一.Opends简介
OpenDS 是一个基于 CDDL ( Common Development and Distribution License )协议,开源 , 免费,使用 LDAP 与 DSML 标准的综合的下一代 Directory Service 。 OpenDS 是用纯 Java 编写的处理大数据量,高性能,高可扩展性,很容易地部署,管理和监控。 Directory Service 不仅包括 DirectoryServer ,还有其它与 directory 相关的基本 service 如: directoryproxy 、 virtualdirectory 、 namespacedistribution 和数据同步。 DirectoryServer 是一个可以通过网络访问,信息分级存储的数据库。客户端可以使用标准的网络协议(当前支持 LDAP 和 DSML )来与它通信,以达到通过各种各样的方式获取和更新信息。
下载地址:https://opends.java.net/public/downloads_index.html
文档:https://java.net/projects/opends/pages/2_2_Main
相关单词:
DN : Directory Namespace 目录空间 Domain 域
DC:Domain Component 域组件
OU:Organizational Unit 组织单元
CN:Common Name(O:Organization 组织 ) Certificate name 证书名
C : Country
二.opends安装
1 ,从官网下载 opends2.2.0 ,然后解压缩到要安装的目录。
安装过程参考视频如下:链接:http://pan.baidu.com/s/1bs8ilC 密码: pb42
安装手册:https://java.net/projects/opends/pages/2_2_InstallationGuide
一定采用 jdk1.6 版本安装, 否则无法启动, 原因如下:
Exception in thread "main" java.lang.ExceptionInInitializerError: A security class cannot be found in this JVM because of the following reason: sun.security.x509.X500Signer
at org.opends.server.util.Platform$PlatformIMPL.<clinit>(Platform.java:157)
at org.opends.server.util.Platform.<clinit>(Platform.java:96)
at org.opends.server.util.CertificateManager.generateSelfSignedCertificate(CertificateManager.java:281)
at org.opends.server.admin.AdministrationConnector.createSelfSignedCertifIfNeeded(AdministrationConnector.java:684)
at org.opends.server.admin.AdministrationConnector.initializeAdministrationConnector(AdministrationConnector.java:179)
at org.opends.server.core.ConnectionHandlerConfigManager.initializeAdministrationConnectorConfig(ConnectionHandlerConfigManager.java:350)
at org.opends.server.core.DirectoryServer.initializeAdministrationConnector(DirectoryServer.java:2842)
at org.opends.server.core.DirectoryServer.startServer(DirectoryServer.java:1390)
at org.opends.server.core.DirectoryServer.main(DirectoryServer.java:9501)
https://java.net/jira/browse/OPENDS-4483
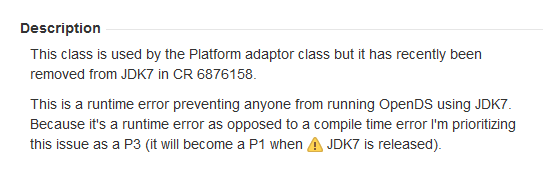
This class is used by the Platform adaptor class but it has recently been
removed from JDK7 in CR 6876158.
This is a runtime error preventing anyone from running OpenDS using JDK7.
Because it's a runtime error as opposed to a compile time error I'm prioritizing
this issue as a P3 (it will become a P1 when ![]() JDK7 is released).
JDK7 is released).
