这里说的是为服务设计模式, 题目很大, 也不知道能否说好, 先简单的有一下, 有问题的地方我在修改!
双十一刚刚过去, 我们也沾上一点双十一的热气,现在电商系统可谓五花八门,形形色色,表面看就是一个卖东西, 其实地下包括了商品展示、商品管理、商品库存、商家、支付、保险、运输等等非常多的环节。 有的商品是房子,有的商品是家电等等! 他们的购买流程是一样的吗?估计买房子的流程同其他的流程完全不同了!
一. 传统的单一服务应用
1. 传统单一服务系统应用场景
传统的应用系统通常如下图:

用户通过互联网访问应用系统, 然后在应用系统内部调用数据库系统。
通常情况下各个功能模块都集中在应用系统中,这样开发简单,维护方便,在业务量不大的情况下还是比较实用的。
但是到了双十一这个超级压力大的情况下, 传统的系统就有些问题了,如上图中小绿负责的模块包括了一个慢查询语句,这样系统的整个资源都被占满了, 造成其他相关模块无辜的被拖累。 具体如下图
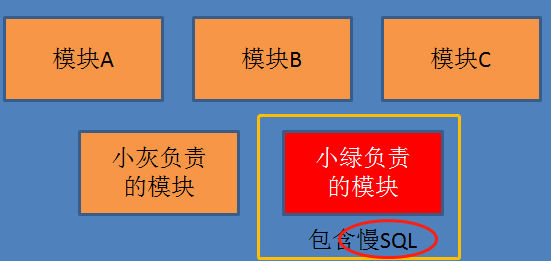
上图中可以清楚看到在传统的业务系统中经常将一系列耦合比较小或者相关性不大的模块合并到一起进行开发、测试、部署、维护等等, 这样在业务量不大时还看不出问题, 但当公司业务发展, 系统访问量增大后, 就有了上图的问题。
理论一点说法:传统的WEB应用核心分为业务逻辑、适配器以及API或通过UI访问的WEB界面。业务逻辑定义业务流程、业务规则以及领域实体。适配器包括数据库访问组件、消息组件以及访问接口等。尽管也是遵循模块化开发,但最终它们会打包并部署为单体式应用。例如Java应用程序会被打包成WAR,部署在Tomcat或者Jetty上。
2. 这种单体应用比较适合于小项目,优点是:
- 开发简单直接,集中式管理
- 基本不会重复开发
- 功能都在本地,没有分布式的管理开销和调用开销
3. 单体应用的缺点
当然它的缺点也十分明显,特别对于互联网公司来说:
缺点一:项目过于臃肿
当大大小小的功能模块都集中在同一项目的时候,整个项目必然会变得臃肿,让开发者难以维护。
缺点二:资源无法隔离
就像刚刚小灰的经历一样,整个单体系统的各个功能模块都依赖于同样的数据库、内存等资源,一旦某个功能模块对资源使用不当,整个系统都会被拖垮。
缺点三:无法灵活扩展
当系统的访问量越来越大的时候,单体系统固然可以进行水平扩展,部署在多台机器上组成集群:

但是这种扩展并非灵活的扩展。比如我们现在的性能瓶颈是支付模块,希望只针对支付模块做水平扩展,这一点在单体系统是做不到的。
缺点四:开发效率低
所有的开发在一个项目改代码,递交代码相互等待,代码冲突不断
缺点五:代码维护难
代码功能耦合在一起,新人不知道何从下手
缺点六:部署不灵活
构建时间长,任何小修改必须重新构建整个项目,这个过程往往很长
缺点七:稳定性不高
一个微不足道的小问题,可以导致整个应用挂掉
二. 微服务系统架构
1. 微服务的演化
现在大型互联网公司解决传统架构的一个必备的方式是采用微服务的架构方式,下面是一个简易的微服务示意图
