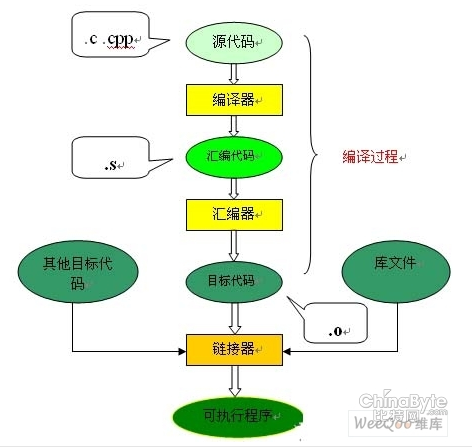
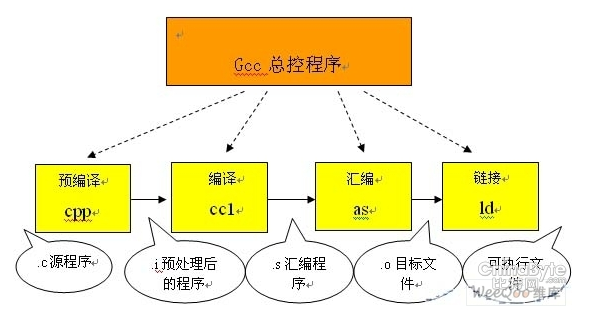
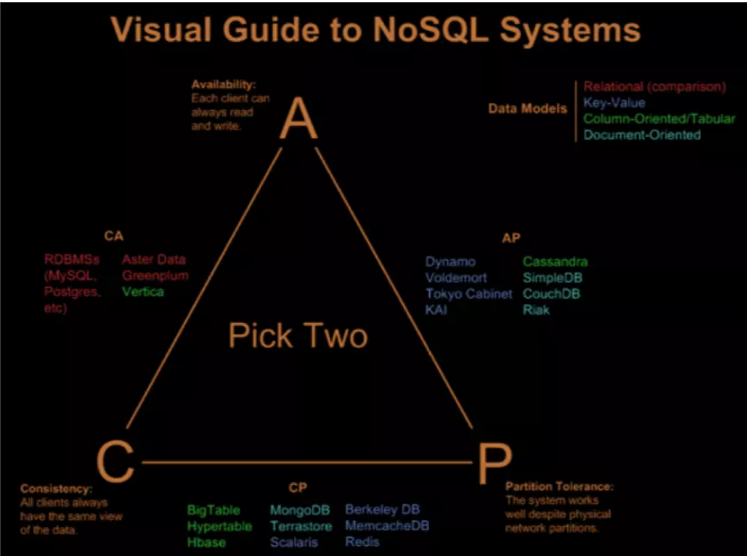
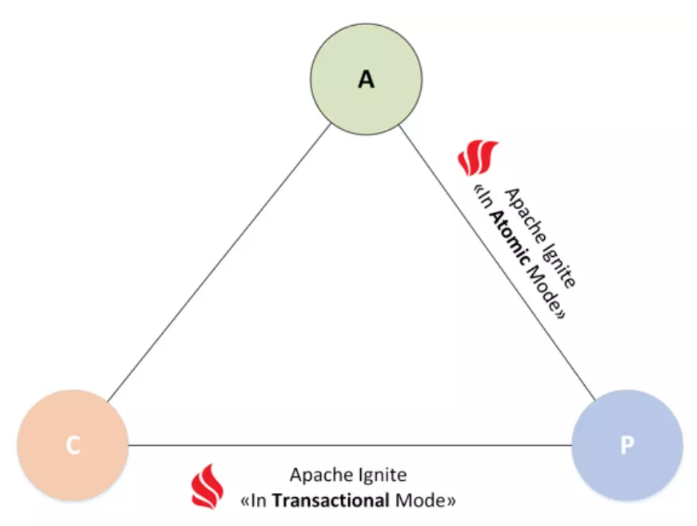
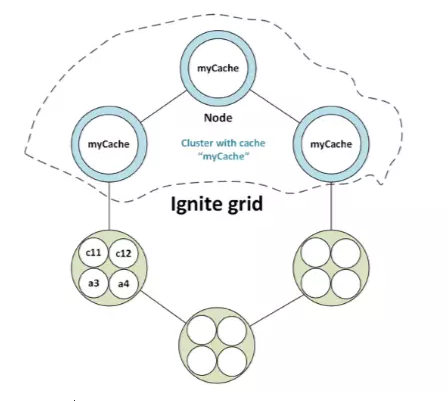
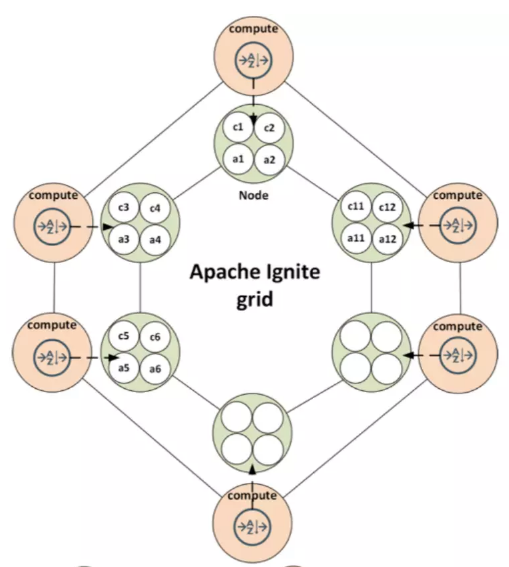
极客侠网站导航(全部书单资源导航页):https://pymlovelyq.github.io/archives/
前言:技术书阅读方法论总结
一.速读一遍(最好在1~2天内完成)
人的大脑记忆力有限,在一天内快速看完一本书会在大脑里留下深刻印象,对于之后复习以及总结都会有特别好的作用。
对于每一章的知识,先阅读标题,弄懂大概讲的是什么主题,再去快速看一遍,不懂也没有关系,但是一定要在不懂的地方做个记号,什么记号无所谓,但是要让自己后面再看的时候有个提醒的作用,看看第二次看有没有懂了些。二.精读一遍(在2周内看完)
有了前面速读的感觉,第二次看会有慢慢深刻了思想和意识的作用,具体为什么不要问我,去问30年后的神经大脑专家,现在人类可能还没有总结出为什么大脑对记忆的完全方法论,但是,就像我们专业程序员,打代码都是先实践,然后就渐渐懂了过程,慢慢懂了原理,所以第二遍读的时候稍微慢下来,2周内搞定。记住一句话:没看完一个章节后,总结一下这个章节讲了啥。很关键。
