这两天看了一下Flume的开发文档,并且体验了下Flume的使用。
本文就从如下的几个方面讲述下我的使用心得:
- 初体验——与Logstash的对比
- 安装部署
- 启动教程
- 参数与实例分析
Flume初体验
Flume的配置是真繁琐,source,channel,sink的关系在配置文件里面交织在一起,没有Logstash那么简单明了。
Flume与Logstash相比,我个人的体会如下:
- Logstash比较偏重于字段的预处理;而Flume偏重数据的传输;
- Logstash有几十个插件,配置灵活;FLume则是强调用户的自定义开发(source和sink的种类也有一二十个吧,channel就比较少了)。
- Logstash的input和filter还有output之间都存在buffer,进行缓冲;Flume直接使用channel做持久化(可以理解为没有filter)
Logstash浅谈:
Logstash中:
- input负责数据的输入(产生或者说是搜集,以及解码decode);
- Filter负责对采集的日志进行分析,提取字段(一般都是提取关键的字段,存储到elasticsearch中进行检索分析);
- output负责把数据输出到指定的存储位置(如果是采集agent,则一般是发送到消息队列中,如kafka,redis,mq;如果是分析汇总端,则一般是发送到elasticsearch中)
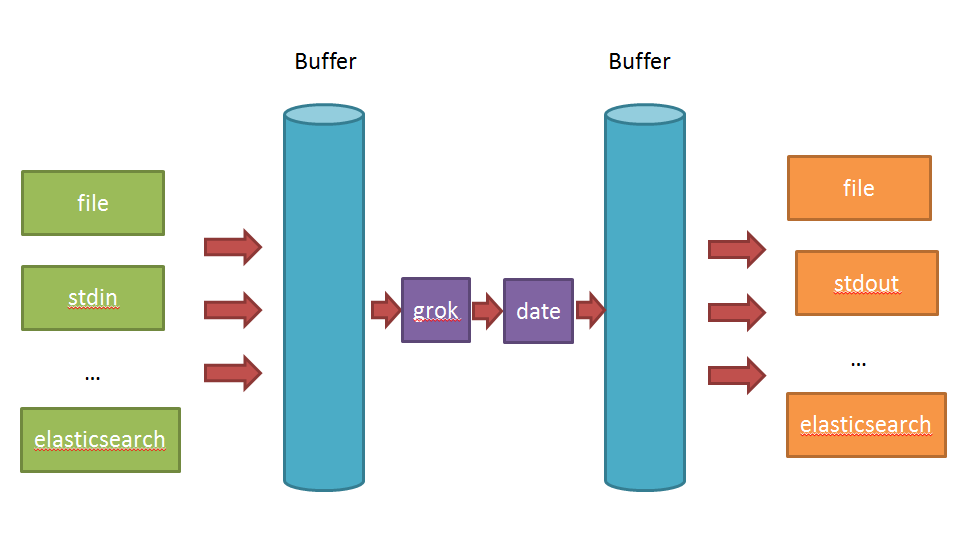
在Logstash比较看重input,filter,output之间的协同工作,因此多个输入会把数据汇总到input和filter之间的buffer中。filter则会从buffer中读取数据,进行过滤解析,然后存储在filter于output之间的Buffer中。当buffer满足一定的条件时,会触发output的刷新。
Flume浅谈:
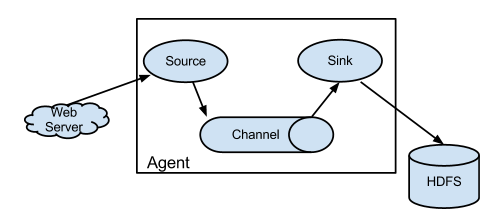
在Flume中:
- source 负责与Input同样的角色,负责数据的产生或搜集(一般是对接一些RPC的程序或者是其他的flume节点的sink)
- channel 负责数据的存储持久化(一般都是memory或者file两种)
- sink 负责数据的转发(用于转发给下一个flume的source或者最终的存储点——如HDFS)
Flume比较看重数据的传输,因此几乎没有数据的解析预处理。仅仅是数据的产生,封装成event然后传输。传输的时候flume比logstash多考虑了一些可靠性。因为数据会持久化在channel中(一般有两种可以选择,memoryChannel就是存在内存中,另一个就是FileChannel存储在文件种),数据只有存储在下一个存储位置(可能是最终的存储位置,如HDFS;也可能是下一个Flume节点的channel),数据才会从当前的channel中删除。这个过程是通过事务来控制的,这样就保证了数据的可靠性。
不过flume的持久化也是有容量限制的,比如内存如果超过一定的量,也一样会爆掉。
安装
在官网下载最新版本http://flume.apache.org/download.html,目前最新的版本是1.6.0
默认flume是不支持windows的,没有bat的启动命令。不过有一个flume-ng.cmd,其实它也不是启动文件,只是启动了一个powershell而已,如果你本地有这个软件,就可以在windows下运行了。
powershell.exe -NoProfile -InputFormat none -ExecutionPolicy unrestricted -File %~dp0flume-ng.ps1 %*目录介绍
bin
存放了启动脚本
lib
启动所需的所有组件jar包
conf
提供了几个测试配置文件
docs
文档
tools
跟日志输出有关的一个jar包(不知道有什么不同)
