Flannel概述
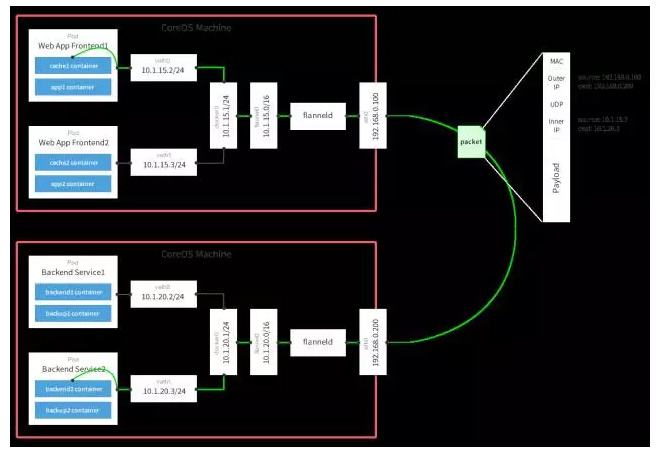
值得探讨的是,flannel的这个overlay网络支持多种后端实现,除上图中的UDP,还有VXLAN和host-gw等。此外,flannel支持通过两种模式来维护隧道端点上FDB的信息,其中一种是通过连接Etcd来实现,另外一种是直接对接K8S,通过K8S添加删除Node来触发更新。
Flannel部署常见问题
1. Node状态显示为“NotReady”
我的K8S环境使用kubeadm来容器化运行K8S的各个组件(除kubelet直接运行在裸机上外),当我使用kubeadm join命令加入新的Minion Node到K8S集群中后,通过kubectl get node会发现所有的node都还是not ready状态,这是因为还没有配置好flannel网络。
2. 使用kube-flannel.yml无法创建DaemonSet
我使用的是K8S的1.6.4的版本,然后按照官方的说明,使用kube-flannel.yml来创建flannel deamon set,结果始终报错。正确的姿势是先使用kube-flannel-rbac.yml来创建flannel的ClusterRole并授权。该yml的主要作用是创建名叫flannel的ClusterRole,然后将该ClusterRole与ServiceAccount(flannel)绑定。接下来,当我们使用kube-flannel.yml来创建flannel daemon set的时候,该daemon set明确指定其Pod的ServiceAccount为flannel,于是通过它启动起来的Pod就具有了flannel ClusterRole中指定的权限。
3.flannel Pod状态为Running,网络不通
我之前在我的Mac Pro上跑了三个VM,为了能够访问公网拉取镜像,我为每个VM分配了一张网卡使用NAT模式,其分配到的IP地址可能重启后发生变化。另外,为了我本机方便管理,我为每台VM又分配了一张网卡使用Host-Only网络模式,每个网卡都有一个固定的IP地址方便SSH。然后,奇怪的事情就这样发生了….
原因在与在kube-flannel.yml中,kube-flannel容器的command被指定为:
command: [ "/opt/bin/flanneld", "--ip-masq", "--kube-subnet-mgr"]
可见,其并没有指定使用哪一张网卡作为flanneld对外通信的物理网卡,于是,可能由于机器上面路由配置的差异,导致三台机器并没有一致通过Host-Only网络模式的网卡来打通Overlay网络。遇到这种情况,如果几台机器的配置一致,可以手动修改kube-flannel.yml文件中kube-flannel的command的值,添加参数–iface=ethX,这里的ethX就为我们希望flanneld通信使用的网卡名称。
4.flannel启动异常,显示install-cni错误
这个现象比较坑,遇到这种情况的第一反应就是去查看install-cni容器到底做了什么。我们打开kube-flannel.yml可以看到,该容器的command字段只有简单的一行Shell:
command: [ "/bin/sh", "-c", "set -e -x; cp -f /etc/kube-flannel/cni-conf.json /etc/cni/net.d/10-flannel.conf; while true; do sleep 3600; done" ]
也就是将镜像中做好的cni-conf.json拷贝到cni的netconf目录下。由于容器的/etc/cni/net.d是挂载主机的对应的目录,所以该操作主要目的是为CNI准备flannel环境,便于启动容器的时候正确从netconf目录中加载到flannel,从而使用flannel网络。
我发现进入主机的netconf目录中能够看到10-flannel.conf:
#ls /etc/cni/net.d/10-flannel.conf /etc/cni/net.d/10-flannel.conf # cat /etc/cni/net.d/10-flannel.conf cat: /etc/cni/net.d/10-flannel.conf: No such file or directory
无法打出其内容,而且文件显示为红色,说明其内容并没有正确从容器中拷贝过来。
之前我怀疑该异常是因为kubelet所带的文件系统参数为systemd,而docker的文件系统参数为cgroupfs所致,结果发现并非如此。当前能够绕开该异常的workaround为手动进入到主机的netconf目录,创建10-flannel.conf目录,并写入以下数据:
{ "name": "cbr0", "type": "flannel", "delegate": { "isDefaultGateway": true } }
5.flannel网络启动正常,能够创建pod,但是网络不通
出现该现象一般会想到debug,而debug的思路当然是基于官方的那张网络拓扑图。比如在我的机器上,通过参看网卡IP地址有如下信息:
6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN link/ether 22:a0:ce:3c:bf:1f brd ff:ff:ff:ff:ff:ff inet 10.244.1.0/32 scope global flannel.1 valid_lft forever preferred_lft forever inet 10.244.2.0/32 scope global flannel.1 valid_lft forever preferred_lft forever 7:cni0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1450 qdisc noqueue state DOWN qlen 1000 link/ether 0a:58:0a:f4:01:01 brd ff:ff:ff:ff:ff:ff inet 10.244.1.1/24 scope global cni0 valid_lft forever preferred_lft forever inet6 fe80::4cb6:7fff:fedb:2106/64 scope link valid_lft forever preferred_lft forever
很明显,cni0为10.244.1.1/24网段,说明该主机应该位于10.244.1.0/16子网内;但是我们看flannel.1网卡,确有两个IP地址,分别为于两个不同的”/16”子网。所以,可以肯定的是,我们一定是在该太主机上部署了多次kubeadm,而kubeadm reset并不会清理flannel创建的flannel.1和cni0接口,这就导致环境上遗留下了上一次部署分配到的IP地址。这些IP地址会导致IP地址冲突,子网混乱,网络通信异常。
