Hazelcast 是一个开源的可嵌入式数据网格(社区版免费,企业版收费)。你可以把它看做是内存数据库,不过它与 Redis 等内存数据库又有些不同。项目地址:http://hazelcast.org/
Hazelcast 使得 Java 程序员更容易开发分布式计算系统,提供了很多 Java 接口的分布式实现,如:Map, Queue, ExecutorService, Lock, 以及 JCache。它以一个 JAR 包的形式提供服务,只依赖于 Java,并且提供 Java, C/C++, .NET 以及 REST 客户端,因此十分容易使用。
1 import com.hazelcast.config.Config;
2 import com.hazelcast.core.Hazelcast;
3 import com.hazelcast.core.HazelcastInstance;
4
5 import java.util.concurrent.ConcurrentMap;
6
7 public class DistributedMap {
8 public static void main(String[] args) {
9 Config config = new Config();
10 HazelcastInstance h = Hazelcast.newHazelcastInstance(config);
11 ConcurrentMap<String, String> map = h.getMap("my-distributed-map");
12 map.put("key", "value");
13 map.get("key");
14
15 //Concurrent Map methods
16 map.putIfAbsent("somekey", "somevalue");
17 map.replace("key", "value", "newvalue");
18 }
19 }
20如何存储数据
Hazelcast 服务之间是端对端的,没有主从之分,因此也不存在单点故障。集群中所有的节点都存储等量的数据以及进行等量的计算。
Hazelcast 缺省情况下把数据分为 271 个区。这个值可配置于系统属性 hazelcast.partition.count。 对于一个给定的键,在经过序列号、哈希并对分区总数取模之后能得到此键对应的分区号。所有的分区等量的分布与集群中所有的节点中,每个分区对应的备份也同样分布在集群中。
下例是拥有2个节点的 Hazelcast 集群:
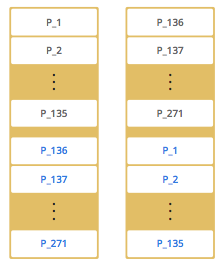
黑色字体表示分区,蓝色字体表示备份。节点1存储了1到135分区,这些分区同时备份在节点2中。节点2存储了136到271分区,并备份在节点1中。
此时如果添加2个节点到集群中,Hazelcast 一个一个的移动分区和备份到新的节点,使得集群数据分布平衡。
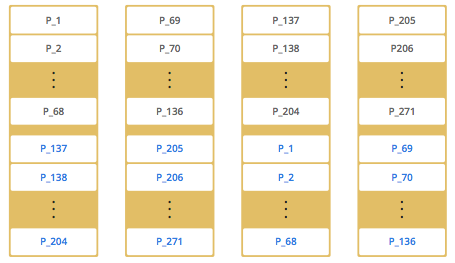
注意实际中分区并不是有顺序的分布,而是随机分布,上面的示例只是为了方便理解。重要的是理解 Hazelcast 平均分布分区以及备份。
Hazelcast 使用哈希算法进行数据分区。对于一个给定的键(如Map)或者对象名称(如topic和list):
- 序列化此键或对象名称,得到一个byte数组。
- 对byte数组进行哈希。
- 取模后的值即为分区号。
每个节点维护一个分区表,存储着分区号与节点之间的对应关系。这样每个节点都知道如何获取数据。
重分区
集群中最老的节点(或者说最先启动)负责定时发送分区表到其他节点。这样如果有节点加入或者离开集群,所有的节点也能更新分区表。
![]() 注意: 如果最老的节点挂了,次老节点会接手这个任务。
注意: 如果最老的节点挂了,次老节点会接手这个任务。
这个定时任务时间间隔可配置系统属性 hazelcast.partition.table.send.interval。 缺省值为15秒。
重分区发生在:
- 节点加入集群。
- 节点离开集群。
此时最老节点会更新分区表,分发,接着集群开始移动分区,或者从备份恢复分区。
使用方式
有两种方式:嵌入式和客户端服务器。
- 嵌入式,Hazelcast 服务器的 jar 包被导入宿主应用程序,服务器启动并存在于各个宿主应用中。优点是可以更低延迟的数据访问。
- 客户端服务器,Hazelcast 客户端的 jar 包被导入宿主应用程序,服务器 jar 包独立运行于 JVM 中。优点是更容易调试以及更可靠的性能,最重要的是更好的扩展性。
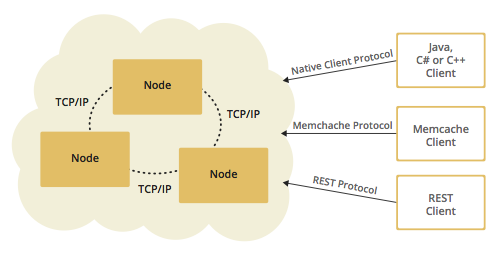
Hazelcast作为一个高度可扩展的数据分发和集群平台,提供了高效的、可扩展的分布式数据存储、数据缓存。Hazelcast是开源的,在分布式技术方面,Hazelcast提供了十分友好的接口供开发者选择,如Map,Queue,ExecutorService, Lock和Jcache。
Hazelcast的稳定性很高,分布式应用可以使用Hazelcast进行存储数据、同步数据、发布订阅消息等。Hazelcast是基于Java开发的,其客户端有Java, C/C++, .NET以及REST。Hazelcast同时也支持memcache协议。它很好的支持了Hibernate,可以很容易的在当今流行的数据库系统中应用。
如果你在寻找一个基于内存的、可扩展的以及对开发者友好的NoSql,那么Hazelcast是一个很不错的选择!
