原创文档,转载请将原文url地址标明
本文将研究当你输入一个网址的时候,后台到底发生了一件件什么样的事。当用户在一个浏览器中输入一个网站地址,然后点击回车,我们就会看到相关网站,操作可谓简单,但是若是无法打开一个网站时,如何能确定问题在哪里,这就需要我们了解在用户下达命令后,系统都发生了什么,这样为我们排除指明了方向。
1. 在浏览器里输入网址
当用户输入了地址后,然后敲击回车键,一个网站的页面也就显示出来了。
里面其实主要发生了几个过程。
(1)浏览器查找域名及ip地址的对应关系
(2)浏览器根据ip地址。连接ip地址对应的服务器进行数据获取工作
之后就是根据数据进行相关数据的处理工作
(3)根据获取到的数据进行解析,然后获取里面包括的其他资源
(4)下载相关资源
(5)解释相关资源
(6)根据这些资源等,显示页面
下面将重点介绍相关过程。
2. 浏览器查找域名的IP地址
浏览器在接受到用户的请求后,首先要做的事情是找到用户输入的域名对应的ip地址是多少?然后去连接这个ip地址相关的服务程序,然后取得相关页面,最后进行显示。
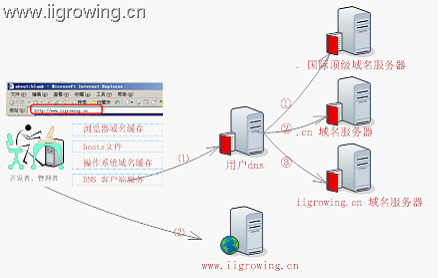
取得ip地址,首先浏览器会先检查自己的缓冲中是否存在域名及ip地址的对应关系,若是没有进行下面
检查hosts文件中是否有域名与ip地址的对应关系。我们经常在网站的开发中,临时指定hosts文件中的配置将某个域名指向开发的机器来调试应用程序的。利用就是这个原理。
然后检查操作系统的dns缓存,若是有也可以返回了,若是没有进行下面的
通过操作系统的dns客户端服务程序,访问用户配置的dns服务器进行域名解析。
用户的域名服务器会在自己的内存等中检查域名,若是域名存在则放回,若是不存在则根据设置,去检查上级域名服务器。
检查域名服务器主要过程如下:
①检查国际顶级域名服务器(.), 然后这个dns服务器会通知这个dns服务器区到 .cn域名的dns服务器检查域名,
②然后域名服务器会联系这个.cn域名服务器去解析域名,最后.cn域名服务器会告诉dns服务器区访问iigrowing.cn这个dns服务器区解析这个域名。
③最后用户dns服务器获取了相关的域名的ip的地址解析。
DNS对于像wikipedia.org这样的大型网站,整个域名实际对应是比较复杂的。有几种方法可以被采用,这里仅仅需要了解就好。
1. 循环 DNS 是DNS查找时返回多个IP时的解决方案。
2. 负载平衡器 是以一个特定IP地址进行侦听并将网络请求转发到集群服务器上的硬件设备。 一些大型的站点一般都会使用这种昂贵的高性能负载平衡器。
3. 地理 DNS 根据用户所处的地理位置,通过把域名映射到多个不同的IP地址提高可扩展性。这样不同 的服务器不能够更新同步状态,但映射静态内容的话非常好。
4. Anycast是一个IP地址映射多个物理主机的路由技术。 美中不足,Anycast与TCP协议适应的不是很好,所以很少应用在那些方案中。
大多数DNS服务器使用Anycast来获得高效低延迟的DNS查找。
3. 浏览器给web服务器发送一个HTTP请求

因为现在通常的网站都是动态页面,打开后在浏览器缓存中很快甚至马上就会过期,毫无疑问他们不能从中读取。
所以,浏览器将把一下请求发送到www.iigrowing.cn域名对应ip的所在服务器,服务器经过各种各样的计算后,将结果返回。
用户在请求页面过程中,主要分为,发送请求(request)信息给服务器,然后服务器接收到请求后,进行解析等各项工作。
最后服务器会返回相应(response)给客户端,客户端进行相应的处理工作。
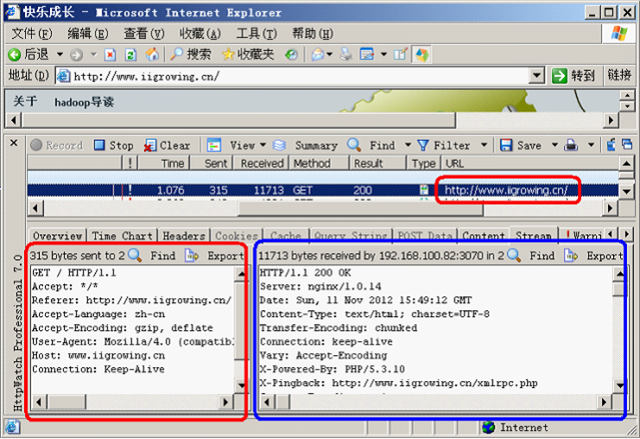
如上图是httpwatch记录是一个http的通信过程。
