前言
最近在学习 kubernetes 过程中,想实现 pod 数据的持久化。在调研的过程中,发现 ceph 在最近几年发展火热,也有很多案例落地企业。在选型方面,个人更加倾向于社区火热的项目,GlusterFS、Ceph 都在考虑的范围之内,但是由于 GlusterFS 只提供对象存储和文件系统存储,而 Ceph 则提供对象存储、块存储以及文件系统存储。怀着对新事物的向往,果断选择 Ceph 来实现 Ceph 块存储对接 kubernetes 来实现 pod 的数据持久化。
一、初始 Ceph
1.1 了解什么是块存储/对象存储/文件系统存储?
直接进入主题,ceph 目前提供对象存储(RADOSGW)、块存储RDB以及 CephFS 文件系统这 3 种功能。对于这3种功能介绍,分别如下:
1.对象存储,也就是通常意义的键值存储,其接口就是简单的GET、PUT、DEL 和其他扩展,代表主要有 Swift 、S3 以及 Gluster 等;
2.块存储,这种接口通常以 QEMU Driver 或者 Kernel Module 的方式存在,这种接口需要实现 Linux 的 Block Device 的接口或者 QEMU 提供的 Block Driver 接口,如 Sheepdog,AWS 的 EBS,青云的云硬盘和阿里云的盘古系统,还有 Ceph 的 RBD(RBD是Ceph面向块存储的接口)。在常见的存储中 DAS、SAN 提供的也是块存储;
3.文件存储,通常意义是支持 POSIX 接口,它跟传统的文件系统如 Ext4 是一个类型的,但区别在于分布式存储提供了并行化的能力,如 Ceph 的 CephFS (CephFS是Ceph面向文件存储的接口),但是有时候又会把 GlusterFS ,HDFS 这种非POSIX接口的类文件存储接口归入此类。当然 NFS、NAS也是属于文件系统存储;
1.2 Ceph 组件介绍
从下面这张图来简单学习下,Ceph 的架构组件。(提示:本人在学习过程中所绘,如果发现问题欢迎留言,不要喷我哟)

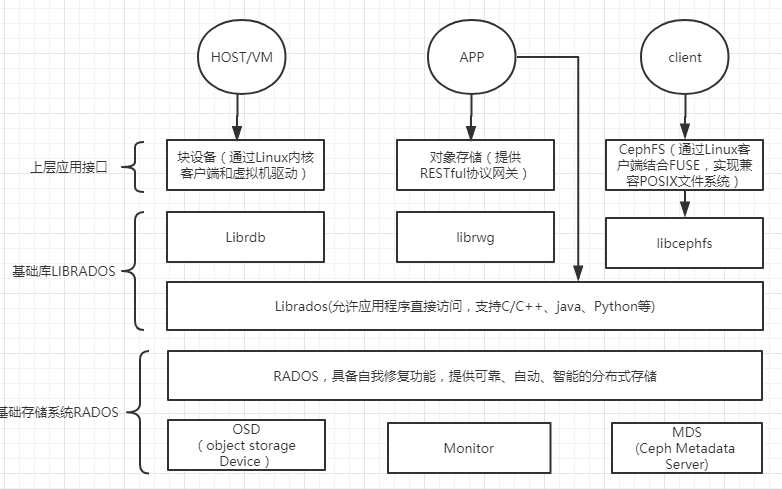
Monitor, 负责监视整个集群的运行状况,信息由维护集群成员的守护程序来提供,各节点之间的状态、集群配置信息。Ceph monitor map主要包括OSD map、PG map、MDS map 和 CRUSH 等,这些 map 被统称为集群 Map。ceph monitor 不存储任何数据。下面分别开始介绍这些map的功能:
- Monitor map:包括有关monitor 节点端到端的信息,其中包括 Ceph 集群ID,监控主机名和IP以及端口。并且存储当前版本信息以及最新更改信息,通过 "ceph mon dump" 查看 monitor map。
- OSD map:包括一些常用的信息,如集群ID、创建OSD map的 版本信息和最后修改信息,以及pool相关信息,主要包括pool 名字、pool的ID、类型,副本数目以及PGP等,还包括数量、状态、权重、最新的清洁间隔和OSD主机信息。通过命令 "ceph osd dump" 查看。
- PG map:包括当前PG版本、时间戳、最新的OSD Map的版本信息、空间使用比例,以及接近占满比例信息,同事,也包括每个PG ID、对象数目、状态、OSD 的状态以及深度清理的详细信息。通过命令 "ceph pg dump" 可以查看相关状态。
- CRUSH map: CRUSH map 包括集群存储设备信息,故障域层次结构和存储数据时定义失败域规则信息。通过 命令 "ceph osd crush map" 查看。
- MDS map:MDS Map 包括存储当前 MDS map 的版本信息、创建当前的Map的信息、修改时间、数据和元数据POOL ID、集群MDS数目和MDS状态,可通过"ceph mds dump"查看。
OSD,Ceph OSD 是由物理磁盘驱动器、在其之上的 Linux 文件系统以及 Ceph OSD 服务组成。Ceph OSD 将数据以对象的形式存储到集群中的每个节点的物理磁盘上,完成存储数据的工作绝大多数是由 OSD daemon 进程实现。在构建 Ceph OSD的时候,建议采用SSD 磁盘以及xfs文件系统来格式化分区。BTRFS 虽然有较好的性能,但是目前不建议使用到生产中,目前建议还是处于围观状态。
Ceph 元数据,MDS。ceph 块设备和RDB并不需要MDS,MDS只为 CephFS服务。
RADOS,Reliable Autonomic Distributed Object Store。RADOS是ceph存储集群的基础。在ceph中,所有数据都以对象的形式存储,并且无论什么数据类型,RADOS对象存储都将负责保存这些对象。RADOS层可以确保数据始终保持一致。
librados,librados库,为应用程度提供访问接口。同时也为块存储、对象存储、文件系统提供原生的接口。