先来看看配置文件
# 关于license的一大堆 blabla
# 配置sources,channels,sinks的名称
agent.sources = seqGenSrc
agent.channels = memoryChannel
agent.sinks = loggerSink
# 配置sources是哪一种类型,注意可以由多个source哦!
# seq 是专门给测试用的,会自动产生一大堆数据。
# (其实我觉得stdin最好,不过flume没这个source)
agent.sources.seqGenSrc.type = seq
# 配置source输出的channel为memoryChannel(名称,你也可以叫c1)
agent.sources.seqGenSrc.channels = memoryChannel
# 配置sink是哪一种类型,本例子为logger,即log4j输出。
# (log4j会参考conf下的log4j.properties文件,一般开启consoleAppender做测试就行)
agent.sinks.loggerSink.type = logger
# 配置sink取数据的channel为memoryChannel,注意跟上面的名字保持一致哦!
agent.sinks.loggerSink.channel = memoryChannel
# 配置channel的类型
agent.channels.memoryChannel.type = memory
# 配置channel的容量
agent.channels.memoryChannel.capacity = 100然后在flume目录下,输入下面的命令:
bin/flume-ng agent --conf-file conf/flume-conf.properties.template --name agent -Dflume.root.logger=INFO,console -C .然后就可以看到满屏滚动的信息了!
注意:上面启动命令没一个字母是废话!
启动参数详解
你可以输入flume-ng help 获得帮助提示:
[root@10 /xinghl/flume]$ bin/flume-ng hekp
Usage: bin/flume-ng <command> [options]...
commands:
help display this help text
agent run a Flume agent
avro-client run an avro Flume client
version show Flume version info
global options:
--conf,-c <conf> use configs in <conf> directory
--classpath,-C <cp> append to the classpath
--dryrun,-d do not actually start Flume, just print the command
--plugins-path <dirs> colon-separated list of plugins.d directories. See the
plugins.d section in the user guide for more details.
Default: $FLUME_HOME/plugins.d
-Dproperty=value sets a Java system property value
-Xproperty=value sets a Java -X option
agent options:
--name,-n <name> the name of this agent (required)
--conf-file,-f <file> specify a config file (required if -z missing)
--zkConnString,-z <str> specify the ZooKeeper connection to use (required if -f missing)
--zkBasePath,-p <path> specify the base path in ZooKeeper for agent configs
--no-reload-conf do not reload config file if changed
--help,-h display help text
avro-client options:
--rpcProps,-P <file> RPC client properties file with server connection params
--host,-H <host> hostname to which events will be sent
--port,-p <port> port of the avro source
--dirname <dir> directory to stream to avro source
--filename,-F <file> text file to stream to avro source (default: std input)
--headerFile,-R <file> File containing event headers as key/value pairs on each new line
--help,-h display help text
Either --rpcProps or both --host and --port must be specified.这里就挑重要的参数将了:
commands 命令参数
这个是很重要的参数,因为flume可以使用不同的角色启动,比如agent以及client等等。暂时搞不清楚avro-client有什么特殊的,先了解一下吧!平时启动就使用agent就可以了。
global options 全局参数
--conf 或者 -c ,指定去conf目录下加载配置文件
--classpath 或者 -C,指定类加载的路径(不知道为什么我下载flume版本启动的时候找不到log4j配置,只能加上 -C .才能启动!)
command 指定
-Dproperty=value 这个参数比较重要,比如logger就需要它来指定传输的级别等信息。如果没有这个参数,logger就不好使了。
agent options agent启动选项
其中最终要的就是 --name 或者 -n ,它指定了启动agent的名称,注意是启动agent的名称。
这个名称必须与配置文件中的一样
这个名称必须与配置文件中的一样
这个名称必须与配置文件中的一样
重要的事情重复三遍!