似乎要在 opends2.4 版本解决, 不过目前没找到 2.4 版本的安装程序。
2 ,执行 setup.bat 进行安装
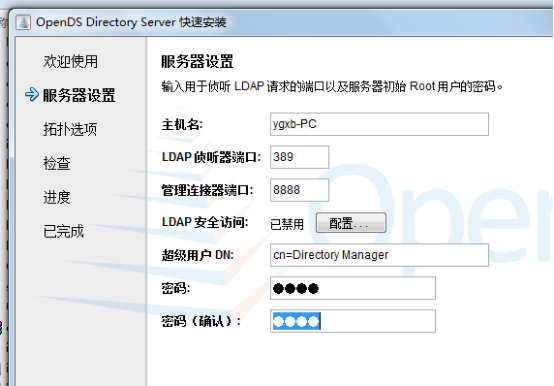
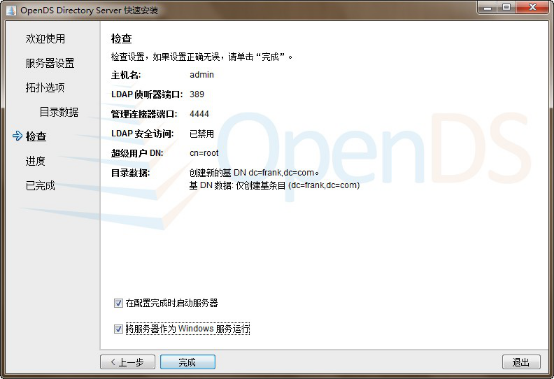
3 ,参数:
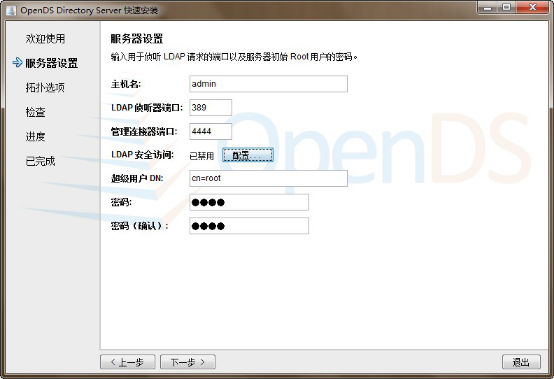
默认 LDAP 端口 389 ,
管理后台端口 4444 ,
Root User DN : cn=Directory Manager 用户根域名(顶层节点)
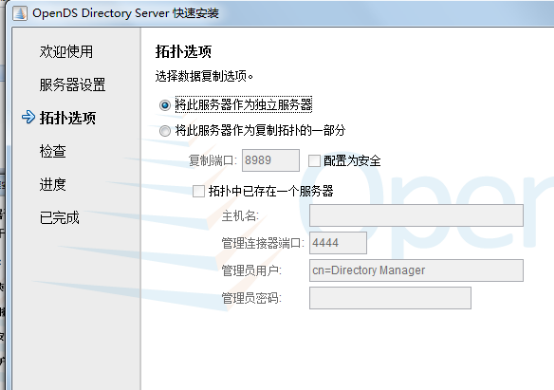
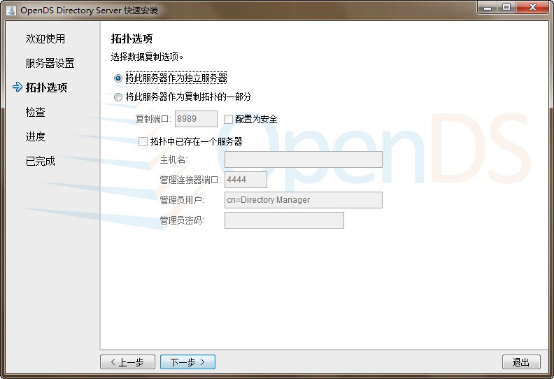
This will be a standalone server
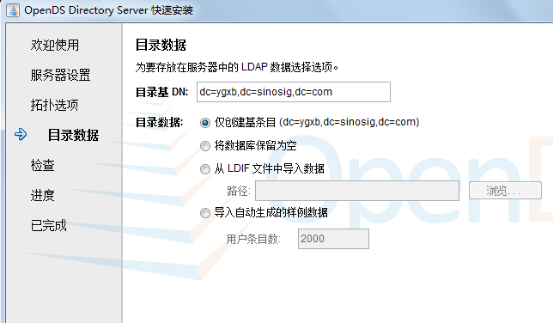
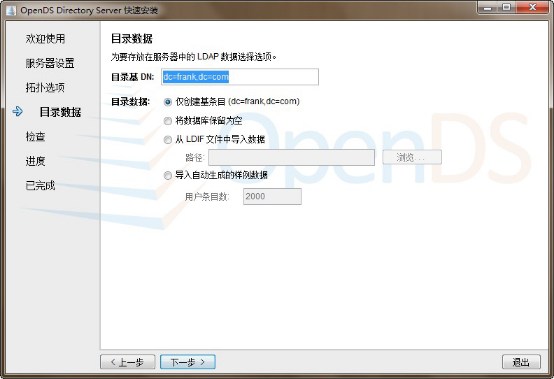
Directory Base DN:dc=company,dc=com 目录基础域名
Only Create Base Entry
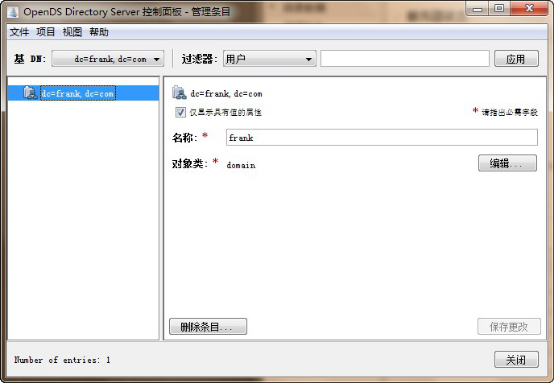
三.opends启动和添加用户
启动命令行 <OpenDS install directory>\bat\control-panel.bat.
