"size" : 256
}
} 之后将以${APISERVER_PEM}和${APISERVER_KEY}分别表示生成出的证书和私匙。
kubelet证书 kubelet证书用于系统组件访问kubelet内置的HTTP Server,获取运行状态或者调用kubelet提供的功能时进行加密和验证。CSR模板如下:
{
"CN" : "${SERVER_NAME}" ,
"hosts" : [
"${SERVER_NAME}" ,
"${SERVER_PRIVATE_IP}" ,
"${SERVER_PUBLIC_IP}"
],
"key" : {
"algo" : "ecdsa" ,
"size" : 256
}
} 之后将以${SERVER_PEM}和${SERVER_KEY}分别表示生成出的证书和私匙。
Service Account证书 Service Account证书用于生成各个Namespace默认的token,以及进行token验证。在集群内部服务访问API Server时会使用这个token进行身份认证。CSR模板如下:
{
"CN" : "service-account" ,
"hosts" : [
"service-account"
],
"key" : {
"algo" : "ecdsa" ,
"size" : 256
}
} 之后将以${SERVICEACCOUNT_PEM}和${SERVICEACCOUNT_KEY}分别表示生成出的证书和私匙。
kubectl证书 kubectl证书用于管理员或者用户远程访问集群,下达各种指令时的身份认证。CSR模板如下:
{
"CN" : "${USERNAME}" ,
"hosts" : [
"${USERNAME}"
],
"key" : {
"algo" : "ecdsa" ,
"size" : 256
}
} 在创建集群时并不需要这一证书,但是在集群创建完成后需要为所有用户生成证书,才能配置好本地的kubectl,获得访问集群的权限。
创建VPC 在阿里云控制台界面,可以很方便的创建VPC,选择目标可用区,并创建服务器所在网段即可。这里我们用10.99.0.0/24这个网段,读者可以根据自身业务设计选择适合的网段。 这里我们选择的网段,除去阿里云提供的服务以及内网SLB占掉的IP地址,至少有200个以上的空余地址,足以满足绝大部分场景下的规模需要。
搭建etcd集群 CoreOS对etcd有原生的支持,我们可以使用CoreOS官方提供的discovery服务快速的完成etcd集群的搭建。
首先访问https://discovery.etcd.io/new?size=3,将得到的地址以及服务器IP地址填入以下文件当中:
#cloud-config
coreos :
etcd2 :
discovery : "https://discovery.etcd.io/<token>"
advertise - client - urls : "http://${SERVER_PRIVATE_IP}:2379"
initial - advertise - peer - urls : "http://${SERVER_PRIVATE_IP}:2380"
listen - client - urls : "http://0.0.0.0:2379"
listen - peer - urls : "http://${SERVER_PRIVATE_IP}:2380"
units :
- name : "start-etcd.service"
command : "start"
enable : true
content : |-
[ Service ]
Type = oneshot
ExecStart = /usr/ bin / systemctl start etcd2
[ Install ]
WantedBy = multi - user . target 接下来在VPC中创建3台服务器,并在服务器上创建文件cloud-init.yaml包含上面的内容。再使用coreos-cloudinit -from-file cloud-init.yaml对服务器进行初始化。
一切顺利的话,各台服务器上的etcd服务将找到其他的节点,共同组成一个高可用的etcd集群。
搭建Master服务器组 在Master服务器组上,我们将在每台服务器上通过kubelet运行kube-aliyun、kube-controller-manager、kube-scheduler这几个组件。 为了简化配置流程,我们依然使用cloud-init来进行服务器初始化。将etcd服务器组的内网IP填入以下文件:
#cloud-config
coreos :
units :
- name : "docker.service"
drop - ins :
- name : "50-docker-opts.conf"
content : |
[ Service ]
Environment = DOCKER_OPTS = '--registry-mirror="https://${YOUR_MIRROR}.mirror.aliyuncs.com"'
- name : "kubelet.service"
command : "start"
enable : true
content : |-
[ Service ]
Environment = KUBELET_VERSION = v1 . 5.1 _coreos . 0
Environment = KUBELET_ACI = kubeup . com / aci / coreos / hyperkube
Environment = "RKT_OPTS=--uuid-file-save=/var/run/kubelet-pod.uuid \
--trust-keys-from-https \
--volume dns,kind=host,source=/etc/resolv.conf \
--mount volume=dns,target=/etc/resolv.conf \
--volume var-log,kind=host,source=/var/log \
--mount volume=var-log,target=/var/log \
--volume lib-modules,kind=host,source=/lib/modules \
--mount volume=lib-modules,target=/lib/modules"
ExecStartPre = /usr/ bin / systemctl stop update - engine
ExecStartPre = /usr/ bin / mkdir - p / etc / kubernetes / manifests
ExecStartPre = /usr/ bin / mkdir - p / var / log / containers
ExecStartPre =-/ usr / bin / rkt rm -- uuid - file = /var/ run / kubelet - pod . uuid
ExecStart = /usr/ lib / coreos / kubelet - wrapper \
