一、关于Harbor
VMware公司最近开源了企业级Registry项目Harbor,由VMware中国研发的团队负责开发。
Harbor是一个用于存储和分发Docker镜像的企业级Registry服务器,通过添加一些企业必需的功能特性,例如安全、标识和管理等,扩展了开源Docker Distribution。作为一个企业级私有Registry服务器,Harbor提供了更好的性能和安全。提升用户使用Registry构建和运行环境传输镜像的效率。Harbor支持安装在多个Registry节点的镜像资源复制,镜像全部保存在私有Registry中, 确保数据和知识产权在公司内部网络中管控。另外,Harbor也提供了高级的安全特性,诸如用户管理,访问控制和活动审计等。
- 基于角色的访问控制 – 用户与Docker镜像仓库通过“项目”进行组织管理,一个用户可以对多个镜像仓库在同一命名空间(project)里有不同的权限。
- 镜像复制 – 镜像可以在多个Registry实例中复制(同步)。尤其适合于负载均衡,高可用,混合云和多云的场景。
- 图形化用户界面 – 用户可以通过浏览器来浏览,检索当前Docker镜像仓库,管理项目和命名空间。
- AD/LDAP 支持 – Harbor可以集成企业内部已有的AD/LDAP,用于鉴权认证管理。
- 审计管理 – 所有针对镜像仓库的操作都可以被记录追溯,用于审计管理。
- 国际化 – 已拥有英文、中文、德文、日文和俄文的本地化版本。更多的语言将会添加进来。
- RESTful API – RESTful API 提供给管理员对于Harbor更多的操控, 使得与其它管理软件集成变得更容易。
- 部署简单 – 提供在线(online)和离线(offline)两种安装工具, 也可以安装到vSphere平台(OVA方式)虚拟设备。
官方中文文档:https://vmware.github.io/harbor/cn
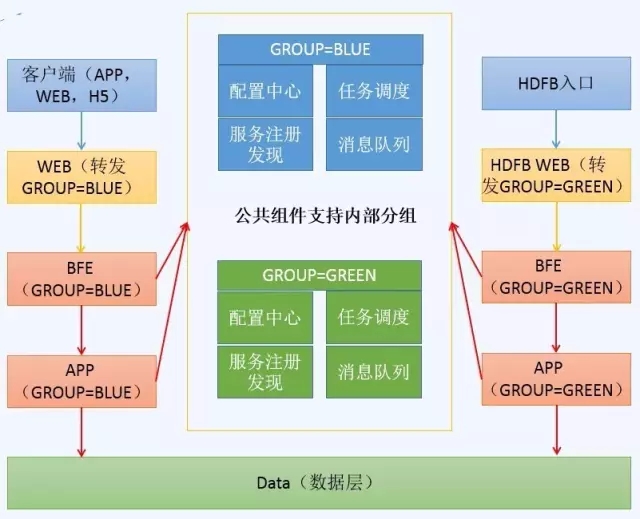
二、架构分解

Harbor在架构上主要由五个组件构成:
Proxy
Harbor的registry, UI, token等服务,通过一个前置的反向代理统一接收浏览器、Docker客户端的请求,并将请求转发给后端不同的服务。
Registry
负责储存Docker镜像,并处理dockerpush/pull 命令。由于我们要对用户进行访问控制,即不同用户对Docker image有不同的读写权限,Registry会指向一个token服务,强制用户的每次docker pull/push请求都要携带一个合法的token,Registry会通过公钥对token 进行解密验证。
Core services
这是Harbor的核心功能,主要提供以下服务:
UI(harbor-ui)
提供图形化界面,帮助用户管理registry上的镜像(image), 并对用户进行授权。
webhook
为了及时获取registry上image状态变化的情况, 在Registry上配置webhook,把状态变化传递给UI模块。
token服务
负责根据用户权限给每个docker push/pull命令签发token.Docker客户端向Regiøstry服务发起的请求,如果不包含token,会被重定向到这里,获得token后再重新向Registry进行请求。
Database(harbor-db)
为coreservices提供数据库服务,负责储存用户权限、审计日志、Docker image分组信息等数据。
Log collector(harbor-log)
为了帮助监控Harbor运行,负责收集其他组件的log,供日后进行分析。
Harbor的每个组件都是以Docker容器的形式构建的,因此很自然地,我们使用Docker Compose来对它进行部署。在源代码中(https://github.com/vmware/harbor), 用于部署Harbor的Docker Compose模板位于harbor/make/docker-compose.tpl。
三、安装Harbor
Harbor被部署为多个Docker容器,因此可以部署在任何支持Docker的Linux发行版上。目标主机需要安装Python,Docker和Docker Compose。
1 2 3 | $ uname -r 3.10.0-327.el7.x86_64 $ yum install docker docker-compose |
Harbor安装步骤归结为以下几点:
- 下载安装程序;
- 配置harbor.cfg文件;
- 运行install.sh来安装并启动Harbor;
下载安装程序:
安装程序的二进制文件可以从发布页面下载。选择在线或离线安装程序。使用tar命令解压缩包。
在线安装程序:$ tar xvf harbor-online-installer-<version>.tgz
脱机安装程序:$ tar xvf harbor-offline-installer-<version>.tgz
然后用离线二进制安装包:
1 2 | $ wget http://harbor.orientsoft.cn/harbor-1.2.2/harbor-offline-installer-v1.2.2.tgz $ tar xvf harbor-offline-installer-v1.2.2.tgz -C /opt/ |
