1. Neo4j简介
Neo4j 是一个高性能的 NoSQL 图形数据库。Neo4j 使用图(graph)相关的概念来描述数据模型,把数据保存为图中的节点以及节点之间的关系。很多应用中数据之间的关系,可以很直接地使用图中节点和关系 的概念来建模。对于这样的应用,使用 Neo4j 来存储数据会非常的自然,要优于使用关系数据库。本文对 Neo4j 进行了深入的介绍,并结合具体的实例来进行详细的说明,可以让您对 Neo4j 有深入的了解,从而可以在应用开发中恰当地选择 Neo4j 来作为存储方式。Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注.
你可以把Neo看作是一个高性能的图引擎,该引擎具有成熟和健壮的数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。 [1]
Neo是一个网络——面向网络的数据库——也就是说,它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络上而不是表中。网络(从数学角度叫做图)是一个灵活的数据结构,可以应用更加敏捷和快速的开发模式。
典型应用如下:
2. Neo4j特点
- 1.对象关系的不匹配使得把面向对象的“圆的对象”挤到面向关系的“方的表”中是那么的困难和费劲,而这一切是可以避免的。
- 2.关系模型静态、刚性、不灵活的本质使得改变schemas以满足不断变化的业务需求是非常困难的。由于同样的原因,当开发小组想应用敏捷软件开发时,数据库经常拖后腿。
- 3.关系模型很不适合表达半结构化的数据——而业界的分析家和研究者都认为半结构化数据是信息管理中的下一个重头戏。
- 4.网络是一种非常高效的数据存储结构。人脑是一个巨大的网络,万维网也同样构造成网状,这些都不是巧合。关系模型可以表达面向网络的数据,但是在遍历网络并抽取信息的能力上关系模型是非常弱的。
虽然Neo是一个比较新的开源项目,但它已经在具有1亿多个节点、关系和属性的产品中得到了应用,并且能满足企业的健壮性和性能的需求:
完全支持JTA和JTS、2PC分布式ACID事务、可配置的隔离级别和大规模、可测试的事务恢复。这些不仅仅是口头上的承诺:Neo已经应用在高请求的24/7环境下超过3年了。它是成熟、健壮的,完全达到了部署的门槛。
Neo4j
数据存储一般是应用开发中不可或缺的组成部分。应用运行中产生的和所需要的数据被以特 定的格式持久化下来。应用开发中很常见的一项任务是在应用本身的领域对象模型与数据存储格式之间进行相互转换。如果数据存储格式与领域对象模型之间比较相 似,那么进行转换所需的映射关系更加自然,实现起来也更加容易。对于一个特定的应用来说,其领域对象模型由应用本身的特征来决定,一般采用最自然和最直观 的方式来进行建模。所以恰当的选择数据存储格式就显得很重要。目前最常见的数据存储格式是关系数据库。关系数据库通过实体 - 关系模型(E-R 模型)来进行建模,即以表和表之间的关系来建模。在实际开发中可以使用的关系数据库的实现非常多,包括开源的和商用的。关系数据库适合用来存储数据条目的 类型同构的表格型数据。如果领域对象模型中不同对象之间的关系比较复杂,则需要使用繁琐的对象关系映射技术(Object-Relationship Mapping,ORM)来进行转换。
对于很多应用来说,其领域对象模型并不适合于转换成关系数据库形式来存储。这也是非关系型数据库 (NoSQL)得以流行的原因。NoSQL 数据库的种类很多,包括键值对数据库、面向文档数据库和图形数据库等。本文中介绍的 Neo4j 是最重要的图形数据库。Neo4j 使用数据结构中图(graph)的概念来进行建模。Neo4j 中两个最基本的概念是节点和边。节点表示实体,边则表示实体之间的关系。节点和边都可以有自己的属性。不同实体通过各种不同的关系关联起来,形成复杂的对 象图。Neo4j 同时提供了在对象图上进行查找和遍历的功能。
对于很多应用来说,其中的领域对象模型本身就是一个图结构。对于这样的应 用,使用 Neo4j 这样的图形数据库进行存储是最适合的,因为在进行模型转换时的代价最小。以基于社交网络的应用为例,用户作为应用中的实体,通过不同的关系关联在一起,如 亲人关系、朋友关系和同事关系等。不同的关系有不同的属性。比如同事关系所包含的属性包括所在公司的名称、开始的时间和结束的时间等。对于这样的应用,使 用 Neo4j 来进行数据存储的话,不仅实现起来简单,后期的维护成本也比较低。
Neo4j 使用“图”这种最通用的数据结构来对数据进行建模使得 Neo4j 的数据模型在表达能力上非常强。链表、树和散列表等数据结构都可以抽象成用图来表示。Neo4j 同时具有一般数据库的基本特性,包括事务支持、高可用性和高性能等。Neo4j 已经在很多生产环境中得到了应用。流行的云应用开发平台 Heroku 也提供了 Neo4j 作为可选的扩展。
在简要介绍完 Neo4j 之后,下面介绍 Neo4j 的基本用法。
Neo4j 基本使用
在使用 Neo4j 之前,需要首先了解 Neo4j 中的基本概念。
节点和关系