如果写错了!一段小异常就跑来了~(比如我配置文件中为agent,启动命令中写agent123)
2016-06-30 17:04:19,529 (conf-file-poller-0) [WARN - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:133)] No configuration found for this host:agent123另外,就是通过--conf-file 或者 -f 指定配置文件。如果配置文件放在conf,也等同于--conf。
参数就介绍到这里了。
来源:http://www.cnblogs.com/xing901022/p/5631445.html
下面是, 另一的一个对比, 很好, 值得一看
本文适合有一定大数据基础的读者朋友们阅读,但如果你没有技术基础,照样可以继续看(这就好比你看《葵花宝典》第一页:欲练此功,必先自宫,然后翻到第二页:若不自宫,也可练功,没错就是这种感觉→_→)。
大数据的数据采集工作是大数据技术中非常重要、基础的部分,数据不会平白无故地跑到你的数据平台软件中,你得用什么东西把它从现有的设备(比如服务器,路由器、交换机、防火墙、数据库等)采集过来,再传输到你的平台中,然后才会有后面更加复杂高难度的处理技术。
目前,Flume和Logstash是比较主流的数据采集工具(主要用于日志采集),但是很多人还不太明白两者的区别,特别是对用户来说,具体场景使用合适的采集工具,可以大大提高效率和可靠性,并降低资源成本。
嗑瓜子群众:喂喂,上面全都是没用的废话,说好的故事呢=。=
咳咳,好吧,现在我们开始讲正事。首先我们给出一个通用的数据采集模型,主要是让不太懂计算机或者通信的读者们了解一下。

其中,数据采集和存储是必要的环节,其他并不一定需要。是不是很简单?本来编程其实就是模块化的东西,没有那么难。但是这毕竟只是一个粗略的通用模型,不同开源社区或者商业厂家开发的时候都会有自己的考虑和目的。我们在本文要讨论的Flume和Logstash原则上都属于数据采集这个范畴,尽管两者在技术上或多或少都自带了一些缓冲、过滤等等功能。
好,我们先来看Logstash,然后看Flume,等你全部看完你就知道我为什么这么安排了。
Logstash是ELK组件中的一个。所谓ELK就是指,ElasticSearch、Logstash、Kibana这三个组件。那么为什么这三个组件要合在一起说呢?第一,这三个组件往往是配合使用的(ES负责数据的存储和索引,Logstash负责数据采集和过滤转换,Kibana则负责图形界面处理);第二,这三个组件又先后被收购于Elastic.co公司名下。是不是很巧合?这里说个题外话,原ELK Stack在5.0版本加入Beats(一种代理)套件后改称为Elastic Stack,这两个词是一个意思,只不过因为增加了Beats代理工具,改了个名字。
Logstash诞生于2009年8有2日,其作者是世界著名的虚拟主机托管商DreamHost的运维工程师乔丹 西塞(Jordan Sissel)。Logstash的开发很早,对比一下,Scribed诞生于2008年,Flume诞生于2010年,Graylog2诞生于2010年,Fluentd诞生于2011年。2013年,Logstash被ElasticSearch公司收购。这里顺便提一句,Logstash是乔丹的作品,所以带着独特的个人性格,这一点不像Facebook的Scribe,Apache的Flume开源基金项目。
你说的没错,以上都是废话。(手动滑稽→_→)
Logstash的设计非常规范,有三个组件,其分工如下:
1、Shipper 负责日志收集。职责是监控本地日志文件的变化,并输出到 Redis 缓存起来;2、Broker 可以看作是日志集线器,可以连接多个 Shipper 和多个 Indexer;3、Indexer 负责日志存储。在这个架构中会从 Redis 接收日志,写入到本地文件。
