来源:互联网
最近也在做搜索相关的项目,一直关注Lucene 3.x 之后下一步的发展方向。我就把我了解到的Lucene 4.0的一些资料和大家分享一下。
大家都知道Lucene的作者是Doug Cutting ,这位博士毕业生因为工作不稳定,想学java,当他准备写个项目练练手的时候,也许他没想到这个以他外祖母的姓Lucene 命名的搜索引擎软件包会在此后的让他声名鹊起,并成为了中小型搜索引擎绝对主流的选择。
关于Lucene在国内流行的原因,请大家参考我2004年的一篇博客:为什么会是Lucene 。 http://blog.csdn.net/accesine960/article/details/227134
大概从Lucene 1.4.3 开始后的每次升级,我听到身边程序员抱怨最多的就是:API 改的太恶心了。的确每次升级API都是大幅度的变化,但这也正是Lucene开源社区活跃的表现。每个人都希望Lucene增加这样或者那样的功能,满足这样或者那样的需求。没错,Lucene 4.0 还将延续这种风格!
言归正传,Lucene 4.0 将会有如下翻天覆地的变化:
1、全部使用字节( utf-8 tytes )替代string来构建 term directory 。Mysql 有MyIsam ,Innodb 引擎,为什么Lucene不能有类似的引擎?
带来的好处是:索引文件读取速度 30 倍的提升;占用原来大约10%的内存;搜索过程由于去掉了字符串的转化速度也会明显提升;
但是如果说这上面的好处只是一个副产品,你会怎么想? 没错,Mysql有MyIsam,Innodb等诸多引擎供我们选择的,Lucene为什么不能向这个方向发展呢?
实现这个机制的模块叫:Codec (编码器),你可以实现自己的Codec来进行自定义的扩展,很显然Codec的操作对象是Segment 。
2、支持多线程建索引,支持:concurrent flushing。
了解过Lucene 3.X的同学们都知道,诸如XXXPerThread 的类在建索引的时候已经支持多线程了,但是当每个线程的内存达到指定上限 (maxBufferedDocs or ramMaxBufferSizeMB)的时候就需要写到硬盘上,而这个过程仍然不是多线程的,仍然需要一个个排队Flush到硬盘。Lucene 4.0 终于支持 concurrent flushing 了。
支持Concurrent Flushing听起来很酷,具体到Lucene 4.0 里,是增加了一个类来完成这个功能的。
先看以下类:DocConsumerPerThread , DocFieldConsumerPerThread , DocInverterPerThread , InvertedDocConsumerPerThread 。
觉得少了什么吗? 对,为什么没有 DocumentsWriterPerThread ,Lucene 4.0 的Concurrent Flushing 正是这个类来实现的。
图形化单线程Flushing和Concurrent Flushing的对比:
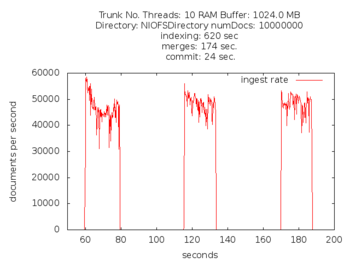

Luene 4.0 支持 Concurrent Flushing后最主要的问题是索引删除/修改的一致性的问题,这个问题比较复杂,不是本文的重点,就不细说了。
3、 基于有限自动机的模糊匹配算法(FSA算法),FuzzyQuery
FuzzyQuery 这类查询估计大家用的比较少。在英文中单词拼写错误,比如: Lucene, Licene , lucen 等就可以用FuzzyQuery来进行查询提高查全率。
在lucene 4.0 之前的FuzzyQuery 的实现非常耗费cpu,实现算法也很暴力。具体过程是:读取每个term,然后计算每个term与查询词的“编辑距离”,如果在指定的范围内则返回。
Lucene 4.0 使用 Levenshtein Automaton 的来衡量文字的"编辑距离" ,使用有限状态自动机来进行计算。以数百倍的效率提升了FuzzyQuery 的效率。
Levenshtein 距离我现在还不是很清楚。用单纯的有限状态机知识能大概理解其中的原理,如下图:
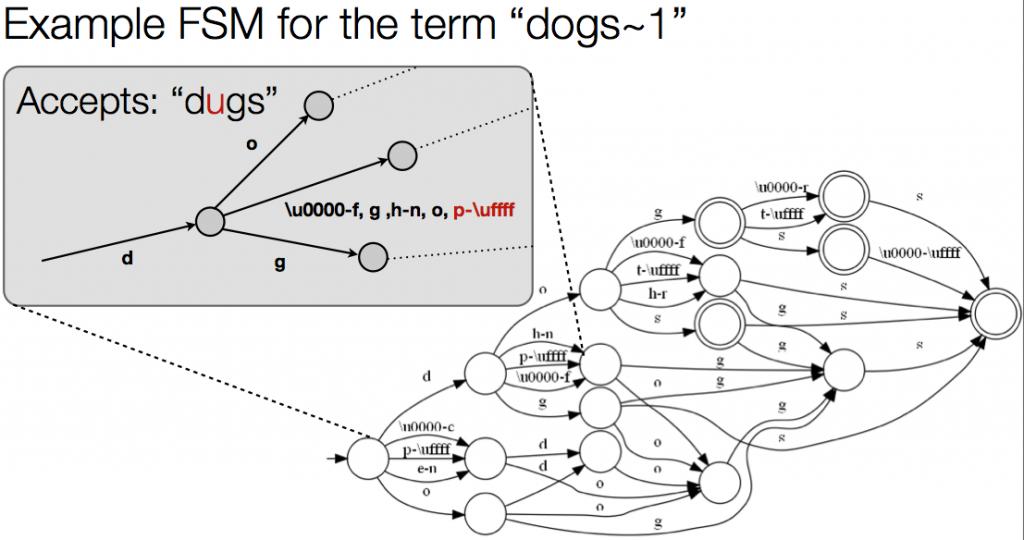
综上所述的3点是Lucene 4.0 众多新特性中最重要的部分,很值得大家期待。