QR码生成原理-QR Code(ISO 18004)编码方式
相关网站:http://www.swetake.com/qrcode/qr2_en.html
一、什么是QR码
QR码属于矩阵式二维码中的一个种类,由DENSO(日本电装)公司开发,由JIS和ISO将其标准化。QR码的样子其实在很多场合已经能够被看到了
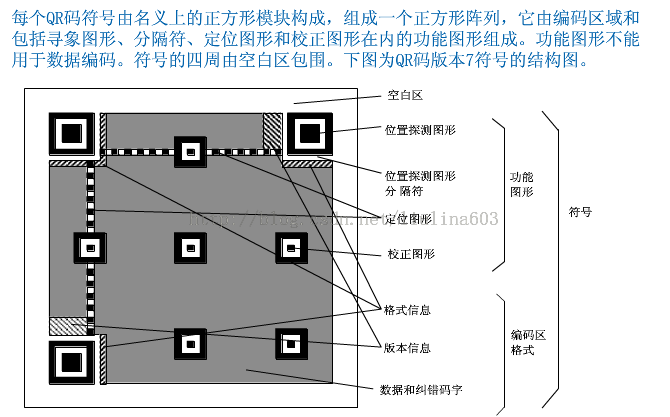
![]()
1. 位置探测图形、位置探测图形分隔符:用于对二维码的定位,对每个QR码来说,位置都是固定存在的,只是大小规格会有所差异;这些黑白间隔的矩形块很容易进行图像处理的检测。
2. 校正图形:根据尺寸的不同,矫正图形的个数也不同。矫正图形主要用于QR码形状的矫正,尤其是当QR码印刷在不平坦的面上,或者拍照时候发生畸变等。
3. 定位图形:这些小的黑白相间的格子就好像坐标轴,在二维码上定义了网格。
4. 格式信息:表示该二维码的纠错级别,分为L、M、Q、H;
5. 数据区域:使用黑白的二进制网格编码内容。8个格子可以编码一个字节。
6. 版本信息:即二维码的规格,QR码符号共有40种规格的矩阵(一般为黑白色),从21x21(版本1),到177x177(版本40),每一版本符号比前一版本 每边增加4个模块。
7. 纠错码字:用于修正二维码损坏带来的错误。
二。 QR二维码的识别原理
2.2.1定位 手机拍摄QR 码图像时,可能会同时采集到条码周围其他的图像。这些干扰图像会增加图像处理的复杂度,因此,可以把这些没必要的干扰图像通过裁切的方式去除。校正后,直 接对正方形A'B'C'D'外的区域裁切,就可以去除其余背景。 QR 码符号中有3 个位置探测图形,分别位于符号图像4 个角中的3 个角,每个 4 位置探测图像都是由固定深浅颜色的模块组成。模块深浅颜色顺序为深色—浅色—深色—浅色—深色,各元素宽度的比例为1∶ 1∶ 3∶ 1∶ 1
即使图像有旋转,位置探测图像的模块颜色顺序和宽度比例也不变。对二值化后的图像按行、列分别逐点扫描,把同一灰度级的相邻像素记录为线段。如果有 5 段线段的长度比例符合1∶ 1∶ 3 ∶ 1 ∶ 1,且深浅颜色顺序为深—浅—深—浅—深,则记录该线段。扫描完后,把行相邻的线段分为1 组,去除与所有线段都不相邻的行线段( 可能是随机的干扰线段) 。同样处理列线段,把行线段组和列线段组中相互交叉的组分类,求出交叉的行、列线段组的中心点,即为位置探测图形的中心。 2.2.2 预处理 基本原理:QR 码作为手机二维码,其应用模式如下图所示。手机等智能设备通过摄像头采集带有条码符号的图像,对图像进行灰度化、二值化、旋转校正等预处理,进行条码检 测。如果检测到非QR 码,则重新采集; 如果是QR 码,则进行图像信息的取样。用Reed - Solomon 码的译码算法对取到的数据进行纠错译码,统计出现的错误数量。如果错误数量超出纠错容量,则纠错译码失败,重新采集图像; 如果可以正确进行纠错译码,则把纠错后的信息进行各种数据模式下的译码,恢复出编码信息,继而根据应用模式进行信息输出、发送短信或网址跳转等后续处理。
三、QR码的特点
说到QR码的特点:
一)是高速读取(QR就是取自“Quick Response”的首字母),对读取速度的体验源自于我手机上的一个软件,象上面贴出的码图,通过摄像头从拍摄到解码到显示内容也就三秒左右,对摄像的角度也没有什么要求;
二)是高容量、高密度;理论上内容经过压缩处理后可以存7089个数字,4296 个字母和数字混合字符,2953个8位字节数据,1817个汉字;
三)是支持纠错处理;纠错处理相对复杂,目前我还没有深入了解,按照QR码的标准文档说明,QR码的纠错分为4个级别,分别是:
level L : 最大 7% 的错误能够被纠正;
level M : 最大 15% 的错误能够被纠正;
level Q : 最大 25% 的错误能够被纠正;
level H : 最大 30% 的错误能够被纠正;
四)是结构化;看似无规则的图形,其实对区域有严格的定义,下图就是一个模式2、版本1的QR图结构(关于QR码的"模式"、"版本"将在后面进行介绍):
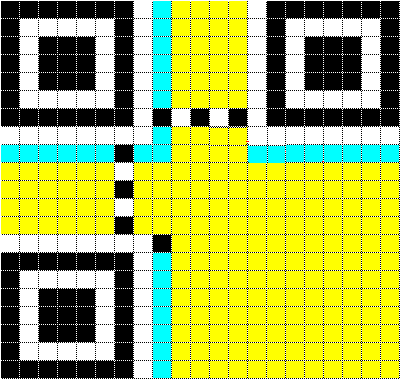
在上图21*21的矩阵中,黑白的区域在QR码规范中被指定为固定的位置,称为寻像图形(finder pattern) 和 定位图形(timing pattern)。寻像图形和定位图形用来帮助解码程序确定图形中具体符号的坐标。
黄色的区域用来保存被编码的数据内容以及纠错信息码。
蓝色的区域,用来标识纠错的级别(也就是Level L到Level H)和所谓的"Mask pattern",这个区域被称为“格式化信息”(format information)。
五)是扩展能力。QR码的Structure Append特点,使一个QR码可以分解成多个QR码,反之,也可以将多个QR码的数据组合到一个QR码中来:

四、QR码的模式和版本
前面提到过QR码的模式(Model)和版本(Version)。QR码分为Model1和Model2两种模式,Model1是对QR的初始定义,Model2是对Model1的扩展,目前使用较为普遍的是Model2,本文的所有说明也仅用于Model2。
QR图的大小(size)被定义为版本(Version),版本号从1到40。版本1就是一个21*21的矩阵,每增加一个版本号,矩阵的大小就增 加4个模块(Module),因此,版本40就是一个177*177的矩阵。(版本越高,意味着存储的内容越多,纠错能力也越强)。
五、QR码支持的编码内容
QR码支持编码的内容包括纯数字、数字和字符混合编码、8位字节码和包含汉字在内的多字节字符。其中:
数字:每三个为一组压缩成10bit。
字母数字混合:每两个为一组,压缩成11bit。
8bit字节数据:无压缩直接保存。
多字节字符:每一个字符被压缩成13bit。
QR码编码原理(编码)
编码就是把常见的数字、字符等转换成QR码的方法。说具体的编码之前,先说一下QR码的最大容量问题。
一、最大容量
QR码的最大容量取决于选择的版本、纠错级别和编码模式(Mode:数字、字符、多字节字符等)。以版本1、纠错级别为Level Q的QR码为例,可以存储27个纯数字,或17个字母数字混合字符或11个8bit字节数据。如果要存储同样多的内容同时提高纠错级别,则需要采用更高的 版本。版本1~9 数据容量、纠错码容量对照如下表:
| 版本 | (error correcting level) | (count of data code words) | count of EC code words | (numeric) | (alphanumeric) | 8bit |
| 1 | L | 19 | 7 | 41 | 25 | 17 |
| M | 16 | 10 | 34 | 20 | 14 | |
| Q | 13 | 13 | 27 | 16 | 11 | |
| H | 9 | 17 | 17 | 10 | 7 | |
| 2 | L | 34 | 10 | 77 | 47 | 32 |
| M | 28 | 16 | 63 | 38 | 26 | |
| Q | 22 | 22 | 48 | 29 | 20 | |
| H | 16 | 28 | 34 | 20 | 14 | |