其中较小的红色区域,是记录的浏览器访问网络的地址
Request:较大的红色是用户的请求数据区域,上面是用户请求的头部信息,下面是body信息
Response:蓝色的区域是相应的数据流,上面是header信息(头部),下面是body信息
下面是浏览器发送的数据的部分片段
GET / HTTP/1.1 // http的方法
Accept: */* // 客户端可以接受的类型
Referer: http://www.iigrowing.cn/ // 发起请求页面的地址
Accept-Language: zh-cn // 客户端的语言环境
Accept-Encoding: gzip, deflate //客户端接受的编码类型
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; BTRS124342; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729) // 浏览器类型
Host: www.iigrowing.cn // 访问的主机
Connection: Keep-Alive // http的连接属性
请求中也包含浏览器存储的该域名的cookies。可能你已经知道,在不同页面请求当中,cookies是与跟 踪一个网站状态相匹配的键值。这样cookies会存储登录用户名,服务器分配的密码和一些用户设置等。Cookies会以文本文档形式存储在客户机里, 每次请求时发送给服务器。
用来看原始HTTP请求及其相应的工具很多。作者比较喜欢使用fiddler(使用比较麻烦,好像需要配置代理服务器等,但是功能非常强大,比如模拟http的header等,目前阶段我们暂不需要这个工具出马),当然也有像FireBug这样其他的工具。这些软件在网站优化时会帮 上很大忙,httpwatch是一个较好的工具
除了获取请求,还有一种是发送请求,它常在提交表单用到。发送请求通过URL传递其参数(e.g.: http://robozzle.com/puzzle.aspx?id=85)。 发送请求在请求正文头之后发送其参数。
像“http://www.iigrowing.cn/”中的斜杠是至关重要的。这种情况下,浏览器能安全的添加斜杠。而像“http: //example.com/folderOrFile”这样的地址,因为浏览器不清楚folderOrFile到底是文件夹还是文件,所以不能自动添加 斜杠。这时,浏览器就不加斜杠直接访问地址,服务器会响应一个重定向,结果造成一次不必要的握手。
4. 永久重定向响应

当服务器给浏览器响应一个301永久重定向响应,这样浏览器就会访问被从指向的域名,例如访问:http://facebook.com/时,从定向到(301)到“http://www.facebook.com/” 而非“http://facebook.com/”。
为什么服务器一定要重定向而不是直接发会用户想看的网页内容呢?这个问题有好多有意思的答案。
其中一个原因跟搜索引擎排名有 关。你看,如果一个页面有两个地址,就像http://www.igoro.com/ 和http://igoro.com/,搜索引擎会认为它们是两个网站,结果造成每一个的搜索链接都减少从而降低排名。而搜索引擎知道301 永久重定向是 什么意思,这样就会把访问带www的和不带www的地址归到同一个网站排名下。
还有一个是用不同的地址会造成缓存友好性变差。当一个页面有好几个名字时,它可能会在缓存里出现好几次。
5. 服务器“处理”请求
服务器接收到获取请求,然后处理并返回一个响应。
这表面上看起来是一个顺向的任务,但其实这中间发生了很多有意思的东西- 就像作者博客这样简单的网站!