ADOS块设备,它能够自动精简配置并可调整大小,而且将数据分散存储在多个OSD上。
RADOSGW,网关接口,提供对象存储服务。它使用librgw和librados来实现允许应用程序与Ceph对象存储建立连接。并且提供S3 和 Swift 兼容的RESTful API接口。
CephFS,Ceph文件系统,与POSIX兼容的文件系统,基于librados封装原生接口。
简单说下CRUSH,Controlled Replication Under Scalable Hashing,它表示数据存储的分布式选择算法, ceph 的高性能/高可用就是采用这种算法实现。CRUSH 算法取代了在元数据表中为每个客户端请求进行查找,它通过计算系统中数据应该被写入或读出的位置。CRUSH能够感知基础架构,能够理解基础设施各个部件之间的关系。并且CRUSH保存数据的多个副本,这样即使一个故障域的几个组件都出现故障,数据依然可用。CRUSH 算是使得 ceph 实现了自我管理和自我修复。
RADOS 分布式存储相较于传统分布式存储的优势在于:
1. 将文件映射到object后,利用Cluster Map 通过CRUSH 计算而不是查找表方式定位文件数据存储到存储设备的具体位置。优化了传统文件到块的映射和Block MAp的管理。
2. RADOS充分利用OSD的智能特点,将部分任务授权给OSD,最大程度地实现可扩展。
二、安装 Ceph
2.1 环境准备
## 环境说明
主机 IP 功能
ceph-node01 192.168.58.128 deploy、mon*1、osd*3
ceph-node02 192.168.58.129 mon*1、 osd*3
ceph-node03 192.168.58.130 mon*1 、osd*3
## 准备 yum 源
1 2 3 4 5 6 7 | cd /etc/yum.repos.d/ && sudo mkdir baksudo mv *.repo bak/sudo wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.reposudo wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.reposudo sed -i '/aliyuncs/d' /etc/yum.repos.d/CentOS-Base.reposudo sed -i '/aliyuncs/d' /etc/yum.repos.d/epel.reposudo sed -i 's/$releasever/7/g' /etc/yum.repos.d/CentOS-Base.repo |
## 添加 Ceph 源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | sudo cat <<EOF > /etc/yum.repos.d/ceph.repo[Ceph]name=Ceph packages for x86_64baseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/enabled=1gpgcheck=1type=rpm-mdgpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc[Ceph-noarch]name=Ceph noarch packagesbaseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/noarch/enabled=1gpgcheck=1type=rpm-mdgpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc[ceph-source]name=Ceph source packagesbaseurl=https://mirrors.aliyun.com/ceph/rpm-jewel/el7/SRPMS/enabled=1gpgcheck=1type=rpm-mdgpgkey=https://mirrors.aliyun.com/ceph/keys/release.ascEOF |
## 配置免密钥(略)
提示:如果使用普通用户进行安装,请授予用户相关权限,如下:
a. 将 yangsheng 用户加入到sudo权限(yangsheng ALL=(ALL) NOPASSWD: ALL)
b. 将 /etc/sudoers 中的 “Defaults requiretty” 注释
2.2 开始安装
## 安装部署工具(在 192.168.58.128 执行如下操作)
1 2 3 4 5 | yum makecacheyum -y install ceph-deployceph-deploy --version1.5.39 |
## 初始化monitor
1 2 | mkdir ceph-cluster && cd ceph-clusterceph-deploy new ceph-node01 ceph-node02 ceph-node03 |
