来源:互联网
substring(int beginIndex, int endIndex)在JDK6与JDK7中的实现方式不一样,理解他们的差异有助于更好的使用它们。为了简单起见,下面所说的substring()指的 就是substring(int beginIndex, int endIndex)方法。
1.substring()是做什么的?
substring(int beginIndex ,int endIndex)方法返回一个子字符串,返回的是从原字符串的beginIndex到endIndex-1之间的内容。
String x ="abcdef";
x = x.substring(1,3);
System.out.println(x);
输出:
"bc" |
2.当substring()被调用的时候,内部发生什么事?
你或许会认为由于x是不可变的对象,当x被x.substring(1,3)返回的结果赋值后,它将指向一个全新的字符串如下图:
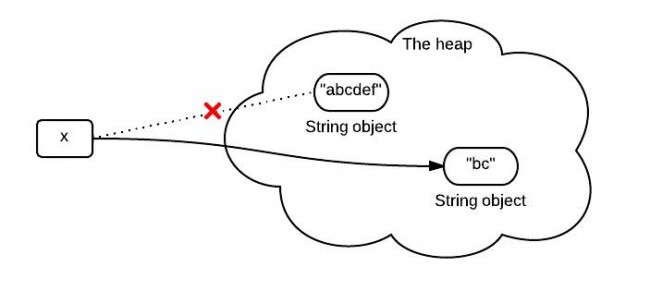
然而,这个图并不完全正确,或者说并没有完全表示出java 堆中真正发生的事情。那么当调用substring()的时候到底发生的了什么事呢?JDK 6与JDK7的substring方法实现有什么不一样呢?
3.JDK6中的substring()
java中字符串是通过字符数组来支持实现的,在JDK6中,String类包含3个域,char[] value、int offset、int count。分别用于存储真实的字符数组、数组的偏移量,以及String所包含的字符的个数。
当substring()方法被调用的时候,它会创建一个新的字符串对象,但是这个字符串的值在java 堆中仍然指向的是同一个数组,这两个字符串的不同在于他们的count和offset的值。
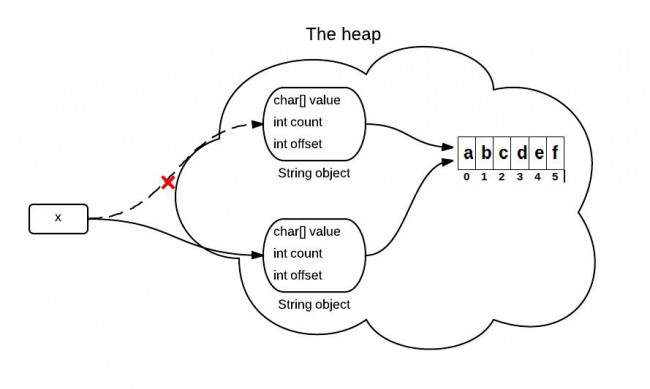
下面是jdk6中的原代码,是简化后只包含用来说明这个问题的关键代码:
//JDK 6
String(intoffset,intcount,charvalue[]) {
this.value = value;
this.offset = offset;
this.count = count;
}
publicString substring(intbeginIndex,intendIndex) {
//check boundary
return new String(offset + beginIndex, endIndex - beginIndex, value);
}
4.jdk6中substring()将会导致的问题
如果你有一个非常长的字符串,但是你仅仅只需要这个字符串的一小部分,这就会导致性能问题(译注:可能会造成内存泄露,这个 bug 很早以前就有提及),因为你需要的只是很小的部分,而这个子字符串却要包含整个字符数组,在jdk6中解决办法就是使用下面的方法,它会指向一个真正的子字符串。
x = x.substring(x, y) +""
5.JDK7中的substring()
在JDK7中有所改进,substring()方法在堆中真正的创建了一个新的数组,当原字符数组没有被引用后就被GC回收了.因此避免了上述问题.
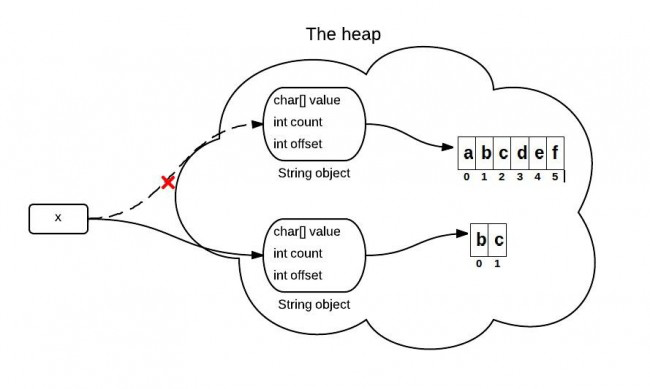
//JDK 7
publicString(charvalue[],intoffset,intcount) {
//check boundary
this.value = Arrays.copyOfRange(value, offset, offset + count);
}
publicString substring(intbeginIndex,intendIndex) {
//check boundary
intsubLen = endIndex - beginIndex;
returnnewString(value, beginIndex, subLen);
}
译注: 在最新的Oralce JDK 6u45中,substring的实现方式已经改进了,不过我查到openjdk的 6-b14就是原来的实现方式,有兴趣的可以查查具体是哪个版改进的.