Ignite的集群部署
Ignite具有非常先进的集群能力,本文针对和集群有关的技术点做一个简短的介绍,然后针对实际应用的可能部署形式做了说明和对比,从中我们可以发现,Ignite平台在部署的灵活性上,具有很大的优势。
Ignite的设计表明整个系统本身就具有固有的可用性和可扩展性。ignite节点间通信允许所有节点接收更新,无需一个快速的主协调器。节点可以不受干扰地添加或删除,以增加可用RAM的数量。
Ignite数据结构具有完全的弹性,允许对单个服务器或多个服务器进行无干扰的自动检测和恢复。
客户端和服务端
Apache Ignite具有一个可选的服务概念,并提供了两种类型的节点:客户端和服务器节点。
- Server 包含数据、缓存、计算和流,并且可以是内存中的Map-Reduce任务的一部分。
- Client 提供远程连接服务器以将元素放入/获取到缓存的能力。它还可以存储部分数据(近缓存),这是一个较小的本地缓存,存储最近和最频繁访问的数据。
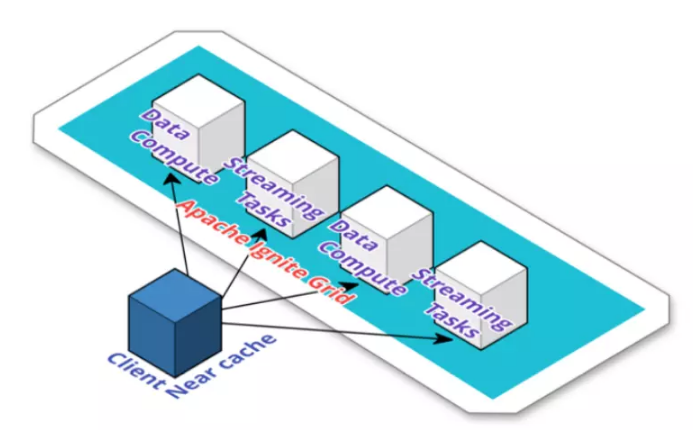
还可以将服务器节点分组到一个集群中执行工作。在集群中,可以限制作业执行、服务部署、流和其他任务只在集群组中运行。
你可以基于任何谓词创建一个集群组。例如,您可以从一组节点创建一个集群组,其中所有节点负责为testCache缓存数据。默认情况下,所有节点都作为服务节点启动。客户端模式需要显式启用。注意,您不能物理地将数据节点与计算节点分离。在Apache Ignite中,包含数据的服务器也用于执行计算。Apache Ignite客户机节点也参与作业执行。乍一看,这个概念似乎很复杂,但让我们试着澄清这个概念。服务器节点总是存储数据,默认情况下可以参与任何计算任务。另一方面,客户端节点可以操作服务器缓存、存储本地数据并参与计算任务。通常,客户端节点用于从缓存中放置或检索数据。这种混合客户端节点在开发具有多个节点的大型Ignite网格时提供了灵活性。客户端和服务器节点都位于一个网格中,在某些情况下(例如,数据节点中的大容量acid事务),您不希望在数据节点上执行任何计算。在这种情况下,您可以通过创建相应的集群组来选择只在客户端节点上执行作业。通过这种方式,您可以在一个网格中将数据节点与计算节点分开。可以使用以下伪代码对客户端进行计算:
ClusterGroup clientGroup = ignite.cluster().forClients(); IgniteCompute clientCompute = ignite.compute(clientGroup);
// Execute computation on the client nodes. clientCompute.broadcast(() -> System.out.println("sum of: " + (2+2)));
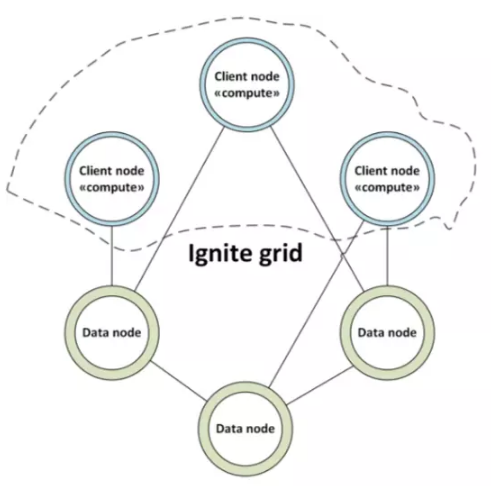
这种方法有一个缺点。使用这种方法,数据将被分配给独立的节点,并且为了计算这些数据,所有的客户端节点都需要从服务器节点检索数据。它可以产生大量的网络连接并产生延迟。但是,您可以在一个主机上单独的JVM上运行客户机和服务器节点,以减少网络延迟。从部署的角度来看,Apache Ignite服务器可以分为以下几个组:
