在数据分析的招聘中,SQL是必考的能力之一。为什么公司要考察应聘者的SQL能力呢?
Excel对十万条以内的数据处理起来没有问题,但是大数据时代从来就不缺数据,很多公司的数据都放在数据库中,这时候就需要学习操作数据库的语言SQL。那么,什么是数据库呢?
一、什么是数据库?
大家都有过下面的经历吧?
- 在银行的存取款机里面存取现金
- 通过手机中的手机簿来存储亲朋好友的联系方式
- 利用电脑中百度搜索查询问题
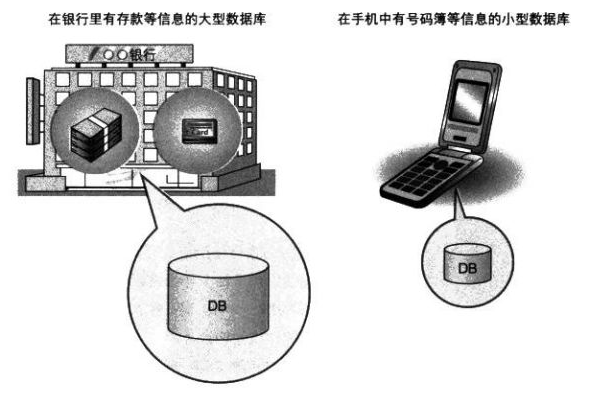
数据库就是存储数据的地方,就像冰箱是存储食物的地方一样。正是因为有了数据库后,所有人可以直接在这个系统上查找数据和修改数据。例如你每天使用余额宝查看自己的账户收益,就是从后台数据库读取数据后给你的。因此,像这样将大量数据保存起来,通过计算机加工而成的可以进行高效访问的数据集合称为数据库(Datebase,DB)。
其实大到银行账户的管理,小到手机的号码簿,可以说社会的所有系统中都有数据库的身影。由于系统的使用者通常无法直接接触到数据库,所以就产生了用来管理数据库的计算机系统,称为数据库管理系统(Datebase Management System,DBMS)。
当然,数据库管理系统(DBMS)有很多种类,比如关系型数据库、层次型数据库、面向对象数据库等。其中关系型数据库是现在应用最广泛的数据库。关系数据库采用行列二维表结构来管理数据,同时使用专门的SQL(Structured Query Language,结构化查询语言)语言对数据进行操作。所以,这种类型的DBMS称为关系数据库管理系统(简称RDBMS)。比较具有代表性的RDBMS有如下五种:
- Oracle Datebase:甲骨文公司的RDBMS
- SQL Server:微软公司的RDBMS
- DB2:IBM公司的RDBMS
- PostgreSQL:开源的RDBMS
- MySQL:开源的RDBMS
现在很多公司和企业对MySQL用的较多,所以如果想成为数据分析师,就需要利用SQL操作开关系数据库MySQL进行查询,掌握数据库的分组、聚合、排序,并且对于增删改、约束、索引、数据库范式均需要了解。因此,接下来我们学习关系数据库MySQL以及其SQL语言。
二、如何安装数据库?
MySQL是一个关系型数据库软件,由瑞典MySQL AB公司开发,目前属于Oracle公司。为什么使用Mysql:
1)Mysql是开源的,所以你不需要支付额外的费用就能使用。
2)Mysql支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
3)MySQL使用标准的SQL数据语言形式。
4)Mysql可以允许于多个系统上,并且支持多种语言。这些编程语言包括R、Python、Java、PHP、、Ruby等。
当然,Mysql分为服务端安装和客户端安装。Mysql服务端是数据库软件本身用于存放数据。mysql客户端工具用于从服务端获取数据。
①服务端安装教程:Mysql安装教程
②客户端安装教程:Mysql客户端安装教程
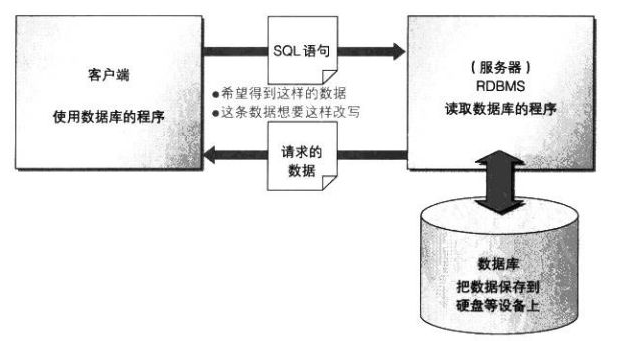
三、数据库MySQL和SQL语言
在学习数据库之前,我们先要弄清楚数据库和SQL是什么关系。数据库里面存放着数据,而SQL则是用来操作数据库里数据的语言(工具)。通俗地讲,比如有一碗米饭(碗就是mysql,里面放的米是数据),你要吃碗里的米饭,拿什么吃?拿筷子(sql)。用筷子(sql)操作碗里(mysql)的米饭(数据)。
对于学习MySQL数据库的方法,我认为有两种,一种是通过看书学习,另一种是通过网站学习。
1)书籍学习:比较好的书籍有《SQL必知必会》、《SQL基础教程》。但是对于零基础的朋友来说Mick的《SQL基础教程》更容易看懂学会,非常适合入门者学习。如果只推荐一本书的话,我比较倾向于这本。
2)网站学习:网上关于MySQL数据库的学习有很多,比如MySQL教程——易百教程、MySQL教程——RUNOOB.COM等。这些网站教程各有千秋,因此只有找到最适合自己的,才是最好的。
四、如何学习SQL语言(一周学会SQL)
在此,对于零基础的朋友来说Mick的《SQL基础教程》更容易看懂学会,非常适合入门者学习。该书共有八个章节,分别是数据库和SQL、查询基础、聚合与排序、数据更新、复杂查询、(函数、谓词、case表达式)、聚合运算以及SQL高级处理。其中第八章——SQL高级处理在该书中只能适用于PostgreSQL数据库,故而第八章暂时不学,只学前七章。
因此,可以定下一个学习目标(一周学完《SQL基础教程》):
第一天:学习数据库和SQL
第二天:学习查询基础
第三天:学习聚合与排序
第四天:学习数据更新
第五天:学习复杂查询
第六天:学习函数、谓词、case表达式
第七天:学习聚合运算
1、第一天:学习数据库和SQL
1)SQL概要
根据对RBDMS赋予的指令种类不同,SQL语句可以分为三类:
①数据定义语言(Data Definition Language,DDL):用来创建或删除存储数据用的数据库及数据库中的表等对象。包含以下几个命令:CREATE(创建数据库或表等对象),DROP(删除数据库或表等对象),ALTER(修改数据库或表等对象的结构)。
②数据操作语言(Data Manipulation Language,DML):用来查询或变更表中的记录。包含以下几个命令:SELECT(查询表中的数据),INSERT(向表中插入新数据),UPDATE(变更表中的数据),DELETE(删除表中的数据)。
③数据控制语言(Data Control Language,DCL):用来确认或取消对数据库中的数据进行变更,还可以对RDMS的用户是否有权限操作数据库中的对象进行设定。包括以下几个命令:COMMIT(确认对数据库中的数据进行变更),ROLLBACK(取消对数据库中的数据进行变更),GRANT(赋予用户操作权限),REVOKE(取消用户的操作权限)。
2)SQL基本书写规则
①SQL语句以分号(;)结尾。
②SQL语句不区分大小写(推荐:关键字大写,表名首字母大写,其余(列名等)小 写),但插入表中的数据的区分大小写的。
③常数的书写方式是固定的(除数字常数外,其它类型的常数(如:字符串、日期等)都要使用单引号来标识)。
④单词之间需要用半角空格或换行符来分隔(注意不能使用全角空格,不能在两个子句之间插入空行)(所谓半角空格、全角空格是指输入的格式)。
3)数据库的创建和表的创建
※背景为橙黄色表示SQL语句的语法结构,背景为淡灰色表示SQL语句实例
①数据库的创建:CREATE DATABASE 数据库名 ;
如:CREATE DATABASE Shop;数据库的使用:USE 数据库名 ;
如:USE Shop;②表的创建:
CREATE TABLE 表名
(列名1 数据类型 该列所需约束,
列名2 数据类型 该列所需约束,
......
该表的约束1,该表的约束2,......
);
如:创建商品表Shohin
CREATE TABLE Shohin
(
shohin_id CHAR(4) PRIMARY KEY NOT NULL,
shohin_mei VARCHAR(100) NOT NULL,
shohin_bunrui VARCHAR(32) NOT NULL,
hanbai_tanka INTEGER,
shiire_tanka INTEGER,
torokubi DATE
);③命名规则
- 只能使用半角英文字母、数字、下划线(_)作为数据库、表和列的名称,且必须以英文字母开头。
- 同一数据库中不能创建两个同名表,同一表中不能创建两个同名列。
④数据类型的指定
所有的列都必须指定数据类型,且每一列都不能存储与该列数据类型不符的数据。SQL的四种基本数据类型如下:
- INTEGER型:用于存放整数型的数据,不能存储小数
- CHAR型:字符串以定长字符串的形式存储;如,CHAR(8):8表示字符串的最大长度,超过部分无法输入,不足部分用空格补足
- VARCHAR型:字符串以可变长字符串的形式存储(与CHAR的区别在于:未到达最大长度时不会用空格补足)
- DATE型:存储日期的数据类型
- NUMBERIC型:NUMBERIIC(全体位数,小数位数)的形式来指定数值的大小(大多数DBMS适用)
⑤ 约束设置
约束:除数据类型外,对列中存储的数据进行限制或追加条件的功能。
常见的约束设置有,在数据类型右边设定 NOT NULL 或 NULL 或 DEFAULT等;
对表的约束设置有,PRIMARY KEY(主键约束)、外键约束、check约束、唯一性约束等。
4)表的删除、更新与插入
- 表的删除:删除的表是无法恢复的
DROP TABLE 表名
如:删除Shohin表
DROP TABLE Shohin;- 表定义的更新:表定义变更后无法恢复
ALTER TABLE 表名 ADD COLUMN 列名 数据类型 约束
如:向表中添加一列
ALTER TABLE Shohin ADD COLUMN shohin_mei_kana VARCHAR(100);ALTER TABLE 表名 DROP COLUMN 列名
如:从表中删除添加的列
ALTER TABLE Shohin DROP COLUMN shohin_mei_kana;- 向表中插入数据:
START TRANSACTION;
INSERT INTO 表名 VALUES (值1,值2, ...),
(值1,值2,...),
...