这里要说明,因为架构比较灵活,如果不想用 Logstash 的存储,也可以对接到 Elasticsearch,这也就是前面所说的 ELK 的套路了。

如果继续细分,Logstash也可以这么解剖来看

貌似到这里。。。好像就讲完了。。。读者朋友们不要骂我,因为Logstash就是这么简约,全部将代码集成,程序员不需要关心里面是如何运转的。
Logstash最值得一提的是,在Filter plugin部分具有比较完备的功能,比如grok,能通过正则解析和结构化任何文本,Grok 目前是Logstash最好的方式对非结构化日志数据解析成结构化和可查询化。此外,Logstash还可以重命名、删除、替换和修改事件字段,当然也包括完全丢弃事件,如debug事件。还有很多的复杂功能供程序员自己选择,你会发现这些功能Flume是绝对没有(以它的轻量级线程也是不可能做到的)。当然,在input和output两个插件部分也具有非常多类似的可选择性功能,程序员可以自由选择,这一点跟Flume是比较相似的。
大大的分割线,读者朋友们可以去上个厕所,然后再买一包瓜子了。
Logstash因为集成化设计,所以理解起来其实不难。现在我们讲讲Flume,这块内容就有点多了。
最早Flume是由Cloudrea开发的日志收集系统,初始的发行版本叫做Flume OG(就是original generation的意思),作为开源工具,一经公布,其实是很受关注的一套工具,但是后面随着功能的拓展,暴露出代码工程臃肿、核心组件设计不合理、核心配置不标准等各种缺点。尤其是在Flume OG的最后一个发行版本0.94.0中,日志传输不稳定的现象特别严重。我们来看看Flume OG到底有什么问题。

直到现在,你在网络上搜索Flume相关资料的时候还会经常出现Flume OG的结构图,这对新人来说是很不友好的,很容易引起误导,请读者朋友们一定要注意!我们可以看到Flume OG有三种角色的节点:代理节点(agent)、收集节点(collector)、主节点(master)。
流程理解起来也并不困难:agent 从各个数据源收集日志数据,将收集到的数据集中到 collector,然后由收集节点汇总存入 hdfs。master 负责管理 agent,collector 的活动。agent、collector 都称为 node,node 的角色根据配置的不同分为 logical node(逻辑节点)、physical node(物理节点)。对logical nodes和physical nodes的区分、配置、使用一直以来都是使用者最头疼的地方。

agent、collector 由 source、sink 组成,代表在当前节点数据是从 source 传送到 sink。
就算是外行人,看到这里也觉得很头大,这尼玛是谁设计出来的破玩意?
各种问题的暴露,迫使开发者痛下决心,抛弃原有的设计理念,彻底重写Flume。于是在2011 年 10 月 22 号,Cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation下一代的意思);改动的另一原因是将 Flume 纳入 apache 旗下,Cloudera Flume 改名为 Apache Flume,所以现在Flume已经是Apache ETL工具集中的一员。
这里说个题外话,大家都知道,通常情况下大公司,特别是大型IT公司是比较排斥使用一些不稳定的新技术的,也不喜欢频繁变换技术,这很简单,因为变化很容易导致意外。举个例子,Linux发展了二十多年了,大部分公司都在使用RedHat、CentOS和Ubuntu这类旨在提供稳定、兼容好的版本,如果你看到一家公司用的是Linux新内核,那多半是一家新公司,需要用一些新技术在竞争中处于上风。