三.实践(在整个过程中都要)
实践的时候,要注意不用都去实践,最好看着书,敲下代码,把重点的内容敲一遍有个肌肉记忆就很不错了。
以及到自己做过的项目中去把每个有涉及的原理的代码,研究一遍,就可以了
一共四个系列整整32本电子书,找了好久终于齐了,如果都能看完看懂且科学的总结外加合理的实践,相信未来你的技术路会更好走,当然阿里巴巴,腾讯,阿里这些的Offer不将是梦,除了多看点技术书,你觉得还有什么能拿出来和985,211的朋友比呢?
最后 附上这32本书的电子版链接:
所有资源百度网盘链接:https://pan.baidu.com/s/1C0RDhilrwlmEIZ811oAZoA
提取码:s9si
复制这段内容后打开百度网盘手机App,操作更方便哦
备注:里面已经顺便整理压缩好,需要下载后才可以打开,网盘直接打开会显示损坏。
资源图示(下载链接如上):
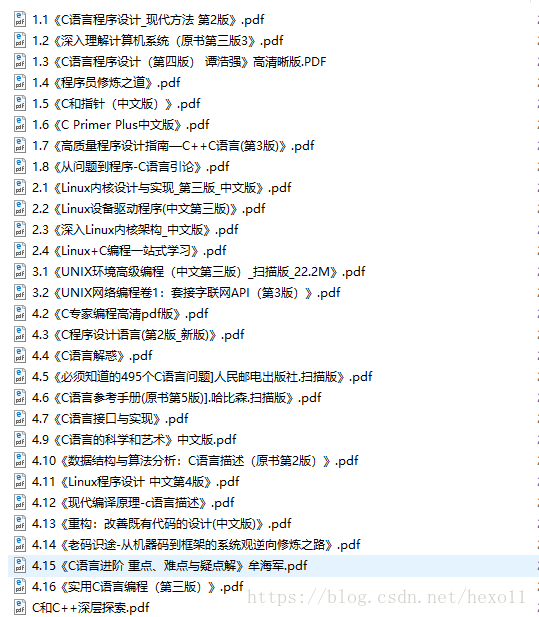
以下是每本书的推荐语,清楚自己缺的是什么,就下定决心去补吧,一个好工作意味着高收入,投资自己的时间换来更宝贵的东西。
一.C语言入门,初学,编程基础系列
1.《C语言程序设计:现代方法》(第2版)

