spark和hadoop都是两个炙手可热的两个项目,都是大名鼎鼎, hadoop的联邦高可用集群已经搭建完毕。
今天基于新版的spark1.3.1并且构建在hadoop2.7上,安装过程如下:
安装前提, 安装好hadoop集群,略。
一. 安装scala
1. 进入下载页面 http://www.scala-lang.org/download/2.11.7.html
2. 下载如下scala版本 http://downloads.typesafe.com/scala/2.11.7/scala-2.11.7.tgz?_ga=1.131438735.1254462619.1436380164
3. 上传的服务器上相关目录
4. 解压缩scala文件 tar -xvf scala-2.11.7.tgz
5. 验证scala, 输入scala -version
Scala code runner version 2.11.7 -- Copyright 2002-2013, LAMP/EPFL
--- $ scala
Welcome to Scala version 2.11.7 (Java HotSpot(TM) 64-Bit Server VM, Java 1.6.0_37).
Type in expressions to have them evaluated.
Type :help for more information.
二. 下载spark
1. 进入下载页面 http://spark.apache.org/downloads.html 选择如下选项

2. 上传下载的spark程序到master服务器
3. 进入spark的master服务器,解压缩 tar xzvf spark-1.3.1-bin-hadoop2.6.tgz
4. 修改spark的相关目录, 修改为 spark1.3
三. 配置环境变量
1. 编辑环境变量 vi ~/.bash_profile
在文件最后添加如下内容:
HADOOP_PREFIX=/export/hh/hadoop-ha-zk
export HADOOP_PREFIX
export JAVA_HOME=/export/hh/jdk1.7.0_79
export CLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar
export SCALA_HOME=/export/hh/scala
export HADOOP_HOME=/export/hh/hadoop-ha-zk
export SPARK_HOME=/export/hh/spark1.3
export PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:${HADOOP_HOME}/bin
保存退出,
2. 运行 source ~/.bash_profile 是配置 在本机生效
3. 拷贝.bash_profile 文件到其他服务器
scp .bash_profile hh@mq66:~
。。。。。
四. 配置spark的环境变量
1. 进入spark的配置目录 cd /export/hh/spark1.3/conf 请根据自己的解压缩目录调整命令
2. 执行下面命令, cp spark-env.sh.template spark-env.sh 进行配置
3. 编辑vi spark-env.sh 文件, 在文件最后添加如下内容
export JAVA_HOME=/export/hh/jdk1.7.0_79
export SCALA_HOME=/export/hh/scala
export SPARK_WORKER_MEMORY=4g
export SPARK_MASTER_IP=mq65
export MASTER=spark://mq65:7077
保存退出
4. 拷贝配置文件到其他服务器, 执行下面命令
scp spark-env.sh hh@mq66:/export/hh/spark1.3/conf/
。。。。。
5. 编辑slaves文件, 输入如下命令
cp slaves.template slaves
vi slaves
添加如下内容:
mq65
mq66
。。。。。
保存退出
6. 拷贝配置文件 到其他服务器
scp slaves hh@mq66:/export/hh/spark1.3/conf
。。。。。
五. 启动spark集群
1. 启动spark分布式集群并查看信息
用下面命令启动spark集群 sbin/start-all.sh
用jps查看进程
jps
23016 NodeManager
21909 JournalNode
22120 DFSZKFailoverController
21678 DataNode
21559 NameNode
5870 Worker
5185 Master
6507 Jps
2. 页面查看集群状况:
http://mq65:8080/
进去spark集群的web管理页面,访问
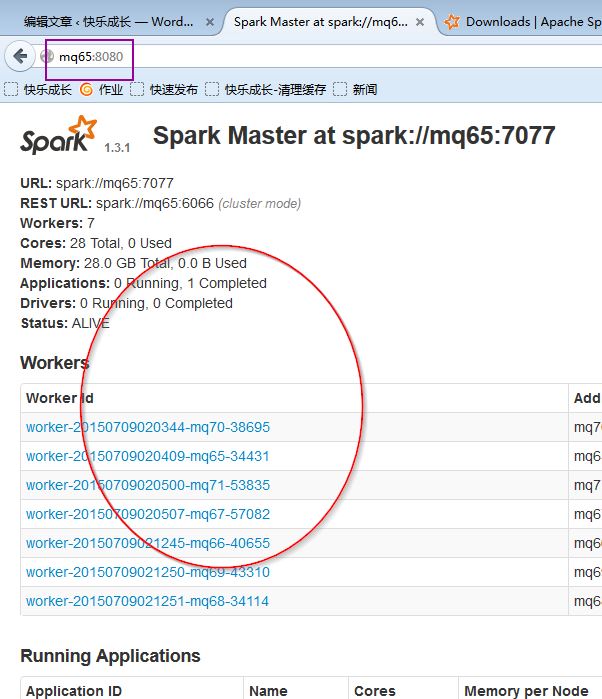
3. 我们进入spark的bin目录,启动spark-shell控制台
bin/spark-shell


现在我们已经顺利进入spark-shell的世界了
访问http://mq65:4040/,我们可以看到spark WEBUI页面
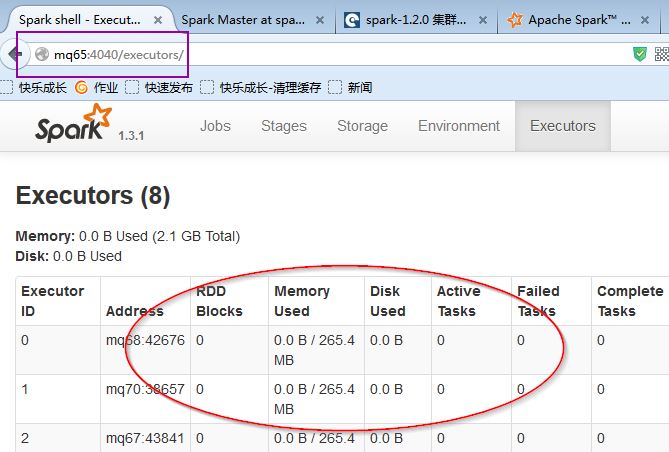
spark集群环境搭建成功了

