上个夏天,我们分享了 Kubernetes 的伸缩性更新,经过一番努力,我们自豪的宣布 Kubernetes 1.6 能够处理 5000 个节点的集群和 15 万个 Pod 了;另外即使在这种负载规模下,端到端的 Pod 启动速度依然优于 2000 节点规模的 1.3 版本的 Kubernetes 集群,API 调用的延迟依然满足 1 秒的 SLO。
本文中我们会讨论到
- 性能测试的指标和结果
- 提高性能的改进
- 未来在伸缩性方面的发展计划
XX 节点的集群意味着什么?
现在 Kubernetes 1.6 已经发布,那么当我们说到支持多少个节点的集群的时候,我们到底在说什么?前文说过,我们有两个性能相关的服务水平目标(SLO):
- API 响应性:99% 的 API 调用应该在一秒之内返回。
- Pod 启动时间:99% 的 Pod 及其容器(已拉取镜像)在五秒之内完成启动。
跟以前一样,集群规模是可以超过 5000 节点的,但是会引起性能下降,可能无法满足 SLO 要求。
我们知道 SLO 的限制。还有很多我们没有覆盖到的系统因素。例如,新 Pod 启动之后,需要多久才能通过服务 IP 进行访问?这个数据我们就没有测量。如果你在使用大规模 Kubernetes 集群过程中,还有没有被我们的 SLO 覆盖的性能需要,请联系 Kubernetes 的伸缩性小组,让我们可以帮助你进一步理解 Kubernetes 是否能够满足你的负载需求。
接下来, Kubernetes 的伸缩性相关的最高优先级任务就是清晰一下对于支持 XX 节点规模的集群的定义:
- 强化现有的 SLO。
- 加入更多的 SLO(覆盖 Kubernetes 相关的更多方面,包括网络)
Kuernetes 1.6 的性能指标
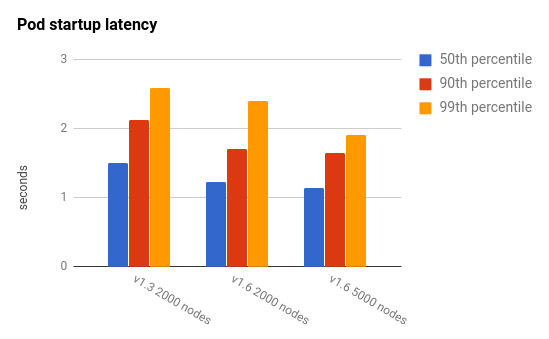
那么在 Kubernetes 1.6 中,大规模集群到底怎样呢?下图显示了 2000 和 5000 节点的集群规模下的端到端的 Pod 启动时间。另外我们还加入了之前性能测试中发布过的 Kubernetes 1.3 下 2000 节点规模集群的相应指标来作对比。如图所见,两种规模的 Kubernetes 1.6 集群的 Pod 启动延迟都优于 2000 节点规模的 Kubernetes 1.3 集群。
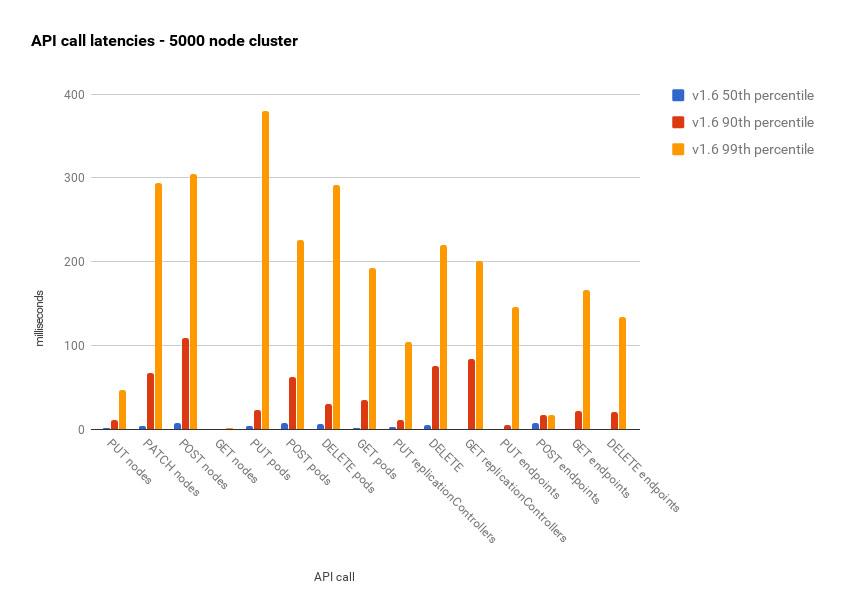
接下来的这种图展示了 5000 节点规模的 Kubernetes 1.6 集群的 API 响应时间。所有的百分位数都少于 500 毫秒,而且 90 百分位数下低于 100 毫秒。
如何达成现有的性能目标?