(值1,值2,...);
COMMIT;
如:向表Shohin中插入数据
START TRANSACTION;
INSERT INTO Shohin
VALUES ('0001','T恤','衣服',1000,500,'2009-09-20'),
('0002','打孔器','办公用品',500,320,'2009-09-11'),
('0003','运动T恤','衣服',4000,2800,NULL),
('0004','菜刀','厨房用具',3000,2800,'2009-09-20'),
('0005','高压锅','厨房用具',6800,5000,'2009-01-15'),
('0006','叉子','厨房用具',500,NULL,'2009-09-20'),
('0007','擦菜板','厨房用具',880,790,'2008-04-28'),
('0008','圆珠笔','办公用品',100,NULL,'2009-11-11');
COMMIT;- 变更表名:
ALTER TABLE 旧表名 RENAME TO 新表名
如:ALTER TABLE sohin RENAME TO shohin;2、第二天:学习查询基础
1)SELECT语句基础
①列的查询:通过SELECT 语句查询并选取出必要数据的过程称为匹配查询或查询。
SELECT的基本语句:
SELECT 列名1,... FROM 表名;
解释1:SELECT子句中列举了希望从表中查询出的列的名称,其顺序可以任意指定,多个列名直接用逗号分隔排列,查询结果中列的顺序与其子句顺序相同。当要查询全部列时,可以用星号(*)表示。使用星号时,就无法设定列的显示顺序了。
如:查询是商品表Shohin中的shohin_id列、shohin_mei列、shiire_tanka列的信息
SELECT shohin_id,shohin_mei,shiire_tanka FROM Shohin;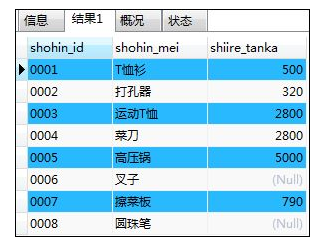
②查询全部列
SELECT * FROM 表名
解释2:FROM子句指定了选取出数据的表的名称
如:查询商品表Shohin的全部信息
SELECT * FROM Shohin;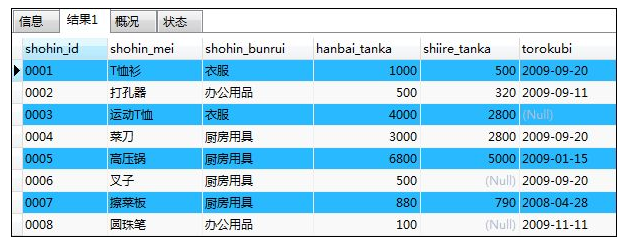
③为列设定别名:使用关键字 AS,设定汉语别名时要用双引号(" ")括起来
SELECT 列名 AS 列别名 FROM 表名
如:为查询列设定别名
SELECT shohin_id AS "商品编号",shohin_mei AS "商品名称",shiire_tanka AS "进货单价"
FROM Shohin;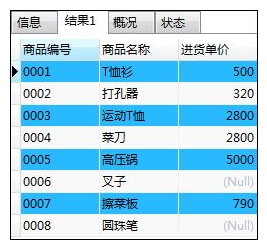
④常数的查询:
SELECT '字符串常数' AS 别名, 数字常数 AS 别名, '日期常数' AS 别名 FROM 表名;
如:查询常数
SELECT '商品' AS mojiretsu,38 AS kaza,'2009-02-24' AS hizuke,
shohin_id,shohin_mei
FROM shohin;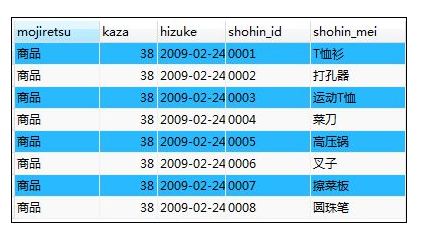
⑤从结果中删除重复行:在SELECT子句中使用DISTINCT。
SELECT DISTINCT 列名 FROM 表名;
如:使用distinct删除shohin_bunrui列中的重复数据
SELECT DISTINCT shohin_bunrui FROM shohin;
注意:在使用DISTINCT时,NULL也被视为一类数据。
如:对含有null数据的列使用distinct关键字
SELECT DISTINCT shiire_tanka FROM shohin;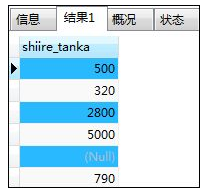
在多个列之前使用,此时会将多个列的数据进行组合,将重复的数据结合为一条。DISTINCT只能用在第一个列名之前。
如:对含有null数据的列使用distinct关键字
SELECT DISTINCT shiire_tanka FROM shohin;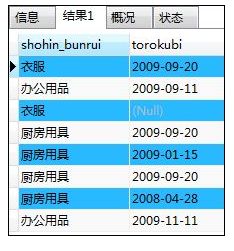
⑥根据WHERE语句来选择记录:WHERE子句可以指定“某一列的值和这个字符串相等”或者“某一列的值大于这个数字”等条件。
SELECT语句中的WHERE子句语法:
SELECT 列名1,列名2,...
FROM 表名
WHERE 表达式条件;
如:选取出hanbai_tanka列为500的记录
SELECT * FROM shohin
WHERE hanbai_tanka=500;
如:选取出hanbai_tanka列不为500的记录
SELECT * FROM shohin
WHERE hanbai_tanka <> 500;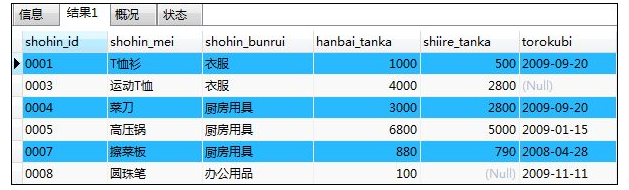
解释:首先通过WHERE子句查询出符合指定条件的记录,然后再取出SELECT语句指定的列
注意:SQL中子句的书写顺序是固定的,不能随意更改。即WHERE子句要紧跟在FROM子句之后。
⑦关于SQL语句的注释:
单行注释:将注释内容写在“ -- ”之后
多行注释:将注释内容写在“ /* ”和“ */ ”之间
2)算术运算符和比较运算符
①算术运算符:使用其两边的值进行四则运算(+、-、*、/)或者字符串拼接、数值大小比较等运算,并返回结果的符号。运算是以行为单位进行的。也可以使用括号来提升表达式的优先级。
如:将表Shop中的hanbai_tanka乘以2
SELECT shohin_mei,hanbai_tanka,
hanbai_tanka*2 AS "hanbai_tanka_x2"
FROM shohin;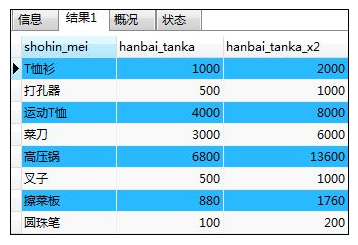
注意:所有包含NULL的计算,结果肯定为NULL
如:不含from的select语句
SELECT (100+200)*3 AS heisan;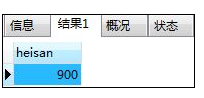
②比较运算符:像符号=、< >(不等于)、<=、<、>=、>这样用来比较其两边的列或者值的符号,几乎所有数据类型(字符、数字、日期等)的列和值都可以用比较运算符进行比较,当然也可以对计算结果进行比较。
如:选取销售单价大于等于1000日元的记录
SELECT * FROM shohin
WHERE hanbai_tanka >= 1000;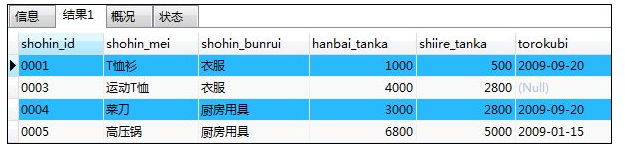
如:选取登记日期在2009年9月27日之前的记录
SELECT * FROM shohin
WHERE torokubi < '2009-09-27';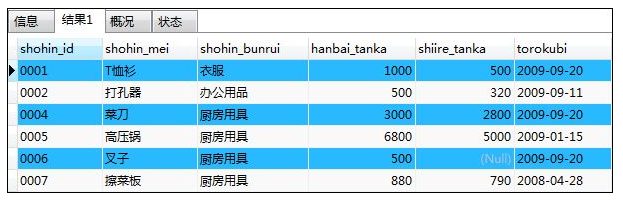
如:选取销售单价减去进货单价的值大于等于500日元的记录
SELECT shohin_mei,hanbai_tanka,shiire_tanka FROM shohin
WHERE hanbai_tanka-shiire_tanka >=500;
③对字符串使用不等号时的注意事项:对字符串类型的数据进行大小比较时,使用的是和数字比较不同的规则,典型的规则就是按照字典顺序进行比较。
→DDL:创建表
CREATE TABLE Chars
(chr CHAR(3) NOT NULL PRIMARY KEY);→DML:插入数据
START TRANSACTION;
INSERT INTO Chars VALUES ('1'),('2'),('3'),('10'),('11'),('222');
COMMIT;如:选取大于‘2’的数据
SELECT chr FROM Chars
WHERE chr > '2';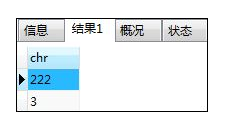
解释:因为其按照字典顺序进行比较,所以输出结果只显示:3,222
④不能对NULL使用比较运算符,SQL提供了专门用来判断是否为NULL的运算符IS NULL;希望选取不是NULL的记录时,需要使用IS NOT NULL。
如:选取进货单价为2800日元的记录
SELECT shohin_mei,shiire_tanka FROM shohin
WHERE shiire_tanka=2800;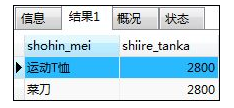
如:选取进货单价不是2800日元的记录
SELECT shohin_mei,shiire_tanka FROM shohin
WHERE shiire_tanka <>2800;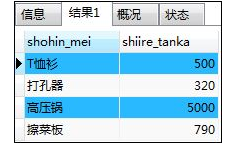
如:没有发现叉子和圆珠笔的记录,因此若要查询:
SELECT shohin_mei,shiire_tanka FROM shohin
WHERE shiire_tanka IS NULL;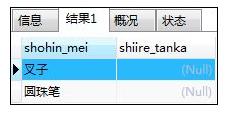
如:选取不为null的记录
SELECT shohin_mei,shiire_tanka FROM shohin
WHERE shiire_tanka IS NOT NULL;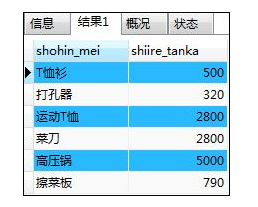
3)逻辑运算符
①NOT运算符:表示否定,不能单独使用,必须和其他查询条件组合起来使用,不要滥用。
如:选取销售单价大于等于1000日元的记录,添加not运算符后
SELECT shohin_mei,shohin_bunrui,hanbai_tanka FROM shohin
WHERE NOT hanbai_tanka >= 1000;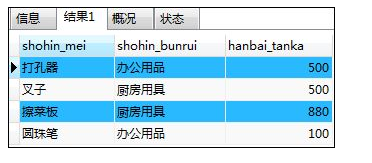
如:选取销售单价小于1000日元的记录