-- api_servers = http : //localhost:8080 \
-- register - schedulable = false \
-- allow - privileged = true \
-- config = /etc/ kubernetes / manifests \
-- cluster - dns = 10.3 . 0.10 \
-- node - ip = $ { SERVER_PRIVATE_IP } \
-- hostname - override = $ { SERVER_PRIVATE_IP } \
-- cluster - domain = cluster . local \
-- network - plugin = kubenet \
-- tls - cert - file = /etc/ kubernetes / ssl / server . pem \
-- tls - private - key - file = /etc/ kubernetes / ssl / server - key . pem \
-- pod - infra - container - image = registry . aliyuncs . com / archon / pause - amd64 : 3.0
ExecStop =-/ usr / bin / rkt stop -- uuid - file = /var/ run / kubelet - pod . uuid
Restart = always
RestartSec = 10
User = root
[ Install ]
WantedBy = multi - user . target
write_files :
- path : "/etc/kubernetes/manifests/kube-apiserver.yaml"
permissions : "0644"
owner : "root"
content : |
apiVersion : v1
kind : Pod
metadata :
name : kube - apiserver
namespace : kube - system
spec :
hostNetwork : true
containers :
- name : kube - apiserver
image : registry . aliyuncs . com / archon / hyperkube - amd64 : v1 . 5.1
command :
- /hyperkube
- apiserver
- --bind-address=0.0.0.0
- --etcd-servers=http:/ / $ { ETCD_SERVER1_IP }: 2379 , http : //${ETCD_SERVER2_IP}:2379,http://${ETCD_SERVER3_IP}:2379
- -- allow - privileged = true
- -- service - cluster - ip - range = 10.3 . 0.0 / 24
- -- runtime - config = extensions / v1beta1 = true , extensions / v1beta1 / thirdpartyresources = true
- -- secure - port = 443
- -- advertise - address = $ { LOAD_BALANCER_IP }
- -- admission - control = NamespaceLifecycle , NamespaceExists , LimitRanger , SecurityContextDeny , ServiceAccount , ResourceQuota
- -- tls - cert - file = /etc/ kubernetes / ssl / apiserver . pem
- -- tls - private - key - file = /etc/ kubernetes / ssl / apiserver - key . pem
- -- service - account - key - file = /etc/ kubernetes / ssl / serviceaccount - key . pem
- -- client - ca - file = /etc/ kubernetes / ssl / ca . pem
ports :
- containerPort : 443
hostPort : 443
name : https
- containerPort : 8080
hostPort : 8080
name : local
volumeMounts :
- mountPath : /etc/ kubernetes / ssl
name : ssl - certs - kubernetes
readOnly : true
- mountPath : /etc/ ssl / certs
name : ssl - certs - host
readOnly : true
volumes :
- hostPath :
path : /etc/ kubernetes / ssl
name : ssl - certs - kubernetes
- hostPath :
path : /usr/ share / ca - certificates
name : ssl - certs - host
- path : "/etc/kubernetes/manifests/kube-proxy.yaml"
permissions : "0644"
owner : "root"
content : |
apiVersion : v1
kind : Pod
metadata :
name : kube - proxy
namespace : kube - system
spec :
hostNetwork : true
containers :
- name : kube - proxy
image : registry . aliyuncs . com / archon / hyperkube - amd64 : v1 . 5.1
command :
- /hyperkube
- proxy
- --master=http:/ / 127.0 . 0.1 : 8080
- -- proxy - mode = iptables
securityContext :
privileged : true
volumeMounts :
- mountPath : /etc/ ssl / certs
name : ssl - certs - host
readOnly : true
volumes :
- hostPath :
path : /usr/ share / ca - certificates
name : ssl - certs - host
- path : "/etc/kubernetes/manifests/kube-controller-manager.yaml"
permissions : "0644"
owner : "root"
