本文将从某互联网金融平台的线上版本发布工作出发,介绍了整个发布过程的优化及改造,以及对于灰度发布的探索及最终实践。
先要说明一点,任何脱离实际业务的技术工作都是耍流氓,技术需要服务于业务。因此,本文尽量淡化了业务方面的因素,聚焦于技术层面,建议在实际运用中还是要根据各自的业务场景去变化和调整。
其次,本文重点描述了线上发布的实施改造思路及演进过程,但对于其它相关联的一些点,比如发布规范流程、配置管理、监控、自动化工具的实施等不做过多涉及,如有兴趣可后续交流。
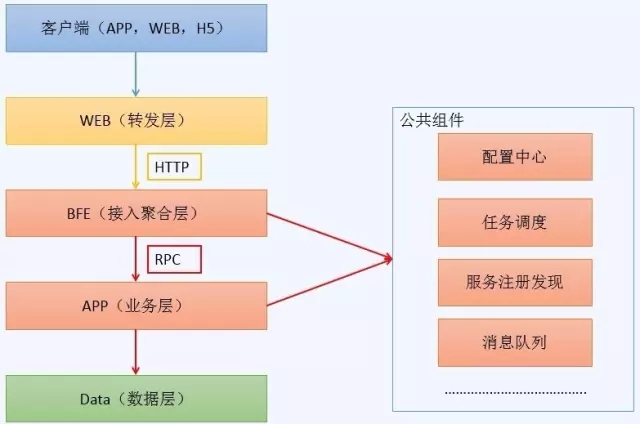
图1 应用逻辑架构图
包含手机APP、Web页面(主站/营销站等)、H5页面等,即访问发起方,来自于真实用户。
主要实现转发功能,利用Nginx实现,同时包含一些业务策略和跳转设置。
Business Front End,业务前端,实现接入和业务聚合功能,有点类似于API网关,但和业务有一定耦合,用Tomcat war包发布。
业务应用层,实现具体业务功能,目前几十个APP模块,用Tomcat war包发布。
数据层,如数据库、缓存、分布式文件系统等。
包含配置中心,任务调度中心,服务注册发现中心,消息队列等(这4个公共组件和灰度发布有一定关系,后续会单独介绍)。
- WEB->BFE:通过Nginx反向代理转发流量,HTTP请求;
BFE->APP和各APP间调用:通过在服务注册中心内注册,进行RPC调用,由BFE统一返回。
公共组件各家公司差异较大,有自研、纯开源或二次开发,我厂综合各方面因素后,选型如下:
- 配置中心
Disconf,百度的开源产品,用起来一般,更新较慢,基本满足配置管理需求。各APP启动时会从Disconf中获取配置信息,也支持热更新。
- 任务调度
Light task scheduler,简称LTS,用于Job类的统一管理调度,相当于统一管理的Crontab,业内相似的有当当网开源的Elastic-Job,不过LTS相对来说比较轻量级。各APP启动时会在lts中注册为任务节点,执行计划任务。
- 服务注册发现
Dubbo,阿里开源产品,有一定年数了,经受过考验。如果重度依赖Spring的,可以考虑Spring Cloud系列。各APP启动时会在Dubbo中进行注册Provider和Consumer 的Service接口,用于相互调用。
- 消息队列
RocketMQ,也是阿里的产品,性能不如Kafka,但用在金融行业应该没问题。各APP启动时会连接到RocketMQ中,进行后续消息的消费。
介绍完基本背景后,我们来聊聊核心问题:线上发布。