根据自己的IP配置向ceph.conf中添加public_network,并稍微增大mon之间时差允许范围(默认为0.05s,现改为2s):
1 2 3 4 5 | # change default replica 3 to 2osd pool default size = 2public network = 192.168.58.0/24cluster network = 192.168.58.0/24 |
## 安装 ceph
1 | ceph-deploy install ceph-node01 ceph-node02 ceph-node03 |
## 开始部署monitor
1 2 3 4 5 | ceph-deploy mon create-initial[root@ceph-node01 ceph]# lsceph.bootstrap-mds.keyring ceph.bootstrap-osd.keyring ceph.client.admin.keyring ceph-deploy-ceph.log rbdmapceph.bootstrap-mgr.keyring ceph.bootstrap-rgw.keyring ceph.conf ceph.mon.keyring |
查看集群状态
1 2 3 4 5 6 7 8 9 10 11 | [root@ceph-node01 ceph]# ceph -s cluster b5108a6c-7e3d-4295-88fa-88dc825be3ba health HEALTH_ERR no osds monmap e1: 3 mons at {ceph-node01=192.168.58.128:6789/0,ceph-node02=192.168.58.129:6789/0,ceph-node03=192.168.58.130:6789/0} election epoch 6, quorum 0,1,2 ceph-node01,ceph-node02,ceph-node03 osdmap e1: 0 osds: 0 up, 0 in flags sortbitwise,require_jewel_osds pgmap v2: 64 pgs, 1 pools, 0 bytes data, 0 objects 0 kB used, 0 kB / 0 kB avail 64 creating |
提示:Monitor创建成功后,检查集群的状态,此时集群状态并不处于健康状态。
## 开始部署OSD
1 2 3 4 5 6 7 8 9 | ### 列出节点所有磁盘信息ceph-deploy disk list ceph-node01 ceph-node02 ceph-node03### 清除磁盘分区和内容ceph-deploy disk zap ceph-node01:sdb ceph-node02:sdb ceph-node03:sdb### 分区格式化并激活ceph-deploy osd create ceph-node01:sdb ceph-node02:sdb ceph-node03:sdbceph-deploy osd activate ceph-node01:sdb ceph-node02:sdb ceph-node03:sdb |
此时,再次查看集群状态
1 2 3 4 5 6 7 8 9 10 | [root@ceph-node01 ceph-cluster]# ceph -s cluster 86fb7c8b-9ad1-4eaf-a24c-0d2d9f36ab29 health HEALTH_OK monmap e2: 3 mons at {ceph-node01=192.168.58.128:6789/0,ceph-node02=192.168.58.129:6789/0,ceph-node03=192.168.58.130:6789/0} election epoch 6, quorum 0,1,2 ceph-node01,ceph-node02,ceph-node03 osdmap e15: 3 osds: 3 up, 3 in flags sortbitwise,require_jewel_osds pgmap v32: 64 pgs, 1 pools, 0 bytes data, 0 objects 100 MB used, 45946 MB / 46046 MB avail 64 active+clean |
2.3 清理环境
如果之前部署失败了,不必删除ceph客户端,或者重新搭建虚拟机,只需要在每个节点上执行如下指令即可将环境清理至刚安装完ceph客户端时的状态!强烈建议在旧集群上搭建之前清理干净环境,否则会发生各种异常情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 | sudo ps aux|grep ceph | grep -v "grep"| awk '{print $2}'|xargs kill -9sudo ps -ef|grep cephsudo umount /var/lib/ceph/osd/*sudo rm -rf /var/lib/ceph/osd/*sudo rm -rf /var/lib/ceph/mon/*sudo rm -rf /var/lib/ceph/mds/*sudo rm -rf /var/lib/ceph/bootstrap-mds/*sudo rm -rf /var/lib/ceph/bootstrap-osd/*sudo rm -rf /var/lib/ceph/bootstrap-rgw/*sudo rm -rf /var/lib/ceph/tmp/*sudo rm -rf /etc/ceph/*sudo rm -rf /var/run/ceph/* |
三、配置客户端
3.1 安装客户端
1 2 | ssh-copy-id 192.168.58.131ceph-deploy install 192.168.58.131 |
将Ceph 配置文件复制到 192.168.58.131。
1 | ceph-deploy config push 192.168.58.131 |
3.2 新建用户密钥
客户机需要 ceph 秘钥去访问 ceph 集群。ceph创建了一个默认的用户client.admin,它有足够的权限去访问ceph集群。但是不建议把 client.admin 共享到所有其他的客户端节点。这里我用分开的秘钥新建一个用户 (client.rdb) 去访问特定的存储池。
1 | ceph auth get-or-create client.rbd mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=rbd' |
为 192.168.58.131 上的 client.rbd 用户添加秘钥
1 | ceph auth get-or-create client.rbd | ssh 192.168.58.131 tee /etc/ceph/ceph.client.rbd.keyring |
到客户端(192.168.58.131)检查集群健康状态
1 2 3 4 5 6 7 8 9 10 11 | [root@localhost ~]# cat /etc/ceph/ceph.client.rbd.keyring >> /etc/ceph/keyring[root@localhost ~]# ceph -s --name client.rbd cluster 86fb7c8b-9ad1-4eaf-a24c-0d2d9f36ab29 health HEALTH_OK monmap e2: 3 mons at {ceph-node01=192.168.58.128:6789/0,ceph-node02=192.168.58.129:6789/0,ceph-node03=192.168.58.130:6789/0} election epoch 6, quorum 0,1,2 ceph-node01,ceph-node02,ceph-node03 osdmap e15: 3 osds: 3 up, 3 in flags sortbitwise,require_jewel_osds pgmap v32: 64 pgs, 1 pools, 0 bytes data, 0 objects 100 MB used, 45946 MB / 46046 MB avail 64 active+clean |
3.3 创建块设备
1 2 | rbd create foo --size 4096 --name client.rbd # 创建一个 4096MB 大小的RADOS块设备rbd create rbd01 --size 10240 --name client.rbd # 创建一个 10240MB 大小的RADOS块设备 |
映射块设备
1 2 3 | [root@localhost ceph]# rbd create rbd02 --size 10240 --image-feature layering --name client.rbd[root@localhost ceph]# rbd map --image rbd02 --name client.rbd /dev/rdb02/dev/rbd0 |
提示:在 映射块设备的时候,发生了如下错误。
1 2 3 4 5 | [root@localhost ceph]# rbd map --image rbd01 --name client.rbd /dev/rdb01rbd: sysfs write failedRBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable".In some cases useful info is found in syslog - try "dmesg | tail" or so.rbd: map failed: (6) No such device or address |