1. Web 服务器软件
web服务器软件(像nginx和阿帕奇)接收到HTTP请求,然后确定执行什么请求处理来处理它。请求处理就是一个能够读懂请求 并且能生成HTML来进行响应的程序(像ASP.NET,PHP,RUBY...)。
举 个最简单的例子,需求处理可以以映射网站地址结构的文件层次存储。像http://example.com/folder1/page1.aspx这个地 址会映射/httpdocs/folder1/page1.aspx这个文件。web服务器软件可以设置成为地址人工的对应请求处理,这样 page1.aspx的发布地址就可以是http://example.com/folder1/page1。
2. 请求处理
请求处理阅读请求及它的参数和cookies。它会读取也可能更新一些数据,并讲数据存储在服务器上。然后,需求处理会生成一 个HTML响应。
所有动态网站都面临一个有意思的难点 -如何存储数据。小网站一半都会有一个SQL数据库来存储数据,存储大量数据和/或访问量大的网站不得不找一些办法把数据库分配到多台机器上。解决方案 有:sharding (基于主键值讲数据表分散到多个数据库中),复制,利用弱语义一致性的简化数据库。
6. 服务器发回一个HTML响应
以上步骤都完成后,服务器将发送返回数据给浏览器了,如下图。

返回给浏览器的数据包括:返回码,状态信息,头部数据,body数据等等,下面是头部数据的截取。
HTTP/1.1 200 OK // 表明是http1.1协议, 状态码200, 状态信息OK
Server: nginx/1.0.14 // server的信息,表明是nginx的一个版本
Date: Sun, 11 Nov 2012 15:49:12 GMT // 页面的服务器生成时间
Content-Type: text/html; charset=UTF-8 // 内容类型,及编码格式
Transfer-Encoding: chunked
Connection: keep-alive // 连接属性
Vary: Accept-Encoding
X-Powered-By: PHP/5.3.10
X-Pingback: http://www.iigrowing.cn/xmlrpc.php
Content-Encoding: gzip
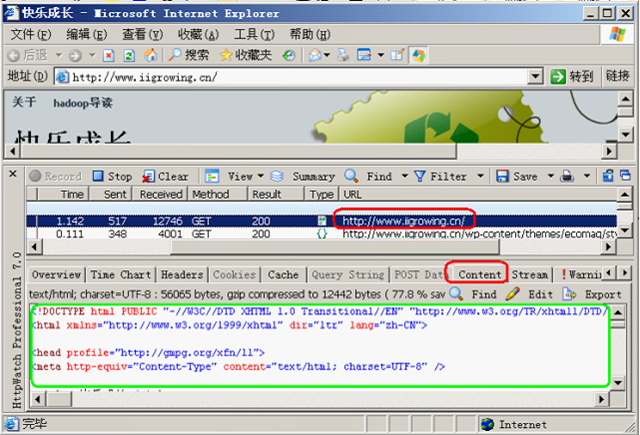
上图是服务器返回页面数据的内容,用户可以通过content标签卡进行查看
返回的部分内容如下:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" dir="ltr" lang="zh-CN">
<head profile="http://gmpg.org/xfn/11">
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<title> 快乐成长</title>
<link rel="stylesheet" href="http://www.iigrowing.cn/wp-content/themes/ecomag/style.css" type="text/css" media="screen" />
<link rel="alternate" type="application/rss+xml" title="快乐成长 RSS Feed" href="http://www.iigrowing.cn/feed" />
<link rel="alternate" type="application/atom+xml" title="快乐成长 Atom Feed" href="http://www.iigrowing.cn/feed/atom" />
<link rel="pingback" href="http://www.iigrowing.cn/xmlrpc.php" />
<link rel="shortcut icon" href="http://www.iigrowing.cn/wp-content/themes/ecomag/images/favicon.ico" />
<link rel="stylesheet" href="http://www.iigrowing.cn/wp-content/themes/ecomag/style.css" type="text/css" />
