Leveldb是一个google实现的非常高效的kv数据库,目前的版本1.2能够支持billion级别的数据量了。 在这个数量级别下还有着非常高的性能,主要归功于它的良好的设计。特别是LMS算法,但是Leveldb是单进程的服务,而且它只是一个 C/C++ 编程语言的库, 不包含网络服务封装, 所以无法像一般意义的存储服务器(如 MySQL)那样, 用客户端来连接它. LevelDB 自己也声明, 使用者应该封装自己的网络服务器.所以它只能做一个嵌入式数据来使用,目前淘宝的Tair系统将它做了封装。
下面是性能对比
Accumulo是一个使用谷歌BigTable的设计思路,基于Hadoop、Zookeeper和Thrift构建的,可靠的、可伸缩的、高性能的排序分布式KV数据存储系统。这个开源项目是由美国国家安全局开发,并于2011年发布的。目前,Accumulo属于Apache的顶级项目,它具有BigTable中所没有的一些功能,例如基于单元的访问控制。
下面我们看看Accumulo都有哪些主要特性:
1、对数据保护的安全性高
从下图可以清楚的看到Accumulo是如何控制单元的访问控制的。
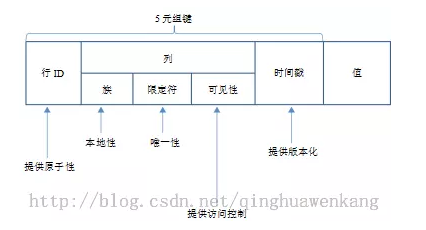
2、支持ACID原则
3、读写性能强
麻省理工2013的性能测试报告
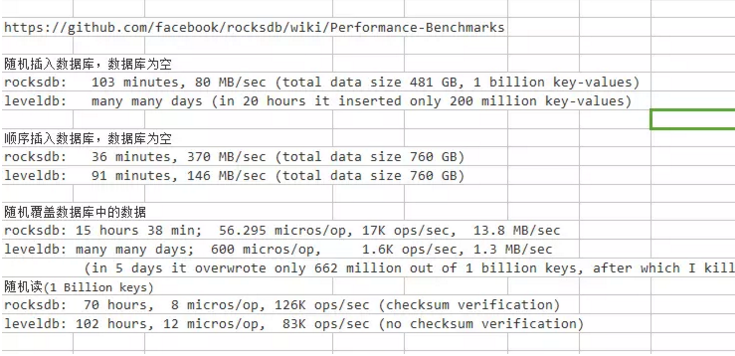
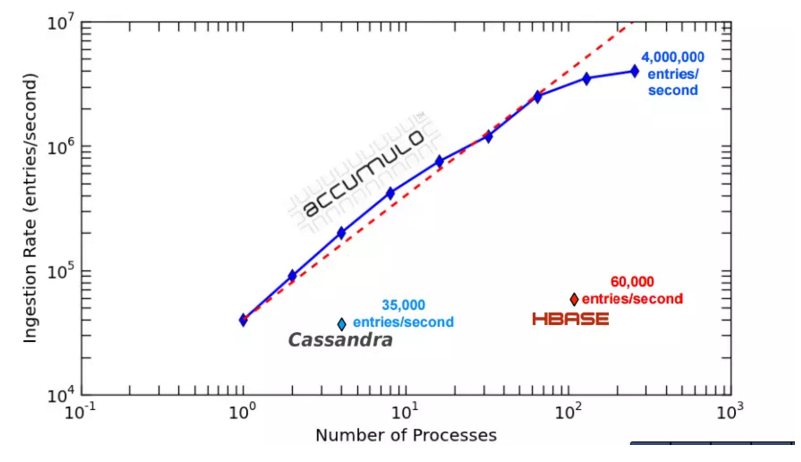
MIT Lincoln laboratories has recently released performance data for Apache Accumulo.In this paper MIT reached ~400,000 writes per second per node across an 8 node cluster.This is impressive performance given that MIT cites HBase as supporting ~60,000 writes per second per node and Cassandra as supporting ~35,000 writes per second per node.