SELECT shohin_mei,shohin_bunrui,hanbai_tanka FROM shohin
WHERE hanbai_tanka < 1000;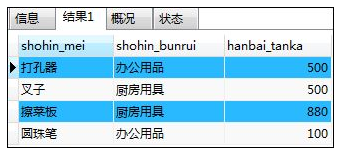
解释:发现这两种方法的结果都是一样的
②AND运算符和OR运算符:主要用于多个查询条件进行组合时,AND运算符在其两侧的查询条件都成立时整个查询条件才成立,为交集的效果(又称逻辑积运算)。
如:选出shohin表中产品名为“厨房用具”且销售价格大于等于3000日元的记录
SELECT shohin_mei,shiire_tanka,hanbai_tanka FROM shohin
WHERE shohin_bunrui='厨房用具' AND hanbai_tanka >= 3000;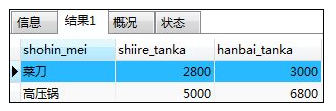
③OR运算符在其两侧的查询条件有一个成立时整个查询条件都成立,为并集的效果(又称逻辑和运算)
如:选出shohin表中产品名为“厨房用具”或销售价格大于等于3000日元的记录
SELECT shohin_mei,shiire_tanka,hanbai_tanka FROM shohin
WHERE shohin_bunrui='厨房用具' OR hanbai_tanka >= 3000;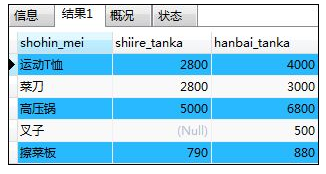
注意:AND的运算优先级高于OR,如果要先优先执行OR运算只能通过添加括号。
如:多条件查询
SELECT shohin_mei,shohin_bunrui,torokubi FROM shohin
WHERE shohin_bunrui='办公用品'
AND (torokubi = '2009-09-11' OR torokubi = '2009-09-20');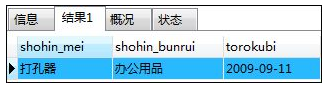
④逻辑运算符和真值:真值,即值为真(TRUE)或假(FALSE)之一,在SQL中还存在“不确定(UNKNOWN)”这样的值。AND运算符两侧都为真时,结果为真,否则为假;OR运算符两侧都为假时,结果为假,否则为真;NOT运算符单纯的取反,即将真转换为假,将假转换为真。当与NULL进行逻辑运算时,其结果为不确定。
3、第三天:学习聚合与排序
1)对表进行聚合查询
①聚合函数:通过SQL对数据进行某种操作或计算是需要使用的函数,常见的聚合函数(或称为合计函数)如下:
- COUNT:计算表中的记录数(行数);
- SUM:计算表中数值列的数据合计值;(只适用于数值类型)
- AVG:计算表中数值列的数据平均值;(只适用于数值类型)
- MAX:求出表中任意列中数据的最大值;(适用于所有数据类型)
- MIN:求出表中任意列中数据的最小值;(适用于所有数据类型)
※聚合函数会将NULL排除在外。
②计算表中数据的行数:参数列不同计算结果也会发生变化
如:计算全部数据行数
SELECT COUNT(*) '行数' FROM shohin;
解释:此语句的执行结果包含了空值的行。
注意:其它聚合函数都不能以星号作为参数。
如:计算null之外的数据行数
SELECT COUNT(shiire_tanka) '行数' -- 没有计算null的两列
FROM shohin;
解释:此语句的执行结果为统计“shiire_tanka”的行数,不包含该列名中的NULL;
③计算合计值:SELECT SUM(列名) FROM 表名;
如:计算销售单价的合计值
SELECT SUM(hanbai_tanka) '销售总价',SUM(shiire_tanka) '进货总价' -- NULL在计算时被忽略了
FROM shohin;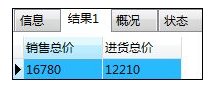
解释:求出“hanbai_tanka”列所有非空值的和
④计算平均值:SELECT AVG(列名) FROM 表名;
若要计算包含NULL的平均值则:
如:计算销售单价的平均值
SELECT AVG(hanbai_tanka) '销售均价',AVG(shiire_tanka) '进货均价' -- 第二个分母为6,忽略null
FROM shohin;
解释:第一个求计算“hanbai_tanka列所有非空值的平均值”,第二个求计算包含NULL的平均值
⑤计算最大值和最小值:SELECT MAX(列名1),MIN(列名2) FROM 表名;
解释:找出列名1的最大值,列名2的最小值
如:计算销售单价的最大值和进货单价的最小值
SELECT MAX(hanbai_tanka) '最大销售价',MIN(shiire_tanka) '最小进货价' -- 忽略null
FROM shohin;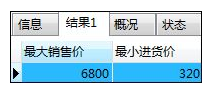
如:计算登记日期的最大值与最小值
SELECT MAX(torokubi) '最大日期',MIN(torokubi) '最小日期'
FROM shohin;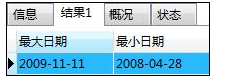
※MAX和MIN函数几乎适用于所有数据类型的列,SUM和AVG函数只适用于数值类型的列
⑥使用聚合函数删除重复值:SELECT COUNT(DISTINCT 列名) FROM 表名;
解释:删除重复的列名,再计算行数
如:计算去除重复数据后的数据行数(即计算种类)
SELECT COUNT(DISTINCT shohin_bunrui) FROM shohin;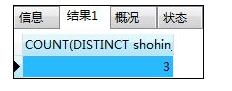
注意:DISTINCT必须写在括号内,若写成 SELECT DISTINCT COUNT(列名) 则会变成先计算行数,再删除重复的列名
※在上述五类聚合函数中都可以使用DISTINCT来删除对重复数据的处理。
如:使不使用distinct时的动作差异(sum函数)
SELECT SUM(hanbai_tanka),SUM(DISTINCT hanbai_tanka) -- 有相同的价格被删除了后只剩一条数据
FROM shohin;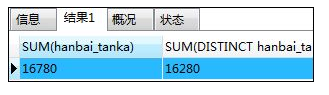
2)对表进行分组
①GROUP BY 子句:SELECT 列名1,列名2,列名3, ... FROM 表名
GROUP BY 列名1,列名2,列名3, ...;
解释:按照列名1、列名2、列名3对表中的数据进行分组。其中,GROUP BY子句中指定的列称为聚合键或分组列。
如:根据商品种类,统计数据行数
SELECT shohin_bunrui '商品种类',COUNT(*) '行数' FROM shohin
GROUP BY shohin_bunrui;
注意:使用逗号分隔指定的多列;其书写位置一定要写在FROM语句之后。SQL子句的顺序不能改变,也不能互相替换。
※子句的书写顺序:SELECT->FROM->WHERE->GROUP BY
②聚合键中包含NULL的情况:NULL也会作为一组特定的数据表示
如:按照进货单价统计数据行数
SELECT shiire_tanka,COUNT(*) FROM shohin
GROUP BY shiire_tanka;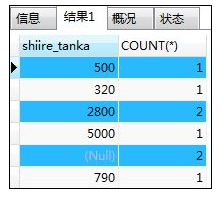
结果:null的行数为2,这里的null可以理解为不确定
使用WHERE子句时GROUP BY的执行结果:
SELECT 列名1,列名2,列名3, ... FROM 表名
WHERE ...
GROUP BY 列名1,列名2,列名3, ...;
解释:先根据WHERE子句指定的条件进行过滤,然后再进行聚合处理
如:使用where子句
SELECT shiire_tanka,COUNT(*) FROM shohin
WHERE shohin_bunrui='衣服'
GROUP BY shiire_tanka;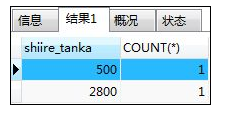
※子句的执行顺序:FROM->WHERE->GROUP BY->SELECT
③与聚合函数和GROUP BY子句有关的注意要点:
- MySQL可以把聚合键之外的列名写在SELECT子句之中(SELECT子句中可以能包含常数、聚合函数、聚合键以及其他列)
如:在聚合列shiire_tanka后面,可以添加其他列(如shohin_mei列),*代表聚合列
SELECT shiire_tanka,shohin_mei,COUNT(*) FROM shohin
GROUP BY shiire_tanka;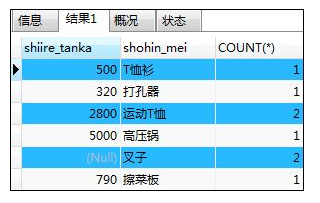
还有一种只有在MySQL中才能使用,但要慎用:
SELECT shohin_mei,shiire_tanka,COUNT(*) FROM shohin
GROUP BY shiire_tanka;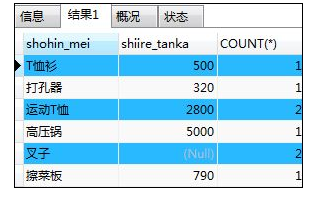
解释:上面是在shohin_mei,shiire_tanka这两种候选键中选择了shiire_tanka作为聚合键
- GROUP BY子句中使用列别名
如:在group by子句中写了列的别名
SELECT shohin_bunrui AS s_b,COUNT(*) FROM shohin
GROUP BY s_b;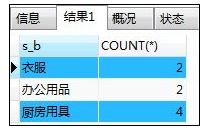
解释:这并不是通常的使用方法
- GROUP BY子句的结果是随机的、无序的
- 不能在WHERE子句中使用聚合函数(只有在SELECT、HAVING、GROUP BY子句中使用聚合函数)
3)为聚合结果指定条件:HAVING子句
HAVING子句的语法:
SELECT 列名1,列名2,列名3, ... FROM 表名
GROUP BY 列名1,列名2,列名3, ...