Neo4j 中最基本的概念是节点(node)和关系(relationship)。节点表示实体,由 org.neo4j.graphdb.Node 接口来表示。在两个节点之间,可以有不同的关系。关系由 org.neo4j.graphdb.Relationship 接口来表示。每个关系由起始节点、终止节点和类型等三个要素组成。起始节点和终止节点的存在,说明了关系是有方向,类似于有向图中的边。不过在某些情况, 关系的方向可能并没有意义,会在处理时被忽略。所有的关系都是有类型的,用来区分节点之间意义不同的关系。在创建关系时,需要指定其类型。关系的类型由 org.neo4j.graphdb.RelationshipType 接口来表示。节点和关系都可以有自己的属性。每个属性是一个简单的名值对。属性的名称是 String 类型的,而属性的值则只能是基本类型、String 类型以及基本类型和 String 类型的数组。一个节点或关系可以包含任意多个属性。对属性进行操作的方法声明在接口 org.neo4j.graphdb.PropertyContainer 中。Node 和 Relationship 接口都继承自 PropertyContainer 接口。PropertyContainer 接口中常用的方法包括获取和设置属性值的 getProperty 和 setProperty。下面通过具体的示例来说明节点和关系的使用。
该示例是一个简单的歌曲信息管理程序,用来记录歌手、歌曲和专辑等相关信息。在这个程序中,实体包括歌手、歌曲和专辑,关系则包括歌手与专辑之间的发布关系,以及专辑与歌曲之间的包含关系。清单 1 给出了使用 Neo4j 对程序中的实体和关系进行操作的示例。
清单 1. 节点和关系的使用示例
private static enum RelationshipTypes implements RelationshipType {
PUBLISH, CONTAIN
}
public void useNodeAndRelationship() {
GraphDatabaseService db = new EmbeddedGraphDatabase("music");
Transaction tx = db.beginTx();
try {
Node node1 = db.createNode();
node1.setProperty("name", "歌手 1");
Node node2 = db.createNode();
node2.setProperty("name", "专辑 1");
node1.createRelationshipTo(node2, RelationshipTypes.PUBLISH);
Node node3 = db.createNode();
node3.setProperty("name", "歌曲 1");
node2.createRelationshipTo(node3, RelationshipTypes.CONTAIN);
tx.success();
} finally {
tx.finish();
}
}在 清单 1 中,首先定义了两种关系类型。定义关系类型的一般做法是创建一个实现了 RelationshipType 接口的枚举类型。RelationshipTypes 中的 PUBLISH 和 CONTAIN 分别表示发布和包含关系。在 Java 程序中可以通过嵌入的方式来启动 Neo4j 数据库,只需要创建 org.neo4j.kernel.EmbeddedGraphDatabase 类的对象,并指定数据库文件的存储目录即可。在使用 Neo4j 数据库时,进行修改的操作一般需要包含在一个事务中来进行处理。通过 GraphDatabaseService 接口的 createNode 方法可以创建新的节点。Node 接口的 createRelationshipTo 方法可以在当前节点和另外一个节点之间创建关系。
另外一个与节点和关系相关的概念是路径。路径 有一个起始节点,接着的是若干个成对的关系和节点对象。路径是在对象图上进行查询或遍历的结果。Neo4j 中使用 org.neo4j.graphdb.Path 接口来表示路径。Path 接口提供了对其中包含的节点和关系进行处理的一些操作,包括 startNode 和 endNode 方法来获取起始和结束节点,以及 nodes 和 relationships 方法来获取遍历所有节点和关系的 Iterable 接口的实现。关于图上的查询和遍历,在下面小节中会进行具体的介绍。
使用索引
当 Neo4j 数据库中包含的节点比较多时,要快速查找满足条件的节点会比较困难。Neo4j 提供了对节点进行索引的能力,可以根据索引值快速地找到相应的节点。清单 2 给出了索引的基本用法。
清单 2. 索引的使用示例
public void useIndex() {
GraphDatabaseService db = new EmbeddedGraphDatabase("music");
Index<Node> index = db.index().forNodes("nodes");
Transaction tx = db.beginTx();
try {
Node node1 = db.createNode();
String name = "歌手 1";
node1.setProperty("name", name);
index.add(node1, "name", name);
node1.setProperty("gender", "男");
tx.success();