- 内置应用程序
- 服务器在单独的JVM
1.相关概念
1.1.节点平等
Ignite没有master节点或者server节点,也没有worker节点或者client节点,按照Ignite的观点所有节点都是平等的。但是开发者可以将节点配置成master,worker或者client以及data节点。
1.2.发现机制
Ignite节点之间会自动感知,集群可扩展性强,不需要重启集群,简单地启动新加入的节点然后他们就会自动地加入集群。这是通过一个发现机制实现的,他使节点可以彼此发现对方,Ignite默认使用TcpDiscoverySpi通过TCP/IP协议来作为节点发现的实现,也可以配置成基于多播的或者基于静态IP的,这些方式适用于不同的场景。
1.3.部署模式
Ignite可以独立运行,也可以在集群内运行,也可以将几个jar包嵌入应用内部以嵌入式的模式运行,也可以运行在Docker容器以及Mesos和Yarn等环境中,可以在物理机中运行,也可以在虚拟机中运行,这个广泛的适应性是他的一个很大的优势。
1.4.配置方式
Ignite的大部分配置选项,都同时支持通过基于Spring的XML配置方式以及通过Java代码的编程方式进行配置,这个也是个重要的优点。
1.5.客户端和服务端
Ignite中各个节点是平等的,但是可以根据需要将节点配置成客户端或者服务端,服务端节点参与缓存,计算,流式处理等等,而原生的客户端节点提供了远程连接服务端的能力。Ignite原生客户端可以使用完整的Ignite API,包括近缓存,事务,计算,流,服务等等。 所有的Ignite节点默认都是以服务端模式启动的,客户端模式需要显式地启用,如下:
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="clientMode" value="true"/>
</bean>
2.创建集群
一个Ignite节点可以从命令行启动,可以用默认的配置也可以传递一个配置文件。可以启动很多的节点然后他们会自动地发现对方。 要启动一个基于默认配置的网格节点,打开命令行然后切换到IGNITE_HOME(安装文件夹),然后输入如下命令:
$ bin/ignite.sh
然后会看到大体如下的输出:
1.[02:49:12] Ignite node started OK (id=ab5d18a6)
2.[02:49:12] Topology snapshot [ver=1, nodes=1, CPUs=8, heap=1.0GB]
在嵌入式模式中,通过如下的代码同样可以启动一个节点:
Ignite ignite = Ignition.start();
3.集群组
从设计上讲,所有集群节点都是平等的,所以没有必要以一个特定的顺序启动任何节点,或者给他们赋予特定的规则。然而,Ignite可以因为一些应用的特殊需求而创建集群节点的逻辑组,比如,可能希望只在远程节点上部署一个服务,或者给部分worker节点赋予一个叫做worker的规则来做作业的执行。比如,下面这个例子只把作业广播到远程节点(除了本地节点):