| 3 | L | 55 | 15 | 127 | 77 | 53 |
| M | 44 | 26 | 101 | 61 | 42 | |
| Q | 34 | 36 | 77 | 47 | 32 | |
| H | 26 | 44 | 58 | 35 | 24 | |
| 4 | L | 80 | 20 | 187 | 114 | 78 |
| M | 64 | 36 | 149 | 90 | 62 | |
| Q | 48 | 52 | 111 | 67 | 46 | |
| H | 36 | 64 | 82 | 50 | 34 | |
| 5 | L | 108 | 26 | 255 | 154 | 106 |
| M | 86 | 48 | 202 | 122 | 84 | |
| Q | 62 | 72 | 144 | 87 | 60 | |
| H | 46 | 88 | 106 | 64 | 44 | |
| 6 | L | 136 | 36 | 322 | 195 | 134 |
| M | 108 | 64 | 255 | 154 | 106 | |
| Q | 76 | 96 | 175 | 108 | 74 | |
| H | 60 | 112 | 139 | 84 | 58 | |
| 7 | L | 156 | 40 | 370 | 224 | 154 |
| M | 124 | 72 | 293 | 178 | 122 | |
| Q | 88 | 108 | 207 | 125 | 86 | |
| H | 66 | 130 | 154 | 93 | 64 | |
| 8 | L | 194 | 48 | 461 | 279 | 192 |
| M | 154 | 88 | 365 | 221 | 152 | |
| Q | 110 | 132 | 259 | 157 | 108 | |
| H | 86 | 156 | 202 | 122 | 84 | |
| 9 | L | 232 | 60 | 552 | 335 | 230 |
| M | 182 | 110 | 432 | 262 | 180 | |
| Q | 132 | 160 | 312 | 189 | 130 | |
| H | 100 | 192 | 235 | 143 | 98 |
如果要了解更详细的QR码容量信息,可以到电装的网站去看看:
http://www.denso-wave.com/qrcode/vertable1-e.html。
下面,就举例说明将“ABCDE123”转换成为版本1、Level H的QR码转换方法。
六、模式标识符(Mode Indicator)
QR码的模式(Mode)就是前文提到的数字、字符、8bit 字节码、多字节码等。对于不同的模式,都有对应的模式标识符(Mode Indicator)来帮助解码程序进行匹配,模式标识符是4bit的二进制数:
1、数字模式(numeric mode ): 0001
2、混合字符模式(alphanumeric mode) : 0010
3、8bit byte mode: 0100
4、日本汉字(KANJI mode) : 1000
5、中国汉字(GB2312):1101
由于示例文本串是混合字符,因此将选择alphanumeric mode,其标识码为:0010
三、文本串计数标识符(Character count indicator)
文本串计数标识符用来存储源内容字符串的长度,在版本1-9的QR码中,文本串长度标识符自身的长度被定义为:
数字 : 10bit
混合字符 : 9bit