} finally {
tx.finish();
}
Object result = index.get("name", "歌手 1").getSingle()
.getProperty("gender");
System.out.println(result); // 输出为“男”
}在 清单 2 中,通过 GraphDatabaseService 接口的 index 方法可以得到管理索引的 org.neo4j.graphdb.index.IndexManager 接口的实现对象。Neo4j 支持对节点和关系进行索引。通过 IndexManager 接口的 forNodes 和 forRelationships 方法可以分别得到节点和关系上的索引。索引通过 org.neo4j.graphdb.index.Index 接口来表示,其中的 add 方法用来把节点或关系添加到索引中,get 方法用来根据给定值在索引中进行查找。
图的遍历
在图上进行的最实用的操作是图的遍历。通过遍历操作,可以获取到与图中节点之间的关系相关的信息。Neo4j 支持非常复杂的图的遍历操作。在进行遍历之前,需要对遍历的方式进行描述。遍历的方式的描述信息由下列几个要素组成。
- 遍历的路径:通常用关系的类型和方向来表示。
- 遍历的顺序:常见的遍历顺序有深度优先和广度优先两种。
- 遍历的唯一性:可以指定在整个遍历中是否允许经过重复的节点、关系或路径。
- 遍历过程的决策器:用来在遍历过程中判断是否继续进行遍历,以及选择遍历过程的返回结果。
- 起始节点:遍历过程的起点。
Neo4j 中遍历方式的描述信息由 org.neo4j.graphdb.traversal.TraversalDescription 接口来表示。通过 TraversalDescription 接口的方法可以描述上面介绍的遍历过程的不同要素。类 org.neo4j.kernel.Traversal 提供了一系列的工厂方法用来创建不同的 TraversalDescription 接口的实现。清单 3 中给出了进行遍历的示例。
清单 3. 遍历操作的示例
TraversalDescription td = Traversal.description()
.relationships(RelationshipTypes.PUBLISH)
.relationships(RelationshipTypes.CONTAIN)
.depthFirst()
.evaluator(Evaluators.pruneWhereLastRelationshipTypeIs(RelationshipTypes.CONTAIN));
Node node = index.get("name", "歌手 1").getSingle();
Traverser traverser = td.traverse(node);
for (Path path : traverser) {
System.out.println(path.endNode().getProperty("name"));
}在 清单 3 中,首先通过 Traversal 类的 description 方法创建了一个默认的遍历描述对象。通过 TraversalDescription 接口的 relationships 方法可以设置遍历时允许经过的关系的类型,而 depthFirst 方法用来设置使用深度优先的遍历方式。比较复杂的是表示遍历过程的决策器的 evaluator 方法。该方法的参数是 org.neo4j.graphdb.traversal.Evaluator 接口的实现对象。Evalulator 接口只有一个方法 evaluate。evaluate 方法的参数是 Path 接口的实现对象,表示当前的遍历路径,而 evaluate 方法的返回值是枚举类型 org.neo4j.graphdb.traversal.Evaluation,表示不同的处理策略。处理策略由两个方面组成:第一个方面为是否包含当 前节点,第二个方面为是否继续进行遍历。Evalulator 接口的实现者需要根据遍历时的当前路径,做出相应的决策,返回适当的 Evaluation 类型的值。类 org.neo4j.graphdb.traversal.Evaluators 提供了一些实用的方法来创建常用的 Evalulator 接口的实现对象。清单 3 中使用了 Evaluators 类的 pruneWhereLastRelationshipTypeIs 方法。该方法返回的 Evalulator 接口的实现对象会根据遍历路径的最后一个关系的类型来进行判断,如果关系类型满足给定的条件,则不再继续进行遍历。
清单 3 中的遍历操作的作用是查找一个歌手所发行的所有歌曲。遍历过程从表示歌手的节点开始,沿着 RelationshipTypes.PUBLISH 和 RelationshipTypes.CONTAIN 这两种类型的关系,按照深度优先的方式进行遍历。如果当前遍历路径的最后一个关系是 RelationshipTypes.CONTAIN 类型,则说明路径的最后一个节点包含的是歌曲信息,可以终止当前的遍历过程。通过 TraversalDescription 接口的 traverse 方法可以从给定的节点开始遍历。遍历的结果由 org.neo4j.graphdb.traversal.Traverser 接口来表示,可以从该接口中得到包含在结果中的所有路径。结果中的路径的终止节点就是表示歌曲的实体。