解决该办法有多种方式,分别如下所示:
1. 在创建的过程中加入如下参数 "--image-feature layering" 也解决该问题。
2. 手动disable 掉相关参数,如下所示:
1 | rbd feature disable foo exclusive-lock, object-map, fast-diff, deep-flatten |
3. 在每个 ceph 节点的配置文件中,加入该配置项 "rbd_default_features = 1"。
3.4 检查被映射的块设备
1 2 3 | [root@localhost ceph]# rbd showmapped --name client.rbdid pool image snap device 0 rbd rbd02 - /dev/rbd0 |
创建并挂载该设备
1 2 3 4 | fdisk -l /dev/rbd0mkfs.xfs /dev/rbd0mkdir /mnt/ceph-disk1mount /dev/rbd1 /mnt/ceph-disk1 |
验证
1 2 3 | [root@localhost ceph]# df -h /mnt/ceph-disk1/文件系统 容量 已用 可用 已用% 挂载点/dev/rbd0 10G 33M 10G 1% /mnt/ceph-disk1 |
一个 ceph 块设备就创建完成。
来源: https://www.cnblogs.com/yangxiaoyi/p/7795274.html
另附 一些 配置文档
本文档适用于特定版本的ceph源码,对于不同版本可能有不同的依赖库,或配置步骤可能略有不同。
Ceph配置分为client和其他(monitor,mds,osd)两部分,其中client已经集成在2.6.34及其以后的内核版本中,故只需下载新内核版本编译内核即可;其他部分则用到了ceph源码包(从官网获得),其中有些依赖库,详细步骤见第二节。
Ceph集群简介:
Monitor线程处理集中的集群管理,配置和状态监控。他们是相对来说较轻的线程,用到的数据保存在本地文件系统。需要注意的是,监控线程必须有奇数个。
Ceph中的元数据服务器(mds)本质上就是一个满足一致性的分布式元数据缓存,所有的元数据都保存在存储节点上。元数据服务器(线程)能根据需要任意地加入到集群中,负载会自动的在这些服务器间进行平衡。例如可以先启动1到2个,然后根据需要再增加。配置文件中max mds参数控制最多有多少活动线程,额外的线程处于standby状态,如果有活动线程出故障了则standby状态的线程取代之。
Osd是存储数据和元数据的实际存储节点,最好运行两个osd,其中一个作为另一个的备份。每个osd其实就是一个线程,提供访问本地磁盘的服务。Osd端本地的文件系统最好用BTRFS,但是其他文件系统如ext3也可以。
2.配置步骤
除client以外其他节点的配置
1)下载ceph源码(http://ceph.newdream.net/download/)这里选择较早版本 ceph-0.20.tar.gz为了涉及尽量少的依赖库。
2)安装libedit_devel库,命令如下:
rpm -Uvh http://dev.CentOS.org/centos/5/testing/x86_64/RPMS/libedit-3.0-2.20090905cvs.el5.centos.x86_64.rpm
rpm -Uvh http://dev.centos.org/centos/5/testing/x86_64/RPMS/libedit-devel-3.0-2.20090905cvs.el5.centos.x86_64.rpm
注:这里可以直接运行上述命令,前提是机器能上网,如果不能的话可以自己下载两个rpm包然后手动安装。
3)解压源码
Tar -zvxf ceph-0.20.tar.gz
4)进入源码目录并执行如下操作(蓝色部分为命令)
# ./autogen.sh
# CXXFLAGS="-g -O2" ./configure --prefix=/usr --sbindir=/sbin --localstatedir=/var --sysconfdir=/etc
# make && make install
Ceph环境配置文档 PDF版下载:
免费下载地址在 http://linux.linuxidc.com/
用户名与密码都是www.linuxidc.com
具体下载目录在 /2013年资料/5月/31日/Ceph环境配置文档 PDF
或者百度网盘下载:http://pan.baidu.com/share/link?shareid=510183&uk=1983309261




