本参照hadoop官方网站的 说明进行操作, 最后在参照文档中遇到一些问题,通过查找百度找到解决方案,把操作过程记录下来。
Purpose
This document describes how to set up and configure a single-node Hadoop installation so that you can quickly perform simple operations using Hadoop MapReduce and the Hadoop Distributed File System (HDFS).
本文介绍配置单节点(本地程序,并非集群)hadoop的方法, 通过这个集群可以快速操作在hdfs文件系统下执行hadoop的mapruduce程序。
Prerequisites
Supported Platforms
- GNU/Linux is supported as a development and production platform. Hadoop has been demonstrated on GNU/Linux clusters with 2000 nodes.
linux是开发和产品运行的平台。hadoop已经可以在运行在有2000个节点的linux系统上。
- Windows is also a supported platform but the followings steps are for Linux only. To set up Hadoop on Windows, see wiki page.
hadoop目前也支持windows系统(以前不支持,或者用非常特别的方法运行,在windows上模拟linux环境,现在不用了, 但是你要自己编译一个特别的版本), 但是本文是介绍linux下安装hadoop的,windows 的安装过程请参照wiki进行配置
Required Software
Required software for Linux include:
Java™ must be installed. Recommended Java versions are described at HadoopJavaVersions.
java必须被安装好, 推荐的java列表参照上面的链接
ssh must be installed and sshd must be running to use the Hadoop scripts that manage remote Hadoop daemons.
ssh程序必须被安装到系统中,( 并且要进行免密码登录)。hadoop程序通过ssh管理远程的服务程序
Installing Software
If your cluster doesn’t have the requisite software you will need to install it.
For example on Ubuntu Linux:
$ sudo apt-get install ssh $ sudo apt-get install rsync centos上 请用 yum install ssh 和 yum install rsync
Download
To get a Hadoop distribution, download a recent stable release from one of the Apache Download Mirrors.
hadoop下载通过上面的 相关镜像站点下载, 也可以通过官方的归档站点下载, 可以下载到 全部各个版本。
Prepare to Start the Hadoop Cluster
Unpack the downloaded Hadoop distribution. In the distribution, edit the file etc/hadoop/hadoop-env.sh to define some parameters as follows:
解压缩hadoop应用程序。 在解压缩目录中, 编辑解压目录中 etc/hadoop/hadoop-env.sh文件, 在文件中设置下面的环境变量
# set to the root of your Java installation export JAVA_HOME=/usr/java/latest
Try the following command:
$ bin/hadoop
This will display the usage documentation for the hadoop script.
Now you are ready to start your Hadoop cluster in one of the three supported modes:
Standalone Operation
By default, Hadoop is configured to run in a non-distributed mode, as a single Java process. This is useful for debugging.
默认的情况下, hadoop被配置为一个单个java进程的本地单机模式, 这个模式下可以方便调试程序(可以设置断点进行调试java代码,其他任何模式都不能方便调试程序)
The following example copies the unpacked conf directory to use as input and then finds and displays every match of the given regular expression. Output is written to the given output directory.
下面代码拷贝解压后的conf目录中一些文件到 input目录(当前目录是hadoop的home目录), 然后调用hadoop程序执行文件的正则查找工作, 查找完成后讲结果输出到output目录中
$ mkdir input $ cp etc/hadoop/*.xml input $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep input output 'dfs[a-z.]+' $ cat output/*
Pseudo-Distributed Operation
Hadoop can also be run on a single-node in a pseudo-distributed mode where each Hadoop daemon runs in a separate Java process.
