背景
目前对于时序大数据的存储和处理往往采用关系型数据库的方式进行处理,但由于关系型数据库天生的劣势导致其无法进行高效的存储和数据的查询。时序大数据解决方案通过使用特殊的存储方式,使得时序大数据可以高效存储和快速处理海量时序大数据,是解决海量数据处理的一项重要技术。该技术采用特殊数据存储方式,极大提高了时间相关数据的处理能力,相对于关系型数据库它的存储空间减半,查询速度极大的提高。时间序列函数优越的查询性能远超过关系型数据库,Informix TimeSeries非常适合在物联网分析应用。
定义
时间序列数据库主要用于指处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据。
最新时序数据库排名:
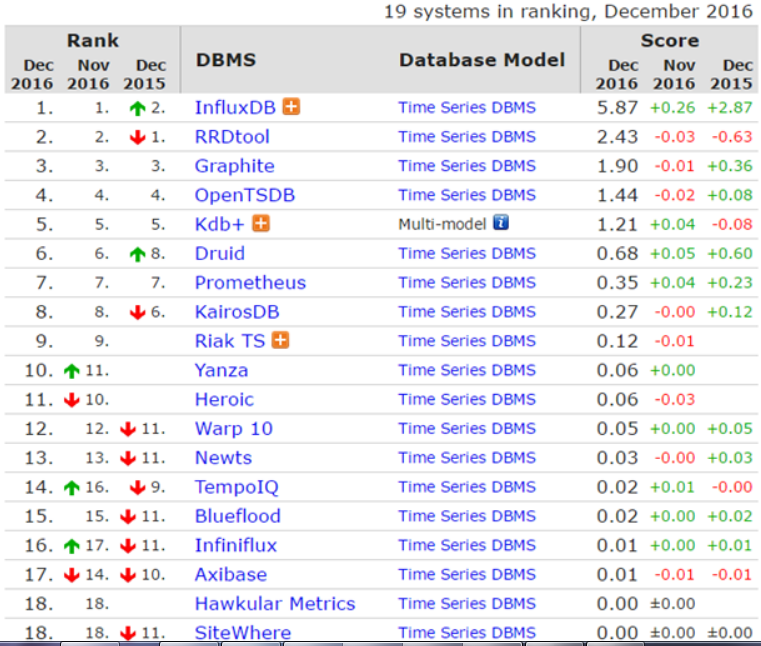
特点& 分类:
- 专门优化用于处理时间序列数据
- 该类数据以时间排序
- 由于该类数据通常量级大(因此Sharding和Scale非常重要)或逻辑复杂(大量聚合,上取,下钻),关系数据库通常难以处理
- 时间序列数据按特性分为两类
- 高频率低保留期(数据采集,实时展示)
- 低频率高保留期(数据展现、分析)
- 按频度
- 规则间隔(数据采集)
- 不规则间隔(事件驱动)
- 时间序列数据的几个前提
- 单条数据并不重要
- 数据几乎不被更新,或者删除(只有删除过期数据时),新增数据是按时间来说最近的数据
- 同样的数据出现多次,则认为是同一条数据
如图:

时间序列数据库关键比对
| InfluxDB | ElasticSearch |
| 流行(TSDB排行第一) | 流行(搜索引擎排行第一) |
| 高可用需要收费 | 集群高可用容易实现,免费 |
| 单点写入性能高 | 单点写入性能低 |
| 查询语法简单,功能强 | 查询语法简单,功能强(弱于Influxdb) |
| 后端时序数据库设计,写入快 | 设计并不是时序数据库,后端存储采用文档结构,写入慢 |
由此可见:高频度低保留期用Influxdb,低频度高保留期用ES。
其他时序数据库介绍:

如何使用
数据的查询与写入:
- Influxdb与ES都是REST API风格接口
- 通过HTTP Post写入数据,通过HTTP Get获取数据,ES还有HTTP Put和Delete等
- 写入数据可以是JSON格式,Influxdb支持Line Protocol
- JSON格式徒增解析成本,录入数据格式越简单越好
- 通常ES搭配Logstash使用,Influxdb搭配telegraf使用
以Influxdb为例,看一些如何插入和查询数据:
Influxdb的HTTP API
创建DB
[root@host31 ~]# curl -i -XPOST http://192.168.32.31:8086/query --data-urlencode "q=CREATE DATABASE mydb" HTTP/1.1 200 OK Connection: close Content-Type: application/json Request-Id: 42a1f30c-5900-11e6-8003-000000000000 X-Influxdb-Version: 0.13.0 Date: Tue, 02 Aug 2016 22:27:13 GMT Content-Length: 16 {"results":[{}]}[root@host31 ~]#
写入数据
[root@host31 ~]# curl -i -XPOST http://192.168.32.31:8086/query --data-urlencode "q=CREATE DATABASE mydb" HTTP/1.1 200 OK Connection: close Content-Type: application/json Request-Id: 42a1f30c-5900-11e6-8003-000000000000 X-Influxdb-Version: 0.13.0 Date: Tue, 02 Aug 2016 22:27:13 GMT Content-Length: 16 {"results":[{}]}[root@host31 ~]#
查询写入的数据
[root@host31 ~]# curl -GET 'http://192.168.32.31:8086/query?pretty=true' --data-urlencode "db=mydb" --data-urlencode "q=SELECT \"value\" FROM \"cpu_load_short\" WHERE \"region\"='us-west'" { "results": [ { "series": [ { "name": "cpu_load_short", "columns": [ "time", "value" ], "values": [ [ "2015-06-11T20:46:02Z", 0.64 ] ] } ] } ] }[root@host31 ~]#
介绍Telegraf&Logstash:
- 都是数据收集和中转的工具,架构都是插件式配置
- Telegraf相比Logstash更加轻量
- 都支持大量源,包括关系数据库、NOSQL、直接收集操作系统信息(Linux、Win)、APP、服务(Docker)执行模式分为两种
- 主动:根据配置一次性读取被收集的数据,收集完成后关闭进程
- 被动:作为进程驻留内存,监听特定端口,等待消息发送
介绍两种时序数据库使用的架构:
1.日志采集,然后存入influxdb,最后在grafana 中进行可视化查询。
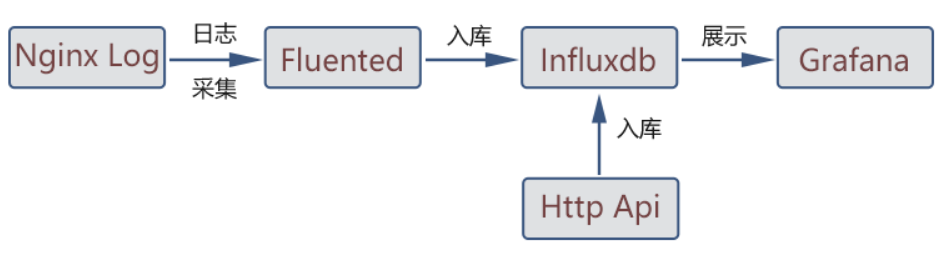
2.数据库监控,主要通过采集关系型数据库的性能指标分析数据库的运行状态便于监控和管理,如下图所示

数据可视化展示
数据的可视化展示有很多种选择,比如ELK中推荐使用kibana,配合es更方便,而搭配influxdb可以使用grafana。
目前grafana支持数据源
– ES
– Influxdb
– Prometheus
– Graphite
– OpenTSDB
– CloudWatch
安装Grafana
Grafana的安装很简单,以Debian安装为例:
执行命令: $ wget https://grafanarel.s3.amazonaws.com/builds/grafana_2.6.0_amd64.deb $ sudo apt-get install -y adduser libfontconfig $ sudo dpkg -i grafana_2.6.0_amd64.deb 启动服务器: $ sudo service grafana-server start
然后即可进行配置使用数据可视化了。这里就不展开讲了。下面会有独立文章介绍grafana和kibana。
总结
本篇简要概述了时序数据库的内容,介绍了特点并以influxdb为实例对比了与传统数据库的区别,以及如何使用Influxdb。最后讲解了使用时序数据库的架构,日志和监控等,通过grafana进行可视化的数据查询分析监控等。文章地址https://www.cnblogs.com/wenBlog/p/8297100.html