HAVING 分组结果对应的条件;
子句的书写顺序:SELECT->FROM->WHERE->GROUP BY->HAVING
如:从通过商品种类进行聚合分组后的结果中,取出”包含数据的行数为2行“的组
SELECT shohin_bunrui,COUNT(*) FROM shohin
GROUP BY shohin_bunrui
HAVING COUNT(*)=2;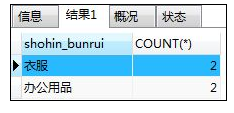
如:从通过商品种类进行聚合分组后的结果中,取出”销售单价的平均值大于等于2500日元“的组
SELECT shohin_bunrui,AVG(hanbai_tanka) FROM shohin
GROUP BY shohin_bunrui
HAVING AVG(hanbai_tanka) >= 500;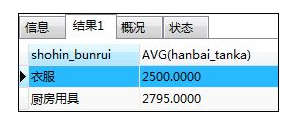
※注意:HAVING子句必须写在GROUP BY子句之后;HAVING子句中能使用的3种要素为常数、聚合函数、聚合键。
区别:WHERE子句=指定行所对应的条件
HAVING子句=指定组所对应的条件
相对于HAVING子句,更适合写在WHERE子句中的条件是:聚合键所对应的条件。
4)对查询结果进行排序
①ORDER BY子句:
SELECT 列名1,列名2,列名3, ... FROM 表名
ORDER BY 排序基准列1,排序基准列2, ...;
子句的书写顺序:SELECT->FROM->WHERE->GROUP BY->HAVING->ORDER BY
子句的执行顺序:FROM->WHERE->GROUP BY->HAVING->SELECT->ORDER BY
②指定升序或降序:未指定ORDER BY子句中排序顺序时会默认使用升序进行排序(或在列名后使用关键字ASC),若要进行降序排列时在列名后使用DESC关键字。
SELECT 列名1,列名2,列名3, ... FROM 表名
ORDER BY 排序基准列1 DESC;
如:按照销售单价由低到高(升序)进行排列
SELECT shohin_id,shohin_mei,hanbai_tanka,shiire_tanka FROM shohin
ORDER BY hanbai_tanka;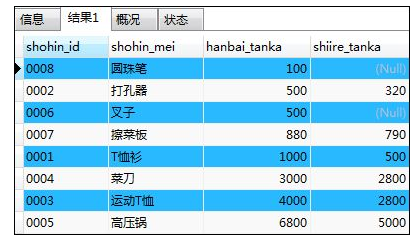
如:按照销售单价由高到低(降序)进行排列
SELECT shohin_id,shohin_mei,hanbai_tanka,shiire_tanka FROM shohin
ORDER BY hanbai_tanka DESC;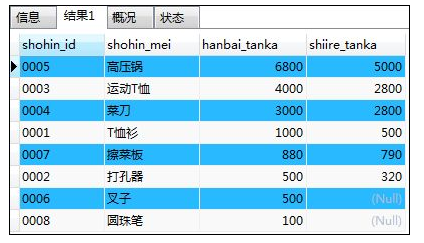
③指定多个排序键:可以同时使用2个或2个以上的排序键
优先使用左侧的键,如果该列存在相同值的话,会接着参考右侧的键
如:按照销售单价和商品编号的升序进行排列
SELECT shohin_id,shohin_mei,hanbai_tanka,shiire_tanka FROM shohin
ORDER BY hanbai_tanka,shohin_id DESC;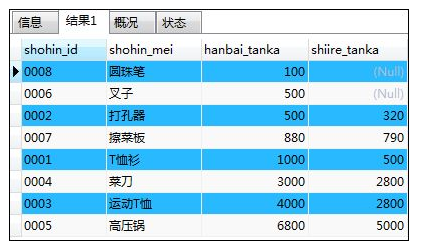
④NULL的顺序:排序键中包含NULL时,会在开头或末尾进行汇总
如:按照进货单价的升序进行排列
SELECT shohin_id,shohin_mei,hanbai_tanka,shiire_tanka FROM shohin
ORDER BY shiire_tanka;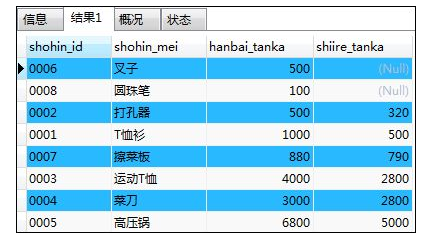
解释:NULL在结果的开头
※使用having子句的执行顺序是:
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY
⑤ORDER BY子句中可以使用SELECT子句中定义的别名
如:按照销售单价和商品编号的升序进行排列(使用别名)
SELECT shohin_id id,shohin_mei sm,hanbai_tanka ht,shiire_tanka st FROM shohin
ORDER BY ht,st;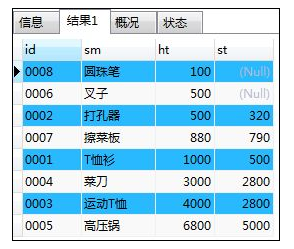
⑥ORDER BY子句中可以使用SELECT子句未使用的列和聚合函数
如:select子句中未包含的列
SELECT shohin_mei,hanbai_tanka,shiire_tanka FROM shohin
ORDER BY shohin_id;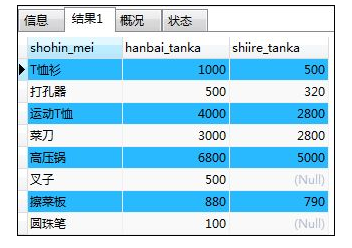
如:聚合函数
SELECT shohin_bunrui,COUNT(*) FROM shohin
GROUP BY shohin_bunrui
ORDER BY COUNT(*) DESC;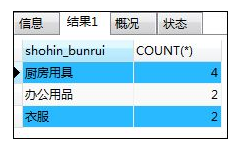
⑦ORDER BY子句中可以不要使用列编号
如:MySQL中使用列编号
SELECT shohin_id,shohin_mei,hanbai_tanka,shiire_tanka
FROM shohin
ORDER BY 3 DESC,1;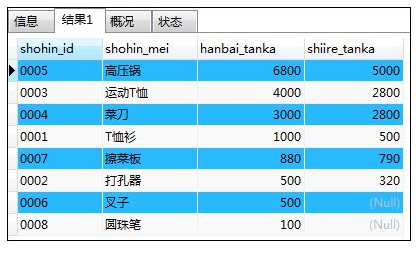
解释:不推荐使用
4、第四天:学习数据更新
1)数据的插入(INSERT语句的使用方法)
①用来装入数据的SQL就是INSERT
INSERT语句的基本语法:
INSERT INTO 表名 (列名1,列名2,列名3,...) VALUES (值1,值2,值3,...);
注意:a.插入的数据要用单引号括起来
b.多个列名与值用逗号隔开
c.表名后面的列清单与VALUES后的值清单数量必须保持一致
d.原则上,执行一次INSERT只会插入一行数据(即,要插入多行数据就需要多条 INSERT语句)
如:创建Shohinins表
CREATE TABLE Shohinins
( shohin_id CHAR(4) NOT NULL PRIMARY KEY,
shohin_mei VARCHAR(100) NOT NULL,
shohin_bunrui VARCHAR(32) NOT NULL,
hanbai_tanka INTEGER DEFAULT 0,
shiire_tanka INTEGER,
torokubi DATE
);②列清单的省略:
对表进行全列INSERT时,可以省略表名后的列清单。此时,VALUES子句的值会默认按照从左到右的顺序赋给每一列。
如:插入数据
INSERT INTO Shohinins
VALUES ('0001','T恤衫','衣服',1000,500,'2009-09-20');③插入NULL:
INSERT语句中想给某一列赋予NULL值时,可以直接在VALUES子句的值清单中写入NULL。但是,想要插入NULL的列一定不能设置NOT NULL约束。
④插入默认值:
通过CREATE TABLE语句中设置DEFAULT约束来实现对默认值的设定。
- 通过显示方法插入默认值:在VALUES子句中指定DEFAULT关键字;
如:显示方法插入默认值
INSERT INTO Shohinins VALUES ('0007','擦菜板','厨房用具',DEFAULT,790,'2009-04-28');- 通过隐示方法插入默认值:在列清单与值清单中都省略设定了默认值的列。
如:通过隐示方法插入默认值(省略默认列)
INSERT INTO Shohinins(shohin_id,shohin_mei,shohin_bunrui,shiire_tanka,torokubi)
VALUES ('0007','擦菜板','厨房用具',790,'2009-04-28');※注意:若省略了没有设定默认值的列的话,该列的值就会被设定为NULL。(如果此时该列设定为NOT NULL,INSERT语句就会出错)
⑤从其它表中复制数据:使用INSERT...SELECT语句,原有数据不会发生改变,可以在需要数据备份时使用,将一个表的数据复制到另外一个表中:
INSERT INTO 复制目的表名 (列名1,列名2,列名3, ...)
SELECT 列名1,列名2,列名3, ... FROM 复制源表名;
如:从其他表中复制数据(可用于数据备份)
CREATE TABLE shohincopy(SELECT * FROM shohin);如:若表存在:
INSERT INTO new_biao SELECT * FROM old_biao;⑥为查询的结果创建表:
方法a:
CREATE TABLE shohinBunrui
( SELECT shohin_bunrui,SUM(hanbai_tanka),SUM(shiire_tanka)
FROM shohin GROUP BY shohin_bunrui);方法b:
CREATE TABLE shohinBunrui_01
( shohin_bunrui VARCHAR(32) NOT NULL PRIMARY KEY,
sum_hanbai_tanka INTEGER,
sum_shiire_tanka INTEGER
);
INSERT INTO shohinBunrui_01
SELECT shohin_bunrui,SUM(hanbai_tanka),SUM(shiire_tanka)
FROM shohin GROUP BY shohin_bunrui;查询结果:
SELECT * FROM shohinBunrui;※INSERT语句的SELECT语句中,可以使用WHERE子句或者GROUP子句等任何SQL语法,但使用ORDER BY子句并不会产生任何效果。
2)数据的删除(DELETE语句的使用方法)
①DROP TABLE语句和DELETE语句:一旦删除,不可恢复
※区别:DROP TABLE语句会将表完全删除;DELETE语句会留下表(容器),而删除表中的全部数据
DELETE语句的基本语法:DELETE FROM 表名;
解释:删除表名中的全部数据
如:清空表中的数据
DELETE FROM shohinins;注意:a.不能漏写FROM;b.DELETE删除的对象是行,不是列或表
②指定删除对象的DELETE语句:(搜索型DELETE:使用WHERE子句指定删除条件)
DELETE FROM 表名 WHERE 条件;
解释:删除表名指定条件下的行数据
如:删除销售单价大于等于4000日元的数据
DELETE FROM shohin
WHERE hanbai_tanka >= 4000;注意:DELETE语句中不能使用GROUP BY、HAVING和ORDER BY三类子句,只能使用WHERE子句
3)数据更新(UPDATE语句的使用方法)
①UPDATE语句的基本语法:UPDATE 表名 SET 列名=表达式;
解释:a.在SET子句中记录更新对象的列和更新后的值;b.该列名下的所有数据都会被更新为指定的值
如:将登记日期全部更新为‘2009-10-10’
UPDATE shohin
SET torokubi='2009-10-10';解释: NULL的值也更新为‘2009-10-10’
②指定条件的UPDATE语句:(搜索型UPDATE:使用WHERE子句指定更新条件)
UPDATE 表名
SET 列名=表达式
WHERE 条件;
解释:将表名中符合条件的列名设为表达式的值
如:将商品种类为厨房用具的记录的销售单价更新为原来的10倍
UPDATE shohin
SET hanbai_tanka=hanbai_tanka*10
WHERE shohin_bunrui='厨房用具';③使用NULL进行更新:亦称为NULL清空
只需将表达式右边的值直接写为NULL即可,但只限于未设置NOT NULL约束的列
UPDATE 表名
SET 列名=NULL
WHERE 条件;
如:将商品编号为0008的数据的登记日期更新为null
UPDATE shohin
SET torokubi=NULL
WHERE shohin_id='0008';④多列更新:
- 使用逗号分隔排列(对所有的DBMS都适用)
UPDATE 表名
SET 列名1=表达式1,列名2=表达式2, ...