选择“ Directory Data ” -> ” Manage Entries ”
选择安装时输入的 Directory Base DN :“ dc=company,dc=com ”
选择 “ Entries ” -> ” New Organizational Unit …” :
输入组织的相关信息
在生成的组织下面,选择“ Entries ” -> ” New User …”来创建用户
输入相关的用户信息,并把“ Naming Attribute ” 选择为 uid
完成
uid : User ID
LDAP 是轻量目录访问协议,英文全称是 Lightweight Directory Access Protocol ,一般都简称为 LDAP 。它是基于 X.500 标准的,但是简单多了并且可以根据需要定制。与 X.500 不同, LDAP 支持 TCP/IP ,这对访问 Internet 是必须的。 LDAP 的核心规范在 RFC 中都有定义,所有与 LDAP 相关的 RFC 都可以在 LDAPman RFC 网页中找到。
目录是一个为查询、浏览和搜索而优化的专业分布式数据库,它成树状结构组织数据,就好象 Linux/Unix 系统中的文件目录一样。目录数据库和关系数据库不同,它有优异的读性能,但写性能差,并且没有事务处理、回滚等复杂功能,数据修改使用简单的锁定机制实现 All-or-Nothing, 不适于存储修改频繁的数据。所以目录天生是用来查询的,就好象它的名字一样。现在国际上的目录服务标准有两个,一个是较早的 X.500 标准,一个是较新的 LDAP 标准。
LDAP 诞生的目标是快速响应和大容量查询并且提供多目录服务器的信息复制功能,它为读密集型的操作进行专门的优化。因此,当从 LDAP 服务器中读取数据的时候会比从专门为 OLTP 优化的关系型数据库中读取数据快一个数量级。
An LDAP 目录类似于文件系统目录 . 下列目录 :
DC=redmond,DC=wa,DC=microsoft,DC=com
如果我们类比文件系统的话,可被看作如下文件路径 :
Com\Microsoft\Wa\Redmond
例如: CN=test,OU=developer,DC=domainname,DC=com
在上面的代码中 cn=test 代表一个用户名, ou=developer 代表一个 active directory 中的组织单位。这句话的含义是 test 这个对象处在 domainname.com 域的 developer 组织单元中。
官网: http://opends.java.net/
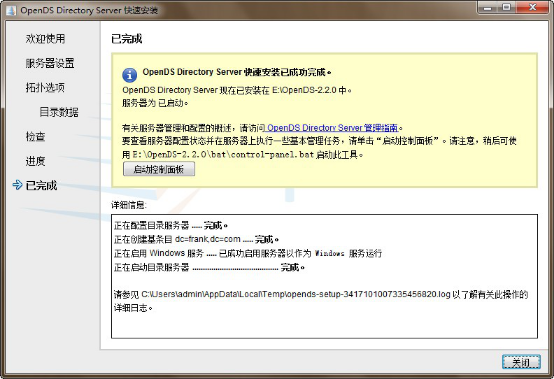
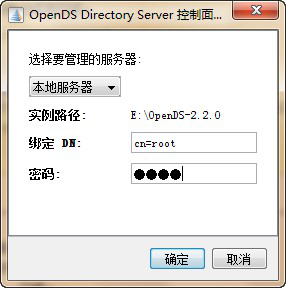
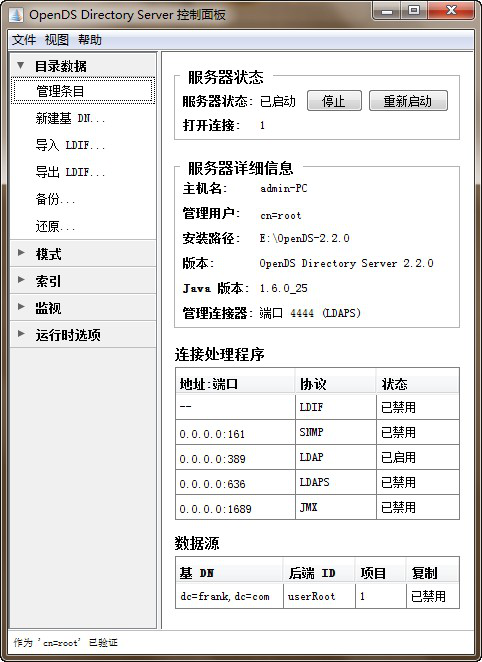
安装失败 时
删除 windows 下的服务 地址:
https://java.net/projects/opends/pages/2_2_RemoveWindowsService
四.应用实例
下面是 opends 官方给出的应用实例,供参考
https://java.net/projects/opends/pages/2_2_DirectoryDeployments
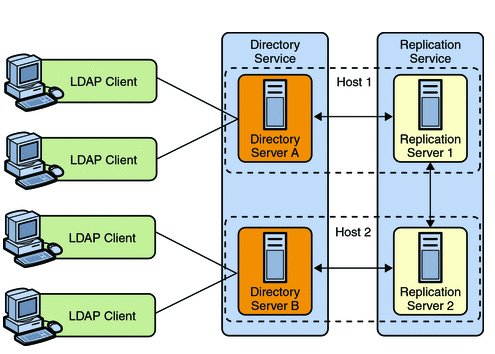
Small Replicated Topology
By replicating directory data across servers, you can reduce the access load on a single machine, improving server response time and providing horizontal read scalability. In addition, replication can be used to ensure availability of data in the event of machine failure.
Note that you cannot use replication to scale write operations because a write operation to one directory server results in a write operation to every other server in the topology. The only way to scale write operations horizontally is to split the directory data among multiple databases and place those databases on different servers.
The centralized replication model in OpenDS separates user data from replication metadata. In this model, the server that stores the user data is called the directory server. The server that stores the replication metadata is called the replication server. This approach simplifies the management of replication topologies and can improve performance.