Neo4j 实战开发
在 介绍了 Neo4j 的基本使用方式之后,下面通过具体的案例来说明 Neo4j 的使用。作为一个数据库,Neo4j 可以很容易地被使用在 Web 应用开发中,就如同通常使用的 MySQL、SQL Server 和 DB2 等关系数据库一样。不同之处在于如何对应用中的数据进行建模,以适应后台存储方式的需求。同样的领域模型,既可以映射为关系数据库中的 E-R 模型,也可以映射为图形数据库中的图模型。对于某些应用来说,映射为图模型更为自然,因为领域模型中对象之间的各种关系会形成复杂的图结构。
本 节中使用的示例是一个简单的微博应用。在微博应用中,主要有两种实体,即用户和消息。用户之间可以互相关注,形成一个图结构。用户发布不同的微博消息。表 示微博消息的实体也是图中的一部分。从这个角度来说,使用 Neo4j 这样的图形数据库,可以更好地描述该应用的领域模型。
如同使用关系 数据库一样,在使用 Neo4j 时,既可以使用 Neo4j 自身的 API,也可以使用第三方框架。Spring 框架中的 Spring Data 项目提供了对 Neo4j 的良好支持,可以在应用开发中来使用。Spring Data 项目把 Neo4j 数据库中的 CRUD 操作、使用索引和进行图的遍历等操作进行了封装,提供了更加抽象易用的 API,并通过使用注解来减少开发人员所要编写的代码量。示例的代码都是通过 Spring Data 来使用 Neo4j 数据库的。下面通过具体的步骤来介绍如何使用 Spring Data 和 Neo4j 数据库。
开发环境
使用 Neo4j 进行开发时的开发环境的配置比较简单。只需要根据 参考资源中给出的地址,下载 Neo4j 本身的 jar 包以及所依赖的 jar 包,并加到 Java 程序的 CLASSPATH 中就可以了。不过推荐使用 Maven 或 Gradle 这样的工具来进行 Neo4j 相关依赖的管理。
定义数据存储模型
前面已经提到了应用中有两种实体,即用户和消息。这两种实体需要定义为对象图中的节点。清单 1 中给出的创建实体的方式并不直观,而且并没有专门的类来表示实体,后期维护成本比较高。Spring Data 支持在一般的 Java 类上添加注解的方式来声明 Neo4j 中的节点。只需要在 Java 类上添加 org.springframework.data.neo4j.annotation.NodeEntity 注解即可,如 清单 4 所示。
清单 4. 使用 NodeEntity 注解声明节点类
@NodeEntity
public class User {
@GraphId Long id;
@Indexed
String loginName;
String displayName;
String email;
}如 清单 4 所示,User 类用来表示用户,作为图中的节点。User 类中的域自动成为节点的属性。注解 org.springframework.data.neo4j.annotation.GraphId 表明该属性作为实体的标识符,只能使用 Long 类型。注解 org.springframework.data.neo4j.annotation.Indexed 表明为属性添加索引。
节点之间的关系同样用注解的方式来声明,如 清单 5 所示。
清单 5. 使用 RelationshipEntity 注解声明关系类
@RelationshipEntity(type = "FOLLOW")
public class Follow {
@StartNode
User follower;
@EndNode
User followed;
Date followingDate = new Date();
}在 清单 5 中,RelationshipEntity 注解的属性 type 表示关系的类型,StartNode 和 EndNode 注解则分别表示关系的起始节点和终止节点。
在表示实体的类中也可以添加对关联的节点的引用,如 清单 6 中给出的 User 类中的其他域。
清单 6. User 类中对关联节点的引用
@RelatedTo(type = "FOLLOW", direction = Direction.INCOMING) @Fetch Set<User> followers = new HashSet<User>(); @RelatedTo(type = "FOLLOW", direction = Direction.OUTGOING) @Fetch Set<User> followed = new HashSet<User>(); @RelatedToVia(type = "PUBLISH") Set<Publish> messages = new HashSet<Publish>();
如 清单 6 所示,注解 RelatedTo 表示与当前节点通过某种关系关联的节点。因为关系是有向的,可以通过 RelatedTo 的 direction 属性来声明关系的方向。对当前用户节点来说,如果 FOLLOW 关系的终止节点是当前节点,则说明关系的起始节点对应的用户是当前节点对应的用户的粉丝,用“direction = Direction.INCOMING”来表示。因此 followers 域表示的是当前用户的粉丝的集合,而 followed 域表示的是当前用户所关注的用户的集合。注解 RelatedToVia 和 RelatedTo 的作用类似,只不过 RelatedToVia 不关心关系的方向,只关心类型。因此 messages 域包含的是当前用户所发布的消息的集合。