这里的线上发布指上文中的BFE和Service服务,都是基于Java开发,部署方式是war包,容器是Tomcat。
原始发布方式如下:
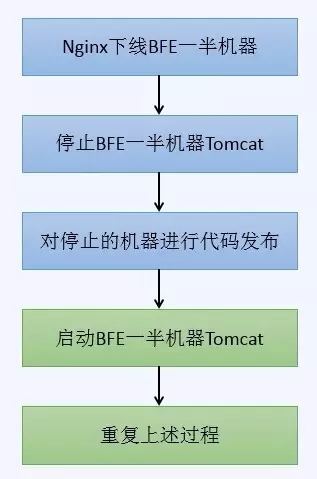
图2 BFE发布流程
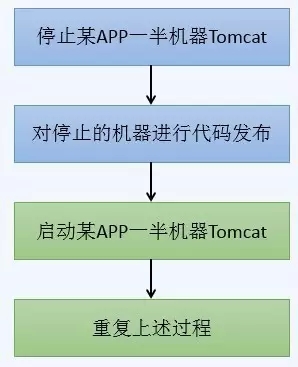
图3 APP发布流程
大家可以发现,BFE只是多了一部分切换Nginx的操作,因此后续重点对APP的发布进行说明。
上述APP的发布方式实施不久后,就遇到了几个问题,而且对业务造成了一定影响,总结有如下几条:
- APP发布时,直接重启Tomcat,导致节点正在处理的请求会受到影响,严重时会有数据异常。
- APP发布时如果节点正在作为task_tracker运行lts任务,会导致任务失败并retry。
- APP发布时如果节点正在消费RocketMQ中的消息,会导致消息消费异常,甚至进入retry或dlq队列。
- APP发布完成后没有即时验证机制,直接暴露给用户,如有异常影响面很广。
- 线上无法同时存在新老版本的APP来用于长时间的验证。
竟然有这么多问题,泪崩~~
仔细分析上述问题,可以归结为两类:
- 平滑发布问题:即以上问题前三点。发布时要尽可能平滑,对用户及业务影响最小(补充一句,当然也可以通过幂等及自动或人工补偿机制去完善,这是另一个维度)。
- 发布验证问题:即以上问题最后两点。发布完成要能小范围的即时验证,最好是能定位到个体,且如有需要,验证时间可以延长。
接下来就结合实践,介绍下如何解决这两个问题。BTW,在过渡期间内,大家只能熬夜停服发布或者在晚上低峰期发布,苦不堪言。
平滑发布,即发布时尽量减少对业务的影响,能够柔和地对服务进行下线。为做到这一点,必须要结合现有公共组件的特点,在代码部署前先对服务进行平稳下线,确认下线完毕后再进行发布工作。
由于所有APP的接口都有在Dubbo中进行注册,因此需要有办法能够对其Provider Service接口进行下线或屏蔽,使其不提供服务,即其它服务无法调用它的接口。
Service接口下线后,此APP机器自然无任何流量流入,因此也无流量返回,达到下线APP机器的目的,然后即可部署代码。
官方有提供Dubbo-Admin工具,用于对Dubbo中各APP及其Service接口进行管理,里面自然也包含有实现下线的功能,可以有3种方法:
- 屏蔽,貌似一直没有效果;
- 禁用,可以成功禁用;
权重调节,可以设置0-100的权重,设置为0时即不提供服务。
经过选型,我们选用更灵活的权重调节方案,通过Dubbo-Admin对需要下线机器的APP应用接口权限设置为0。