好,了解了一些历史背景,现在我们可以放上Flume NG的结构图了

卧槽,是不是很简单?!对比一下OG的结构,外行人都会惊叹:so easy!
这次开发者吸取了OG的血淋林教训,将最核心的几块部分做了改动:
1、NG 只有一种角色的节点:代理节点(agent),而不是像OG那么多角色;
2、没有collector,master节点。这是核心组件最核心的变化;
3、去除了physical nodes、logical nodes的概念和相关内容;
4、agent 节点的组成也发生了变化,NG agent由source、sink、channel组成。
那么这么做有什么好处呢?简单概括有这么三点:
1、NG 简化核心组件,移除了 OG 版本代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点,使得数据流的配置变得更简单合理,这是比较直观的一个改进点;
2、NG 脱离了 Flume 稳定性对 zookeeper 的依赖。在早期的OG版本中,Flume 的使用稳定性依赖 zookeeper。它需要 zookeeper 对其多类节点(agent、collector、master)的工作进行管理,尤其是在集群中配置多个 master 的情况下。当然,OG 也可以用内存的方式管理各类节点的配置信息,但是需要用户能够忍受在机器出现故障时配置信息出现丢失。所以说 OG 的稳定行使用是依赖 zookeeper 的。
3、NG 版本对用户要求大大降低:安装过程除了java无需配置复杂的Flume相关属性,也无需搭建zookeeper集群,安装过程几乎零工作量。
有人很不解,怎么突然冒出来一个Zookeeper这个概念,这是个啥玩意?简单的说,Zookeeper 是针对大型分布式系统的可靠协调系统,适用于有多类角色集群管理。你可以把它理解为整个Hadoop的总管家,负责整个系统所有组件之间的协调工作管理。这个组件平时很不起眼,但非常重要。好比一支篮球队,五个队员个个都是巨星,所以我们平时都习惯关注这五个人,但是整个球队的获胜缺不了教练的协调组织、战术安排,Zookeeper就好比是整个Hadoop系统的教练。比喻虽然有些生硬,只是想说明Zookeeper的重要性,也侧面说明NG在摆脱了Zookeeper的依赖后变得更加轻便,灵活。
说个题外话,OG版本的使用文档有90多页,而NG只用 20 多页的内容就完成了新版 Flume 的使用说明。可见在科学研究领域,人类总是在追求真理,而真理总是可以用最简单的语言描述出来。
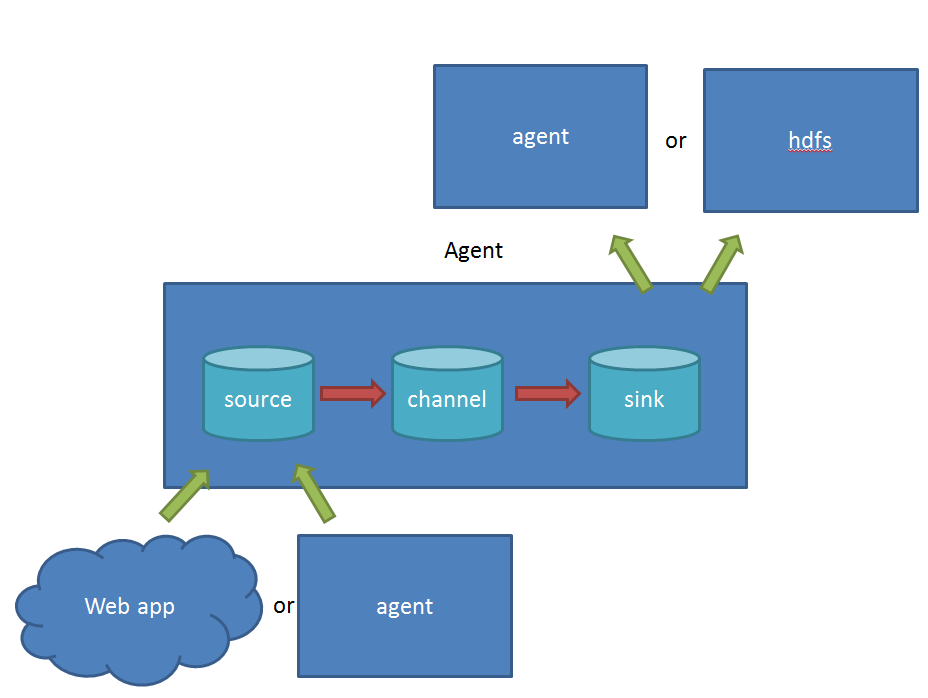
到这里差不多Flume就讲的差不多了,因为这个线程工具从原理上讲真的很简单,三段式的结构:源(Source输入)——存储(Channel管道)——出口(Sink目标输出)。但也因为涉及到这三个结构,所以做配置就比较复杂,这里举个例子,我们看看Flume在一些场景下是如何搭建布置的。

这里要纠正几个很多初学Flume朋友们的误区。首先,Flume已经可以支持一个Agent中有多个不同类型的channel和sink,我们可以选择把Source的数据复制,分发给不同的目的端口,比如:

其次,Flume还自带了分区和拦截器功能,因此不是像很多实验者认为的没有过滤功能(当然我承认Flume的过滤功能比较弱)。
读者可能会隐约感觉到,Flume在集群中最擅长的事情就是做路由了,因为每一个Flume Agent相连就构成了一条链路,这也是众多采集工具中Flume非常出色的亮点。但是也正因为如此,如果有一个Flume Agent出了问题,那么整个链路也会出现问题,所以在集群中需要设计分层架构等来实现冗余备份。但这么一来,配置又会变得很麻烦。
最后一个大大的分隔线