For small deployments, you can set up replication by putting the replication servers and directory servers on the same system. You can further simplify administration by running the replication server and the directory server on each system in a single process.
The following diagram shows how replication is used to ensure availability and to provide read scalability in a small topology.
![]()
The Role of Directory Servers in a Topology
Directory servers are responsible for the following tasks:
· Persistence of data and serving client requests
· Forwarding changes to specific replication servers
When a change is made on a directory server, that server forwards the change to a selected replication server. The replication server then replays the change to other replication servers in the topology, which in turn replay the change to all other directory servers in the topology.
Each directory server contains the following items:
· A list of the suffix DNs to be synchronized
· For each suffix DN, a list of replication servers to connect to
Applications should typically perform reads and writes on the same directory server instance. This prevents those applications from experiencing consistency problems due to loose consistency.
The Role of Replication Servers in a Topology
Replication servers are responsible for the following tasks:
· Managing connections from directory servers
· Connecting to other replication servers
· Listening for connections from other replication servers
· Receiving changes from directory servers
· Forwarding changes to directory servers and to other replication servers
· Saving changes to stable storage, which includes trimming older operations
Each replication server contains a list of all the other replication servers in the replication topology. Replication servers are also responsible for providing other servers with information about the replication topology. Even the smallest deployment must include two replication server instances, to ensure availability in case one of the replication server instances fails. There is usually no need for additional replication server instances unless the directory service must be able to survive more than one failure at a time, or unless the number of directory server instances must be very large.
Although replication servers do not store directory data, they are always LDAP servers or JMX servers. Like directory servers, replication servers can be configured, monitored, backed up and restored.