hadoop程序可以工作在单个节点上, 在这个节点上各个hadoop程序单独运行在独立的jvm中,这个模式就是伪分布模式
Configuration
Use the following:
使用下面一些配置文件, 注意配置文件中的配置结构, 不多有多余的<configuration>结构。 见下面文档中的内容拷贝到配置文件中, 注意文件中已经包括了<configuration>配置结构,需要删除不必要的配置
etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Setup passphraseless ssh
Now check that you can ssh to the localhost without a passphrase:
检查ssh的免密码登录情况
$ ssh localhost
If you cannot ssh to localhost without a passphrase, execute the following commands:
如果上面的登录过程中提示输入密码, 请输入下面的指令设置免密码登录
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys $ export HADOOP\_PREFIX=/usr/local/hadoop
这里: 需要额外添加命令, 设置authorized_keys 文件 是600 否则, 没办法免密码登录
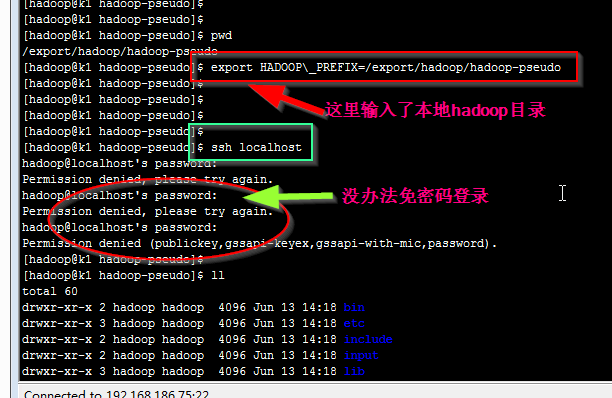
chmod 600 .ssh/authorized_keys
然后在登录就是 免密码登录了!!
Execution
The following instructions are to run a MapReduce job locally. If you want to execute a job on YARN, see YARN on Single Node.
下面的指令在本地运行一个mapreduce程序, 若是要单个节点上运行yarn程序需要看另外一节内容
1. Format the filesystem:
格式化本地hdfs文件系统
$ bin/hdfs namenode -format
2. Start NameNode daemon and DataNode daemon:
启动 namenode和datanode进程
$ sbin/start-dfs.sh
The hadoop daemon log output is written to the $HADOOP_LOG_DIR directory (defaults to $HADOOP_HOME/logs).
hadoop进程输出日子到当前目录的logs目录中
3.Browse the web interface for the NameNode; by default it is available at:NameNode - http://localhost:50070/
可以通过浏览器 查看 http://localhost:50070/地址,来了解namenode工作情况。实践中可以根据情况调整localhost到真实机器的ip地址
4. Make the HDFS directories required to execute MapReduce jobs:
在hdfs中创建相关目录
$ bin/hdfs dfs -mkdir /user $ bin/hdfs dfs -mkdir /user/<username>
5. Copy the input files into the distributed filesystem:
拷贝输入文件到分布式文件系统中
$ bin/hdfs dfs -put etc/hadoop input
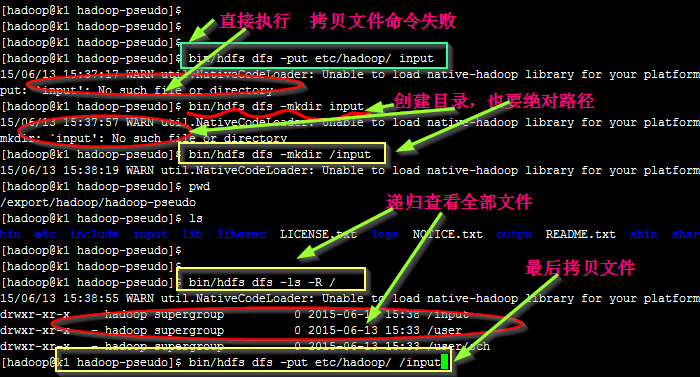
拷贝中发现, hdfs是没有当前目录的概念的, 每次都需要 绝对路径, 详细情况如上图。
6. Run some of the examples provided:
运行下面指令的相关程序,来在本地的伪分布模式中运行mapreduce程序
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep input output 'dfs[a-z.]+'
上面指令中的 目录没有指定 绝对路径, 实践中发现不工作,需要替换为下面:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep /input /output 'dfs[a-z.]+'
7. Examine the output files: Copy the output files from the distributed filesystem to the local filesystem and examine them:
下面指令拷贝 hdfs文件中 output目录中文件到 本地文件的output目录中
$ bin/hdfs dfs -get output output $ cat output/*
or
View the output files on the distributed filesystem:
或者直接查看 hdfs中相关文件
$ bin/hdfs dfs -cat output/*
8. When you’re done, stop the daemons with:
当上面完成后, 可以用下面的指令停止伪分布集群
$ sbin/stop-dfs.sh
YARN on a Single Node
You can run a MapReduce job on YARN in a pseudo-distributed mode by setting a few parameters and running ResourceManager daemon and NodeManager daemon in addition.
你能通过一些设置让ResourceManager 和NodeManager 工作在伪分布式模式下, 你能在这样的一个伪分布模式中运行yarn程序
The following instructions assume that 1. ~ 4. steps of the above instructions are already executed.
下面的指令是假设您在上面了伪分布式模式都设置完成的前提下,进行下面的设置
1. Configure parameters as follows:etc/hadoop/mapred-site.xml:
在下面的etc/hadoop/mapred-site.xml文件中设置如下配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
mapred-site.xml文件不存在, 需要用下面命令拷贝一份配置文件
cp mapred-site.xml.template mapred-site.xml
2. 配置下面的文件
etc/hadoop/yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3. Start ResourceManager daemon and NodeManager daemon:
用下面的命令启动ResourceManager和NodeManager程序
$ sbin/start-yarn.sh
4. Browse the web interface for the ResourceManager; by default it is available at:
- ResourceManager - http://localhost:8088/
通过web浏览器方式查看ResourceManager相关信息
5. Run a MapReduce job.
通过下面命令 运行mapreduce程序(在伪分布式模式中)
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep /input /output5 'dfs[a-z.]+'
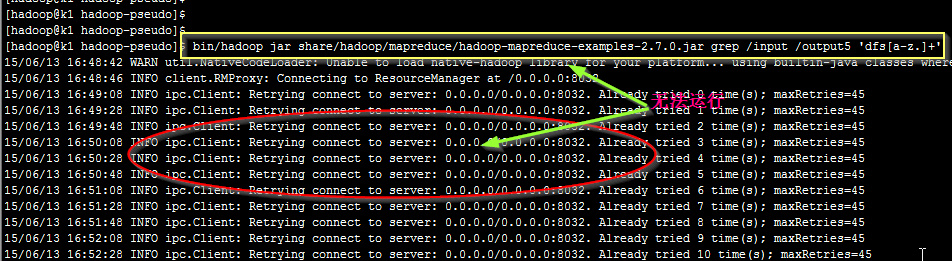
如上图, 运行时,程序无法正常工作, 无法连接ResourceManager程序
经过百度搜索, 知道在yarn-site.xml文件中额外添加如下配置
<property>
<name>yarn.resourcemanager.address</name>
<value>127.0.0.1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>127.0.0.1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>127.0.0.1:8031</value>
</property>
配置如下图所示:
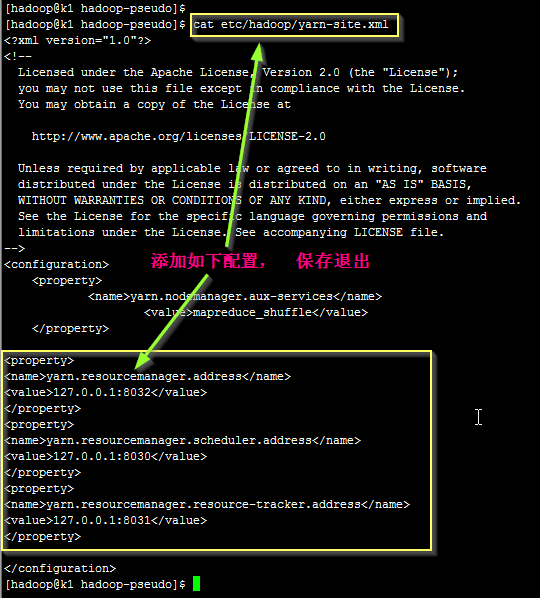

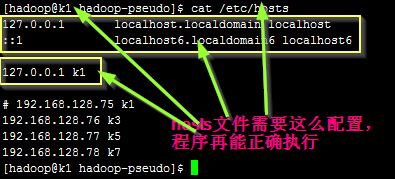
修改完成后,重新启动 mapreduce程序, 程序很快就运行完毕
When you’re done, stop the daemons with:
最后你可以停止yarn程序
$ sbin/stop-yarn.sh
参考文章