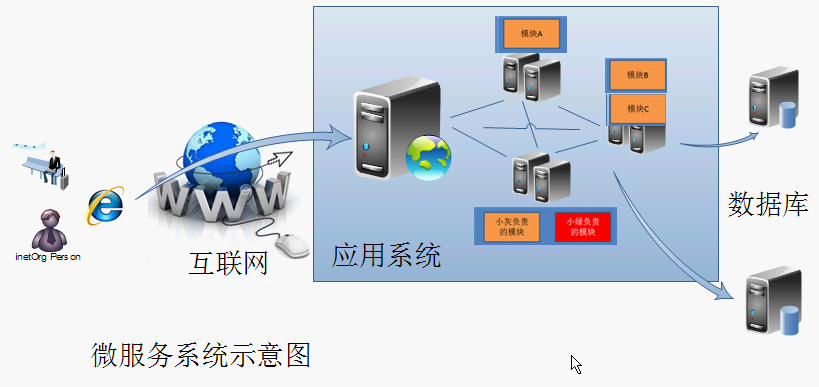
如上图, 将一个复杂的单一系统拆分为若干个上图中的小系统, 每个小系统包括原来的一个或者若干个功能模块, 这些小系统可以相互间进行调用,同时这些小系统可以通过一个统一的入口为用户提供服务。
这个方式的好处是, 小系统的功能单一, 不会由于一个慢查询而造成一个模块影响其他模块了。
另外小系统的功能简单开发、升级、维护都非常方便, 可以进行更好的迭代开发了, 快速升级系统。
准确一点的微服务定义如下:
2. 微服务定义
微服务(Microservice Architecture)是近几年流行的一种架构思想,关于它的概念很难一言以蔽之。
究竟什么是微服务呢?我们在此引用 ThoughtWorks 公司的首席科学家 Martin Fowler 的一段话:

In short, the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies.
谷歌翻译如下:
简而言之,微服务架构风格是一种将单个应用程序作为一套小型服务开发的方法,每种应用程序都在自己的进程中运行,并与轻量级机制(通常是HTTP资源API)进行通信。 这些服务是围绕业务功能构建的,可以通过全自动部署机制独立部署。 这些服务的集中管理最少,可以用不同的编程语言编写,并使用不同的数据存储技术。
简单说:
1)一组小的服务(大小没有特别的标准,只要同一团队的工程师理解服务的标识一致即可)
2)独立的进程(java的tomcat,nodejs等)
3)轻量级的通信(不是soap,是http协议)
4)基于业务能力(类似用户服务,商品服务等等)
5)独立部署(迭代速度快)
6)无集中式管理(无须统一技术栈,可以根据不同的服务或者团队进行灵活选择)
3. 微服务有什么样的具体特点呢?
1)它解决了复杂性问题。
它将单体应用分解为一组服务。虽然功能总量不变,但应用程序已被分解为可管理的模块或服务。这些服务定义了明确的RPC或消息驱动的API边界。微服务架构强化了应用模块化的水平,而这通过单体代码库很难实现。因此,微服务开发的速度要快很多,更容易理解和维护。
2)这种体系结构使得每个服务都可以由专注于此服务的团队独立开发。
只要符合服务API契约,开发人员可以自由选择开发技术。这就意味着开发人员可以采用新技术编写或重构服务,由于服务相对较小,所以这并不会对整体应用造成太大影响。
3)、独立部署,灵活扩展
传统的单体架构是以整个系统为单位进行部署,而微服务则是以每一个独立组件(例如用户服务,商品服务)为单位进行部署。
用一张经典的图来表现,就是下面这个样子:

图中左边是单体架构的集群,右边是微服务集群。
什么意思呢?比如根据每个服务的吞吐量不同,支付服务需要部署20台机器,用户服务需要部署30台机器,而商品服务只需要部署10台机器。这种灵活部署只有微服务架构才能实现。
4)、资源的有效隔离
微服务设计的原则之一,就是每一个微服务拥有独立的数据源,假如微服务A想要读写微服务B的数据库,只能调用微服务B对外暴露的接口来完成。这样有效避免了服务之间争用数据库和缓存资源所带来的问题。