final Ignite ignite = Ignition.ignite();
IgniteCluster cluster = ignite.cluster();
IgniteCompute compute = ignite.compute(cluster.forRemotes());
compute.broadcast(() -> System.out.println("节点Id: " + ignite.cluster().localNode().id()));
Ignite内置了很多预定义的集群组,同时还支持集群组的自定义。可以基于一些谓词定义动态集群组,这个集群组只会包含符合该谓词的节点。下面这个例子,一个集群组只会包括CPU利用率小于50%的节点,注意这个组里面的节点会随着CPU负载的变化而改变:
IgniteCluster cluster = ignite.cluster();
ClusterGroup readyNodes = cluster.forPredicate((node) -> node.metrics().getCurrentCpuLoad() < 0.5);
4.集群配置
Ignite中,通过DiscoverySpi节点可以彼此发现对方,可以配置成基于多播的或者基于静态IP的。Ignite提供了TcpDiscoverySpi作为DiscoverySpi的默认实现,它使用TCP/IP来作为节点发现的实现。 对于多播被禁用的情况,TcpDiscoveryVmIpFinder会使用预配置的IP地址列表,只需要提供至少一个远程节点的IP地址即可,但是为了保证冗余一个比较好的做法是提供2-3个网格节点的IP地址。如果建立了与任何一个已提供的IP地址的连接,Ignite就会自动地发现其他的所有节点。 也可以同时使用基于多播和静态IP的发现,这种情况下,除了通过多播接受地址以外,TcpDiscoveryMulticastIpFinder也可以使用预配置的静态IP地址列表。 下面的例子,显示的是如何通过预定义的IP地址列表建立集群:
TcpDiscoverySpi spi = new TcpDiscoverySpi();
TcpDiscoveryVmIpFinder ipFinder = new TcpDiscoveryVmIpFinder();
// 设置预定义IP地址,注意端口或者端口范围是可选的。
ipFinder.setAddresses(Arrays.asList("1.2.3.4", "1.2.3.5:47500..47509"));
spi.setIpFinder(ipFinder);
IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setDiscoverySpi(spi);
// 启动集群
Ignition.start(cfg);
5.零部署