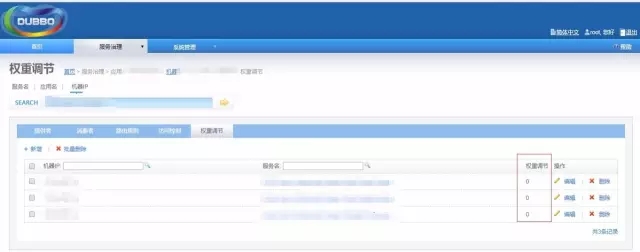
图4 Dubbo权重调节
同理,如果要被重启的APP机器正在消费消息队列中的消息,也需要等消费完成后才能进行发布,因此需要查询该APP机器所对应的Consumer Group及绑定的Queue,然后下线,即解除绑定。在RocketMQ的web-console中我们增加了对应接口,进行下线。
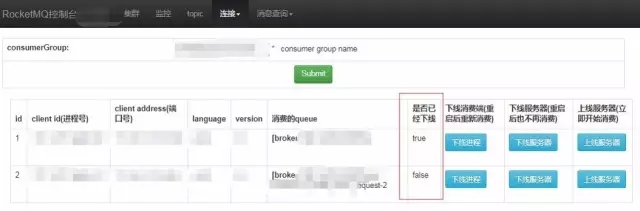
图5 RocketMQ控制台
对于任务调度这一块,我们也必须要让APP机器不再接受任何新任务,以免重启发布时任务执行失败。
我们的做法是在ZooKeeper里对需要停止跑Job任务的APP机器,增加一个Znode,比如”机器ID=offline”,当JobTracker去调度TaskTracker执行任务时,一旦检测到包含有此Tag的机器,就不会再给这些APP机器分配任务,以此达到任务解耦。
为了平滑发布的顺利进行,检查确认机制不可或缺,即确保Dubbo/Rocketmq/Lts中的下线都已生效,并且无流量发生,我们从以下两个维度去检查:
- 接口检查,调用Dubbo、RocketMQ、LTS的API接口,检查APP机器状态,是否为已经下线。当然,在做了下线功能的同时,我们也有检查功能和上线功能,可供调用。
- 监控检查,调用CAT、ELK的API接口,检查APP机器的请求访问数和日志流量是否都已经为0,已经处于下线状态。
经过上述改造后,我们新的发布流程如下,基本解决了平滑发布问题,发布时对业务的影响降到了最低;
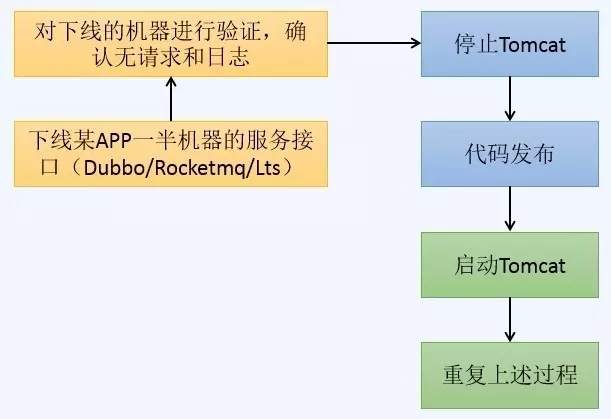
图6 发布流程图解
这一章主要解决发布验证的问题,即如何验证以确保线上发布的准确性,有问题时确保影响面最小。
这里先来个小插曲,不知道各位有没有碰到过类似情况,大版本发布时通常会挂停服公告,把请求切断在Web层,然后运维小伙伴会进行APP发布,此时通常会把所有APP都进行代码部署,因为是大版本,十分凶残。

图7 停服页面
下面问题来了,等发布完成后,产品经理通常会说,能不能先不要开服,对外还是保持停服页面,但让我们几个人能够验证下功能,以肯定确定以及确认这次发布没有遗漏或漏测的坑。
如果你是运维的小伙伴,会怎么搞,大家可以脑洞下~~
先分享下我们的做法,我们会在办公网络单独申请一个HDFB的wifi(灰度发布),然后当你连上这个wifi出公网解析时,所有和我们业务相关的域名会解析到另一个入口,这个入口对应一个灰度发布的WEB层,配置和线上一模一样,限制只能办公网络访问,所有人员在办公室通过这个入口即可访问和验证新版本,但公网用户不可达。