推荐理由:时至今日, C语言仍然是计算机领域的通用语言之一,但今天的 C语言已经和最初的时候大不相同了。本书最主要的一个目的就是通过一种“现代方法”来介绍 C语言,书中强调标准 C,强调软件工程,不再强调“手工优化”。这一版中紧密结合了 C99标准,并与 C89标准进行对照,补充了 C99中的最新特性。本书分为 C语言的基础特性、 C语言的高级特性、 C语言标准库和参考资料 4个部分。每章末尾都有一个“问与答”小节给出一系列与该章内容相关的问题及答案,此外还包含适量的习题。
本书是为大学本科阶段的 C语言课程编写的教材,同时也非常适合作为其他课程的辅助用书。
2.《C语言程序设计》(第2版)谭浩强版本

这本书堪称经典之作初学者学习可以看看,这个就是零基础入门学习C语言的,上手快。但也要坚持上机,要是只看书,不在电脑上运行一下看看,是永远学不会的。关键在实践!坚持!
不过这本书被诟病的地方也不少,可以看完上面那本再看这本,很多东西就懂了。
3.《程序员修炼之道》

《程序员修炼之道》由一系列的独立的部分组成,涵盖的主题从个人责任、职业发展,直到用于使代码保持灵活、并且易于改编和复用的各种架构技术。利用许多富有娱乐性的奇闻轶事、有思想性的例子以及有趣的类比,全面阐释了软件开发的许多不同方面的最佳实践和重大陷阱。无论你是初学者,是有经验的程序员,还是软件项目经理,本书都适合你阅3读。
4.《C和指针》

看到书名很让人担心翻译的英语水平。实际不然,翻译的很好。只能说标题党了。看封面不难理解作者用pointers的意思吧,再说了书又不是只讲指针。书名用《C语言指导》更好些,
这是一本全面的C语言入门书。当然入门的深度和高度都比国内的教材高太多了。所以,如果你能直接从这本书开始学的话,起点会比较高,当然能学懂的话,说明你很有才。
一般情况下,本书的部分内容更适合有C基础的人看。如ADT、递归、指针和数组的部分,书中所述的思想是国内教材所缺乏的。看完本书,能得到一个正确的C语言观。
5.《C primer plus》(入门首选)

C prime Plus这本书看了两遍,练习题基本上都自己独立做完了。题目没怎么主动算法能力(毕竟不是算法的书),但是每个细节说的很清楚。初学者很容易找到信心的。学完c primer plus之后可以来看上面谭大爷的书找错误。
6.《高质量程序设计指南》(一定要看)

大一上学期的时候,一个偶然的机会接触了本书的第一版,引发了对软件工程的思考,让我很早就意识到代码规范的重要性,为今后学习打下了坚实基础,真的很感激这本书,虽然其内容都很简单,但是在我迷茫的时候真的给了我很多启迪。
7.《C/C++深层探索》

很早读过的书,很不错,姚的另外一本c标准:标准和实现也非常好。原创佳作~~语言的扩充成为C++,我们知道C语言是一种程式语言,而C++则为对象化语言,因此C++比C更加接近人类的语言,因此第四代语言就是人类语言,这就是说人类也是按照程式来行动的,也是一种程式动物或者程式生物。人类根据一定的世界的部分而创造的语言本不与世界一致或者总一致,因此才有扩充,但是基本词汇只有这么多,因此没办法表述所有的事物,因此不得不将词汇表扩充至一切声响,这就是音乐的美丽,音乐就是现代语言的最终发展。可见音乐的重要性。
8.《从问题到程序》(最佳高校教材)