在8节点集群的每个节点上,accumulo每秒达到40万次的写入,hbase达到6万次的写入,Cassandra达到3.5万次的写入。
为什么会写入这么快呢?原因如下:
因为accumulo使用了动态分布式空间数据模型(The Dynamic Distributed Dimensional Data Model (D4M)),Accumulo没有直接使用Hadoop的MapReduce并行编程模型,而是使用了pMatlab的并行编程环境。
4、分布式
Accumulo采用分布式存储。当Accumulo表不断的变大时,表会被自动分成块,数据可以存储在不同的块中。
5、分区
当表的容量达到上限时,accumulo会自动将表进行分割成默认的大小。
Accumulo的使用场景
目前,Accumulo都用在了政府的应用中,除政府之外的企业用的比较少。Cloudera公司已经将Accumulo 1.6.0的版本加入到了CDH 5.4.1中。此外,Hadoop系统打算用Accumulo解决储存海量数据的可扩展性。
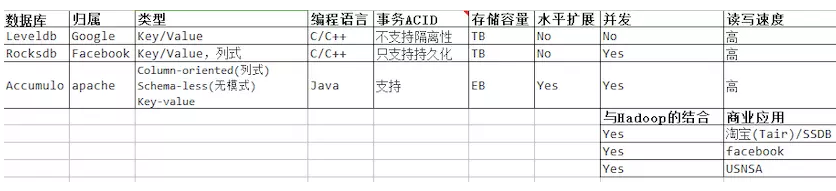
最后通过各维度的比较,三个数据库的对比为
参考的相关链接
来源:https://www.jianshu.com/p/4c57cd82ccde
-----------------
五分钟快速实现leveldb中数据的高可靠
==========================================
众所周知leveldb是Google的Sanjay Ghemawat和Jeff Dean两位大神编写的一个高性能KV引擎使用起来非常方便。然而开源版本的leveldb将所有数据存放在了本地磁盘如果本地磁盘发生故障可能导致部分甚至全部数据丢失(例如MANIFEST丢失)这对于使用者来说无疑会带来灾难性的后果。在这时数据的高可靠便成为了一个至关重要的问题本篇博文将带你五分钟快速实现leveldb中数据存储的高可靠。
百度开源的分布式文件系统BFS(开源地址:https://github.com/baidu/bfs)提供了mount工具可以将整个分布式文件系统直接挂载到本地目录从而可以像操作本地文件一样来操作分布式文件系统中的文件我们可以利用分布式文件系统本身提供的数据高可靠特性来保证leveldb中数据的安全。
1. 首先下载BFS源码
- git clone git@github.com:baidu/bfs.git
2. 然后编译所需要的二进制文件
- cd bfs; make && make bfs_mount
编译完成后会在当前目录下生成启动BFS所需要的nameserver、chunkserver二进制以及挂载工具bfs_mount
3. 启动BFS集群(本地模拟分布式环境)
- cd sandbox; ./depoly.sh; ./start_bfs.sh
执行成功后会在本地启动一个包含一个Nameserver4个Chunkserver的小集群其中Nameserver占用的端口为8827 4. 将BFS集群挂载到本地
- cd ../; mkdir bfs_dir; nohup ./bfs_mount -d ./bfs_dir -c localhost:8827 -p / 1>fuse_mount.log 2>&1 &
其中-d表示输出debug日志./bfs_dir表示将BFS挂载到本地的bfs_dir目录下-c localhost:8827指明了BFS集群的地址上一步中的start_bfs.sh会在本地的8827端口启动BFS的Nameserver-p /指定将BFS的根目录进行挂载
至此与BFS所做的相关准备工作已经全部完成~
接下来可以将自己程序中leveldb的数据写到BFS中如果有不熟悉leveldb的同学可以参考下面的使用示例
- #include <stdio.h>
- #include <leveldb/db.h>
- int main()
- {
- leveldb::DB* db_;
- leveldb::Options options;
- options.create_if_missing = true;
- leveldb::Status s = leveldb::DB::Open(options, "./bfs_dir/ldb_data/", &db_);
- if (!s.ok()) {
- printf("Open db fail\n");
- return -1;
- }
- std::string test_key("hello"), test_value("world");
- s = db_->Put(leveldb::WriteOptions(), test_key, test_value);
- if (!s.ok()) {
- printf("Write db fail\n");
- return -1;
- }
- return 0;
- }
到这里是不是有点小激动?即使本地磁盘挂掉BFS自动会进行副本恢复保证数据不丢失。
更重要的是只要在其它机器上同样挂载BFS相应目录便可以不需要任何代价的在另外的机器上对同样一个leveldb进行操作。(鉴于同一个leveldb同一时刻只允许被一个进程打开前提需要此机器已经正确的将自己打开的leveldb关闭)这样就相当于数据毫无代价的从一台机器『迁移』到了另外一台机器是不是很炫酷?可能有些同学发现了什么对其实BigTable的模型正是如此~ 如果有希望继续深入了解的同学可以移步百度开源的目前已经存储了万亿级别网页数据的分布式数据库Tera(开源地址:http://github.com/baidu/tera)正是通过类似的原理在保证数据安全的情况下可以实现快速的负载均衡***合并等特性。
---------------