<link rel="EditURI" type="application/rsd+xml" title="RSD" href="http://www.iigrowing.cn/xmlrpc.php?rsd" />
<link rel="wlwmanifest" type="application/wlwmanifest+xml" href="http://www.iigrowing.cn/wp-includes/wlwmanifest.xml" />
<link rel='index' title='快乐成长' href='http://www.iigrowing.cn' />
<meta name="generator" content="WordPress 3.1.3" />
<style type="text/css">.recentcomments a{display:inline !important;padding:0 !important;margin:0 !important;}</style>
<!--[if lt IE 7]>
<!-- script defer type="text/javascript" src="http://www.iigrowing.cn/wp-content/themes/ecomag/js/pngfix.js"></script -->
<style type="text/css">
*html .excrept_in {height: 1%;}
</style>
<![endif]-->
</head>
<body>
<div id="header">
<div id="topnav">
<div id="topnav_left">
<ul id="pagenav">
<li class="page_item page-item-2"><a href="http://www.iigrowing.cn/sample-page" title="关于">关于</a></li>
<li class="page_item page-item-181"><a href="http://www.iigrowing.cn/hadoop_intr" title="hadoop导读">hadoop导读</a></li>
</ul>
</div>
<div id="topnav_right">
关于压缩,头信息说明了是否缓存这个页面,如果缓存的话如何去做,有什么cookies要去设置(前面这个响应里没有这点)和隐私信息等等。
请注意报头中把Content-type设置为“text/html”。报 头让浏览器将该响应内容以HTML形式呈现,而不是以文件形式下载它。浏览器会根据报头信息决定如何解释该响应,不过同时也会考虑像URL扩展内容等其他 因素。
7. 浏览器开始显示HTML
在浏览器没有完整接受全部HTML文档时,它就已经开始显示这个页面了:
有时页面设置得当的话,浏览器会边下载边显示页面的,但若是设置不当,就要下载全部资源后在显示了。
8 浏览器发送获取嵌入在HTML中的对象
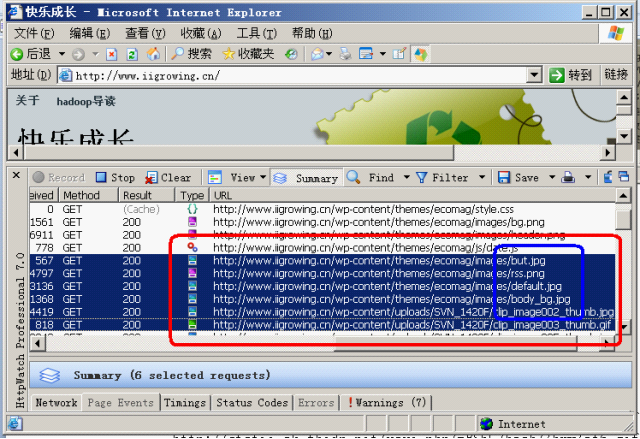
在浏览器显示HTML时,它会注意到需要获取其他地址内容的标签。这时,浏览器会发送一个获取请求来重新获得这些文件。
下面是几个我们访问www.iigrowing.cn时需要重获取的几个URL:
1. 图片
http://www.iigrowing.cn/wp-content/themes/ecomag/images/but.jpg
http://www.iigrowing.cn/wp-content/themes/ecomag/images/rss.png
…
2. CSS 式样表
http://www.iigrowing.cn/wp-content/themes/ecomag/style.css
…
3. JavaScript 文件
http://www.iigrowing.cn/wp-content/themes/ecomag/js/date.js
这些地址都要经历一个和HTML读取类似的过程。所以浏览器会在DNS中查找这些域名,发送请求,重定向等等...
但不像动态页面那样,静态文件会允许浏览器对其进行缓存。有的文件可能会不需要与服务器通讯,而从缓存中直接读取。服务器的响应中包含了静态文件保 存的期限 信息,所以浏览器知道要把它们缓存多长时间。还有,每个响应都可能包含像版本号一样工作的ETag头(被请求变量的实体值),如果浏览器观察到文件的版本 ETag信息已经存在,就马上停止这个文件的传输。