WHERE 条件;
- 使用列清单化(只对部分DBMS适用)
UPDATE 表名
SET (列名1,列名2, ...)=(表达式1,表达式2, ...)
WHERE 条件;
如:多列更新
UPDATE shohin
SET hanbai_tanka=hanbai_tanka/10,
shiire_tanka=shiire_tanka*2
WHERE shohin_bunrui='厨房用具';解释:一般多用逗号隔开
4)事务:需要在同一个处理单元中执行的一系列更新处理的集合
①创建事务:
事物开始语句(START TRANSTION);
DML语句1;
DML语句2;
DML语句3;
...
事物结束语句(COMMIT或者ROLLBACK);
解释:
1.在标准SQL中并没有定义事务的开始语句,而是由各个DBMS自已来定义的。比较有代表性的语法有SQL Server、PostgreSQL(BEGIN TRANSACTION),MySQL(START TRANSACTION),Oracle、DB2(无)
2.事务的结束需要用户明确地给出指示。(COMMIT是提交事务包含的全部更新处理的结束指令,一旦提交就无法恢复到事务开始前的状态;ROLLBACK是取消事务包含的全部更新处理的结束指令,一旦回滚就会回复到事务开始之前的状态)
如:更新商品信息的事务
START TRANSACTION;
-- 将菜刀的销售单价降低1000日元
UPDATE shohin
SET hanbai_tanka=hanbai_tanka-1000
WHERE shohin_mei='菜刀';
-- 将叉子的销售单价上浮1000日元
UPDATE shohin
SET hanbai_tanka=hanbai_tanka+1000
WHERE shohin_mei='叉子';
COMMIT;②ACID特性:
DBMS的事务都遵循四种标准规格的约定,即ACID特性
- 原子性(Atomicity):事务结束时,其中所包含的更新处理要么全部执行,要么完全不执行的特性;
- 一致性(Consistency)(也称为完整性):事务中包含的处理,要满足数据库提前设置的约束;
- 隔离性(Isolation):保证不同事务之间互不干扰的特性,即事务中间不会相互嵌套;
- 持久性(Durability):事务一旦结束,DBMS会保证该时点的数据状态得以保存的特性
5、第五天:学习复杂查询
1)视图
①视图与表:从SQL角度来看视图就是一张表
视图与表的唯一区别:是否保存了实际的数据。数据库中的数据实际上会被保存到计算机的存储设备中,但使用视图时并不会将数据保存到存储设备之中,也不会将数据保存到其他任何地方。实际上是他保存的是SELECT语句。
表中存储的是实际数据,而视图中保存的是从表中取出数据所使用的SELECT语句。
视图的优点:1.无需保存数据,可以节省存储设备的容量;2.可以将频繁使用的SELECT语句保存成视图,这样一来就不用每次都重新书写了。
②创建视图的方法:
CREATE VIEW 视图名称(视图列名1,视图列名2,...)
AS
SELECT语句
解释:SELECT语句需要书写在AS关键字之后(AS关键字不可省略);SELECT语句中列的排列顺序和视图中列的排列顺序相同
如:创建shohinsum视图
CREATE VIEW shohinsum(shohin_bunrui,cnt_shohin)
AS
SELECT shohin_bunrui,COUNT(*) FROM shohin
GROUP BY shohin_bunrui;解释:创建一个shohinsum视图,其数据来于shohin表按shohin_bunrui进行分组计数的结果
③视图的使用与表一样:
如:使用视图
SELECT * FROM shohinsum;
④使用视图的查询:通常需要执行2条以上的SELECT语句
a.首先执行定义视图的SELECT语句;
b.根据得到的结果,再执行在FROM子句中使用视图的SELECT语句。
如:视图中创建视图
CREATE VIEW shohinsumjim(shohin_bunrui,cnt_shohin)
AS
SELECT shohin_bunrui,cnt_shohin FROM shohinsum
WHERE shohin_bunrui='办公用品';
-- 使用视图
SELECT * FROM shohinsumjim;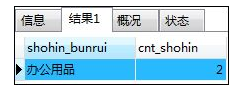
解释:应该避免在视图的基础上创建视图
⑤多重视图:尽量避免,因为它会降低SQL的性能
如:多重视图的创建
CREATE VIEW ShopSumJim(name,cnt_name)
AS
SELECT name,cnt_name FROM ShopSum
WHERE name='筷子';⑥视图的限制:通过聚合得到的视图无法进行更新
a.定义视图时不能使用ORDER BY子句(视图和表一样,数据行都是没有顺序的,除了PostgreSQL数据库)
b.当定义视图的SELECT语句满足以下某些条件时,可以对视图进行更新(更新包括:INSERT、DELETE、UPDATE)。条件如下:SELECT语句中未使用DISTINCT;FROM只有一张表;未使用GROUP BY子句;未使用HAVING子句
如:能更新的情况:(与原始表的列对应,无缺失)
CREATE VIEW shohinjim(shohin_id,shohin_mei,shohin_bunrui,hanbai_tanka,shiire_tanka,torokubi)
AS
SELECT * FROM shohin WHERE shohin_bunrui='办公用品';
-- 使用视图
SELECT * FROM shohinjim;
如:向视图shohinjim中插入数据
INSERT INTO shohinjim VALUES ('0009','印章','办公用品',95,10,'2009-11-30');解释:此时,数据是插入到了原始表shohin中
⑦删除视图:DROP VIEW 视图名称 (视图列名1,视图列名2,视图列名3,...);
如:删除视图
DROP VIEW shohinsum;2)子查询
①子查询和视图:
子查询:将用来定义视图的SELECT语句直接用于FROM子句当中。子查询的特点概括起来就是一张一次性视图。
如:根据商品种类统计商品数量的视图
SELECT shohin_bunrui,cnt_shohin -- 要子查询里面的列存在
FROM ( SELECT shohin_bunrui,COUNT(*) AS cnt_shohin -- 子查询里面的列
FROM shohin
GROUP BY shohin_bunrui
) AS shohinsum;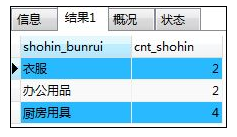
解释:()部分即为子查询,即,将用来定义视图 的SELECT子句直接作用于FROM子句当中;子查询作为内层查询会首先执行。
如:增加子查询的层数
SELECT shohin_bunrui,cnt_shohin
FROM ( SELECT *
FROM ( SELECT shohin_bunrui,COUNT(*) AS cnt_shohin
FROM shohin
GROUP BY shohin_bunrui
) AS shohinsum01
WHERE cnt_shohin=4
) AS shohinsum02;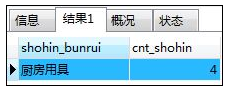
解释:子查询的层数原则上没有限制,但应尽量避免使用多重嵌套的子查询
②子查询的名称:
原则上子查询必须使用AS关键字设定名称,此关键字有时可省略
③标量子查询:必须而且只能返回1行1列的结果,其返回值可以用在=或者< >这样需要单一值的比较运算符之中。
- 在where中使用标量子查询
如:选取出销售单价高于全部商品的平均单价的商品
SELECT shohin_id,shohin_mei,hanbai_tanka FROM shohin
WHERE hanbai_tanka > (SELECT AVG(hanbai_tanka) FROM shohin);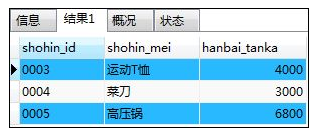
解释:从shohin表中选出销售价格高于平均价格的商品信息;由于WHERE子句中不能使用聚合函数,所以利用标量子查询SELECT AVG(hanbai_tanka) FROM shohin来实现
- 在select语句中使用标量子查询
如:选取出销售单价高于全部商品的平均单价的商品
SELECT shohin_id,shohin_mei,hanbai_tanka,
(SELECT AVG(hanbai_tanka) FROM shohin) AS avg_tanka
FROM shohin;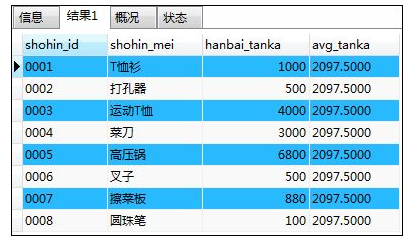
- 在having子句中使用标量子查询
如:选取出销售单价高于全部商品的平均单价的商品
SELECT shohin_bunrui,AVG(hanbai_tanka) FROM shohin
GROUP BY shohin_bunrui
HAVING AVG(hanbai_tanka) > (SELECT AVG(hanbai_tanka) FROM shohin);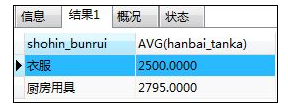
注意:标量子查询的书写位置并不仅仅局限于WHERE子句中,能够使用常数或者列名的地方,无论是SELECT子句、GROUP BY 子句、HAVING子句,还是ORDER BY子句,几乎所有地方都可用。
※使用标量子查询时的注意事项:该子查询绝对不能返回多行结果
3)关联子查询
①普通子查询和关联子查询的区别
如:通过关联子查询按照商品种类对平均销售单价进行比较
SELECT shohin_id,shohin_mei,hanbai_tanka
FROM shohin AS s1
WHERE hanbai_tanka >(SELECT AVG(hanbai_tanka)
FROM shohin AS s2
WHERE s1.shohin_bunrui=s2.shohin_bunrui --关联条件
GROUP BY shohin_bunrui);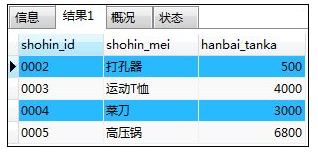
解释:对表shohin按shohin_bunrui分组,选出每组中hanbai_tanka大于每组的平均hanbai_tanka的商品信息
※在细分的组内进行比较时,需要使用关联子查询
②关联子查询也是用来对集合进行切分的:关联子查询实际只能返回1行结果
结合条件/关联条件一定要写在子查询中:因为关联名称的作用域