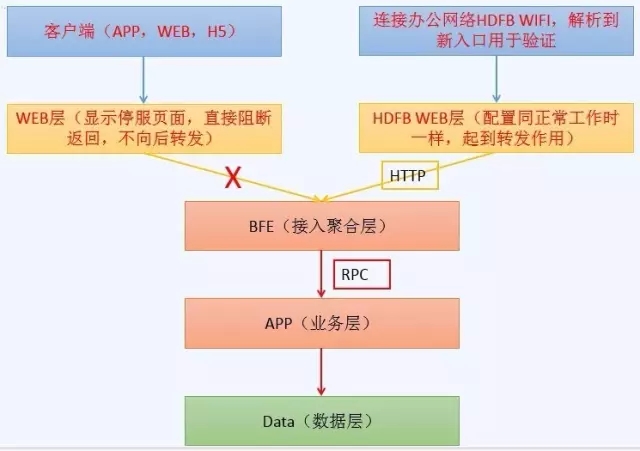
图8
通过之前的平滑发布和小范围验证的摸索,开始进行灰度发布实践之路。
灰度发布,我相信大家对这个词都有各自的理解和体会,它也有很多相似的概念或变体。比如分组发布,蓝绿发布,金丝雀发布,甚至于A/B测试。这里不想纠结于某个具体的名词或概念(需要烦请自行百度),还是致力于解决实际中碰到的两个问题:平滑发布和发布验证。
平滑发布问题前文中已有描述,至于发布验证问题,前文介绍了在停服情况下通过HDFB WEB层进行验证,但有两个问题:
- 一是只适用于停服发布,如果某次只发布几个APP模块,无法单独验证。
- 二是验证时间有限(停服窗口一般不会太大),如果需要长时间验证,无法满足。
为了解决上面的问题,思考过程如下:
- BFE,接入汇聚层,可以通过Nginx反向代理进行分组,即可区分流量,进行分组;
- APP,由于会在多个公共组件中进行注册,因此需要在公共组件中对接入的APP及其Service接口进行分组,具有相互隔离的能力,即可区分验证;
- 针对公共组件的优化,又有以下两种做法:
- 多搭建几套公共环境,用于不同分组,但很快被否定,维护成本太大。
- 在一套公共环境中,支持多个分组,在APP中引入对应的framework jar包,支持灰度分组参数GROUP。
因此,按照这个思路,如果需要进行灰度发布及长时间验证时,会是下面的架构图:
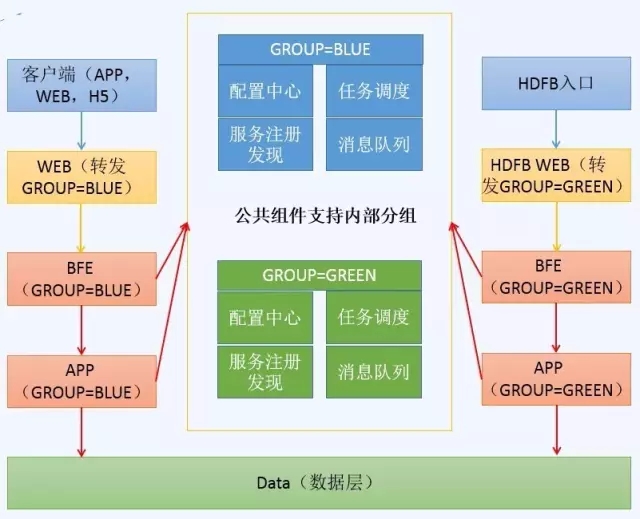
图9
此处以GROUP=BLUE及GROUP=GREEN为例来进行说明(当然也可以分成更多的组),描述APP机器灰度发布流程(BFE类似,只是增加一步切换Nginx操作,不单独描述)。
正常情况下,各APP机器启动时,引入framework.jar包,并指定自己所属GROUP,假设初始时为BLUE。
当需要发布及进行验证时,平滑下线所有APP的一部分机器,然后对需要部署代码的APP进行发布,启动时修改所有下线APP机器的所属GROUP=GREEN。
发布完成后,可以通过单独的HDFB WEB入口,进行验证,此时线上仍可正常提供服务。
确认无误后,重复上述步骤,增加GROUP=GREEN机器比例,当超过一半时,GROUP=GREEN直接提供线上服务,即把线上WEB层直接指向BFE(GROUP=GREEN)的分组。
随即把GROUP=BLUE机器再全部进行代码发布。
发布完成后,线上APP统一运行在GROUP=GREEN的环境。
通过这种方式,我们即完成在不需要停服的情况下,对线上APP进行灰度发布及验证,对应的各基础组件截图如下:
配置中心Disconf:通过版本来对应GROUP的功能
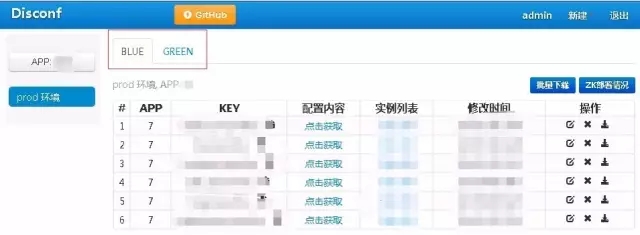
图10 Disconf
注册中心Dubbo:通过在Service的名称前加上GROUP以分组
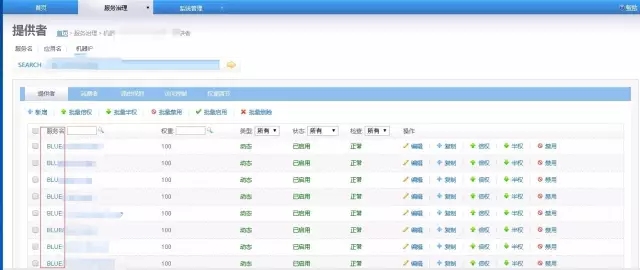
图11 Dubbo
消息队列RocketMQ:通过在Topic的后面加上GROUP以分组
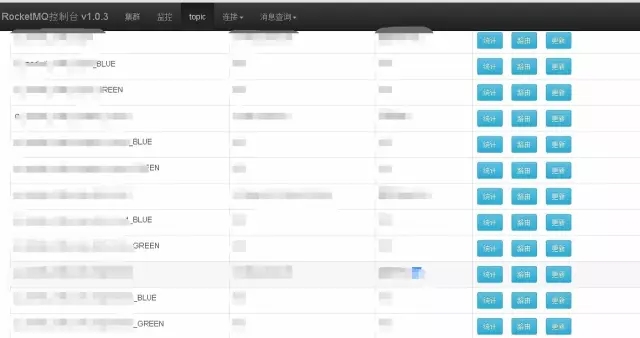
图12 RocketMQ
任务调度中心lTS:通过给每个task id加入灰度分组信息,以区分不同的TaskTracker执行节点,新的task只在新代码的机器上运行。
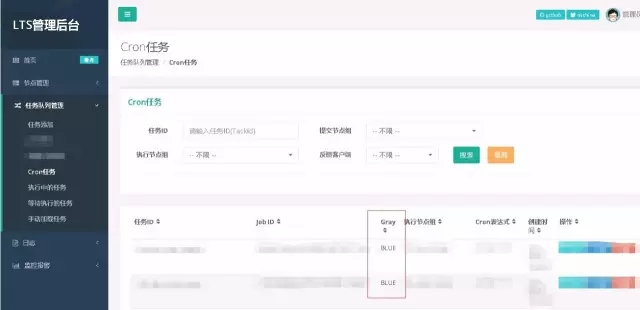
图13 lts
下面,我们谈一谈灰度发布的前提条件、应对思路以及后续的优化改善。细心的同学一定发现了,前面讲的灰度发布流程,应该是有一定先决条件的,体现在以下几个方面:
- 数据层的变化导致新老版本无法兼容的,不能使用灰度发布。
应对思路:这个没有特别好的办法,只能从研发层面去规范,比如APP访问数据时,尽量别出现select * from table的操作,而且架构设计时要及早考虑这点。
- APP层中各APP的新老Service接口无法兼容的,不能使用灰度发布。
应对思路:这个原则上要求一般的程序都要满足,比如至少要求跨一个版本的兼容,多个版本间就不需要了。但实际操作时会略困难,牵涉到开发流程规范问题,需要开发测试同学一起配合,能做到单模块级别的测试,且各模块间要相互保持兼容和一致。
- 日常流量对灰度发布的影响有多少。
应对思路:这个目前的解决办法是通过增加机器来解决,我们目前采取双机房四区域,4倍的流量冗余,每次按照25%的流量依次进行灰度发布。
关于灰度发布的后续优化及改善,目前有考虑到几个方面,总结如下,后续会逐步改进:
首先,当然是一个效率问题,目前虽然已经实现自动化,但发布过程中还是需要一定的人为介入,而且验证周期较长,后续要考虑如何更流畅的使用。
其次,是不是每个发布都要走灰度进行,还是平滑发布后就能直接对外提供服务,比如一个Hotfix的修改,要不要灰度?这个需要有一定的标准。
再次,如果需要长时间来验证灰度环境,线上会同时存在两个甚至以上的版本,不利于运维维护,且监控方面需要加强。
最后,能否利用灰度发布的方式,在线上进行流量回放及全链路压测,也是一个后续摸索的话题。
来源:http://dbaplus.cn/news-72-1441-1.html



