“Stream”是Trident中的核心数据模型,它被当做一系列的batch来处理。在Storm集群的节点之间,一个stream被划分成很多partition(分区),对流的操作(operation)是在每个partition上并行进行的。注:
①“Stream”是Trident中的核心数据模型:有些地方也说是TridentTuple,没有个标准的说法。
②一个stream被划分成很多partition:partition是stream的一个子集,里面可能有多个batch,一个batch也可能位于不同的partition上
Trident有五类操作(operation):
1、Partition-local operations,对每个partition的局部操作,不产生网络传输
2、Repartitioning operations:对数据流的重新划分(仅仅是划分,但不改变内容),产生网络传输
3、Aggregation operations:聚合操作
4、Operations on grouped streams:作用在分组流上的操作
5、Merge、Join操作
Partition-local operations
对每个partition的局部操作包括:function、filter、partitionAggregate、stateQuery、partitionPersist、project等。
Functions
一个function收到一个输入tuple后可以输出0或多个tuple,输出tuple的字段被追加到接收到的输入tuple后面。如果对某个 tuple执行function后没有输出tuple,则该tuple被过滤(filter),否则,就会为每个输出tuple复制一份输入tuple的 副本。假设有如下的function:
public class MyFunction extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
for(int i=0; i < tuple.getInteger(0); i++) {
collector.emit(new Values(i));
}
}
}
假设有个叫“mystream”的流(stream),该流中有如下tuple( tuple的字段为["a", "b", "c"] ),
[1, 2, 3]
[4, 1, 6]
[3, 0, 8]
运行下面的代码:
mystream.each(new Fields("b"), new MyFunction(), new Fields("d")))
则输出tuple中的字段为["a", "b", "c", "d"],如下所示
[1, 2, 3, 0]
[1, 2, 3, 1]
[4, 1, 6, 0]
Filters fileter收到一个输入tuple后可以决定是否留着这个tuple,看下面的filter:public class MyFilter extends BaseFilter {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(0) == 1 && tuple.getInteger(1) == 2;
}
}
假设你有如下这些tuple(包含的字段为["a", "b", "c"]):
[1, 2, 3]
[2, 1, 1]
[2, 3, 4]
运行下面的代码:
mystream.each(new Fields("b", "a"), new MyFilter())
则得到的输出tuple为:
[2, 1, 1]
partitionAggregate partitionAggregate对每个partition执行一个function操作(实际上是聚合操作),但它又不同于上面的functions操作,partitionAggregate的输出tuple将会取代收到的输入tuple,如下面的例子:mystream.partitionAggregate(new Fields("b"), new Sum(), new Fields("sum"))
假设输入流包括字段 ["a", "b"] ,并有下面的partitions:
Partition 0:
["a", 1]
["b", 2]
Partition 1:
["a", 3]
["c", 8]
Partition 2:
["e", 1]
["d", 9]
["d", 10]
则这段代码的输出流包含如下tuple,且只有一个”sum”的字段:
Partition 0:
[3]
Partition 1:
[11]
Partition 2:
[20]
上面代码中的new Sum()实际上是一个聚合器(aggregator),定义一个聚合器有三种不同的接口:CombinerAggregator、ReducerAggregator 和 Aggregator。
下面是CombinerAggregator接口:public interface CombinerAggregator extends Serializable {
T init(TridentTuple tuple);
T combine(T val1, T val2);
T zero();
}
一个CombinerAggregator仅输出一个tuple(该tuple也只有一个字段)。每收到一个输入 tuple,CombinerAggregator就会执行init()方法(该方法返回一个初始值),并且用combine()方法汇总这些值,直到剩 下一个值为止(聚合值)。如果partition中没有tuple,CombinerAggregator会发送zero()的返回值。下面是聚合器 Count的实现:
public class Count implements CombinerAggregator {
public Long init(TridentTuple tuple) {
return 1L;
}
public Long combine(Long val1, Long val2) {
return val1 + val2;
}
public Long zero() {
return 0L;
}
}
当使用aggregate()方法代替partitionAggregate()方法时,就能看到CombinerAggregation带来的好处。这种情况下,Trident会自动优化计算:先做局部聚合操作,然后再通过网络传输tuple进行全局聚合。
ReducerAggregator接口如下:public interface ReducerAggregator extends Serializable {
T init();
T reduce(T curr, TridentTuple tuple);
}
ReducerAggregator使用init()方法产生一个初始值,对于每个输入tuple,依次迭代这个初始值,最终产生一个单值输出tuple。下面示例了如何将Count定义为ReducerAggregator:
public class Count implements ReducerAggregator {
public Long init() {
return 0L;
}
public Long reduce(Long curr, TridentTuple tuple) {
return curr + 1;
}
}
最通用的聚合接口是Aggregator,如下:
public interface Aggregator extends Operation {
T init(Object batchId, TridentCollector collector);
void aggregate(T state, TridentTuple tuple, TridentCollector collector);
void complete(T state, TridentCollector collector);
}
Aggregator可以输出任意数量的tuple,且这些tuple的字段也可以有多个。执行过程中的任何时候都可以输出tuple(三个方法的参数中都有collector)。Aggregator的执行方式如下:
1、处理每个batch之前调用一次init()方法,该方法的返回值是一个对象,代表aggregation的状态,并且会传递给下面的aggregate()和complete()方法。2、每个收到一个该batch中的输入tuple就会调用一次aggregate,该方法中可以更新状态(第一点中init()方法的返回值)。
3、当该batch partition中的所有tuple都被aggregate()方法处理完之后调用complete方法。
注:理解batch、partition之间的区别将会更好的理解上面的几个方法。
下面的代码将Count作为Aggregator实现:public class CountAgg extends BaseAggregator {
static class CountState {
long count = 0;
}
public CountState init(Object batchId, TridentCollector collector) {
return new CountState();
}
public void aggregate(CountState state, TridentTuple tuple, TridentCollector collector) {
state.count+=1;
}
public void complete(CountState state, TridentCollector collector) {
collector.emit(new Values(state.count));
}
}
有时需要同时执行多个聚合操作,这个可以使用链式操作完成:
mystream.chainedAgg()
.partitionAggregate(new Count(), new Fields("count"))
.partitionAggregate(new Fields("b"), new Sum(), new Fields("sum"))
.chainEnd()
这段代码将会对每个partition执行Count和Sum聚合器,并输出一个tuple(字段为 ["count", "sum"])。
stateQuery and partitionPersist参见Trident state一文。
projection
经Stream中的project方法处理后的tuple仅保持指定字段(相当于过滤字段)。例如,mystream中的字段为 ["a", "b", "c", "d"],执行下面代码:
mystream.project(new Fields("b", "d"))
则输出流将仅包含["b", "d"]字段。
Repartitioning operations
Repartition操作可以改变tuple在各个task之上的划分。Repartition也可以改变Partition的数量。Repartition需要网络传输。下面都是repartition操作:
1、shuffle:随机将tuple均匀地分发到目标partition里。
2、broadcast:每个tuple被复制到所有的目标partition里,在DRPC中有用 — 你可以在每个partition上使用stateQuery。
3、partitionBy:对每个tuple选择partition的方法是:(该 tuple指定字段的hash值) mod (目标partition的个数),该方法确保指定字段相同的tuple能够被发送到同一个partition。(但同一个partition里可能有字 段不同的tuple)
4、global:所有的tuple都被发送到同一个partition。
5、batchGlobal:确保同一个batch中的tuple被发送到相同的partition中。
6、patition:该方法接受一个自定义分区的function(实现backtype.storm.grouping.CustomStreamGrouping)
Aggregation operations
Trident中有aggregate()和persistentAggregate()方法对流进行聚合操作。aggregate()在每个 batch上独立的执行,persistemAggregate() 对所有batch中的所有tuple进行聚合,并将结果存入state源中。
aggregate()对流做全局聚合,当使用ReduceAggregator或者Aggregator聚合器时,流先被重新划分成一个大分区 (仅有一个partition),然后对这个partition做聚合操作;另外,当使用CombinerAggregator时,Trident首先对 每个partition局部聚合,然后将所有这些partition重新划分到一个partition中,完成全局聚合。相比而 言,CombinerAggregator更高效,推荐使用。
下面的例子使用aggregate()对一个batch操作得到一个全局的count:
mystream.aggregate(new Count(), new Fields("count"))
同在partitionAggregate中一样,aggregate中的聚合器也可以使用链式用法。但是,如果你将一个CombinerAggregator链到一个非CombinerAggregator后面,Trident就不能做局部聚合优化。
关于persistentAggregate的用法请参见Trident state一文。
Operations on grouped streams
groupBy操作先对流中的指定字段做partitionBy操作,让指定字段相同的tuple能被发送到同一个partition里。然后在每个partition里根据指定字段值对该分区里的tuple进行分组。下面演示了groupBy操作的过程:
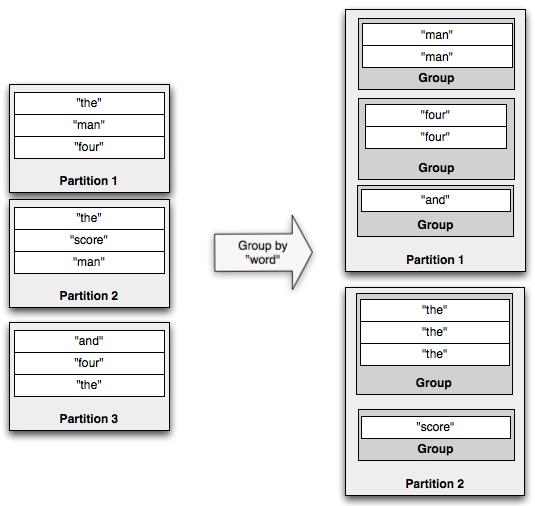
如果你在一个grouped stream上做聚合操作,聚合操作将会在每个分组(group)内进行,而不是整个batch上。GroupStream类中也有 persistentAggregate方法,该方法聚合的结果将会存储在一个key值为分组字段(即groupBy中指定的字段)的MapState 中,这些还是在Trident state一文中讲解。
和普通的stream一样,groupstream上的聚合操作也可以使用链式语法。
Merges(合并) and joins(连接)
最后一部分内容是关于将几个stream汇总到一起,最简单的汇总方法是将他们合并成一个stream,这个可以通过TridentTopology中德merge方法完成,就像这样:
topology.merge(stream1, stream2, stream3);
Trident指定新的合并之后的流中的字段为stream1中的字段。
另一种汇总方法是使用join(连接,类似于sql中的连接操作)。下面的在stream1( ["key", "val1", "val2"] ) 和 stream2[, "val1"]
两个流之间做连接操作:
topology.join(stream1, new Fields("key"), stream2, new Fields("x"), new Fields("key", "a", "b", "c"));
上面这个连接操作使用”key”和”x”字段作为连接字段。由于输入流中有重叠的字段名(如上面的val1字段在stream1和stream2中都有),Trident要求指定输出的新流中的所有字段。输出流中的tuple要包含下面这些字段:
1、连接字段列表:如本例中的输出流中的”key”字段对应stream1中的”key”和stream2中的”x”。
2、来自所有输入流中的非连接字段列表,按照传入join方法中的输入流的顺序:如本例中的”a”和”b”对应于stream1中的”val1″ 和 “val2″,”c” 对应stream2中的 “val1″。
Over.