content : |
apiVersion : v1
kind : Pod
metadata :
name : kube - controller - manager
namespace : kube - system
spec :
hostNetwork : true
containers :
- name : kube - controller - manager
image : registry . aliyuncs . com / archon / hyperkube - amd64 : v1 . 5.1
command :
- /hyperkube
- controller-manager
- --master=http:/ / 127.0 . 0.1 : 8080
- -- leader - elect = true
- -- service - account - private - key - file = /etc/ kubernetes / ssl / serviceaccount - key . pem
- -- root - ca - file = /etc/ kubernetes / ssl / ca . pem
- -- allocate - node - cidrs = true
- -- cluster - cidr = 10.2 . 0.0 / 16
- -- configure - cloud - routes = false
livenessProbe :
httpGet :
host : 127.0 . 0.1
path : /healthz
port: 10252
initialDelaySeconds: 15
timeoutSeconds: 1
volumeMounts:
- mountPath: / etc / kubernetes / ssl
name : ssl - certs - kubernetes
readOnly : true
- mountPath : /etc/ ssl / certs
name : ssl - certs - host
readOnly : true
volumes :
- hostPath :
path : /etc/ kubernetes / ssl
name : ssl - certs - kubernetes
- hostPath :
path : /usr/ share / ca - certificates
name : ssl - certs - host
- path : "/etc/kubernetes/manifests/kube-scheduler.yaml"
permissions : "0644"
owner : "root"
content : |
apiVersion : v1
kind : Pod
metadata :
name : kube - scheduler
namespace : kube - system
spec :
hostNetwork : true
containers :
- name : kube - scheduler
image : registry . aliyuncs . com / archon / hyperkube - amd64 : v1 . 5.1
command :
- /hyperkube
- scheduler
- --master=http:/ / 127.0 . 0.1 : 8080
- -- leader - elect = true
livenessProbe :
httpGet :
host : 127.0 . 0.1
path : /healthz
port: 10251
initialDelaySeconds: 15
timeoutSeconds: 1
- path: "/ etc / kubernetes / manifests / kube - aliyun . yaml "
permissions: " 0644 "
owner: " root "
content: |
apiVersion: v1
kind: Pod
metadata:
name: aliyun-controller
namespace: kube-system
spec:
hostNetwork: true
containers:
- name: aliyun-controller
image: registry.aliyuncs.com/kubeup/kube-aliyun
command:
- /aliyun-controller
- --server=http://127.0.0.1:8080
- --leader-elect=true
- --cluster-cidr=10.2.0.0/16
env:
- name: ALIYUN_ACCESS_KEY
valueFrom:
secretKeyRef:
name: aliyun-creds
key: accessKey
- name: ALIYUN_ACCESS_KEY_SECRET
valueFrom:
secretKeyRef:
name: aliyun-creds
key: accessKeySecret
- name: ALIYUN_REGION
value: ${YOUR_VPC_REGION}
- name: ALIYUN_VPC
value: ${YOUR_VPC_ID}
- name: ALIYUN_ROUTER
value: ${YOUR_ROUTER_ID}
- name: ALIYUN_ROUTE_TABLE
value: ${YOUR_ROUTE_TABLE_ID}
- name: ALIYUN_VSWITCH
value: ${YOUR_VSWITCH_ID}
- path: " / etc / kubernetes / ssl / ca . pem "
permissions: " 0644 "
owner: " root "
content: |
${CA_PEM}
- path: " / etc / kubernetes / ssl / apiserver . pem "
permissions: " 0644 "
owner: " root "
content: |
${APISERVER_PEM}
- path: " / etc / kubernetes / ssl / apiserver - key . pem "
permissions: " 0600 "
owner: " root "
content: |
${APISERVER_KEY}
- path: " / etc / kubernetes / ssl / serviceaccount . pem "
permissions: " 0644 "
owner: " root "
content: |
${SERVICEACCOUNT_PEM}
- path: " / etc / kubernetes / ssl / serviceaccount - key . pem "
permissions: " 0600 "
owner: " root "
content: |
${SERVICEACCOUNT_KEY}