5)微服务架构使得每个服务都可独立扩展。
我们只需定义满足服务部署要求的配置、容量、实例数量等约束条件即可。比如我们可以在EC2计算优化实例上部署CPU密集型服务,在EC2内存优化实例上部署内存数据库服务。
4.微服务架构的缺点和挑战
实际上并不存在silver bullets,微服务架构也会给我们带来新的问题和挑战。
1) 服务的粒度
微服务强调了服务大小,但实际上这并没有一个统一的标准。业务逻辑应该按照什么规则划分为微服务,这本身就是一个经验工程。有些开发者主张10-100行代码就应该建立一个微服务。虽然建立小型服务是微服务架构崇尚的,但要记住,微服务是达到目的的手段,而不是目标。微服务的目标是充分分解应用程序,以促进敏捷开发和持续集成部署。
2)分布式
微服务的另一个主要缺点是微服务的分布式特点带来的复杂性。开发人员需要基于RPC或者消息实现微服务之间的调用和通信,而这就使得服务之间的发现、服务调用链的跟踪和质量问题变得的相当棘手。
3)分布式数据库或者数据库调整
微服务的另一个挑战是分区的数据库体系和分布式事务。更新多个业务实体的业务交易相当普遍。这些类型的事务在单体应用中实现非常简单,因为单体应用往往只存在一个数据库。但在微服务架构下,不同服务可能拥有不同的数据库。CAP原理的约束,使得我们不得不放弃传统的强一致性,而转而追求最终一致性,这个对开发人员来说是一个挑战。
4)微服务测试
传统的单体WEB应用只需测试单一的REST API即可,而对微服务进行测试,需要启动它依赖的所有其他服务。这种复杂性不可低估。
5)服务的更改
比如在传统单体应用中,若有A、B、C三个服务需要更改,A依赖B,B依赖C。我们只需更改相应的模块,然后一次性部署即可。但是在微服务架构中,我们需要仔细规划和协调每个服务的变更部署。我们需要先更新C,然后更新B,最后更新A。
6)部署工作量
部署基于微服务的应用也要复杂得多。单体应用可以简单的部署在一组相同的服务器上,然后前端使用负载均衡即可。每个应用都有相同的基础服务地址,例如数据库和消息队列。而微服务由不同的大量服务构成。每种服务可能拥有自己的配置、应用实例数量以及基础服务地址。这里就需要不同的配置、部署、扩展和监控组件。此外,我们还需要服务发现机制,以便服务可以发现与其通信的其他服务的地址。因此,成功部署微服务应用需要开发人员有更好地部署策略和高度自动化的水平。
以上问题和挑战可大体概括为:
- API Gateway
- 服务间调用
- 服务发现
- 服务容错
- 服务部署
- 数据调用
幸运的是,出现了很多微服务框架,可以解决以上问题。
三. 从建设角度看待几个微服务实施过程中几个重要问题
1. 服务注册与发现
当然天下没有免费的盛宴, 微服务系统中, 由于部署维护的机器数量增多了, 另外服务和服务之间的调用关系也变复杂了。首先需要解决服务和服务之间调用的复杂性, 否则随着服务数量的变多, 如何让服务之间进行调用就造成了很大的麻烦, 而这个过程最好是能自动的进行服务找到要调用的服务。 解决办法是找一个公共的空间, 每个提供服务的应用程序, 先公共空间说明(注册)自己, 说明自己谁, 能提供什么服务, 提供方式如何等等。 调用方法也简单了, 也仅仅到公共空间查找自己要找到的服务, 从中获取相关信息,然后根据这个相关信息进行服务和服务之间的调用, 那么这个公共空间其实就是“服务注册中心”