四、配置Harbor
配置参数位于文件harbor.cfg中。
harbor.cfg中有两类参数,所需参数和可选参数。
- 所需参数:这些参数需要在配置文件harbor.cfg中设置,如果用户更新它们并运行install.sh脚本重新安装Harbour,参数将生效。
- 可选参数:这些参数对于更新是可选的,即用户可以将其保留为默认值,并在启动Harbour后在Web UI上进行更新。如果他们进入harbor.cfg,他们只会在第一次启动Harbor时生效,随后对这些参数的更新,harbor.cfg将被忽略。
注意:如果你选择通过UI设置这些参数,请确保在启动Harbour后立即执行此操作。具体来说,你必须在注册或在Harbor中创建任何新用户之前设置所需的auth_mode。当系统中有用户时(除了默认的admin用户), auth_mode不能被修改。
所需参数:
- hostname:用于访问用户界面和register服务。它应该是目标机器的IP地址或完全限定的域名(FQDN),例如192.168.1.10或reg.yourdomain.com。不要使用localhost或127.0.0.1为主机名。
- ui_url_protocol:(http或https,默认为http)用于访问UI和令牌/通知服务的协议。如果公证处于启用状态,则此参数必须为https。
- max_job_workers:镜像复制作业线程。
- db_password:用于db_auth的MySQL数据库的root密码。
- customize_crt:打开或关闭,默认打开)打开此属性时,准备脚本创建私钥和根证书,用于生成/验证注册表令牌。当由外部来源提供密钥和根证书时,将此属性设置为off。
- ssl_cert:SSL证书的路径,仅当协议设置为https时才应用。
- ssl_cert_key:SSL密钥的路径,仅当协议设置为https时才应用。
- secretkey_path:用于在复制策略中加密或解密远程register密码的密钥路径。
可选参数:
- 电子邮件设置:Harbor需要这些参数才能向用户发送“密码重置”电子邮件,并且只有在需要该功能时才需要。另外,请注意,在默认情况下SSL连接时没有启用-如果你的SMTP服务器需要SSL,但不支持STARTTLS,那么你应该通过设置启用SSL email_ssl = TRUE。
1 2 3 4 5 6 7 | email_server = smtp.mydomain.com email_server_port = 25 email_identity = email_username = sample_admin@mydomain.com email_password = abc email_from = admin sample_admin@mydomain.com email_ssl = false |
- harbour_admin_password:管理员的初始密码,这个密码只在Harbour第一次启动时生效。之后,此设置将被忽略,并且应在UI中设置管理员的密码。请注意,默认的用户名/密码是admin/Harbor12345。
- auth_mode:使用的认证类型,默认情况下,它是db_auth,即凭据存储在数据库中。对于LDAP身份验证,请将其设置为ldap_auth。
1 2 3 4 5 6 7 | ldap_url = ldaps://ldap.mydomain.com ldap_searchdn = uid=searchuser,ou=people,dc=mydomain,dc=com ldap_search_pwd = password ldap_basedn = ou=people,dc=mydomain,dc=com ldap_uid = uid ldap_scope = 3 ldap_timeout = 5 |
- self_registration:( 打开或关闭,默认打开)启用/禁用用户注册功能。禁用时,新用户只能由Admin用户创建,只有管理员用户可以在Harbour中创建新用户。 注意:当auth_mode设置为ldap_auth时,自注册功能将始终处于禁用状态,并且该标志被忽略。
- token_expiration:由令牌服务创建的令牌的到期时间(分钟),默认为30分钟。
- project_creation_restriction:用于控制哪些用户有权创建项目的标志。默认情况下,每个人都可以创建一个项目,设置为“adminonly”,这样只有admin可以创建项目。
- verify_remote_cert:( 打开或关闭,默认打开)此标志决定了当Harbour与远程register实例通信时是否验证SSL/TLS证书。将此属性设置为off将绕过SSL/TLS验证,这在远程实例具有自签名或不可信证书时经常使用。
另外,默认情况下,Harbour将镜像存储在本地文件系统上。在生产环境中,你可以考虑使用其他存储后端而不是本地文件系统,如S3,Openstack Swift,Ceph等。你需要更新common/templates/registry/config.yml文件。例如,如果你使用Openstack Swift作为存储后端,那么该部分可能如下所示:
1 2 3 4 5 6 7 8 9 | storage: swift: username: admin password: ADMIN_PASS authurl: http://keystone_addr:35357/v3/auth tenant: admin domain: default region: regionOne container: docker_images |
配置完成就可以启动Harbor了,如下操作:
1 | $ sudo ./install.sh |
查看启动镜像
1 2 3 4 5 6 7 8 9 10 | $ docker-compose ps Name Command State Ports ------------------------------------------------------------------------------------------------------------------------------ harbor-adminserver /harbor/harbor_adminserver Up harbor-db docker-entrypoint.sh mysqld Up 3306/tcp harbor-jobservice /harbor/harbor_jobservice Up harbor-log /bin/sh -c crond && rm -f ... Up 127.0.0.1:1514->514/tcp harbor-ui /harbor/harbor_ui Up nginx nginx -g daemon off; Up 0.0.0.0:443->443/tcp, 0.0.0.0:4443->4443/tcp, 0.0.0.0:80->80/tcp registry /entrypoint.sh serve /etc/ ... Up 5000/tcp |
如果一切正常,你应该可以打开浏览器访问http://reg.yourdomain.com的管理页面(将reg.yourdomain.com更改为你的主机名harbor.cfg)。请注意,默认的管理员用户名/密码是admin/Harbor12345。

至此, Harbor已经搭建完成,具体在WEB UI下面操作也是非常的简单,只有几个选项。
登录管理员界面后可以创建一个新项目,例如myproject。然后,你可以使用docker命令在本地通过127.0.0.1来登录和推送镜像了(默认情况下,Register服务器在端口80上侦听),首先登录Harbor:
1 2 3 4 5 6 7 8 9 | # 登录Harbor; $ docker login -u admin -p Harbor12345 http://127.0.0.1 Login Succeeded # 镜像打tag; $ docker push 127.0.0.1/myproject/wordpress:mytag # 上传镜像到Harbor; $ docker push 127.0.0.1/myproject/wordpress:mytag |
都操作成功之后,在Harbor界面myproject目录下就可以看见这个镜像,以及这个镜像的一些信息:

但是,以上操作都是在Harbor本地,如果其他客户端操作Harbor,就会报如下错误:
1 2 | $ docker login -u admin -p Harbor12345 http://10.10.0.109 Error response from daemon: Get https://10.10.0.109/v1/users/: dial tcp 10.10.0.109:443: getsockopt: connection refused |
报错了,由于Harbor的默认安装使用HTTP,而Register v2版本开始必须使用HTTPS,因此你需要将该选项添加 --insecure-registry到客户端的Docker守护程序并重新启动Docker服务。在Docker客户端配置如下:
1 2 | $ cat /etc/docker/daemon.json { "insecure-registries":["10.10.0.109:80"] } |
然后重启docker,再次登录就可以了:
1 2 3 | $ systemctl restart docker $ docker login -u admin -p Harbor12345 10.10.0.109:80 Login Succeeded |
五、开启公证服务器
要使用公证服务安装Harbor,请在运行时install.sh时添加一个参数:
1 | $ ./install.sh --with-notary |
注:对于使用公证进行安装,必须将参数ui_url_protocol。设置为“https”开头有关配置HTTPS的信息,请参阅以下章节。有关公证和Docker的内容信任的更多信息,请参阅Docker的文档:https://docs.docker.com/engine/security/trust/content_trust
5.1 获得证书
安装之前首先需要在Harbor服务器上创建ca证书和私钥,以及签发Harbor要使用的证书和私钥。假设你的register的主机名是dockerhub.ywnds.com,并且其DNS记录指向你正在运行Harbour的主机。你首先应该从CA获得一个证书。证书通常包含.crt文件和.key文件,例如ywnds.com.crt和ywnds.com.key。