解决的方法就是每次执行kubeadm reset的时候,手动执行以下命令来清楚对应的残余网卡信息:
ip link del cni0 ip link del flannel.1
K8S如何使用Flannel网络
Flannel打通Overlay网络
当使用kubeadm来部署k8s,网络组件(如flannel)是通过Add-ons的方式来部署的。我们使用这个yml文件来部署的flannel网络。
我截除了关键的一段内容(containers spec):
containers: - name: kube-flannel image: quay.io/coreos/flannel:v0.7.1-amd64 command: [ "/opt/bin/flanneld", "--ip-masq", "--kube-subnet-mgr" ] securityContext: privileged: true env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace volumeMounts: - name: run mountPath: /run - name: flannel-cfg mountPath: /etc/kube-flannel/ - name: install-cni image: quay.io/coreos/flannel:v0.7.1-amd64 command: [ "/bin/sh", "-c", "set -e -x; cp -f /etc/kube-flannel/cni-conf.json /etc/cni/net.d/10-flannel.conf; while true; do sleep 3600; done" ] volumeMounts: - name: cni mountPath: /etc/cni/net.d - name: flannel-cfg mountPath: /etc/kube-flannel/
通过分析该yaml文件可以知道:该pod内有两个container,分别为install-cni和 kube-flannel。
- install-cni
主要负责将config-map中适用于该flannel的CNI netconf配置拷贝到主机的CNI netconf 路径下,从而使得K8S在创建pod的时候可以遵照标准的CNI流程挂载网卡。
- kube-flannel
主要启动flanneld,该command中为flanneld的启动指定了两个参数: –ip-masq, –kube-subnet-mgr。第一个参数–ip-masq代表需要为其配置SNAT;第二个参数–kube-subnet-mgr代表其使用kube类型的subnet-manager。该类型有别于使用etcd的local-subnet-mgr类型,使用kube类型后,flannel上各Node的IP子网分配均基于K8S Node的spec.podCIDR属性。可以参考下图的方式来查看(该示例中,k8s为node-1节点分配的podCIDR为:10.244.8.0/24):
#kubectl edit node node-1 apiVersion: v1 kind: Node ... name: dev-1 resourceVersion: "2452057" selfLink: /api/v1/nodesdev-1 uid: 31f6e4c3-57b6-11e7-a0a5-00163e122a49 spec: externalID: dev-1 podCIDR: 10.244.8.0/24
另外,flannel的subnet-manager通过监测K8S的node变化来维护了一张路由表,这张表里面描述了要到达某个Pod子网需要先到达哪个EndPoint。
CNI挂载容器到隧道端点
如果说flannel为Pod打通了一张跨node的大网,那么CNI就是将各个终端Pod挂载到这张大网上的安装工人。
在刚部署好flannel网络并未在该Node上启动任何Pod时,通过ip link我们只能够看到flannel.1这张网卡,却无法看到cni0。难道是flannel网络运行异常吗?我们接下来就来分析flannel的CNI实现原理,就知道答案了。
通过传统方式来部署flannel都需要通过脚本来修改dockerd的参数,从而使得通过docker创建的容器能够挂载到指定的网桥上。但是flannel的CNI实现并没有采用这种方式。通过分析CNI代码,
我们可以了解flannel CNI的流程:
- 读取netconf配置文件,并加载/run/flannel/subnet.env环境变量信息。
- 基于加载的信息,生成适用于其delegate的ipam和CNI bridge的netconf文件;其中指定ipam使用host-local,CNI bridge type为bridge。
- 调用deletgate(CNI bridge type)对应的二进制文件来挂载容器到网桥上。
这里的环境变量文件/run/flannel/subnet.env是由flanneld生成的,里面包含了该主机所能够使用的IP子网网段,具体内容如下:
# cat /run/flannel/subnet.env FLANNEL_NETWORK=10.244.0.0/16 FLANNEL_SUBNET=10.244.8.1/24 FLANNEL_MTU=1450 FLANNEL_IPMASQ=true
这些数据生成ipam的配置文件的依据,另外,flannel CNI插件的代码中,默认指定delegate为bridge:
if !hasKey(n.Delegate, "type") { n.Delegate["type"] = "bridge" }
所以,当flannel CNI插件调用delegate,本质上就是调用bridge CNI插件来将容器挂载到网桥上。分析bridge CNI 插件的过程我们可以看到其指定了默认网桥名称为cni0:
const defaultBrName = "cni0" func loadNetConf(bytes []byte) (*NetConf, error) { n := &NetConf{ BrName: defaultBrName, } ... return n, nil }
因此,现在我们可以将整个流程连起来了:flannel CNI插件首先读取netconf配置和subnet.env信息,生成适用于bridge CNI插件的netconf文件和ipam(host-local)配置,并设置其delegate为bridge CNI插件。然后调用走bridge CNI插件挂载容器到bridge的流程。由于各个Pod的IP地址分配是基于host-local的Ipam,因此整个流程完全是分布式的,不会对API-Server造成太大的负担。
至此,基于kubeadm的flannel分析就大致结束了,希望对您有帮助!
来源: https://www.kubernetes.org.cn/2270.html