过去的九个月中(从上次的伸缩性博客开始),Kubernetes 有很多性能和伸缩性的改进。本文中会谈谈两个最大的变化,并会列出一些其他的改动。
etcd v3
在 Kubernetes 1.6 中,缺省的存储后端从 etcd v2 升级到了 v3。这一工作从 1.3 的发布周期就开始了。为什么花了这么长的时间呢?
- 第一个稳定的支持 v3 API 的 etcd 发布于 2016 年 6 月 30 日。
- 新 API 是和 Kubernetes 团队合作设计的,以满足 Kubenretes 的功能和伸缩性需求。
- 几乎在 etcd v3 发布的同时,就完成了 Kubernetes 的集成——事实上,CoreOS 就是使用 Kubernetes 作为 etcd v3 API 的概念验证来使用的。
我们有很多做出这一变化的理由,下面列举一些最重要的:
- 从 v2 到 v3 的不向后兼容的升级,是一个巨大的变化,这是一个艰难的决定。我们在九月份发现,如果我们继续使用 etcd v2 的话,是无法负载 5000 节点的集群规模的。etcd v2 中的 watch 实现是一个主要障碍。在 5000 节点规模的集群中,我们每秒需要向同一个 watcher 发送至少 500 个 watch 事件,这在 v2 中是不可能的。
kubernetes/32361: https://github.com/kubernetes/kubernetes/issues/32361 里面包含了一些这方面的讨论。
- 在有了升级到 etcd v3 的动机之后,我们开始进行测试,过程中发现了一些问题。除了 Kubernetes 中出了一些小 Bug 之外,我们还向 etcd v3 的 watch 实现提出了更高的性能要求(etcd v2 中我们遇到的主要性能瓶颈)。这导致了 etcd 3.0.10 的补丁发布。
- 做出这一变化之后,我们确信新的 Kubernetes 集群能够使用 etcd v3。但是还有迁移现有集群的问题。为了自动实现迁移过程,对 CoreOS 的 etcd 升级工具进行了详尽的测试,并且做出了回滚方案。
最终我们确信这一方案是可靠的。
数据格式切换为 protobuf
在 Kubernetes 1.3 中,我们在 Kubernetes 中启用了 protobufs 作为组件通讯的数据格式(作为 JSON 的补充)。这给我们带来巨大的性能提升。
虽说技术上我们已经做好了准备,但我们还在 etcd 存储中使用了 JSON,这一变更的延迟,直接原因就是 etcd v3 的迁移。因为在 etcd v2 中我们无法使用二进制格式存储(只能用 base 64 编码来勉强实现),而在 etcd v3 中就可以了。所以迁移到 etcd v3 能够避免一些不必要的数据转换,最终我们决定等待 etcd v3 的迁移完成后,才切换到 protobufs。
其他优化
我们在 Kubernetes 的最近三次发布中做出了几十项优化,包括:
- 调度器优化( 5-10 倍的调度吞吐)
- 优化控制器设计,降低了 controller-manager 的资源消耗
参见:https://github.com/kubernetes/community/blob/master/contributors/devel/controllers.md
- 对 API Server 的部分操作进行优化(转换、深度复制、patch)
- 降低 API Server 的内存占用(显著的降低了 API 调用的延迟时间)
需要强调的是,近期的几个发布中的优化工作,以及这个项目的整个历史,都是 Kubernetes 社区很多公司和个人通力协作的结果。
下一步
经常有人问,我们到底要把 Kubernetes 的伸缩性提高到何种程度。目前我们还没有在未来版本中把集群规模提高到 5000 节点以上。如果超过 5000 节点,我们建议采用 federation 来结合多个 Kubernetes 集群。
当然并不是说我们要停止对伸缩性和性能的追求。正如开篇所言,我们的最高优先级工作是保证目前的 SLO 并扩展 SLO 到其他系统,例如网络。这些工作都已经在伸缩性 SIG 中启动,我们在 SLO 的定义上已经取得了长足的进步,这些工作将在未来的几个月中逐步完成。