和计算等有关的代码可能是任意自定义的类,在Ignite中, 远程节点会自动感知这些类,不需要显式地将任何jar文件部署或者移动到任何远程节点上。这个行为是通过对等类加载(P2P类加载)实现的,他是Ignite中的一个特别的分布式类加载器,实现了节点间的字节码交换。当对等类加载启用时,不需要在集群内的每个节点上手工地部署代码,也不需要每次在发生变化时重新部署。 可以通过如下方法启用对等类加载;
<bean class="org.apache.ignite.configuration.IgniteConfiguration">
<property name="peerClassLoadingEnabled" value="true"/>
</bean>
6.云部署
对于很多的云环境,通常有多播被禁用以及IP地址不固定的限制,对于这种情况,Ignite提供了发现的扩展机制解决了该问题,并且内置了对于常见的云服务(比如AWS)的支持,本文不赘述,开发者可以参照相关的文档。
7.Docker等其他环境的部署
对于Docker、Mesos、Yarn等环境,Ignite同样支持,本文不赘述,开发者可以参照相关的文档。
8.部署实践
Ignite的部署模式非常的灵活,在实际的场景中可以针对实际需要采用不同的部署方式,下面做简单的总结和对比:
8.1.独立式Ignite集群
这种情况下,集群的部署完全独立于应用,这个集群可以用于分布式计算,分布式缓存,分布式服务等,这时应用以客户端模式接入集群进行相关的操作,大体是如下的部署模式:
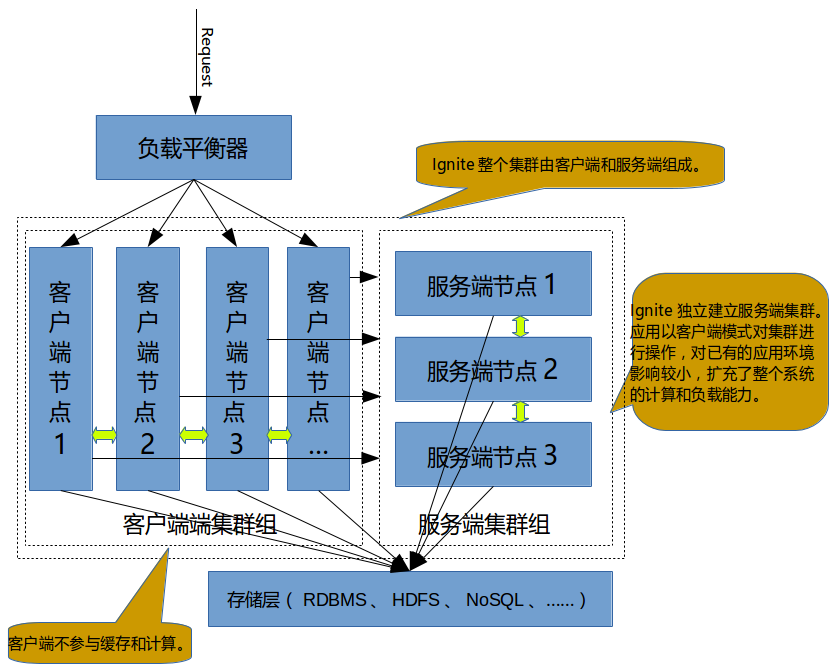
优点 对已有的应用运行环境影响小,并且这个集群可以共享,为多个应用提供服务,对整个应用来说,额外增加了很多的计算和负载能力。 缺点 需要单独的一组机器,相对成本要高些,如果缓存操作并发不高或者计算不饱和,存在资源利用率低的情况。整体架构也变得复杂,维护成本也要高些。
8.2.嵌入式Ignite集群
这种情况下,可以将必要的jar包嵌入已有应用的内部,利用Ignite的发现机制,自动建立集群,大体是如下的部署模式:
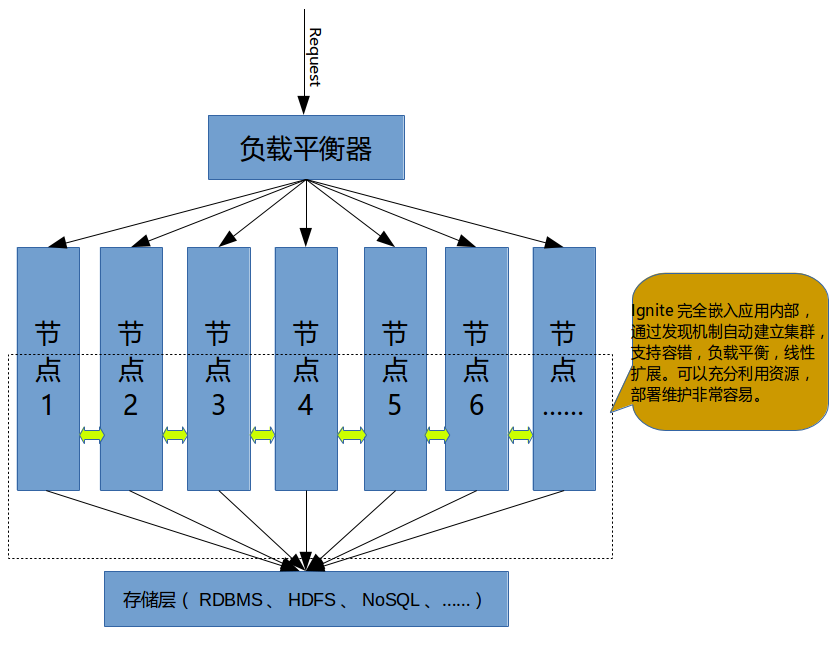
优点 无需额外增加机器,成本最低,Ignite可以和应用无缝集成,所有节点都为服务端节点,可以充分利用Ignite的丰富功能。这个模式可扩展性最好,简单增加节点即可快速扩充整个系统的计算和负载能力。 缺点 Ignite占用了服务器的部分资源,对应用整体性能有影响,可能需要进行有针对性的优化,应用更新时,集群可能需要重启,这时如果Ignite需要加载大量的数据,重启的时间可能变长,甚至无法忍受。
8.3.混合式Ignite集群
这种情况下,将上述2种模式混合在一起,即同时增加机器部署独立集群,同时又将Ignite嵌入应用内部以服务端模式运行,通过逻辑集群组进行资源的分配,整体上形成更大的集群,大体是如下的部署模式:
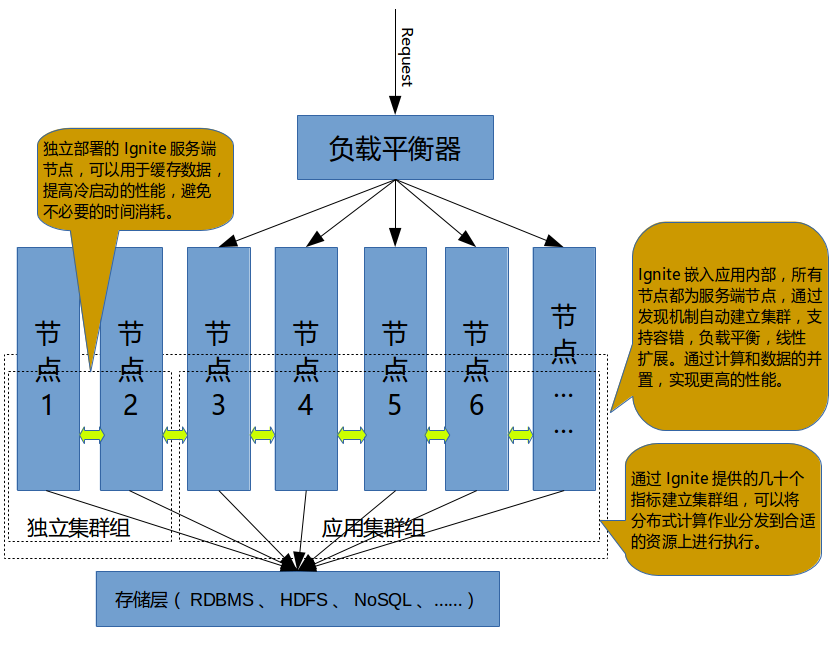
这种模式更为灵活,调优后能做到成本、功能、性能的平衡,综合效果最佳。这时可以将缓存的数据通过集群组部署到应用外部的节点上,这样可以避免频繁的冷启动导致缓存数据频繁的长时间加载,对于计算,也能够动态地充分利用所有计算节点的资源。