- path: " / etc / kubernetes / ssl / server . pem "
permissions: " 0644 "
owner: " root "
content: |
${SERVER_PEM}
- path: " / etc / kubernetes / ssl / server - key . pem "
permissions: " 0600 "
owner: " root "
content: |
${SERVER_KEY} 接下来使用cloud-init在新创建的2台服务器上完成服务器初始化。经过一定时间的镜像拉取,所有组件将正常启动,这时可以在主机上用kubectl来验证服务器的启动状态。
创建LoadBalancer 如果直接使用Master服务器组当中的任何一台服务器,会存在单点故障。我们使用阿里云控制台创建一个内网的SLB服务,在两台服务器之上提供一个稳定的负载均衡的apiserver。 具体的操作流程请参考相关阿里云的文档,因为apiserver暴露在443端口,我们只需要配置443端口的负载均衡即可。
搭建Node服务器组 Node服务器组的初始化与Master服务器组的初始化类似。我们可以一次性启动N台服务器,然后在每台服务器上用以下配置进行初始化:
#cloud-config
coreos :
units :
- name : "docker.service"
drop - ins :
- name : "50-docker-opts.conf"
content : |
[ Service ]
Environment = DOCKER_OPTS = '--registry-mirror="https://${YOUR_MIRROR}.mirror.aliyuncs.com"'
- name : "kubelet.service"
command : "start"
enable : true
content : |-
[ Service ]
Environment = KUBELET_VERSION = v1 . 5.1 _coreos . 0
Environment = KUBELET_ACI = kubeup . com / aci / coreos / hyperkube
Environment = "RKT_OPTS=--uuid-file-save=/var/run/kubelet-pod.uuid \
--trust-keys-from-https \
--volume dns,kind=host,source=/etc/resolv.conf \
--mount volume=dns,target=/etc/resolv.conf \
--volume var-log,kind=host,source=/var/log \
--mount volume=var-log,target=/var/log \
--volume lib-modules,kind=host,source=/lib/modules \
--mount volume=lib-modules,target=/lib/modules"
ExecStartPre = /usr/ bin / systemctl stop update - engine
ExecStartPre = /usr/ bin / mkdir - p / etc / kubernetes / manifests
ExecStartPre = /usr/ bin / mkdir - p / var / log / containers
ExecStartPre =-/ usr / bin / rkt rm -- uuid - file = /var/ run / kubelet - pod . uuid
ExecStart = /usr/ lib / coreos / kubelet - wrapper \
-- api_servers = https : //${APISERVER_ENDPOINT}:443 \
-- register - schedulable = true \
-- allow - privileged = true \
-- pod - manifest - path = /etc/ kubernetes / manifests \
-- cluster - dns = 10.3 . 0.10 \
-- node - ip = $ { SERVER_PRIVATE_IP } \
-- hostname - override = $ { SERVER_PRIVATE_IP } \
-- cluster - domain = cluster . local \
-- network - plugin = kubenet \
-- kubeconfig = /etc/ kubernetes / node - kubeconfig . yaml \
-- tls - cert - file = /etc/ kubernetes / ssl / server . pem \
-- tls - private - key - file = /etc/ kubernetes / ssl / server - key . pem \
-- pod - infra - container - image = registry . aliyuncs . com / archon / pause - amd64 : 3.0
ExecStop =-/ usr / bin / rkt stop -- uuid - file = /var/ run / kubelet - pod . uuid
Restart = always
RestartSec = 10
User = root
[ Install ]
WantedBy = multi - user . target
write_files :
- path : "/etc/kubernetes/manifests/kube-proxy.yaml"
permissions : "0644"
owner : "root"
content : |
apiVersion : v1
kind : Pod
metadata :
name : kube - proxy
namespace : kube - system
spec :
hostNetwork : true
containers :
- name : kube - proxy
image : registry . aliyuncs . com / archon / hyperkube - amd64 : v1 . 5.1
command :
- /hyperkube
- proxy
- --master=https:/ / $ { APISERVER_ENDPOINT }: 443
- -- kubeconfig = /etc/ kubernetes / node - kubeconfig . yaml
securityContext :
privileged : true
volumeMounts :
- mountPath : /etc/ ssl / certs
name : ssl - certs - host
readOnly : true