数据操作
在 定义了数据存储模型之后,需要创建相应的类来对数据进行操作。数据操作的对象是数据模型中的节点和关系类的实例,所涉及的操作包括常见的 CRUD,即创建、读取、更新和删除,还包括通过索引进行的查找和图上的遍历操作等。由于这些操作的实现方式都比较类似,Spring Data 对这些操作进行了封装,提供了简单的使用接口。Spring Data 所提供的数据操作核心接口是 org.springframework.data.neo4j.repository.GraphRepository。 GraphRepository 接口继承自三个提供不同功能的接 口:org.springframework.data.neo4j.repository.CRUDRepository 接口提供 save、delete、findOne 和 findAll 等方法,用来进行基本的 CRUD 操作;org.springframework.data.neo4j.repository.IndexRepository 则提供了 findByPropertyValue、findAllByPropertyValue 和 findAllByQuery 等方法,用来根据索引来查 找;org.springframework.data.neo4j.repository.TraversalRepository 则提供了 findAllByTraversal 方法,用来根据 TraversalDescription 接口的描述来进行遍历操作。
Spring Data 为 GraphRepository 接口提供了默认的实现。在大多数情况下,只需要声明一个接口继承自 GraphRepository 接口即可,Spring Data 会在运行时创建相应的实现类的对象。对表示用户的节点类 User 进行操作的接口 UserRepository 如 清单 7 所示。
清单 7. 操作 User 类的 UserRepository 接口
public interface UserRepository extends GraphRepository<User> {
}如 清单 7 所示,UserRepository 接口继承自 GraphRepository 接口,并通过泛型声明要操作的是 User 类。对节点类的操作比较简单,而对于关系类的操作就相对复杂一些。清单 8 中给出了对发布关系进行操作的接口 PublishRepository 的实现。
清单 8. 操作 Publish 类的 PublishRepository 接口
public interface PublishRepository extends GraphRepository<Publish> {
@Query("start user1=node({0}) " +
" match user1-[:FOLLOW]->user2-[r2:PUBLISH]->followedMessage" +
" return r2")
List<Publish> getFollowingUserMessages(User user);
@Query("start user=node({0}) match user-[r:PUBLISH]->message return r")
List<Publish> getOwnMessages(User user);
}在 清单 8 中,getFollowingUserMessages 方法用来获取某个用户关注的所有其他用户所发布的消息。该方法的实现是通过图上的遍历操作来完成的。Spring Data 提供了一种简单的查询语言来描述遍历操作。通过在方法上添加 org.springframework.data.neo4j.annotation.Query 注解来声明所使用的遍历方式即可。以 getFollowingUserMessages 方法的遍历声明为例,“node({0})”表示当前节点,“start user1=node({0})”表示从当前节点开始进行遍历,并用 user1 表示当前节点。“match”用来表示遍历时选中的节点应该满足的条件。条件“user1-[:FOLLOW]->user2- [r2:PUBLISH]->followedMessage”中,先通过类型为 FOLLOW 的关系找到 user1 所关注的用户,以 user2 来表示;再通过类型为 PUBLISH 的关系,查找 user2 所发布的消息。“return”用来返回遍历的结果,r2 表示的是类型为 PUBLISH 的关系,与 getFollowingUserMessages 方法的返回值类型 List<Publish> 相对应。
在应用中的使用
在定义了数据操作的接口之后,就可以在应用的服务层代码中使用这些接口。清单 9 中给出了用户发布新微博时的操作方法。
清单 9. 用户发布新微博的方法
@Autowired
UserRepository userRepository;