Hazelcast是一个高度可扩展的数据分发和集群平台。特性包括:
- 提供java.util.{Queue, Set, List, Map}分布式实现。
- 提供java.util.concurrency.locks.Lock分布式实现。
- 提供java.util.concurrent.ExecutorService分布式实现。
- 提供用于一对多关系的分布式MultiMap。
- 提供用于发布/订阅的分布式Topic(主题)。
- 通过JCA与J2EE容器集成和事务支持。
- 提供用于安全集群的Socket层加密。
- 支持同步和异步持久化。
- 为Hibernate提供二级缓存Provider 。
- 通过JMX监控和管理集群。
- 支持动态HTTP Session集群。
- 利用备份实现动态分割。
- 支持动态故障恢复。
1.优点
a. Hazelcast开发比较简单
Hazelcast是基于Java写的,没有任何其它的以来。它提供的API跟Java util包很像。对于开发者来说,只需要加入hazelcast.jar,然后就可以快速使用在多个JVM之间的数据共享(分布式)。
b. Hazelcast的节点之间是平等的(Peer-to-Peer)
不像其它很多的NoSql解决方案,Hazelcast的节点之间是对等的(没有主次之分)。所有的节点存储的数据都是相等的,在应用中可以很容易的增加一个Hazelcast节点。或者以客户端-服务端的形式使用。
c. Hazelcast是可扩展的
Hazelcast的扩展性非常强,可以很简单的增加或减少节点。可以自动的监听节点的增加,并以线性的方式增加存储空间和能力。节点之间的通信是以TCP的方式建立的。
d. Hazelcast效率很高。
将数据存储在内存中,所以是非常高效的,包括读操作和写操作。
e. Hazelcast是可备份的
Hazelcast的数据会在多个节点上进行备份。一旦一个节点失败了,数据将会从别的节点上进行恢复。
f. Hazelcast页面元素齐全
页面可以看到map,list等数据内容,以及一些容量的仪表图.可以看到很多有用的数据,包括每个Map的请求次数等.
2. 使用场景
分布式缓存,通常使用在数据库之前的那一层
缓存服务器
NoSql的数据存储
Spring cache
微服务的结构
储存临时数据,如web的session等
3. Hazelcast的数据拆分
Hazelcast的数据拆分叫做间隔(Partitions)。默认情况下,Hazelcast会将数据拆分成271个间隔(总数,并不是单个单点)。当传入一个key时,Hazelcast会对它进行序列化,以及进行hash的算法等算出一个数值,通过该数值它存放在相应的间隔中(271个的其中一个)。在不同的节点中存放相同数量的间隔。Hazelcast还会生成备份的间隔,同样也是存放在这些间隔中。
4.配置
配置组连接选项
<group>
<name>test</name>
<password>test</password>
</group>配置管理页面,如果配置为true,则可以在mancenter目录下启动页面管理
<management-center enabled="true">http://10.1.4.97:8080/mancenter</management-center>
配置连接网络(自增长如果配为true,端口启动失败时会自增)
<port auto-increment="true" port-count="100">5701</port>
集群节点发现机制,自选一种
<join>
<multicast enabled="false">
<multicast-group>224.2.2.3</multicast-group>
<multicast-port>54327</multicast-port>
</multicast>
<tcp-ip enabled="true">
<interface>10.10.10.10</interface>
<member-list>
<member>10.10.10.10</member>
</member-list>
</tcp-ip>
<aws enabled="false">
<access-key>my-access-key</access-key>
<secret-key>my-secret-key</secret-key>
<!--optional, default is us-east-1 -->
<region>us-west-1</region>
<!--optional, default is ec2.amazonaws.com. If set, region shouldn't be set as it will override this property -->
<host-header>ec2.amazonaws.com</host-header>
<!-- optional, only instances belonging to this group will be discovered, default will try all running instances -->
<security-group-name>hazelcast-sg</security-group-name>
<tag-key>type</tag-key>
<tag-value>hz-nodes</tag-value>
</aws>
</join>配置节点对套接字加密,算法可选
<symmetric-encryption enabled="false">
<!--
encryption algorithm such as
DES/ECB/PKCS5Padding,
PBEWithMD5AndDES,
AES/CBC/PKCS5Padding,
Blowfish,
DESede
-->
<algorithm>PBEWithMD5AndDES</algorithm>
<!-- salt value to use when generating the secret key -->
<salt>thesalt</salt>
<!-- pass phrase to use when generating the secret key -->
<password>thepass</password>
<!-- iteration count to use when generating the secret key -->
<iteration-count>19</iteration-count>
</symmetric-encryption>配置执行服务器的线程和队列容量
<executor-service name="default">
<pool-size>16</pool-size>
<!--Queue capacity. 0 means Integer.MAX_VALUE.-->
<queue-capacity>0</queue-capacity>
</executor-service>