6、第六天:学习函数、谓词、CASE表达式
1)各种各样的函数
①函数的种类:
在SQL中函数大致可分为以下几种:算术函数、字符串函数、日期函数、转换函数、聚合函数。
②算术函数:大多数函数对NULL(只有有一个参数为NULL)的结果都为NULL
+(加法)、-(减法)、*(乘法)、/(除法)
如:创建samplemath表
CREATE TABLE samplemath
( m numeric(10,3),
n INTEGER,
p INTEGER
);
-- 插入数据
START TRANSACTION;
INSERT INTO samplemath VALUES (500,0,NULL),(-180,0,NULL),(NULL,NULL,NULL),
(NULL,7,3),(NULL,5,2),(NULL,4,NULL),
(8,NULL,3),(2.27,1,NULL),(5.555,2,NULL),
(NULL,1,NULL),(8.76,NULL,NULL);
COMMIT;
SELECT * FROM samplemath;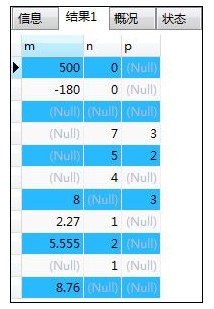
- ABS(列名)--求绝对值:不考虑数值符号,表示一个数到原点距离的数值。
如:ABS()绝对值函数
SELECT m,ABS(m) AS abs_m FROM samplemath;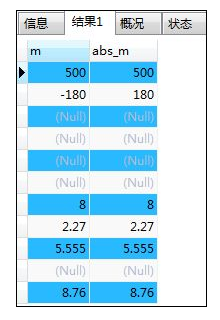
- MOD(被除数列名,除数列名)--除法余数的函数:只能对整数类型的列使用,SQL Server不支持该函数
如:MOD求余函数
SELECT n,p,MOD(n,p) AS mod_np FROM samplemath;
- ROUND(对象数值,保留小数的位数)--四舍五入
如:ROUND()四舍五入函数
SELECT m,n,ROUND(m,n) AS round_mn
FROM samplemath;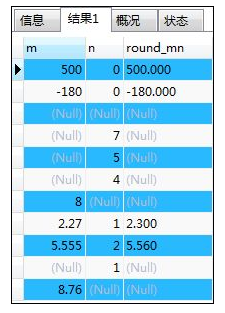
③字符串函数:如果函数参数中包含NULL,其结果都为NULL
如:创建samplestr表
CREATE TABLE samplestr
( str1 VARCHAR(40),
str2 VARCHAR(40),
str3 VARCHAR(40)
);
-- 插入数据
START TRANSACTION;
INSERT INTO samplestr
VALUES ('opx','rt',NULL),('abc','def',NULL),('山田','太郎','是我'),
('aaa',NULL,NULL),(NULL,'xyz',NULL),('@!#$%',NULL,NULL),
('ABC',NULL,NULL),('aBC',NULL,NULL),('abc太郎','abc','ABC'),
('abcdefabc','abc','ABC'),('micmic','i','I');
COMMIT;
SELECT * FROM samplestr;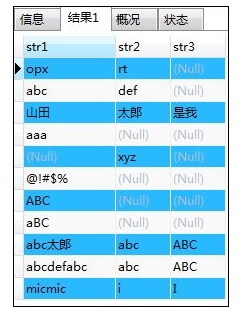
- CONCAT(str1,str2,...)拼接函数:可以对两个或两个以上的字符串进行拼接
SELECT str1,str2,CONCAT(str1,str2) AS str_12 FROM samplestr;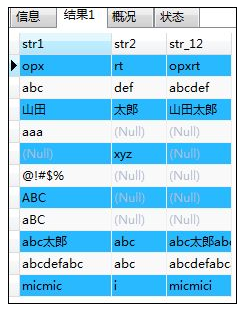
- LENGTH(字符串)--字符串长度:求取字符串中包含多少个字符
SELECT str1,LENGTH(str1) AS len_str FROM samplestr;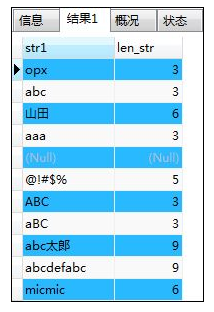
解释:汉字是三个字节,一个长度为3;英文是一个字节,长度为1
- LOWER(字符串)--小写转换:只能针对英文字母使用,将参数中的字符串全部转换为小写,并不影响原本就是小写的字符
SELECT str1,LOWER(str1) AS low_str FROM samplestr
WHERE str1 IN ('ABC','aBC','abc','山田');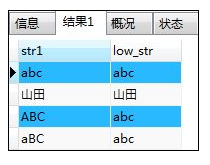
- UPPER(字符串)--大写转换:只能针对英文字母使用,将参数中的字符串全部转换为大写,并不影响原本就是大写的字符
SELECT str1,UPPER(str1) AS upp_str FROM samplestr
WHERE str1 IN ('ABC','aBC','abc','山田');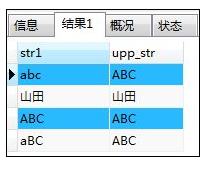
- REPLACE(对象字符串,替换前的字符串,替换后的字符串)--字符替换:将字符串中的一部分替换为其它的字符串
SELECT str1,str2,str3,REPLACE(str1,str2,str3) AS rep_str FROM samplestr;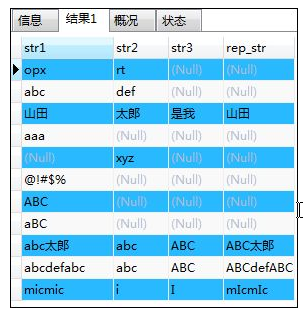
- SUBSTRING(对象字符串 FROM 截取的起始位置 FOR 截取的字符数)--字符串截取:截取的位置从左侧开始计算
SELECT str1,SUBSTRING(str1 FROM 3 FOR 2) AS sub_str FROM samplestr;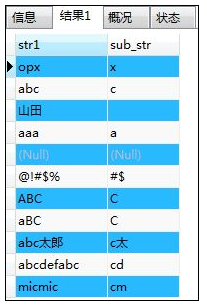
④日期函数:
- CURRENT_DATE--当前日期:能够返回SQL执行的日期,没有参数
SELECT CURRENT_DATE;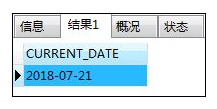
- CURRENT_TIME--当前时间:能够取得SQL执行的时间,没有参数
SELECT CURRENT_TIME;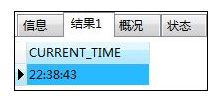
- CURRENT_TIMESTAMP--当前日期和时间:同时得到当前的日期和时,没有参数
SELECT CURRENT_TIMESTAMP;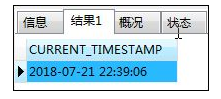
- EXTRACT(日期元素 FROM 日期)--截取日期元素:可以截取出日期数据中的一部分
SELECT CURRENT_TIMESTAMP,
EXTRACT(YEAR FROM CURRENT_TIMESTAMP) AS year,
EXTRACT(MONTH FROM CURRENT_TIMESTAMP) AS month,
EXTRACT(DAY FROM CURRENT_TIMESTAMP) AS day,
EXTRACT(HOUR FROM CURRENT_TIMESTAMP) AS hour,
EXTRACT(MINUTE FROM CURRENT_TIMESTAMP) AS minute,
EXTRACT(SECOND FROM CURRENT_TIMESTAMP) AS second;
⑤转换函数:一是数据类型的转换,二是值的转换
- CAST(转换前的值 AS 想要转换的数据类型)--类型转换
如:将字符串型转换为数值型
SELECT CAST('0001' AS SIGNED INTEGER) AS cast_int;
如:将字符串型转换为日期类型
SELECT CAST('2009-12-14' AS DATE) AS cast_date;
- COALESCE(数据1,数据2,数据3, ...)--将NULL转换为其它值:返回可变参数中左侧开始第1个不是NULL的值
如:将null转换为其他值coalesce
SELECT COALESCE(NULL,1) AS col_1,
COALESCE(NULL,'test',NULL) AS col_2,
COALESCE(NULL,NULL,'2009-11-01') AS col_3;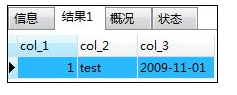
如:使用samplestr表中的列做例子
SELECT COALESCE(str2,'NULL') FROM samplestr;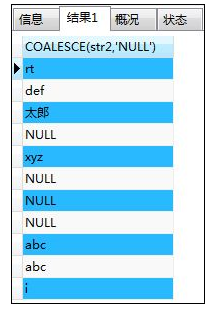
2)谓词:满足返回值是真值的函数
如:创建samplelike表
CREATE TABLE samplelike
( strcol VARCHAR(6) PRIMARY KEY NOT NULL
);
-- 插入数据
START TRANSACTION;
INSERT INTO samplelike VALUES ('abcddd'),('dddabc'),('abdddc'),
('abcdd'),('ddabc'),('abddc');
COMMIT;
SELECT * FROM samplelike;
①LIKE谓词——字符串的部分一致查询:
- 前方一致查询
SELECT * FROM samplelike
WHERE strcol LIKE 'ddd%';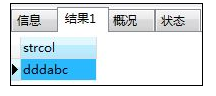
解释:从表SampleLike中选出开头为“ddd”的字符串;其中“%”表示0字符以上的任意字符串
- 中间一致查询
SELECT * FROM samplelike
WHERE strcol LIKE '%ddd%';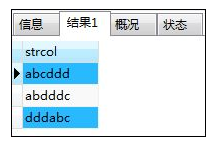
解释:从表SampleLike中选出中间为“ddd”的字符串;其中“%”表示0字符以上的任意字符串
- 后方一致查询
SELECT * FROM samplelike
WHERE strcol LIKE '%ddd';
解释:从表SampleLike中选出结尾为“dd”的字符串;其中“%”表示0字符以上的任意字符串
※注:‘_’代表任意一个字符,而‘%’则代表一个或多个字符
②BETWEEN谓词——范围查询:需要使用三个参数
如:选取销售单价为100-1000日元的商品
SELECT * FROM shohin
WHERE hanbai_tanka BETWEEN 100 AND 1000; 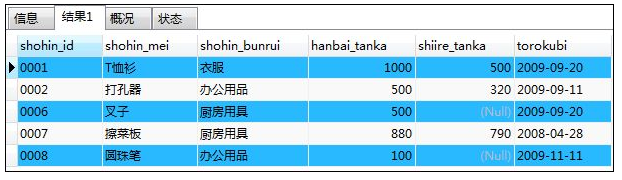
解释:从表Shop中选出price在100~1000之间的产品信息(结果中包含临界值100和1000);
若不想包含临界值必须使用<和>:
如:选取出销售单价为101-999日元的商品(不包含100和1000)
SELECT * FROM shohin
WHERE hanbai_tanka > 100
AND hanbai_tanka < 1000;
③IS NULL、IS NOT NULL——判断是否为NULL:
如:选取出进货单价为null的商品
SELECT * FROM shohin
WHERE shiire_tanka IS NULL;
如:选取出进货单价不为null的商品
SELECT * FROM shohin
WHERE shiire_tanka IS NOT NULL;
④IN谓词——OR的简便用法:
如:OR的简便用法
SELECT shohin_mei,shiire_tanka FROM shohin
WHERE shiire_tanka=320
OR shiire_tanka=500
OR shiire_tanka=5000;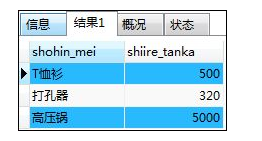
如:IN谓词的简便用法
SELECT shohin_mei,shiire_tanka FROM shohin
WHERE shiire_tanka IN (320,500,5000);
如:NOT IN谓词的简便用法
SELECT shohin_mei,shiire_tanka FROM shohin
WHERE shiire_tanka NOT IN (320,500,5000);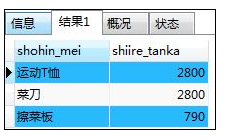
注意:使用IN和NOT IN 是无法选取出NULLL数据的
⑤使用子查询作为IN谓词的参数:
IN/NOT IN 和子查询:能够将表作为IN的参数,也可以认为“能够将视图作为IN的参数”
如:创建商店商品表tenposhohin
CREATE TABLE tenposhohin
( tenpo_id CHAR(4) NOT NULL,
tenpo_mei VARCHAR(200) NOT NULL,
shohin_id CHAR(4) NOT NULL,
suryo INTEGER NOT NULL,
PRIMARY KEY(tenpo_id,shohin_id)
);
-- 插入数据
START TRANSACTION;
INSERT INTO tenposhohin
VALUES ('000A','东京','0001',30),('000A','东京','0002',50),
('000A','东京','0003',15),('000B','名古屋','0002',30),
('000B','名古屋','0003',120),('000B','名古屋','0004',20),
('000B','名古屋','0006',10),('000B','名古屋','0007',40),
('000C','大阪','0003',20),('000C','大阪','0004',50),
('000C','大阪','0006',90),('000C','大阪','0007',70),
('000D','福冈','0001',100);
COMMIT;
SELECT * FROM tenposhohin;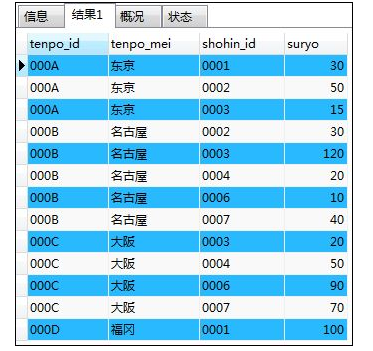
如:读取“大阪店在售商品的销售单价”
SELECT shohin_mei,hanbai_tanka FROM shohin
WHERE shohin_id IN
(SELECT shohin_id FROM tenposhohin WHERE tenpo_id='000C');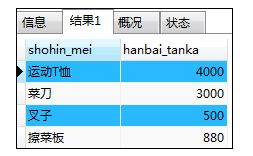
如:NOT IN与子查询
SELECT shohin_mei,hanbai_tanka
FROM shohin
WHERE shohin_id NOT IN
(SELECT shohin_id FROM tenposhohin WHERE tenpo_id='000A');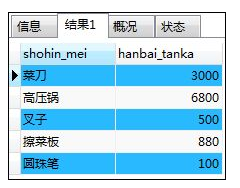
⑥EXIST谓词:基本上可以使用IN(或者NOT IN)来代替
如:使用exists选取出“大阪店在售商品的销售单价”
SELECT shohin_mei,hanbai_tanka
FROM shohin AS S
WHERE EXISTS (SELECT * FROM tenposhohin AS TS
WHERE TS.tenpo_id='000C'
AND TS.shohin_id=S.shohin_id);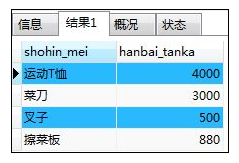
解释:从表tenposhohin中选出tenpo_id为“000C”,且在表shohin和表tenposhohin的shohin_id相同的产品信息
a.EXIST谓词的使用方法:判断是否存在满足某种条件的记录,若存在则返回真,若不存在则返回为假
b.EXIST的参数:左侧并没有任何参数,右侧通常是一个子查询(关联子查询)
子查询中的SELECT *:在EXIST的子查询中书写SELECT *为SQL的一种习惯
c.使用NOT EXIST替换NOT IN:当不存在满足子查询中指定条件的记录时返回真
如:选取出“东京店在售以外的商品的销售单价”
SELECT shohin_mei,hanbai_tanka
FROM shohin AS S
WHERE NOT EXISTS (SELECT * FROM tenposhohin AS TS
WHERE TS.tenpo_id='000A'
AND TS.shohin_id=S.shohin_id);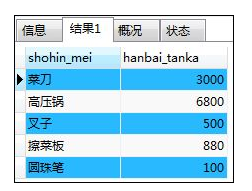
3)CASE表达式:一种表示(条件)分歧的函数
①CASE表达式的语法:分为简单CASE表达式和搜索CASE表达式(搜索CASE包含了简单CASE的全部功能)
②搜索CASE表达式:
CASE WHEN 判断表达式 THEN 表达式
WHEN 判断表达式 THEN 表达式
...
ELSE 表达式
END
解释:WHEN子句中的判断表达式就是类似“列=值”这样,返回值为真值的表达式;
CASE表达式从最初的WHEN子句中的判断表达式进行判断开始执行。若判断为真,则返回THEN子句的表达式,CASE表达式的执行到此为止;若判断为假,则跳转到下一条WHEN子句的判断之中。如果直到最后的WHEN子句为止返回结果都为假,则返回ELSE中的表达式,执行终止。
如:搜索case表达式
SELECT shohin_mei,
CASE WHEN shohin_bunrui='衣服'
THEN CONCAT('A:',shohin_bunrui)
WHEN shohin_bunrui='办公用品'
THEN CONCAT('B:',shohin_bunrui)
WHEN shohin_bunrui='厨房用具'
THEN CONCAT('C:',shohin_bunrui)
ELSE NULL
END AS abc_shohin_bunrui
FROM shohin;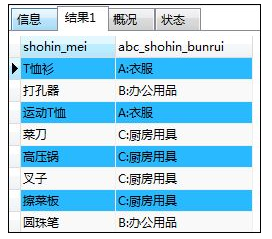
※注意:ELSE子句可以省略不写,自动默认为“ELSE NULL”
③通常使用group by也无法实现行列转换
SELECT shohin_bunrui,SUM(hanbai_tanka) AS sum_tanka FROM shohin
GROUP BY shohin_bunrui;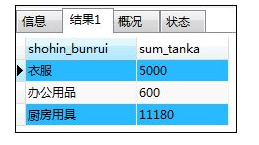
如:对按照商品种类计算出的销售单价合计值进行行列转换
SELECT SUM(CASE WHEN shohin_bunrui='衣服'
THEN hanbai_tanka
ELSE 0
END ) AS sum_tanka_ihuku,
SUM(CASE WHEN shohin_bunrui='厨房用具'
THEN hanbai_tanka
ELSE 0
END ) AS sum_tanka_kitchen,
SUM(CASE WHEN shohin_bunrui='办公用品'
THEN hanbai_tanka
ELSE 0
END ) AS sum_tanka_jimu
FROM shohin;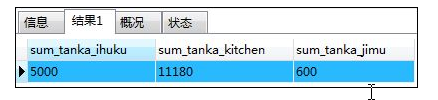
④简单case表达式
SELECT shohin_mei,
CASE shohin_bunrui
WHEN '衣服' THEN CONCAT('A:',shohin_bunrui)
WHEN '办公用品' THEN CONCAT('B:',shohin_bunrui)
WHEN '厨房用具' THEN CONCAT('C:',shohin_bunrui)
ELSE NULL
END AS abc_shohin_bunrui1
FROM shohin;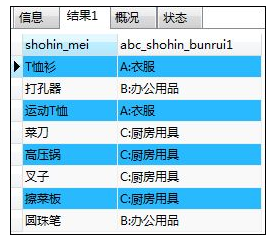
⑤使用IF函数代替CASE表达式:IF(表达式1,表达式2,表达式3)
SELECT shohin_mei,
IF(
IF(
IF (shohin_bunrui='衣服',CONCAT('A:',shohin_bunrui),NULL) IS NULL
AND shohin_bunrui='办公用品',
CONCAT('B:',shohin_bunrui),
IF(shohin_bunrui='衣服',CONCAT('A:',shohin_bunrui),NULL)
)IS NULL AND shohin_bunrui='厨房用具',
CONCAT('C:',shohin_bunrui),
IF(
IF (shohin_bunrui='衣服',CONCAT('A:',shohin_bunrui),NULL)IS NULL
AND shohin_bunrui='办公用品',
CONCAT('B:',shohin_bunrui),
IF (shohin_bunrui='衣服',CONCAT('A:',shohin_bunrui),NULL)
)
) AS abc_shohin_bunrui2
FROM shohin;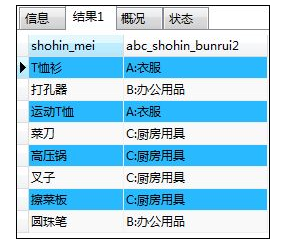
7、第七天:学习集合运算
1)表的加减法
集合运算:对满足同一规则的记录进行的加减等“四则运算”,以行方向为单位进行操作(即导致行数的增减)
如:创建表
CREATE TABLE shohin2
( shohin_id CHAR(4) NOT NULL PRIMARY KEY,
shohin_mei VARCHAR(100) NOT NULL,
shohin_bunrui VARCHAR(32) NOT NULL,
hanbai_tanka INTEGER,
shiire_tanka INTEGER,
torokubi DATE
)
-- 插入数据
START TRANSACTION;
INSERT INTO shohin2