@Transactional
public void publish(User user, String content) {
Message message = new Message(content);
messageRepository.save(message);
user.publish(message);
userRepository.save(user);
}如 清单 9 所示,publish 方法用来给用户 user 发布内容为 content 的微博。域 userRepository 是 UserRepository 接口的引用,由 Spring IoC 容器在运行时自动注入依赖,该接口的具体实现由 Spring Data 提供。在 publish 方法中,首先创建一个 Message 实体类的对象,表示消息节点;再通过 save 方法把该节点保存到数据库中。User 类的 publish 方法的实现如 清单 10 所示,其逻辑是创建一个 Publish 类的实例表示发布关系,并建立用户和消息实体之间的关系。最后再更新 user 对象即可。
清单 10. User 类的 publish 方法
@RelatedToVia(type = "PUBLISH")
Set<Publish> messages = new HashSet<Publish>();
public Publish publish(Message message) {
Publish publish = new Publish(this, message);
this.messages.add(publish);
return publish;
}在创建了相关的服务层类之后,就可以从服务层中暴露出相关的使用 JSON 的 REST 服务,然后在 REST 服务的基础上创建应用的前端展示界面。界面的实现部分与 Neo4j 并无关系,在这里不再赘述。整个程序基于 Spring 框架来开发。Spring Data 为 Neo4j 提供了独立的配置文件名称空间,可以方便在 Spring 配置文件中对 Neo4j 进行配置。清单 11 给出了与 Neo4j 相关的 Spring 配置文件。
清单 11. Neo4j 的 Spring 配置文件
<neo4j:config storeDirectory="data/neo-mblog.db" /> <neo4j:repositories base-package="com.chengfu.neomblog.repository" />
在 清单 11 中,config 元素用来设置 Neo4j 数据库的数据保存目录,repositories 元素用来声明操作 Neo4j 中的节点和关系类的 GraphRepository 接口的子接口的包名。Spring Data 会负责在运行时扫描该 Java 包,并为其中包含的接口创建出对应的实现对象。
示例应用的完整代码存放在 GitHub 上,见 参考资源。
使用 Neo4j 原生 API
如 果不使用 Spring Data 提供的 Neo4j 支持,而使用 Neo4j 的原生 API,也是一样可以进行开发。只不过由于 Neo4j 的原生 API 的抽象层次较低,使用起来不是很方便。下面以示例应用中用户发布微博的场景来展示原生 API 的基本用法,见 清单 12。
清单 12. 使用 Neo4j 原生 API
public void publish(String username, String message) {
GraphDatabaseService db = new EmbeddedGraphDatabase("mblog");
Index<Node> index = db.index().forNodes("nodes");
Node ueserNode = index.get("user-loginName", username).getSingle();
if (ueserNode != null){
Transaction tx = db.beginTx();
try {
Node messageNode = db.createNode();
messageNode.setProperty("message", message);
ueserNode.createRelationshipTo(messageNode, RelationshipTypes.PUBLISH);
tx.success();
} finally {
tx.finish();
}
}
}从 清单 12 中可以看出,原生 API 的基本用法是先通过 Neo4j 数据库的索引找到需要操作的表示用户的节点,然后再创建出表示微博消息的节点,最后在两个节点之间建立关系。这些步骤都使用 Neo4j 的基本 API 来完成。
与 清单 10 中使用 Spring Data 的功能相同的方法进行比较,可以发现使用原生 API 的代码要复杂不少,而使用 Spring Data 的则简洁很多。因此,在实际开发中推荐使用 Spring Data。
小结
关 系数据库在很长一段时间都是大多数应用采用的数据存储方式的首要选择。随着技术的发展,越来越多的 NoSQL 数据库开始流行起来。对于应用开发人员来说,不应该总是盲目使用关系数据库,而是要根据应用本身的特点,选用最合适的存储方式。Neo4j 数据库以“图”作为数据之间关系的描述方式,非常适合于使用在数据本身就以图结构来组织的应用中。本文对 Neo4j 数据库的使用做了详细的介绍,可以帮助开发人员了解和使用 Neo4j 数据库。