既适合初入门到的小子,也适合相见恨晚的匹夫.这里不得不赞一下老裘借鉴得好,而且里面又简略提到不少CS里面的概念:
讲单词计数的时候顺带介绍了有限状态机;程序设计语言里的副作用,前条件,后条件,短路求值.习题也是很不错的,高斯消元,3n+1问题,约瑟夫环,实现一个简单”虚拟机”和”汇编器”还要弄单步执行功能不少open problem.
风格严谨,十分强调程序的强健和安全,测试.越界访问从头到尾都在强调,后面还自己实现了个通用整数输入检查函数,还有通用错误信息处理函数,错误处理讨论得很详细.代码简练,命名规范.老早就讲了函数,”强调通过函数抽象建立清晰结构的重要性”.提供大量的模式,实例和建议,教会初学者设计、权衡.内容不依赖任何具体C实现,讨论IDE好处和坏处.
作为第一本C语言是很合适的.
二.内核/驱动系列
1.《Linux C编程一站式学习》

此书内容涵盖极广:C的基本语法,简单的数据结构,C与汇编的联系,计算机系统结构,操作系统,正则表达式,TCP/IP,无所不包。如此一来似乎样样通而样样不精。其实不是这么回事。作者内容穿插得非常好,用十分简单的方式把每个方面最重要的东西阐明了。所以,其实这是本入门书,当然也适合各个方面都了解之后总结用。看完这本书可能觉得什么都懂一点但什么都不完全会,不要紧,后面的参考文献多数都是经典。入门书嘛,但求上手快。这本书上手就非常快。里面几乎一事一例,不多不少,恰到好处。而且例子基本都简单小巧可爱,不会的地方复制代码调试即可。
“我本来就是菜鸟一个,怎么了?国内这破环境,真正的大家才不稀罕写书,都捞钱去了。”其实中文书水平普遍低下,主要就是缺少宋劲杉老师这样的“菜鸟”。本书适合做零基础的初学者学习C语言的第一本教材,帮助读者打下牢固的基础。有一定的编程经验但知识体系不够完整的读者也可以对照本书查缺补漏,从而更深入地理解程序的工作原理。本书最初是为北京亚嵌教育研究中心的嵌入式Linux系统工程师就业班课程量身定做的教材之一,也适合作为高等院校程序设计基础课程的教材。本书对于C语言的语法介绍得非常全面,对C99标准做了很多解读,因此也可以作为一本精简的C语言语法参考书。
2.《Linux内核设计与实现》(第3版)

这书估计慕名而来的人都会在第一时间略感失望,首先书很薄,而且讲解不求深入。如果一个人在第一次翻阅此书的时候有这样的印象,那应该好好反省下自己是否太浮躁了。
其实这部书的定位有点不高不低,但也正因如此,它是最适合过渡阶段的内核学习者阅读的一部书。正确的阅读顺序或许应是这样的:恐龙书or现代OS->LDK->情景分析之类的详解书。
LDK很适合在你系统地学习了OS理论之后,直接看代码详解又觉得暂且还不够功力的学习者,它可以带你由理论学习阶段逐渐过渡到实践阶段。对于这样一部书,要是太厚就有点骗钱的嫌疑,要是太深入又会让人觉得作者故意显摆自己的学识。LDK算得上是恰到好处。
另外,本书后面的参考文献十分值得一读,要是您读完本书之后觉得不错,建议把它推荐的参考文献也找来读一读,或许会让您有更惊艳的感受。
3.《Linux设备驱动程序》(第3版)

适合中低水平的人。Linux 设备驱动模型真心复杂!对于写Linux驱动的人来说, 这本书应该是教科书级别的吧, 必读.
4.《深入Linux内核架构》
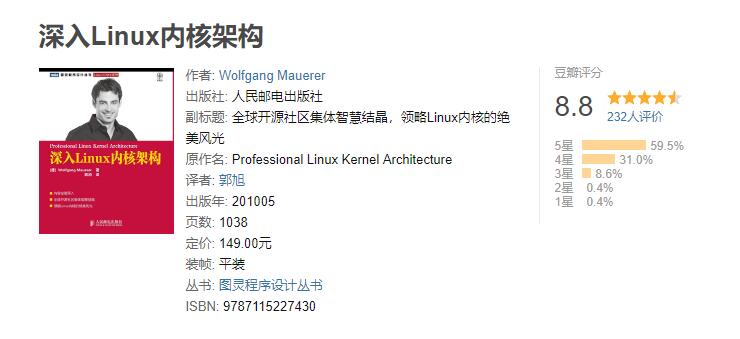
觉得是linux内核的一大作,坊间关于《深入理解linux内核》的传说,本人用自己的拙学是这么理解的。对于可以有较好的英文阅读能力的人,可以不用看毛德操的老师的书,后者已经完全可以替代了。注意现在比较的逻辑,并没有拿这本书去调戏《深入理解》,毕竟本人认为本书阅读时间该是有操作系统概念,然后还没有深入代码研究的阶段。所以同样还在摸索的你我,不要被本书的页数给吓到了,这本书我每天晚上花了3个小时,差不多花了45天阅读完,建议一口气看完,不然就打不到效果了,当然如果你是在校学生,我建议花一个学期对着源码研究。现在这本书也已经被我成功推荐到我们的team了…
三.应用系列
1.《UNIX环境高级编程》