VALUES ('0001','T恤衫','衣服',1000,500,'2008-09-20'),
('0002','打孔器','办公用品',500,320,'2009-09-11'),
('0003','运动T恤','衣服',4000,2800,NULL),
('009','手套','衣服',800,500,NULL),
('0010','水壶','厨房用具',2000,1700,'2009-09-20');
COMMIT;①表的加法——UNION(并集):
SELECT shohin_id,shohin_mei FROM shohin
UNION
SELECT shohin_id,shohin_mei FROM shohin2;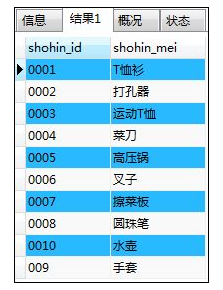
解释:将表shohin与表shohin2进行并集运算;结果中会除去重复的记录
注意:作运算对象的记录的列数必须相同、列的类型必须一致;可以使用任何SELECT语句,但ORDER BY子句只能在最后使用一次
②包含重复行的集合运算——ALL选项:对所有的集合运算符都适用
SELECT shohin_id,shohin_mei FROM shohin
UNION ALL
SELECT shohin_id,shohin_mei FROM shohin2;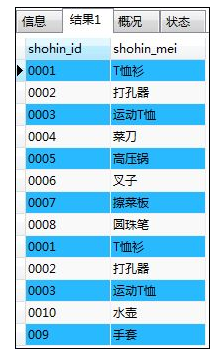
解释:在UNION后加ALL关键字,就可以实现在集合运算中保留重复行的效果
③选取表中的公共部分——INTERSECT:应用于两张表,选取出它们当中的公共记录
如:选取表中重复项(MySQL中没有相应的字段)
SELECT shohin_id,shohin_mei FROM shohin AS s1
WHERE shohin_id IN
( SELECT shohin_id FROM shohin2 AS s2
WHERE s1.shohin_id=s2.shohin_id);
④记录的减法——EXCEPT:两张表的差集
如:记录的减法 (MySQL也不支持except)
select shohin_id,shohin_mei from shohin AS s1
where shohin_id NOT IN
( select shohin_id from shohin AS s2
WHERE s1.shohin_id=s2.shohin_id);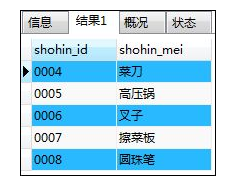
解释:得到的是表shohin减去表shohin2的记录
select shohin_id,shohin_mei from shohin2 AS s1
where shohin_id NOT IN
( select shohin_id from shohin AS s2
WHERE s1.shohin_id=s2.shohin_id);
解释:得到的是表shohin2减去表shohin的记录
注意:当减数和被减数的位置不同时,所得到的结果是不同的
2)联结(以列为单位对表进行联结):将其它表中的列添加进来,进行“添加列”的运算
①内联结——INNER JOIN:应用最广泛的联结运算
对于两张满足以下条件的表:a.两张表中都包含的列;b.只存在于一种表内的列
联结运算:以条件1的列作为桥梁,将条件2中满足同样条件的列汇集到同一结果之中
如:将两张表进行内联结 (FROM A INNER JOIN B ON A.ID=B.ID (联结键))
SELECT ts.tenpo_id,ts.tenpo_mei,s.shohin_id,s.shohin_mei,s.hanbai_tanka
FROM tenposhohin AS ts INNER JOIN shohin AS s
ON ts.shohin_id=s.shohin_id;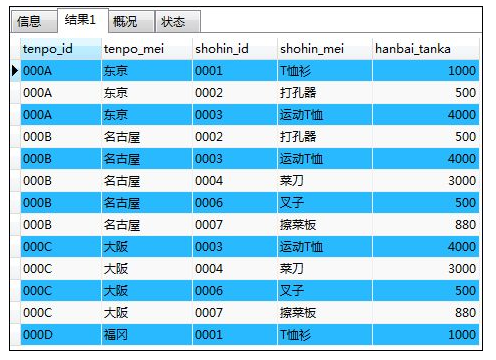
解释:在FROM子句中使用INNER JOIN将两张表联结在一起,注意别名不是必须的;ON子句后面所记载的是联结条件,即指定两张表联结所使用的列(联结键),ON必须写在FROM和WHERE之间;在SELECT子句中需要按照“表的别名.列名”的格式进行书写,以防在两个表的同名列之间产生混乱;
※注意:将表联结起来后,可以使用WHERE、GROUP BY、HAVING、ORDER BY等子句;联结起来的表只在SELECT语句执行期间存在,SELECT语句执行之后就会消失。若希望继续使用这张表,则应将其创建成视图
如:内联结与where子句结合使用(也可以与group by、having、order by一起使用)
SELECT ts.tenpo_id,ts.tenpo_mei,s.shohin_id,s.shohin_mei,s.hanbai_tanka
FROM tenposhohin AS ts INNER JOIN shohin AS s
ON ts.shohin_id=s.shohin_id
WHERE ts.tenpo_id='000A';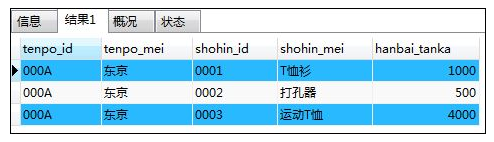
②外联结——OUTER JOIN:也是通过ON子句使用联结键将两张表进行联结
- 右外联结 (FROM A RIGHT OUTER JOIN B ON A.ID=B.ID (联结键))
如:将两张表进行右外联结
SELECT ts.tenpo_id,ts.tenpo_mei,s.shohin_id,s.shohin_mei,s.hanbai_tanka
FROM tenposhohin AS ts RIGHT OUTER JOIN shohin AS s
ON ts.shohin_id=s.shohin_id;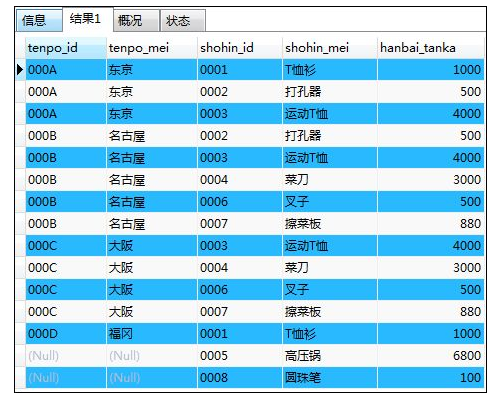
- 左外联结 (FROM A LEFT OUTER JOIN B ON A.ID=B.ID (联结键))
如:将两张表进行左外联结
SELECT ts.tenpo_id,ts.tenpo_mei,s.shohin_id,s.shohin_mei,s.hanbai_tanka
FROM shohin AS s LEFT OUTER JOIN tenposhohin AS ts
ON ts.shohin_id=s.shohin_id;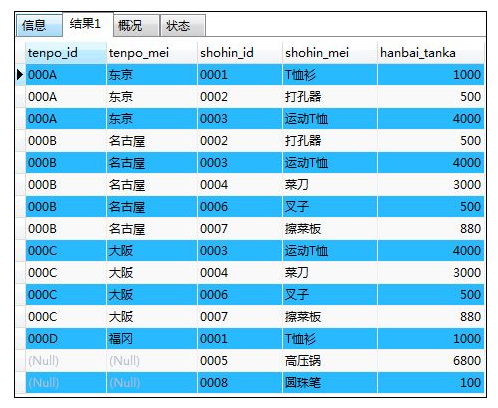
解释:选取出单张表中全部的信息(内联结只能选取出同时存在于两张表中的数据,而只要数据存在于某一张表中,通过外联结就能够读取出来);通过使用LEFT和RIGHT来指定哪张表为主表(最终结果包含主表内所有的数据)
③3张以上表的联结:原则上联结表的数量并没有限制
如:创建库存商品表zaikoshohin
CREATE TABLE zaikoshohin
( souko_id CHAR(4) NOT NULL,
shohin_id CHAR(4) NOT NULL,
zaiko_suiyo INTEGER NOT NULL,
PRIMARY KEY (souko_id,shohin_id)
);
-- 插入数据
START TRANSACTION;
INSERT INTO zaikoshohin
VALUES ('S001','0001',0) ,('S001','0002',120),('S001','0003',200) ,
('S001','0004',3) ,('S001','0005',0) ,('S001','0006',99) ,
('S001','0007',999),('S001','0008',200),('S002','0001',10),
('S002','0002',25) ,('S002','0003',34) ,('S002','0004',19),
('S002','0005',99),('S002','0006',0) ,('S002','0007',0) ,
('S002','0008',18) ;
COMMIT;方法1:三张表进行内联结
SELECT ts.tenpo_id,ts.tenpo_mei,s.shohin_id,
s.shohin_mei,s.hanbai_tanka,zs.zaiko_suiyo
FROM tenposhohin AS ts INNER JOIN shohin AS s
ON ts.shohin_id=s.shohin_id
INNER JOIN zaikoshohin AS zs
ON ts.shohin_id=zs.shohin_id
WHERE zs.souko_id='S001';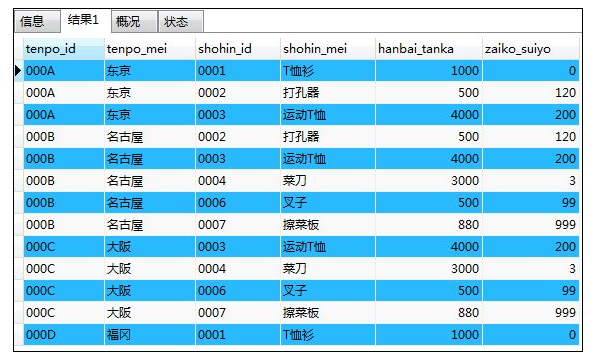
方法2:三张表进行内联结(过时的语句,不推荐使用)
SELECT ts.tenpo_id,ts.tenpo_mei,s.shohin_id,s.shohin_mei,s.hanbai_tanka,zs.zaiko_suiyo
FROM tenposhohin AS ts ,shohin AS s,zaikoshohin AS zs
WHERE zs.souko_id='S001'
AND ts.shohin_id=s.shohin_id
AND ts.shohin_id=zs.shohin_id;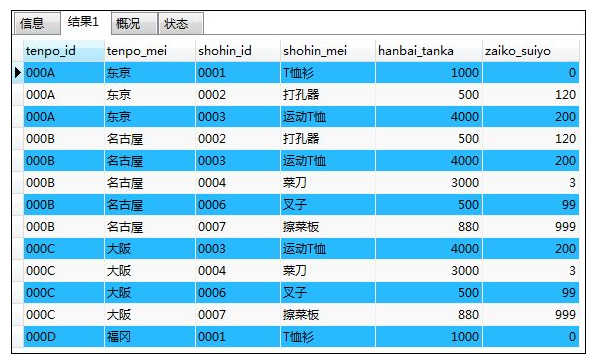
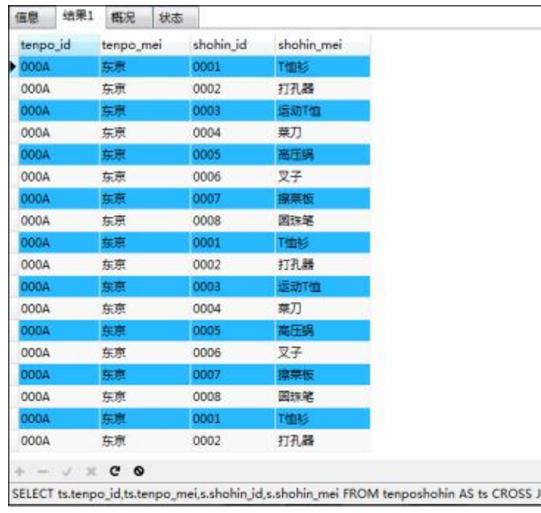
④交叉联结——CROSS JOIN(笛卡尔积):为所有联结运算的基础,但在实际业务中并没有使用过(原因1:其结果没有实用价值;原因2:结果行数太多,需要大量的运算时间与高性能设备的支持)
内联结可以理解为“包含在交叉联结结果中的部分”;外联结可以理解为“交叉联结结果之外的部分”
如:将两张表进行交叉联结(104=13*8条记录)
SELECT ts.tenpo_id,ts.tenpo_mei,s.shohin_id,s.shohin_mei
FROM tenposhohin AS ts CROSS JOIN shohin AS s;
五、总结
如果将上面的每个章节认认真真的学了一遍,那么你应该了解了数据库的基本概念以及数据库和SQL的关系。同时,如果已经掌握对数据的增删查改,那么恭喜你已经做到SQL的入门了。
当然,通过上面的操作,还只是刚踏入数据库学习的门槛,想要进一步掌握对数据库的学习,必须找到一些SQL的练习平台。只要通过不断的反复练习,相信能够对数据库更加熟练。
来源:https://zhuanlan.zhihu.com/p/40280591
另外: https://www.jianshu.com/p/4557783b69c9
https://www.jianshu.com/p/87e00554467c
也值得看看