在测试或开发环境中,你可以选择使用自签名证书而不是CA中的证书。以下命令生成你自己的证书:
1. 创建你自己的CA证书
1 2 3 4 5 6 7 8 | $ openssl req -newkey rsa:4096 -nodes -sha256 -keyout /data/cert/ca.key -x509 -days 365 -out /data/cert/ca.crt Country Name (2 letter code) [XX]:cn State or Province Name (full name) []:sh Locality Name (eg, city) [Default City]:sh Organization Name (eg, company) [Default Company Ltd]:ca Organizational Unit Name (eg, section) []:ca Common Name (eg, your name or your server's hostname) []:10.10.0.109 Email Address []:admin@ca.com |
2. 生成证书签名请求
如果使用像dockerhub.ywnds.com这样的FQDN连接register主机,则必须使用dockerhub.ywnds.com作为CN(通用名称)。否则,如果你使用IP地址连接你的register主机,CN可以是任何类似你的名字等等:
1 2 3 4 5 6 7 8 9 10 11 12 13 | $ openssl req -newkey rsa:4096 -nodes -sha256 -keyout /data/cert/ywnds.com.key -out /data/cert/ywnds.com.csr Country Name (2 letter code) [XX]:cn State or Province Name (full name) []:sh Locality Name (eg, city) [Default City]:sh Organization Name (eg, company) [Default Company Ltd]:ywnds Organizational Unit Name (eg, section) []:tech Common Name (eg, your name or your server's hostname) []:10.10.0.109 Email Address []:admin@ywnds.com Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: An optional company name []: |
3. 生成register主机的证书
如果你使用的是像dockerhub.ywnds.com这样的FQDN来连接您的register主机,请运行以下命令以生成register主机的证书:
1 | $ openssl x509 -req -days 365 -in /data/cert/ywnds.com.csr -CA /data/cert/ca.crt -CAkey /data/cert/ca.key -CAcreateserial -out /data/cert/ywnds.com.crt |
如果你使用的是IP,比如你的register主机是10.10.0.109,你可以运行下面的命令生成证书:
1 2 | $ echo subjectAltName = IP:10.10.0.109 > extfile.cnf $ openssl x509 -req -days 365 -in /data/cert/ywnds.com.csr -CA /data/cert/ca.crt -CAkey /data/cert/ca.key -CAcreateserial -extfile extfile.cnf -out /data/cert/ywnds.com.crt |
5.2 安装配置
接下来,编辑harbor.cfg文件,更新主机名和协议,并更新属性ssl_cert和ssl_cert_key:
1 2 3 4 5 6 7 8 9 | # set hostname hostname = 10.10.0.109 # set ui_url_protocol ui_url_protocol = https # set certificate ssl_cert = /data/cert/ywnds.com.crt ssl_cert_key = /data/cert/ywnds.com.key |
为Harbour生成配置文件(harbor目录下执行,如果有配置错误会报错这里):
1 | $ ./prepare |
如果Harbor已经在运行,请停止并删除现有的实例,但是你的镜像数据会保留在文件系统中。
1 | $ docker-compose down |
最后重启Harbour:
1 | $ docker-compose up -d |
为Harbour设置HTTPS后,可以通过以下步骤进行验证:
1. 打开浏览器并输入地址:https://reg.yourdomain.com。它应该显示Harbor的用户界面。