好书的妙处之一,就是能给你与作者交流的感觉。技术书籍常犯两个毛病,一个是着眼点太低,堆砌细节(比如谭浩强的《C程序设计》),读起来好像听和尚念经,无法交流。再一个就是着眼点太高,兜售哲学(比如ESR的《The Art of UNIX Programming》),读起来好像听于丹老师讲论语,不敢交流。此书的经典性就在于不高不低不多不少,把UNIX系统编程的来龙去脉向你娓娓道来。很多地方都可以让你感觉到,你的疑惑作者在写书的时候已经了如指掌。从疑惑到顿悟的那一瞬间的畅快感是学习最大的快乐。所以,我们的口号就是:有问题,找APUE。
2.《UNIX网络编程》

还是在大二就买了这本书,但一直没拿起来看,各种拖延。了解 linux 下的网络编程,这本很赞。其中讲到了较为底层的网络编程系统调用和几种网络通信模式,譬如阻塞式,非阻塞式,I/O 多路复用等。但离实践还是由于一定的距离,网络编程中重点不在于系统调用,而是对具体的项目想要设计与之适应的网络模式。W.Richard Stevens 爹爹的书,每本都可以是经典。荐!
四.高能来袭,C语言进阶系列(学完就等着封神吧王者归来BAT等你)
1.《C陷阱与缺陷》

这是一本小册子,有让人继续读下去的欲望,倒不是因为页数少好欺负,是因为书中所说的几乎所有需要注意的地方作为一个程序员都有可能遇到,作者叙述起来很有意思,丝毫没有说教的感觉,举的例子很简单却一针见血。
此书作为一本常备读物是非常合适的,没事经常翻翻加深印象。
2.《C专家编程》

一年前我翻了翻这本书就觉得很棒,但那是我并不“主修”C,也没好好看,最近在认真读这本书,真是赞叹不已。
它使你对C的使用有深入了解,最后还介绍了一些C++,如果你以前没太多接触过C++,只知道C,通过这本书打开通往C++之门也不错。书中还提到了一些当年那些传说中Hacker的的故事,挺风趣的。
但是看这本书还是要有些背景的。
你要学过编译原理,虽然不需要学的太深太好,但至少对里面的一些概念要有所了解,否则对里面内存分配的部分(事实上很多是针对编译器的),你会感到吃力。还有,你要有些Unix/Linux的文化背景,比如Unix的C编程风格,还有Unix里的一些命令,工具。
3.《C语言程序设计》K&R版

拿到这本薄薄的书,很多人开始怀疑,C语言是这么几百页能讲清楚的么。看完这本书,我想答案已经很明了,却真的让人感到震憾。什么是好书?无法删减的书才是真正的好书。K&R的书一如C语言的设计理念:简单而高效
里面的习题建议都认真做一遍,而且是在linux下用vi来做,用makefile来编译,用shell脚本来进行测试,本来第八章的题就是和linux相关的
计算机的大学生们不应只会在WINDOWS下用VC来编程,而都应该在linux环境下进行程序设计,因为linux本身就是为开发者准备的操作系统
4.《C语言解惑》
本书脱胎于作者在C语言的摇篮——贝尔实验室教授C语言的讲稿,几乎涵盖了C语言各个方面的难点,并包含了一些其他书籍很少分析到的问题。在每个谜题后面都有详尽的解题分析,使读者能够清晰地把握C语言的构造与含义,学会处理许多常见的限制和陷阱,是一本绝佳的C语言练习册。
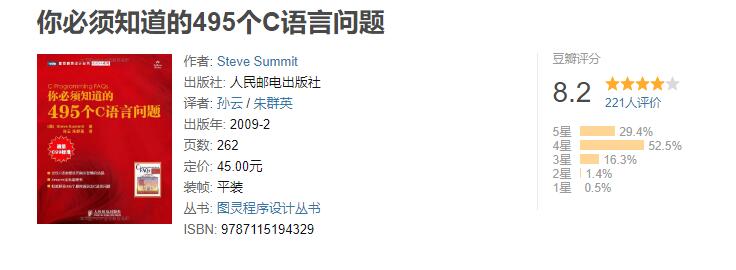
5.《你必须知道的495个C语言问题》
但比教材经典,最好手边一本教材,一边翻,一边看本书。建议集中时间看,然后再重新复习!很实用的书,比c语言陷阱,c语言解惑要深刻!!!广度还行,深度不足,适合查缺补漏。
6.《C语言参考手册(原书第5版)》