把Logstash和Flume都讲完了,我们最后可以对比总结一下了。
首先从结构对比,我们会惊人的发现,两者是多么的相似!Logstash的Shipper、Broker、Indexer分别和Flume的Source、Channel、Sink各自对应!只不过是Logstash集成了,Broker可以不需要,而Flume需要单独配置,且缺一不可,但这再一次说明了计算机的设计思想都是通用的!只是实现方式会不同而已。
从程序员的角度来说,上文也提到过了,Flume是真的很繁琐,你需要分别作source、channel、sink的手工配置,而且涉及到复杂的数据采集环境,你可能还要做多个配置,这在上面提过了,反过来说Logstash的配置就非常简洁清晰,三个部分的属性都定义好了,程序员自己去选择就行,就算没有,也可以自行开发插件,非常方便。当然了,Flume的插件也很多,但Channel就只有内存和文件这两种(其实现在不止了,但常用的也就两种)。读者可以看得出来,两者其实配置都是非常灵活的,只不过看场景取舍罢了。
其实从作者和历史背景来看,两者最初的设计目的就不太一样。Flume本身最初设计的目的是为了把数据传入HDFS中(并不是为了采集日志而设计,这和Logstash有根本的区别),所以理所应当侧重于数据的传输,程序员要非常清楚整个数据的路由,并且比Logstash还多了一个可靠性策略,上文中的channel就是用于持久化目的,数据除非确认传输到下一位置了,否则不会删除,这一步是通过事务来控制的,这样的设计使得可靠性非常好。相反,Logstash则明显侧重对数据的预处理,因为日志的字段需要大量的预处理,为解析做铺垫。
回过来看我当初为什么先讲Logstash然后讲Flume?这里面有几个考虑,其一:Logstash其实更有点像通用的模型,所以对新人来说理解起来更简单,而Flume这样轻量级的线程,可能有一定的计算机编程基础理解起来更好;其二:目前大部分的情况下,Logstash用的更加多,这个数据我自己没有统计过,但是根据经验判断,Logstash可以和ELK其他组件配合使用,开发、应用都会简单很多,技术成熟,使用场景广泛。相反Flume组件就需要和其他很多工具配合使用,场景的针对性会比较强,更不用提Flume的配置过于繁琐复杂了。
最后总结下来,我们可以这么理解他们的区别:Logstash就像是买来的台式机,主板、电源、硬盘,机箱(Logstash)把里面的东西全部装好了,你可以直接用,当然也可以自己组装修改;Flume就像提供给你一套完整的主板,电源、硬盘,Flume没有打包,只是像说明书一样指导你如何组装,才能运行的起来。
讲完,收工。
来源: http://www.jianshu.com/p/349ed5ee6419
来自 Mozilla 的 Heka 是一个用来收集和整理来自多个不同源的数据的工具,通过对数据进行收集和整理后发送结果报告到不同的目标用于进一步分析。
Heka
- 日志收集服务
- 流式
- Mozilla出品
- Golang编写
- 轻量却功能强大
- 灵活易用
- Go/Lua扩展
Heka用户
- Mozilla(FireFox)
- Disqus(最流行的评论服务)
Heka架构
- Inputs, 用于接收数据,有多种输入方式,如:
- 文件
- TCP
- 消息队列如AMQP
- 系统命令输出
- Splitters, 用于将Input收到的数据进行拆分,比如按换行符
- Decoders, 解析Input/Split之后的数据
- Nginx/Apache Access Log
- GeoIP
- syslog
- MultiDecoder,把多个Decoder整合起来一起用
- 还有很多等等,以及很方便的Lua扩展
- Filters, 消息处理引擎,可以进行过滤、计算、聚合