Neo4j图形数据结构
在一个图中包含两种基本的数据类型:Nodes(节点) 和 Relationships(关系)。Nodes 和 Relationships 包含key/value形式的属性。Nodes通过Relationships所定义的关系相连起来,形成关系型网络结构。

Neo4j安装
Neo4j可以被安装成一个独立运行的服务端程序,客户端程序通过REST API进行访问。也可以嵌入式安装,即安装为编程语言的第三方类库,目前只支持java和python语言。
因Neo4j是用java语言开发的,所以确保将要安装的机器上已安装了jre或者jdk
安装为服务
此种安装方式简单,各平台安装过程基本一样
- 从http://neo4j.org/download上下载最新的版本,根据安装的平台选择适当的版本。
- 解压安装包,解压后运行终端,进入解压后文件夹中的bin文件夹。
- 在终端中运行命令完成安装
Linux/MacOS系统
neo4j install
Windows系统Neo4j.bat install - 在终端中运行命令开启服务
Linux/MacOS系统
service neo4j-service start
Windows系统Neo4j.bat start
通过stop命令可以关闭服务,status命令查看运行状态
支持python嵌入式安装
第一步:安装Jpype
从http://sourceforge.net/projects/jpype/files/JPype/ 下载最新版本,windows有exe格式的直接安装程序,linux平台要下载源码包,解压后运行sudo python setup.py install完成安装
第二步:安装 neo4j-embedded
如果安装了python的包管理工具 pip 或者 easy_install 可直接运行
Pip install neo4j-embedded
easy_install neo4j-embedded
也可以从http://pypi.python.org/pypi/neo4j-embedded/下载相应的安装包完成安装。
Neo4j使用实例
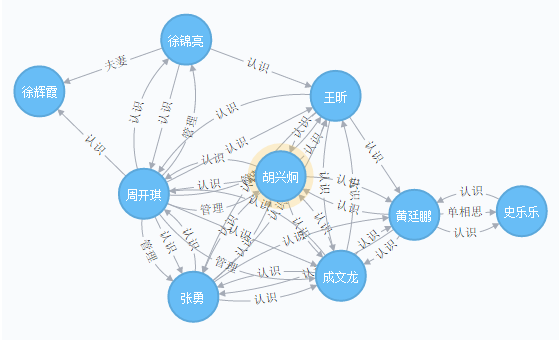
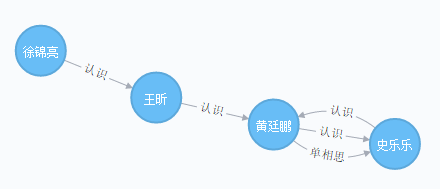
有如下所示的用户关注关系所形成的关系网络

现在利用图形数据库进行数据的储存,并获得user1 的粉丝,并为user4 推荐好友
# -*- coding: utf-8 -*-
#
# Neo4j图形数据库示例
#
from neo4j import GraphDatabase, INCOMING
# 创建或连接数据库
db = GraphDatabase('neodb')
# 在一个事务内完成写或读操作
with db.transaction:
#创建用户组节点
users = db.node()
# 连接到参考节点,方便查找
db.reference_node.USERS(users)
# 为用户组建立索引,便于快速查找
user_idx = db.node.indexes.create('users')
#创建用户节点
def create_user(name):
with db.transaction:
user = db.node(name=name)
user.INSTANCE_OF(users)
# 建立基于用户name的索引
user_idx['name'][name] = user
return user
#根据用户名获得用户节点
def get_user(name):
return user_idx['name'][name].single
#建立节点
for name in ['user1', 'user2','user3','user4']:
create_user(name)
#为节点间添加关注关系(FOLLOWS)
with db.transaction:
get_user('user2').FOLLOWS(get_user('user1'))
get_user('user3').FOLLOWS(get_user('user1'))
get_user('user4').FOLLOWS(get_user('user3'))
# 获得用户1的粉丝
for relationship in get_user('user1').FOLLOWS.incoming:
u = relationship.start
print u['name']
#输出结果:user2,user3
#为用户4推荐好友,即该用户关注的用户所关注的用户
nid = get_user('user4').id
#设置查询语句
query = "START n=node({id}) MATCH n-[:FOLLOWS]->m-[:FOLLOWS]->fof RETURN n,m,fof"
for row in db.query(query,id=nid):
node = row['fof']
print node['name']
#输出结果:user1