这是C99确定发布后出版的参考手册。相比K&R要更加接近现在。K&R适合入门,而这本书不读,恐怕不算”学过C语言“。
7.《C语言接口与实现》

另外,就我个人感觉而言,这本书的语言属于那种简单准确的风格,与原文的语义一致性很高,基本上没有因炫耀文字而牺牲准确性之处。新手当做兴趣书看或者老手老复习下也可以。可以加深对ADT的理解。
8.《深入理解计算机系统》(修订版或第3版)
这本书是引导你如何练内功的,但是要是我来说的话,我个人认为这本书是在你学完数据结构和导论之间去看,因为这本书只是让你去深入理解计算机导论里面的一些概念,算是高配版本的计算机导论,目的是为了引出来操作系统、组成原理这些专业核心的课程。你要是指望看完这本书你就能左手写个App右手写个Web动态网站的话就错了,这本书的意义正在于他的这个英文版的名字,Computer System — A Programmer’s Perspective,一个程序员的修养,如何利用计算机的工作流程去优化自己写的东西这个才是这本书的目的。
10.《C语言的科学和艺术》

本书的作者因为对本科生的教育做出了杰出的贡献而获得了Bing Award奖,而这本书也正体现了他作为一名教师,深入浅出的教学方法和易于理解又引人入胜的行文风格。
文中所用的例子也都非常符合本节所要讲述的内容,并且把不得以而用到的以后章节的知识以一种genlib库的形式封装了起来,隐藏了C的复杂性,从而避免了初学者的困惑。这样,在读完本书后,会发现,我们不仅仅学到了C的知识,而且把库的编写方法、习惯都潜移默化的留在了心中。在书中很多地方都会有作者关于软件工程和优秀程序设计风格的见解,如接口的编写等等,都对我们打下扎实基础起到了积极的作用。
特别需要指出的一点是:这本书对于C语言中比较困难的部分:如指针、C风格字符串、数组和指针的关系、数组和字符串的关系,都有“一针见血”式的透彻分析,使初学者能够容易的明白其中的知识,也使有经验的读者能够抓住重点理解更加深入。对于这些比较精髓的知识,特别是指针和数组名的区别,会在文中多次被提醒:分配内存、左值!
初学者在编程中,很少接触文件的操作,但是文件操作非常重要,无论初学者还是有一定经验的读者都应该对C标准库中的文件函数熟练的掌握,这本书对文件的介绍会让你有系统理解,而且对使用这些函数时常会犯的错误有先知一般的预见,从而避免了初学者遇到问题调试时的辛苦周折。
如果非要说说这本书的缺点,我想就是,没有把genlib库的代码刻成cd附在书里,这多少会给初学者上机调试造成了不便,好在网上有这本书中的源代码和其他资源,而且书后也有完整的代码。其实换种思路想,这也可以算是一件好事,国内学生的动手能力差,那就应该在敲代码的同时把她理解了吧,呵呵,有点自虐倾向-_-b
最后,无论如何,如果你想学习C语言,那么看看这本书吧,她很好的!(而且不必在乎什么“C语言已死”这样的胡说八道)作为一种应用最广的面向过程的语言,她会让你对计算机程序设计形成一种必要的经典的思考模式!
11.《数据结构与算法分析C语言系列》
因为最近需要复习数据结构与算法,所以网上搜索了下这方面的经典书籍。这本书的C语言版本高居榜首,获得一致好评,正好该书又有Java语言的版本,就买来拜读一下。前后大概花了1个月的时间将该书看了两遍,书中的主要数据结构都敲代码实现了一遍,现在算是将以前的数据结构课程都回忆了起来,对比当时上学用的谭浩强的那本数据结构教程,真是天壤之别。有时间的话可以在这本书的基础上看一下<<算法导论>>。
这本书确实是很好的数据结构与算法分析的最佳入门教程,不过看这本书还是要有点数据结构的基础。通过Java语言描述,讨论了主要的数据结构:表、栈、队列、树、散列、优先队列、不相交集合和图;同时讨论了经典的排序算法:插入排序、希尔排序、堆排序、归并排序、快速排序;介绍了5种常用算法:贪婪算法、分治算法、动态规划、随机化算法、回溯算法;并讨论了Java Collection中相关数据结构的实现:ArrayList、LinkedList、TreeSet、TreeMap、HashSet、HashMap、PriorityQueue。
12.《Linux程序设计》