- Encoders, 在输出到Output前将数据处理成Output支持的数据格式
- 有许多常用插件,以及很方便的Lua扩展
- Outputs, 可以同时多个输出落地,如:
- ElasticSeasrch
- TCP
- AMQP
- HTTP
- 还有很多等等,以及很方便的Lua扩展
日志收集架构
1.至简
heka logstreamer Input-> Output到最终落地
2.性能扩展
heka logstreamer Input-> TCP Output -> 汇总层heka TCP Input -> Output到最终落地
3.性能扩展(使用队列)
heka logstreamer Input-> AMQP(Kafka) Output -> 汇总层heka AMQP(Kafka) Input -> Output到最终落地
性能测试
环境:4 CPU虚拟机,CentOS 6.5
syslog协议+文件输出,可达到34K/s
Heka, 一个高可扩展的实时数据收集和处理工具
Heka程序的可扩展性体现在它的插件开发上。Heka核心是Go语言开发,其插件理所当然的可以采用Go语言开发,当然你还可以通过lua来开发插件,如果你更喜欢写lua的话;lua开发的插件具备热更新的能力,也就是修改了lua插件的代码,并不需要重启Heka进程,在某些应用场景下,热更新具备很强的竞争力。根据实际的应用需求,可以为Heka开发4种类型的插件,这4种插件就构成了Heka的整体结构和功能,所以Heka的核心代码量(非插件)只有5,6K行。可开发的4种插件分别是:Input、Decoder、Filter、Output。
Input插件就是Heka的数据输入源。假设需要从一个日志文件读入数据,那就只需要开发一个从日志文件读取日志数据的Input插件即可。值得开心的事情是,Heka已经默认自带了多个Input插件,可以满足大部分数据来源的需求。自带的LogstreamerInput插件就是用来从日志文件实时读入数据用的,它支持读取各种rotate规则的日志文件路径;HttpInput插件可以间断式的通过访问一个URL地址来获取数据,比如:Web服务器的7层健康检查场景就可以使用HttpInput插件来探测。HttpListenInput插件会启动一个Http服务器接收外部访问来获取数据,比如:通过curl等命令直接将数据post到Heka;还有两个比较重要的Input插件:分别是TcpInput和UdpInput,有这两个插件外部程序就可以通过TCP/UDP将数据发送给Heka。http://hekad.readthedocs.org/en/latest/config/inputs/index.html, 这里可以看到Heka提供的全部Input插件和详细使用方法,大部分情况都不需要自己开发Input插件了。
Decoder插件,各种Input插件负责将原始数据送入到Heka内部,这些数据一般来说都是具备一定的格式,比如:Nginx access日志、Syslog协议数据、自定义的数据格式等等,Decoder插件干的事情就是将Input插件输入的一个个的原始数据消息给解析一遍,最终得到一个结构化好的消息,不再是一个非结构化的原始数据消息。结构化的消息更利于编程进行处理。http://hekad.readthedocs.org/en/latest/config/decoders/index.html,这里例举了Heka自带的所有Decoder插件,我最关注的插件是:Nginx Access Log Decoder和 Syslog Decoder,这两个插件都是Lua开发的。注意,每个Input插件得有一个Decoder插件负责对输入的数据进行解析到结构化的程度。
Filter插件干的事情就是负责具体的数据分析、计算任务。Heka默认也带了好几个Filter插件,但都不是我的菜,绝大多数时候,可能都需要我们自己根据应用需求开发自己的Filter插件来完成数据分析、计算工作。