- mountPath : /etc/ kubernetes / node - kubeconfig . yaml
name : kubeconfig
readOnly : true
- mountPath : /etc/ kubernetes / ssl
name : etc - kube - ssl
readOnly : true
volumes :
- hostPath :
path : /usr/ share / ca - certificates
name : ssl - certs - host
- hostPath :
path : /etc/ kubernetes / node - kubeconfig . yaml
name : kubeconfig
- hostPath :
path : /etc/ kubernetes / ssl
name : etc - kube - ssl
- path : "/etc/kubernetes/node-kubeconfig.yaml"
permissions : "0644"
owner : "root"
content : |
apiVersion : v1
kind : Config
clusters :
- name : local
cluster :
certificate - authority : /etc/ kubernetes / ssl / ca . pem
users :
- name : kubelet
user :
client - certificate : /etc/ kubernetes / ssl / server . pem
client - key : /etc/ kubernetes / ssl / server - key . pem
contexts :
- context :
cluster : local
user : kubelet
name : kubelet - context
current - context : kubelet - context
- path : "/etc/kubernetes/ssl/ca.pem"
permissions : "0644"
owner : "root"
content : |
$ { CA_PEM }
- path : "/etc/kubernetes/ssl/server.pem"
permissions : "0644"
owner : "root"
content : |
$ { SERVER_PEM }
- path : "/etc/kubernetes/ssl/server-key.pem"
permissions : "0600"
owner : "root"
content : |
$ { SERVER_KEY } 部署kube-aliyun与hostroutes kube-aliyun的Pod已经在Master服务器组的描述文件中进行了定义,但是这个Pod会因为缺少必要的Secret无法启动。 我们创建这个Secret,来激活kube-aliyun:
kubectl create secret generic aliyun - creds -- namespace = kube - system -- from - literal = accessKey = $ { YOUR_ACCESS_KEY } -- from - literal = accessKeySecret = $ { YOUR_ACCESS_KEY_SECRET } hostroutes是以DaemonSet的形式进行部署的。使用以下定义文件:
apiVersion : extensions / v1beta1
kind : DaemonSet
metadata :
name : hostrouts
labels :
app : hostroutes
spec :
template :
metadata :
name : hostroutes
labels :
app : hostroutes
spec :
hostNetwork : true
containers :
- resources :
requests :
cpu : 0.20
securityContext :
privileged : true
image : kubeup / hostroutes
name : hostroutes
command : [ "/hostroutes" , "--in-cluster" ] 自动化部署和运维 经过前面的手工集群搭建,我们可以发现明显的重复模式。所有的服务器我们均是使用coreos-cloudinit -from-file cloud-init.yaml这个指令完成初始化, 唯一不同的就是不同的服务器组有不同的配置文件模板。这时动手能力强的同学已经可以自己进行简单的编程来简化服务器初始化流程了。
这种初始化模式是我们有意设计的,目的是为了使用程序来实现服务器的自动化运维。我们将以上的实践抽象成了一款叫做Archon的集群管理系统, 方便用户使用描述式的方法来创建和管理集群,这样一个指令就可以完成集群扩容、升级这些日常运维工作,大大降低了运维工程师的工作负担。
关于Archon系统,这里就不详细介绍了。有兴趣的朋友可以访问项目的Github地址https://github.com/kubeup/archon 了解更多的信息。
总结 在本文中,我们首先分析了在阿里云上部署生产级别Kubernetes所具有的优势以及面临的挑战。接着演示了基于CoreOS,使用kube-aliyun以及hostroutes来解决目前存在问题的方法。 最后提出使用archon来进行自动化集群创建以及运维的可能性。整个集群设计充分考虑了生产环境的高可用性需求,同时也使得管理员在运维时可以将出故障的服务器离线进行维护, 或者使用RollingUpdate的方法删除老服务器创建新服务器来下发更新。
由于篇幅所限,部分步骤并没有进行详细的解说,读者在阅读时可以更加注重对原理和思路的理解。在理解了设计思路之后,大可采用自动化工具进行集群的创建和运维来提升工作效率。
本文并没有简单罗列创建集群过程所使用的全部指令,让读者可以一条一条剪切复制来照着操作,而是着重理清思路,帮助读者更好的理解集群搭建的工作细节。 在介绍集群创建流程环节,我们使用了更加底层的用cloud-init的定义文件进行服务器初始化这一演示方式,以期让读者能够清楚看到创建的所有配置文件的内容, 而不是简单依赖工具进行创建,导致出现故障时无法自主解决。文中使用的CoreOS,cfssl等工具可能对部分读者来说比较陌生,在使用过程中大可使用熟悉的工具进行替换,只要整体思路保持一致即可。
实际在生产环境中部署时,还需要部署日志和监控等系统组件,才能有效的对集群进行运维和管理。这些运行在集群之上的系统将留待以后的文章再做分享。
希望本文可以帮助更多的公司更好的在阿里云上利用Kubernetes构建自己的底层架构体系。并在Kubernetes上搭建起自己的DevOps体系,提高整体的研发和运行效率。
原文:https://jishu.io/kubernetes/deploy-production-ready-kubernetes-cluster-on-aliyun/
来源:https://www.kubernetes.org.cn/1667.html