Kafka 跨集群同步方案——Kafka内置的MirrorMaker工具
该方案解决Kafka跨集群同步、创建Kafka集群镜像等相关问题,主要使用Kafka内置的MirrorMaker工具实现。
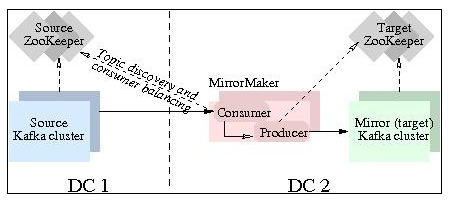
Kafka镜像即已有Kafka集群的副本。下图展示如何使用MirrorMaker工具创建从源Kafka集群(source cluster)到目标Kafka集群(target cluster)的镜像。该工具通过Kafka consumer从源Kafka集群消费数据,然后通过一个内置的Kafka producer将数据重新推送到目标Kafka集群。
一、如何创建镜像
使用MirrorMaker创建镜像是比较简单的,搭建好目标Kafka集群后,只需要启动mirror-maker程序即可。其中,一个或多个consumer配置文件、一个producer配置文件是必须的,whitelist、blacklist是可选的。在consumer的配置中指定源Kafka集群的Zookeeper,在producer的配置中指定目标集群的Zookeeper(或者broker.list)。
1 | kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config sourceCluster1Consumer.config --consumer.config sourceCluster2Consumer.config --num.streams 2 --producer.config targetClusterProducer.config --whitelist=".*" |
例如,你需要创建S集群的镜像,目标集群T已经搭建好,简单的做法如下:
1. 创建consumer配置文件:sourceClusterConsumer.config
1 2 | zk.connect=szk0:2181,szk1:2181,szk2:2181 groupid=test-mirror-consumer-group |
2. 创建producer配置文件:targetClusterProducer.config
1 | zk.connect=tzk0:2181,tzk1:2181 |
3. 创建启动脚本:start.sh
1 | $KAFKA_HOME/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config sourceClusterConsumer.config --num.streams 2 --producer.config targetClusterProducer.config --whitelist=".*" |
4. 执行脚本
执行start.sh通过日志信息查看运行状况,到目标Kafka集群的log.dir中即可看到同步过来的数据。
二、MirrorMaker的参数说明
1 | $KAFKA_HOME/bin/kafka-run-class.sh kafka.tools.MirrorMaker --help |
执行上面的命令就可以看到各个参数的说明:
1. 白名单(whitelist) 黑名单(blacklist)
mirror-maker接受精确指定同步topic的白名单和黑名单。使用java标准的正则表达式,为了方便,逗号(‘,’)被编译为java正则中的(‘|’)。
2. Producer timeout
为了支持高吞吐量,你最好使用异步的内置producer,并将内置producer设置为阻塞模式(queue.enqueueTimeout.ms=-1)。这样可以保证数据(messages)不会丢失。否则,异步producer默认的 enqueueTimeout是0,如果producer内部的队列满了,数据(messages)会被丢弃,并抛出QueueFullExceptions异常。而对于阻塞模式的producer,如果内部队列满了就会一直等待,从而有效的节制内置consumer的消费速度。你可以打开producer的的trace logging,随时查看内部队列剩余的量。如果producer的内部队列长时间处于满的状态,这说明对于mirror-maker来说,将消息重新推到目标Kafka集群或者将消息写入磁盘是瓶颈。
对于kafka的producer同步异步的详细配置请参考$KAFKA_HOME/config/producer.properties文件。关注其中的producer.type和queue.enqueueTimeout.ms这两个字段。
3. Producer 重试次数(retries)
如果你在producer的配置中使用broker.list,你可以设置当发布数据失败时候的重试次数。retry参数只在使用broker.list的时候使用,因为在重试的时候会重新选择broker。
4. Producer 数量
通过设置—num.producers参数,可以使用一个producer池来提高mirror maker的吞吐量。在接受数据(messages)的broker上的producer是只使用单个线程来处理的。就算你有多个消费流,吞吐量也会在producer处理请求的时候被限制。
5. 消费流(consumption streams)数量
使用—num.streams可以指定consumer的线程数。请注意,如果你启动多个mirror maker进程,你可能需要看看其在源Kafka集群partitions的分布情况。如果在每个mirror maker进程上的消费流(consumption streams)数量太多,某些消费进程如果不拥有任何分区的消费权限会被置于空闲状态,主要原因在于consumer的负载均衡算法。
6. 浅迭代(Shallow iteration)与producer压缩
我们建议在mirror maker的consumer中开启浅迭代(shallow iteration)。意思就是mirror maker的consumer不对已经压缩的消息集(message-sets)进行解压,只是直接将获取到的消息集数据同步到producer中。
如果你开启浅迭代(shallow iteration),那么你必须关闭mirror maker中producer的压缩功能,否则消息集(message-sets)会被重复压缩。
7. Consumer 和 源Kafka集群(source cluster)的 socket buffer sizes
镜像经常用在跨集群场景中,你可能希望通过一些配置选项来优化内部集群的通信延迟和特定硬件性能瓶颈。一般来说,你应该对mirror-maker中consumer的socket.buffersize 和源集群broker的socket.send.buffer设定一个高的值。此外,mirror-maker中消费者(consumer)的fetch.size应该设定比socket.buffersize更高的值。注意,套接字缓冲区大小(socket buffer size)是操作系统网络层的参数。如果你启用trace级别的日志,你可以检查实际接收的缓冲区大小(buffer size),以确定是否调整操作系统的网络层。
三、如何检验MirrorMaker运行状况
Consumer offset checker工具可以用来检查镜像对源集群的消费进度。例如:
1 2 3 4 5 6 7 8 9 10 11 | bin/kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --group KafkaMirror --zkconnect localhost:2181 --topic test-topic KafkaMirror,topic1,0-0 (Group,Topic,BrokerId-PartitionId) Owner = KafkaMirror_jkoshy-ld-1320972386342-beb4bfc9-0 Consumer offset = 561154288 = 561,154,288 (0.52G) Log size = 2231392259 = 2,231,392,259 (2.08G) Consumer lag = 1670237971 = 1,670,237,971 (1.56G) BROKER INFO 0 -> 127.0.0.1:9092 |
注意,–zkconnect参数需要指定到源集群的Zookeeper。另外,如果指定topic没有指定,则打印当前消费者group下所有topic的信息。
参考文献
- http://kafka.apache.org/documentation.html#configuration
- https://cwiki.apache.org/confluence/display/KAFKA/Kafka+mirroring+(MirrorMaker)
来源: https://www.cnblogs.com/sunxucool/p/3913131.html