2. 在具有Docker守护进程的机器上,确保选项“ --insecure-registry”不存在,并且你必须将上述步骤中生成的ca.crt复制到/etc/docker/certs.d/reg.yourdomain.com(或你的register主机IP),如果该目录不存在,请创建它。如果你将nginx端口443映射到另一个端口,则应该创建目录/etc/docker/certs.d/reg.yourdomain.com:port(或您的注册表主机IP:端口)。如下操作:
1 2 | $ mkdir /etc/docker/certs.d/10.10.0.109:443/ $ mv ca.crt /etc/docker/certs.d/10.10.0.109:443/ |
然后运行任何docker命令来验证设置,例如:
1 2 | $ docker login -u admin -p Harbor12345 https://10.10.0.109:443 Login Succeeded |
认证成功之后,可以进行镜像上传下载了。
参考:Configuring Harbor with HTTPS Access
六、Harbor实现
Docker login的流程
使用docker login登陆Harbor
1 | $ docker login -u admin -p Harbor12345 http://10.10.0.109 |
当用户输入所需信息并点击回车后,Docker客户端会向地址”10.10.0.109/v1/”发出HTTP GET请求。Harbor的各个容器会通过以下步骤处理:

a) 首先,这个请求会由监听80端口的proxy容器接收到。根据预先设置的匹配规则,容器中的Nginx会将请求转发给后端的registry容器;
b) 在registry容器一方,由于配置了基于token的认证,registry会返回错误代码401,提示Docker客户端访问token服务绑定的URL。在Harbor中,这个URL指向Core Services;
c) Docker客户端在接到这个错误代码后,会向token服务的URL发出请求,并根据HTTP协议的Basic Authentication规范,将用户名密码组合并编码,放在请求头部(header);
d) 类似地,这个请求通过80端口发到proxy容器后,Nginx会根据规则把请求转发给ui容器,ui容器监听token服务网址的处理程序接收到请求后,会将请求头解码,得到用户名、密码;
e) 在得到用户名、密码后,ui容器中的代码会查询数据库,将用户名、密码与mysql容器中的数据进行比对(注:ui容器还支持LDAP的认证方式,在那种情况下ui会试图和外部LDAP服务进行通信并校验用户名/密码)。比对成功,ui容器会返回表示成功的状态码,并用密钥生成token,放在响应体中返回给Docker客户端。
至此,一次docker login成功地完成了,Docker客户端会把步骤(c)中编码后的用户名密码保存在本地的隐藏文件中。
Docker push的流程

用户登录成功后用docker push命令向Harbor推送一个Docker image:
1 2 3 4 5 | # 创建一个镜像; $ docker tag wordpress 10.10.0.109/myproject/wordpress # push镜像到harbor; $ docker push 10.10.0.109/myproject/wordpress |
a) 首先,docker客户端会重复login的过程,首先发送请求到registry,之后得到token服务的地址;
b) 之后,Docker客户端在访问ui容器上的token服务时会提供额外信息,指明它要申请一个对wordpress进行push操作的token;
c) token服务在经过Nginx转发得到这个请求后,会访问数据库核实当前用户是否有权限对该image进行push。如果有权限,它会把image的信息以及push动作进行编码,并用私钥签名,生成token返回给Docker客户端;
d) 得到token之后Docker客户端会把token放在请求头部,向registry发出请求,试图开始推送image。Registry收到请求后会用公钥解码token并进行核对,一切成功后,image的传输就开始了。
七、管理Harbor
你可以使用docker-compose来管理Harbor。一些有用的命令如下所示(必须在与docker-compose.yml相同的目录中运行)。
停止/启动/重启Harbor:
1 2 3 | $ docker-compose stop $ docker-compose start $ docker-compose restart |
要更改Harbour的配置,请先停止现有的Harbour实例并更新harbor.cfg。然后运行prepare脚本来填充配置。最后重新创建并启动Harbour的实例:
1 2 3 4 | $ docker-compose down -v $ vim harbor.cfg $ ./prepare $ docker-compose up -d |
配置Harbour在自定义端口上侦听
默认情况下,Harbour侦听端口80(HTTP)和443(HTTPS,如果已配置)同时用于管理界面和docker命令,则可以使用定制的命令对其进行配置。
修改docker-compose.yml文件,将里面的端口替换为自定义的端口,例如8888:80。
<参考>
安装和配置指南
用户使用指南