结构概述
跟踪器(Tracers)存在在你的应用程序中生存,记录时间和关于操作的元数据。他们经常使用库,因此他们的使用对用户是透明的。例如,当它收到一个请求并发送一个响应时,一个感应器(instrumented )的web服务器记录。所收集的跟踪数据称为Span。
在生产过程中,instrumention是安全的,并且没有太多的开销。由于这个原因,他们只在带内(in-band)传播id,告诉接收方有一个正在进行中的跟踪。完成的跨度被报告给Zipkin的“外带(out-of-band)”,类似于应用程序如何异步地报告指标。
例如,当一个操作被跟踪,它需要发出一个传出的http请求时,会添加几个头来传播IDs。header不用于发送诸如操作名称之类的细节。
将数据发送给Zipkin的应用程序的一种组件被称为Reporter。记者(Reporters)通过几个传输器(transports )中的一个传输跟踪数据到Zipkin收集器(collectors),这些收集器将跟踪数据保存到存储(storage)中。稍后,通过API查询存储,以向UI提供数据。
下面是一个描述这个流程的图表:
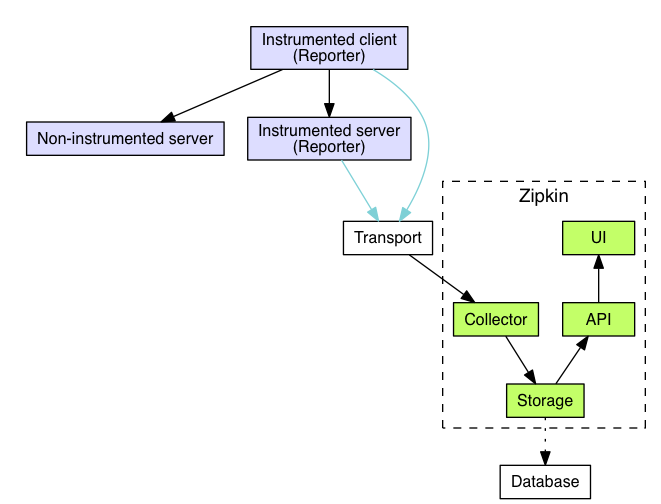
要查看一个工具库是否已经存在于您的平台上,请参见清单
示例流
正如在概述中提到的,标识符被发送到带,而细节则被发送到Zipkin。在这两种情况下,跟踪工具都负责创建有效的跟踪并正确地呈现它们。例如,一个跟踪程序确保了它在带(下游)和带外(异步)的数据之间的奇偶性。
下面是http跟踪的一个示例序列,其中用户代码调用资源/foo。这就产生了一个单一的Span,在用户代码收到http响应后,异步发送给Zipkin。
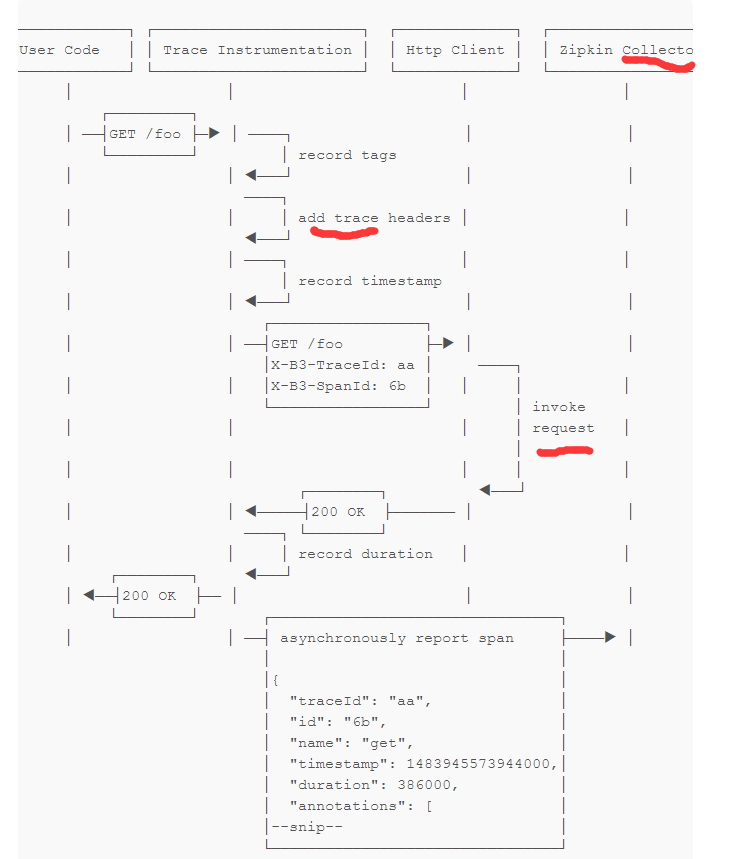
跟踪工具报告的范围是异步的,以防止延迟或故障与跟踪系统延迟或中断用户代码有关。
Transport
由测试库发送的数据(Spans)必须从追踪到Zipkin的collectors的服务中传输。有三种主要的传输方式:HTTP、Kafka和Scribe。
Components
- collector
- storage
- search
- web UI
Zipkin Collector
一旦跟踪数据到达了Zipkin Collector守护程序,就会被Zipkin的收集器进行验证、存储和索引。
Storage
Zipkin最初是为了存储Zipkin的数据而建立的,因为Cassandra是可扩展的,有一个灵活的模式,在Twitter上被大量使用。但是,我们使这个组件可插拔。除了Cassandra之外,我们还支持弹性搜索和MySQL。其他的后端可以作为第三方扩展来提供。
Zipkin Query Service
一旦数据被存储和索引,我们就需要一种方法来提取数据。查询守护进程提供一个简单的JSON API用于查找和检索跟踪。这个API的主要使用者是Web UI。
Web UI
我们创建了一个GUI,为查看跟踪提供了一个很好的界面。web UI提供了一种基于服务、时间和注释查看跟踪的方法。注意:UI中没有内置的身份验证机制!