OutPut插件负责将Heka内部的一个个消息输出到外部环境,比如:文件、数据库、消息队列等;注意,也可以通过TcpOutput将消息输出到下一个Heka继续处理,这样就可以部署成多机分布式结构,只要有必要。
通过4种类型的插件,基本可以了解到Heka是基于Pipeline方式对数据进行实时处理。除了可以开发4种插件以外,Heka还提供了一个很高端的机制——message matcher,message matcher是应用在Filter和Output两种插件身上,它主要是用来指定哪些消息由哪些插件(Filter/Output)处理。有了message matcher机制就可以通过配置文件实现不同的数据由不同的Filter进行计算、不同的Output输出到不同的外部环境。没有message_matcher,Heka的价值就会大打折扣了。
Heka’s Agent/Aggregator架构
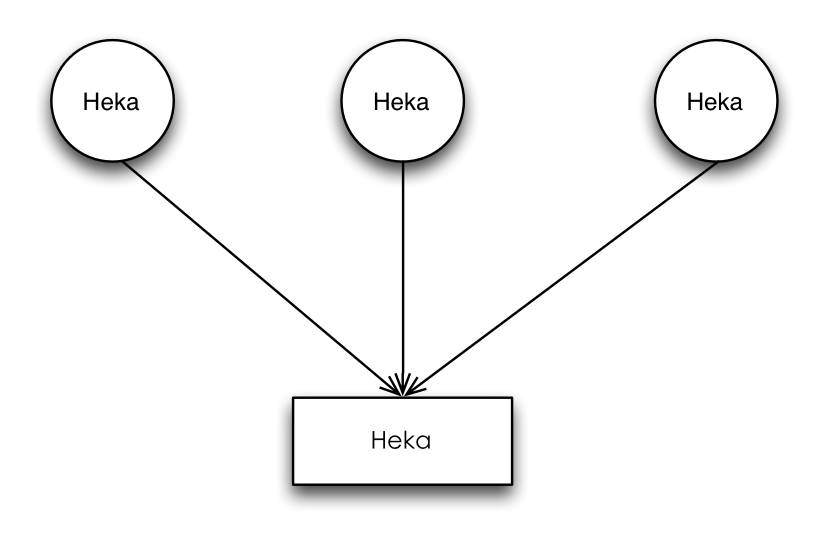
Heka可以通过配置文件部署成为不同的角色,实际上它们都是同一个二进制程序。上图中的圆形组件Heka担任的是Agent角色,而矩形组件Heka担任的是Aggregator角色。假设每个Agent部署在不同的主机上,使用LogstreamerInput插件负责监控、采集Nginx Access日志,然后将日志数据通过Nginx Access Decoder插件进行解析,最后通过特定的Filter插件做一些分析、计算工作,最终的计算结果再通过TcpOutput插件发送到扮演Aggregator角色的Heka进行聚合、汇总计算从而得到所有主机的日志计算结果。Heka具备这样的一个扩展架构,可以非常方便的将计算任务分摊到多机,从而实现类MapReduce,当然Heka仅仅只是一个轻量级的小工具,不是一个分布式计算平台。
Heka’s Agent/Router架构
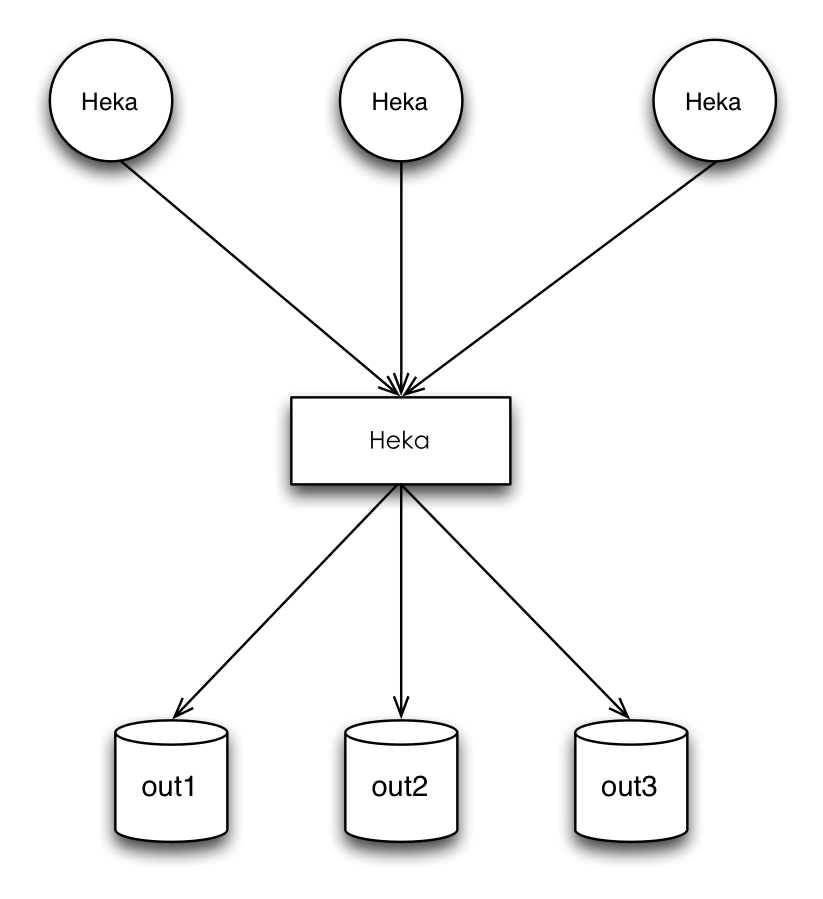
除了Agent/Aggregator架构外,还可以把Heka当做一个Router来使用,图中圆形组件Heka还是Agent,每个Agent负责采集不同的数据发送给矩形组件Heka,也就是Router。Heka Router可以通过message matcher机制将不同的数据输出到不同的外部存储等,从而实现一个Router的功能。当然,上面的两种架构也是可以混合到一起使用的,Heka的系统级扩展性还是足够灵活的。Agent/Router架构其实非常像淘宝开源的DataX工具(DataX是由淘宝 @泽远 同学领导开发的一款各种存储间数据交换的瑞士军刀。DataX也是支持各种插件开发,可以通过插件实现MySql数据同步到Oracle、Oracle同步到MySql、Mysql同步HDFS等等),在没有DataX以前,就是各种存储间同步的独立工具,由不同的人开发,使用方式也完全不一致,零散的小工具极其不友好。在一个灵活、可扩展的工具上面,进行扩展开发实现各种业务需求,可以让系统的运维更加的友好,部署、使用方式也更加的一致。
Heka能够自定义Input/Output插件,再配合message matcher机制,我认为这才是最具想象力的部分。输入输出是直接和外部交互,有了扩展外部交互的能力,我就可以将一切零散的小工具(各种脚本等)整合起来,统一维护,从而实现出一整套完整的应用逻辑;就好比Nginx一样,各种Http相关需求都可以通过开发模块来实现,最后将多个模块组合起来就构成一个完整的应用解决方案。
最后,还是轻量,足够轻量运维成本才足够低。
Heka, 一个高可扩展的实时数据收集和处理工具
本文由 IT学习网 整理,转载请注明“转自IT学习网”,并附上链接。