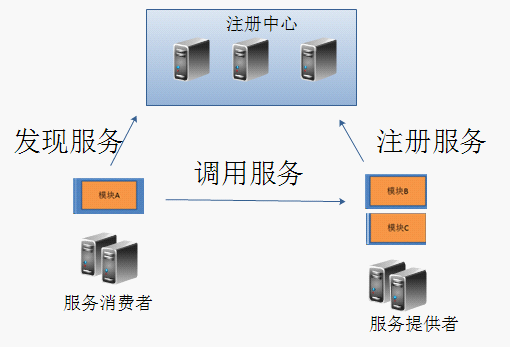
如上图, 通常把微服务中,提供服务给别人调用的系统叫做服务提供者, 把使用别人的服务的系统叫做服务的消费者。服务提供者在启动后要主动注册自己的信息到注册中心, 服务消费者在启动后要到注册中心查询谁提供了自己要调用的服务,这样当需要调用服务时,服务消费者之间通过网络连接调用服务提供者。
目前微服务框架很多, 我这里只说明我用过的, 也是最长久经过考验的, 经过双十一,618考验的系统
那个就是dubbo系统, dubbo的注册中心采用的是zookeeper集群, 并且他对zookeeper集群没有任何过多的依赖,就是一个单纯的集群就好。 不需要开发什么东西什么功能, 您部署了就好, zookeeper资料网上太多搜索一下就发现一堆。
2. 配置中心
目前大部分公司都是把配置写到配置文件中,遇到修改配置的情况,成本很高。并且没有修改配置的记录,出问题很难追溯。配置中心就接解决了以上的问题。
可配置内容:数据库连接,业务参数等等
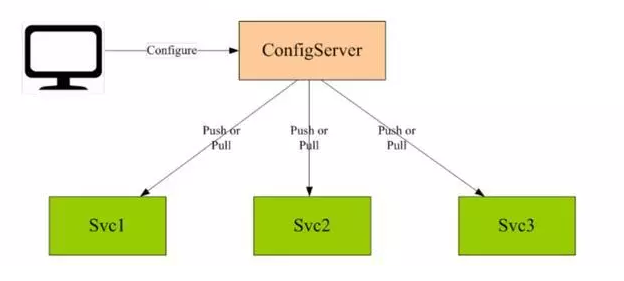
配置中心就是一个web服务,配置人员通过后台页面修改配置,各个服务就会得到新的配置参数。实现方式主要有两种,一种是push,另一种是pull。两张方式各有优缺点。push实时性较好,但是遇到网络抖动,会丢失消息。pull不会丢失消息但是实时性差一些。大家可以同时两种方式使用,实现一个比较好的效果。如下图所示,这是一个国内知名互联网公司的配置中心架构图。
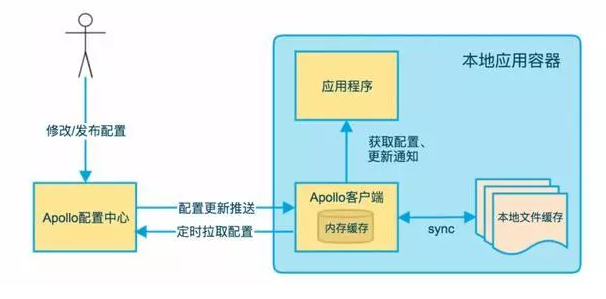
开源地址:http://github.com/ctripcorp/appollo
3. 监控中心
监控预警对于微服务很重要,一个可靠的监控预警体系对微服务运行至关重要。一般监控分为如下层次:

从基础设施到用户端,层层有监控,全方位,多角度,每一个层面都很重要。总体来说,微服务可分5个监控点:日志监控,Metrics监控,健康检查,调用链检查,告警系统
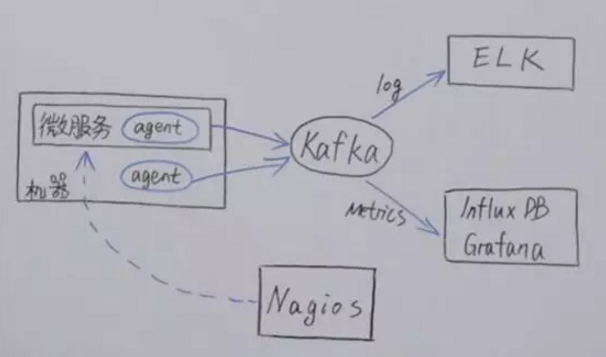
监控架构
下面的图是大部分公司的一种监控架构图。每一个服务都有一个agent,agent收集到关键信息,会传到一些MQ中,为了解耦。同时将日志传入ELK,将Metrics传入InfluxDB时间序列库。而像nagios,可以定期向agent发起信息检查微服务。
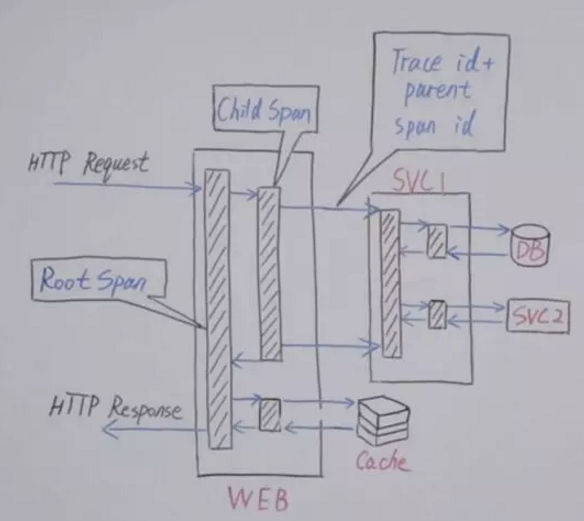
调用链监控APM
很多公司都有调用链监控,就譬如阿里有鹰眼监控,点评的Cat,大部分调用链监控(没错,我指的Zipkin)架构是这样的