8bit 字节码 : 8bit
多字节码 : 8bit
在本例中,源文本串的长度为8个字符,混合字符的长度为9bit,因此将字符个数8编码为9位二进制表示:000001000
加上混合字符模式标识码,总的编码为0010 000001000
七、数据内容编码
1、数字模式下的编码
在数字模式下,数据被限制为3个数字一段,分成若干段。如:"123456" 将分成"123" 和 "456",分别被编码成10bit的二进制数。“123”的10bit二进制表示法为:0001111011,实际上就是二进制的123。
当数据的长度不足3个数字时,如果只有1个数字则用4bit,如果有2个数字就用7个bit来表示。
如:"9876"被分成"987"和"6"两段,因此被表示为"1111011011 0110"。
2、混合字符模式下的编码
混合字符模式编码,其字符对照表如下:
0 | 0 | A | 10 | K | 20 | U | 30 | + | 40 | ||||
1 | 1 | B | 11 | L | 21 | V | 31 | - | 41 | ||||
2 | 2 | C | 12 | M | 22 | W | 32 | . | 42 | ||||
3 | 3 | D | 13 | N | 23 | X | 33 | / | 43 | ||||
4 | 4 | E | 14 | O | 24 | Y | 34 | : | 44 | ||||
5 | 5 | F | 15 | P | 25 | Z | 35 | ||||||
6 | 6 | G | 16 | Q | 26 | [sp] | 36 | ||||||
7 | 7 | H | 17 | R | 27 | $ | 37 | ||||||
8 | 8 | I | 18 | S | 28 | % | 38 | ||||||
9 | 9 | J | 19 | T | 29 | * | 3 | ||||||
编码方式为:
源码被分成两个字符一段,如下所示,每段的第一个字符乘上45,再用第二个数字相加。因此每段变成了11bit的2进制码,如果字符个数只有1个,则用6bit表示。
示例:
"AB" | "CD" | "E1" | "23" | ||
45*10+11 | 45*12+13 | 45*14+1 | 45*2+3 | ||
461 | 553 | 631 | 93 | ||
0010 | 000001000 | 00111001101 | 01000101001 | 01001110111 | 00001011101 |
3、8bit字节数据不经编码转换直接保存。
五、编码终止符(Terminator)
如果编码后的字符长度不足当前版本和纠错级别所存储的容量,则在后续补"0000",如果容量已满则无需添加终止符。此时得到的编码串为:
0010 000001000 00111001101 01000101001 01001110111 00001011101 0000
六、编成8bit码字(Code words)
将以上的编码再按8bit一组,形成码字(code words):
00100000 01000001 11001101 01000101 00101001 11011100 00101110 10000
如果尾部数据不足8bit,则在尾部充0:
00100000 01000001 11001101 01000101 00101001 11011100 00101110 10000000
如果编码后的数据不足版本及纠错级别的最大容量,则在尾部补充 "11101100" 和"00010001",直到全部填满。最后,版本1、Level H下的"ABCDE123" 的QR码是:
00100000 01000001 11001101 01000101 00101001 11011100 00101110 10000000 11101100
十进制表示法为:
32 65 205 69 41 220 46 128 236
QR码编码原理(日本汉字和中文编码)
一、日本汉字(KANJI)是两个字节表示的字符码,编码的方式是将其转换为13字节的二进制码制。
转换步骤为:
1、对于JIS值为8140(hex) 到9FFC(hex)之间字符:
a)将待转换的JIS值减去8140(hex);
b)将高位字节乘以C0(hex);
c)将b)步骤生成的数据加上低位字节;
d)将结果转换为13位二进制串。
2、对于JIS值为E040(hex)到EBBF(hex)之间的字符:
a)将待转换的JIS值减去C140(hex);
b)将高位字节乘以C0(hex);
c)将b)步骤生成的数据加上低位字节;
d)将结果转换为13位二进制串。
二、中文汉字的与日文汉字转换步骤相似:
1、对于第一字节为0xA1~0xAA之间,第二字节在0xA1~0xFE之间字符:
a)第一字节减去0xA1;
b)上一步结果乘以0x60;
c)第二字节减去0xA1;
d)将b)步骤的结果加上c步骤的结果;
e)将结果转换为13位二进制串。
1、对于第一字节为0xB0~0xFA之间,第二字节在0xA1~0xFE之间字符:
a)第一字节减去0xA6;
b)上一步结果乘以0x60;
c)第二字节减去0xA1;
d)将b)步骤的结果加上c步骤的结果;
e)将结果转换为13位二进制串。
掩模
众所周知,为了增加QR码阅读的可靠性,最好均衡地安排深色与浅色模块。应尽可能避免类似“位置探测图形”的位图1011101出现在符号的其他区域。
为了满足上述条件,应按以下步骤进行掩模:
1)掩模不用于功能图形;
2)用多个矩阵图形连续地对已知的编码区域的模块图形(格式信息和版本信息除外)进行XOR操作。XOR操作将模块图形依次放在每个掩模图形上,并将对应于掩模图形的深色模块的模块取反(浅色变成深色,或相反);
3)对每个结果图形的不合要求的部分记分,以评估这些结果;
4)选择得分最低的图形。
下表给出了掩模图形的参考(放置于格式信息中的二进制参考)和掩模图形生成的条件。掩模图形是通过将编码区域(不包括为格式信息和版本信息保留的部 分)内那些条件为真的模块定义为深色而产生的。所示的条件中,i代表模块的行位置,j代表模块的列位置,(i,j)=(0,0)代表符号中左上角的位置。
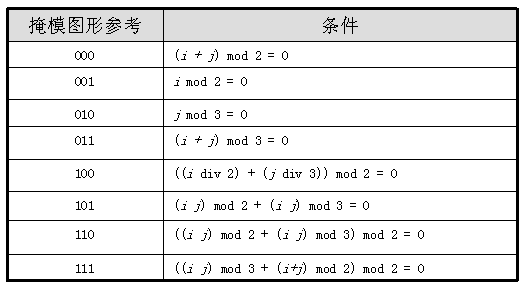
图1 掩模图形参考及条件

图2 QRCode的八种掩模方案

图3 掩模结果(版本1符号的所有的掩模图形,用掩模图形参考000到111的掩模结果)。
下图为掩模过程:
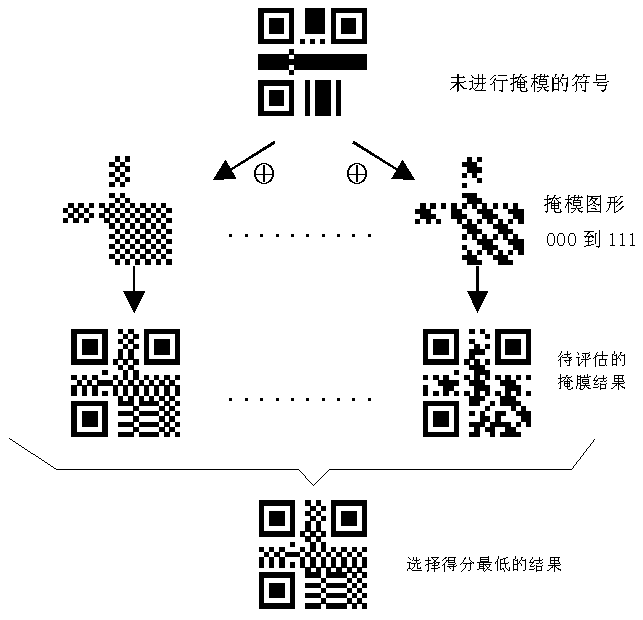
图4 符号的掩模过程
罚点记分:
在依次用每一个掩模图形进行掩模操作之后,要通过对每一次如下情况的出现进行罚点记分,以便对每一个结果进行评估,分数越高,其结果越不可用。在下 表中,N1到N4为对不好的特征所罚分数的权重(N1=3,N2=3,N3=40,N4=10),i为紧邻的颜色相同模块数大于5的次数,k为符号深色模 块所占比率离50%的差距,步长为5%。虽然掩模操作仅对编码区域进行,不包括格式信息,但评价是对整个符号进行的。
最终,应选择掩模结果中罚分最低的掩模图形用于符号掩模。
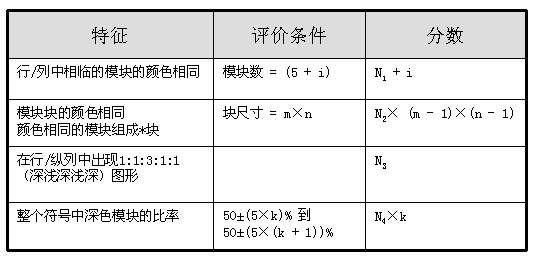
图5 罚点记分表
相关文章:
