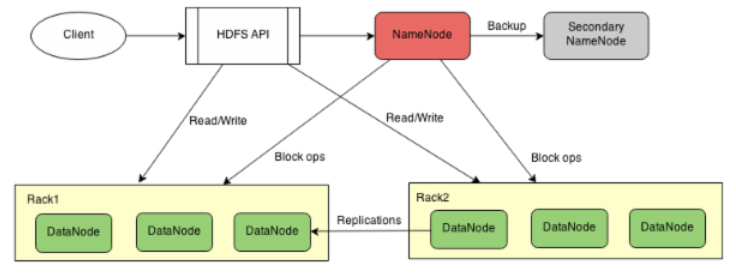
先看看没有HA的HDFS的系统架构(用 draw.io 画的,尼马这么好的网站也被墙了):
然后有HA方案的系统架构:
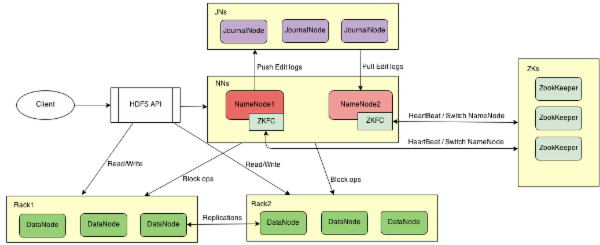
以下的实验基于4个节点的Hadoop集群。其中每个节点的运行的进程列表如下:
| Role\Host | hd1 | hd2 | hd3 | hd4 |
|---|---|---|---|---|
| NN | √ | √ | ||
| DN | √ | √ | √ | |
| JN | √ | √ | √ | |
| ZK | √ | √ | √ |
实验环境中,所有节点的运行环境基本相同:
- Ubuntu14.04 X64
- 4G内存
- OpenJDK-1.7.0
- 100Mbps以太网
下面是实现这个系统的流程(官方文档+个人注解+辅助Shell命令)。
1. 安装Hadoop系统。
严格按照 单节点搭建 和 集群搭建 两个步骤,系统建起来完全没压力。我遇到的问题是刚开始在配置文件(salves和core-site.xml等文件)中使用的是ip地址而非主机名,然后在log文件里看到各种无法连接。解决方案是修改主机名并在hosts文件里建立映射关系。
hostname {new_hostname} # 修改主机名,只有当前Session有效
sudo vi /etc/hostname # 永久修改主机名的方法
另外,对于64位的系统,最好重新编译源码。
2. 修改配置文件。
hdfs-site.xml文件:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hd1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hd3:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hd1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hd3:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hd1:8485;hd2:8485;hd4:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hduser/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/journalnode</value>
</property>
</configuration>
- 其中
nameservices是集群的命名空间,即使有多个集群,可以共用配置文件,但是要注意某些配置项的顺序。 dfs.ha.namenodes.mycluster中的mycluster是可以任取的,但是要和dfs.nameservices对应。dfs.namenode.rpc-address.mycluster.nn1参考上一条。dfs.namenode.shared.edits.dir值的格式是"qjournal://host1:port1;host2:port2;host3:port3/journalId",用来指定对应的JN节点,journalId建议使用和nameservices相同的名称。dfs.client.failover.proxy.provider.mycluster指定激活NameNode的Java类,目前Hadoop内置的只有上面那个。dfs.ha.fencing.methods是来用来隔离失效的NameNode的方法,有sshfence和Shell两种方式。sshfence需要配置dfs.ha.fencing.ssh.private-key-files私钥文件,以便交互的过程不需要输入密码。dfs.journalnode.edits.dir是JN保存数据的文件。
core-site.xml文件:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
</configuration>
- 注意
mycluster要和dhfs-site.xml中的dfs.nameservices对应。fs.defaultFS不用端口号。
3. 部署
改好配置文件好,就要将配置文件同步到所有的机器上了。可以用rsync将文件同步到多台机器上。rsync是一个增量同步工具,需要先安装。下面的rsync.sh的功能是将当前目录的所有文件发送到文件或参数对应的机器上。
$ cat rsync.sh
#! /bin/bash
dir=`pwd`
pdir=`dirname $dir`
send(){
echo "Sending to $2:$1"
rsync -avez -e ssh $1 $2:$3
}
mul_send(){
while read host
do
send $dir $host $pdir
done < $1
}
[ -f $1 ] && mul_send $1 || send $dir $1 $pdirdefool@hd5:/usr/local/hadoop/etc/hadoop
将rsync.sh放在etc/hadoop目录下,进入目录运行
chmod +x rsync.sh
./rsync.sh slaves
# or ./rsync.sh hostname
发送完文件之后,就是启动系统。步骤如下:
启动JNs.
在所有JournalNode上运行
sbin/hadoop-daemon.sh --script hdfs start journalnode
启动NameNode.
在原NameNode上运行
bin/hadoop --script hdfs start namenode # NameNode需要已经format。
(使用上面的rsync.sh文件)将原NameNode(nn1)上的数据复制到第二个NameNode(nn2)。然后在nn2上运行:
bin/hdfs namenode -bootstrapStandby
启动其他节点
在NameNode上运行
bin/start-dfs.sh
4. 切换NameNode
手动方式
上面的NameNode默认以standby的状态启动,这时因为没有active的NameNode,所以是不能在HDFS读写文件,需要将其中的一个转成active状态。比如将nn1(对应前面的配置)转成Active:
bin/hdfs haadmin -transitionToActive nn1
然后在NameNode的web页面上部的括号里的standby变成active。 转成standby的命令是:
bin/hdfs haadmin -transitionToStandby nn1
自动切换
在当前NameNode不能使用时自动切换到第二个NameNode上,需要借助于 ZooKeeper (ZK)。
ZK的安装过程和Hadoop差不多,就是下载文件、修改配置、复制到所有机器、启动。具体步骤 在这里 。
配置文件conf/zoo.conf:
tickTime=2000
dataDir=/data/hadoop/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
server.1=hd2:2888:3888
server.2=hd3:2888:3888
server.3=hd4:2888:3888
hd2,hd3,hd4是主机名,至少需要三台,这个在一台机挂了整个系统还能用,ZK的数量一般是奇数。
然后要在hdfs-site.xml上添加配置:
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hd2:2181,hd3:2181,hd4:2181</value>
</property>
然后就是在NameNode的机器上初始化NameNode在ZK的状态了:
bin/hdfs zkfc -formatZK
重启HDFS或手动启动DFSZKFailoverController(ZKFC):
sbin/stop-dfs.sh # 重启hdfs
sbin/start-dfs.sh
sbin/hadoop-daemon.sh start zkfc # 启动ZKFC
在该HA方案中,每一个NameNode都有一个对应的ZKFC。ZKFC会随NameNode启动。
测试
在当前NameNode运行 jps 看NameNode的进程ID,然后kill掉。通过Web页面( http://hdx:50070 ),可以看到standby的NameNode几乎在kill的同时转成active了。
原文 http://blog.segmentfault.com/defool/1190000000624579