1、Pinpoint github地址:GitHub – naver/pinpoint: Pinpoint is an open source APM (Application Performance Management) tool for large-scale distributed systems written in Java. 对java领域的性能分析有兴趣的朋友都应该看看这个开源项目,这个是一个韩国团队开源出来的,通过JavaAgent的机制来做字节码代码植入,实现加入traceid和抓取性能数据的目的。 NewRelic、Oneapm之类的工具在java平台上的性能分析也是类似的机制。
2、SkyWalking github地址:wu-sheng/sky-walking 这是国内一位叫吴晟的兄弟开源的,也是一个对JAVA分布式应用程序集群的业务运行情况进行追踪、告警和分析的系统,在github上也有400多颗星了。 功能相对pinpoint还是稍弱一些,插件还没那么丰富,不过也很难得了。
3、Zipkin 官网:OpenZipkin · A distributed tracing system github地址:GitHub – openzipkin/zipkin: Zipkin is a distributed tracing system 这个是twitter开源出来的,也是参考Dapper的体系来做的。
Zipkin的java应用端是通过一个叫Brave的组件来实现对应用内部的性能分析数据采集。 Brave的github地址:github.com/openzipkin/… 这个组件通过实现一系列的java拦截器,来做到对http/servlet请求、数据库访问的调用过程跟踪。 然后通过在spring之类的配置文件里加入这些拦截器,完成对java应用的性能数据采集。
4、CAT github地址:GitHub – dianping/cat: Central Application Tracking 这个是大众点评开源出来的,实现的功能也还是蛮丰富的,国内也有一些公司在用了。 不过他实现跟踪的手段,是要在代码里硬编码写一些“埋点”,也就是侵入式的。 这样做有利有弊,好处是可以在自己需要的地方加埋点,比较有针对性;坏处是必须改动现有系统,很多开发团队不愿意。
5、Xhprof/Xhgui 这两个工具的组合,是针对PHP应用提供APM能力的工具,也是非侵入式的。 Xhprof github地址:GitHub – preinheimer/xhprof: XHGUI is a GUI for the XHProf PHP extension, using a database backend, and pretty graphs to make it easy to use and interpret. Xhgui github地址:GitHub – perftools/xhgui: A graphical interface for XHProf data built on MongoDB 我对PHP不熟,不过网上介绍这两个工具的资料还是蛮多的。