Multiple Data Center Topology
Replication enables geographic distribution of the directory service by providing identical copies of directory data on multiple servers across more than one data center. The basic principles of a replication deployment outlined in the small topology also apply to multiple data center deployments.
The OpenDS directory server uses a custom replication protocol that is efficient over a wide area network (WAN). In the following scenario, an enterprise has two major data centers, one in London and the other in New York, separated by a WAN.
This deployment includes two replication server instances for availability in each data center, in case one of the replication server instances fails. The directory servers connect first to local replication servers. Directory servers only access replication servers in another data center if all local replication servers have failed. Client applications always connect to local directory server instances, and perform reads and writes on the same directory server instance.
The OpenDS directory server supports an unlimited number of read/write directory servers in a replication topology. The number of directory servers can be scaled according to the read requirements of the organization. Note that increasing the number of directory servers does not scale the number of writes that can be processed because ultimately all servers in the toplogy must process all the writes. Unless it is acceptable to have a topology that does not converge, the write throughput of the topology is limited to the write throughput of the slowest machine.
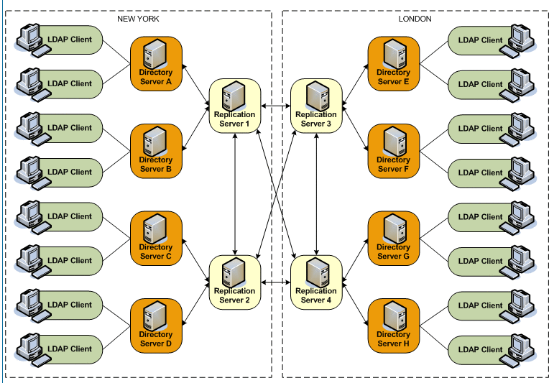
Multiple Data Centers and Replication Groups
Replication groups enable you to organize a replicated topology according to specific criteria, such as data center location. A replication group is identified by a unique ID that is applied to the replication servers and the directory servers in that group. Group IDs determine how a directory server domain connects to an available replication server. From the list of configured replication servers, a directory server first tries to connect to a replication server that has the same group ID as that of the directory server.
This sample deployment shows the use of replication groups across multiple data centers. The deployment assumes two data centers, connected by a wide area network (WAN), with the following configuration:
· Each replication server and directory server within a single data center has the same group ID.
· There is a unique group ID for the entire data center (one group ID per data center).
The following figure shows a disaster recovery deployment that includes two data centers with different group IDs.
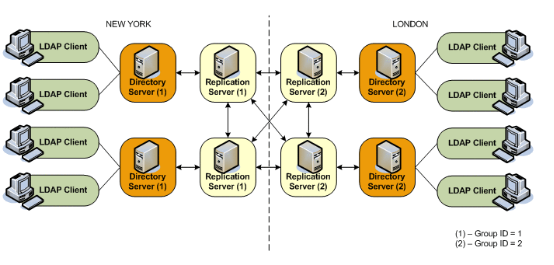
In this deployment, each directory server will attempt to connect to a replication server in its own data center, avoiding the latency associated with connection over a WAN. If all the replication servers in a data center fail, the directory server will connect to a remote replication server. This ensures that the replication service is maintained, albeit in a degraded manner (if the connection between data centers is slow). When one or more local replication servers is back online, the directory servers will automatically reconnect to a local replication server.
Multiple Data Centers and the Window Mechanism
The OpenDS directory server provides a window mechanism which specifies that a certain number of update requests are sent without one server having to wait for an acknowledgement from the recipient server before continuing.
The window size represents the maximum number of update messages that can be sent without immediate acknowledgement from the recipient server. If the topology spans multiple data centers connected by a network with large latency, it might be worth increasing the window size beyond its default value of 100. To assess whether the window size is the limiting factor in replication thoughput, monitor the current-send-window and current-rcv-window attributes below cn=monitor.
If a server publishes a current-send-window to another server that is consistently zero or close to zero and the corresponding server publishes a current-rcv-window that is higher, it means that all the data are currently in the network. In this case, increasing the window size on the recipient server should increase replication speed and reduce replication delay. These improvements will result in the consumption of more resources on the recipient server.
http://www.myexception.cn/software/472439.html