《Linux程序设计》是我的Linux编程入门书籍,也是做为教材使用了一整个学期,在阅读和学习这本书的时候产生了很多的疑问,书里也没有对应的解答,直到……直到我看了APUE,带着这些问题去学习APUE,产生了巨大的能量。总之,推荐这本书,但是这本书也只是入门书籍,站在《Linux程序设计》的肩膀上,学习APUE,在Linux的世界里遨游吧!
13.《现代编译原理》

翻了这么多本书,这是我看过的唯一一本讲具体怎么构建一个编译器的书。同时这本书所构建的编译器就像作者说的那样,简单但是并不平庸,拥有很多挺先进的特性。也能算是一个优化编译器。
但是要跟着这本书做下来还是有一定难度的,需要扎实的C语言功底。
14.《重构-改善既有代码的设计》

大师Martin Fowler的经验之谈,看后有种醍醐灌顶、欲罢不能的感觉。重构也是当今敏捷开发一项不可或缺的技艺,建议所有有设计和项目开发经验的开发者都应读一下。
15.《老码识途-从机器码到框架的系统观逆向修炼之路》
我们《软件开发环境》老师写的书,先教你通过反汇编来分析、修改、自己写底层机器码,后面着重探讨面向对象特性在底层的实现和体现。
知识点都是底层的干货,对理解高层封装出来的一些概念的本质灰常有帮助。比如指针本质上就是个4字节的地址,指针类型只是由编译器识别,然后体现在控制访问多少个字节的CPU指令上;
比如函数是怎么实现调用、传参、返回的,传参又有寄存器传值、压栈传值、压栈传地址等方式,跨语言调用函数时调用惯例的协调。
总之弄懂了这些底层的机制,对高层语言的理解会透彻很多。
不过最好有一点汇编基础再读,否则略艰涩。
另一个特点是全书一直贯彻一种”猜测——实证”的思想,跟作者交流过这本书好几次,感觉这种思想是他最想传达的东西。
16.《C语言进阶》

这本书应该适用于学过C,但是想温习一下的人。里面有一部分基础语法,但是也有很多高级的东西。函数指针与指针函数,指针数组与数组指针,预定义,预编译,调试之类。但是感觉最后一章的常用算法有种多余的感觉。如果想应付面试,看这本书应该也没有错,里面有很多笔试喜欢考的sizeof的东西。
17.《实用C语言编程》

很老的一本C语言书,可以说是我的C语言启蒙书,里面的资料,尤其是附录是我现在还经常翻阅的原因,书写的很朴实,也如书名,确实实用,易懂.把这本书吃透了,找个工作,那是再容易不过了,所以说一本好书需要时间来检验它,在岁月中沉淀下来…岁月检验过的好书,不解释。
总结:天下没有不劳而获的果实,望各位年轻的朋友,想学技术的朋友,在决心扎入技术道路的路上披荆斩棘,把书弄懂了,再去敲代码,把原理弄懂了,再去实践,将会带给你的人生,你的工作,你的未来一个美梦。
所有资源百度网盘链接:https://pan.baidu.com/s/1C0RDhilrwlmEIZ811oAZoA
提取码:s9si
复制这段内容后打开百度网盘手机App,操作更方便哦
备注:里面已经顺便整理压缩好,需要下载后才可以打开,网盘直接打开会显示损坏。
!!! 好像, 里面资料的 是加密的, 需要付费后才能解密的!!