原创文章,转载请指明出处并保留原文url地址
引言,hadoop代表一种全新的编程思想,基于hadoop有很多衍生项目,充分利用他们
为我们服务是非常必要的,同时hadoop又是一个复杂系统,若能理解他的工作原理对
我们将有非常大的帮助,我们在这里以hadoop的0.1.0版本为基础逐步分析他的基本工作
原理、结构、思路等等,希望通过这个能帮助我们理解生产中的hadoop系统。 时间有限,
经验不足,疏漏难免,在这里仅仅分享一些心得,希望对大家能起到一个抛砖引玉的作用吧,
有问题请大家给我留言或者评论等,这样也能对我的工作有莫大的帮助。
感谢您阅读这篇文章!
hadoop 相关视频下载地址: http://pan.baidu.com/share/link?shareid=223046310&uk=3073578852
本篇文档是前一篇文档的延续,我们分析datanode节点启动完毕后的工作状况, 本篇文档着重点仍然是源代码的分析工作,后面我们会专门总结一下相关的工作过程,然后再逐步细化相关工作
一.数据读写功能(监听及用户请求接受)
1. 监控进程的启动
在上一篇文章中的构造函数中,如下图
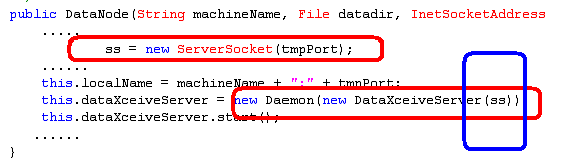
ss = new ServerSocket(tmpPort);
......
this.localName = machineName + ":" + tmpPort;
this.dataXceiveServer = new Daemon(new DataXceiveServer(ss));
this.dataXceiveServer.start();
2. DataXceiveServer类
如上图,注意几个特殊颜色的区域,
第一个区域是创建一个server类型的socket对象,
第二个区域(红色的)创建一个DataXceiveServer匿名对象,然后将创建好的socket对象传递给这个匿名对象。
最后启动这个对象
下面我们了解一下DataXceiveServer类是做什么的。
class DataXceiveServer implements Runnable { // 这个类实现了Runnable 接口因此他可以同线程对象共同工作,可以认为是一个线程。
boolean shouldListen = true; // 关闭标示
ServerSocket ss; // server类型的socket对象
public DataXceiveServer(ServerSocket ss) { // 构造函数
this.ss = ss;
}
public void run() { // java的线程的执行函数,
try {
while (shouldListen) { // 检查线程是否需要退出,若是退出则关闭,执行后面代码
Socket s = ss.accept(); // 这个函数是个阻塞函数,程序阻塞到这里,直到有用户的socket请求到来,然后函数返回新连接的socket对象,程序执行下面代码
//s.setSoTimeout(READ_TIMEOUT);
new Daemon(new DataXceiver(s)).start(); // 创建一下新的线程执行用户请求,然后程序继续循环,继续等待用户的请求
}
ss.close();
} ........
public void kill() { // 关闭这个线程,里面代码较简单,大家自己研究一下了。
...... }
}
3. DataXceiver类的功能
下面我们来看看DataXceiver做什么的,如下图是我们理解的重点
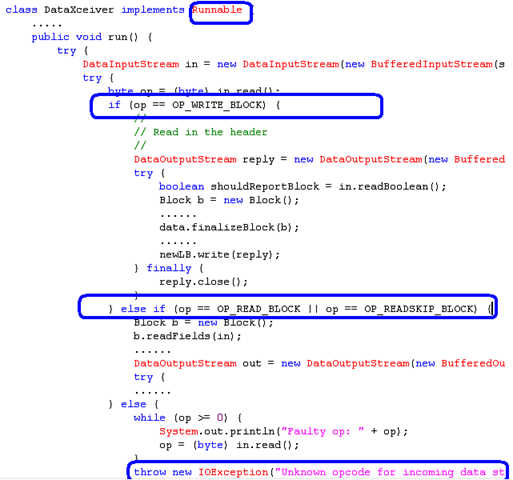
如上图,
首先这个类实现了Runnable 接口,如第一个蓝色区域,因此它是个线程对象(这么说不够准确,但是可以先这么理解)
第二,程序判断是否为写操作,如第二个蓝色区域![]() 所示, 若是相关的块写操作则进行一些列的写操作等,本文主要分析基本工作过程,至于详细的写过程我们可以稍后再行分析。
所示, 若是相关的块写操作则进行一些列的写操作等,本文主要分析基本工作过程,至于详细的写过程我们可以稍后再行分析。
第三,程序判断是否是读块操作等,
![]()
相关代码自然有一番了,我们暂不讨论。
相关核心代码如下:
class DataXceiver implements Runnable {
Socket s;
public DataXceiver(Socket s) {
this.s = s; }
public void run() {
try {
DataInputStream in = new DataInputStream(new BufferedInputStream(s.getInputStream()));
try {
byte op = (byte) in.read();
if (op == OP_WRITE_BLOCK) {
//
// Read in the header
//
DataOutputStream reply = new DataOutputStream(new BufferedOutputStream(s.getOutputStream()));
try {
boolean shouldReportBlock = in.readBoolean();
Block b = new Block();
......
data.finalizeBlock(b);
......
newLB.write(reply);
} finally {
reply.close();
}
} else if (op == OP_READ_BLOCK || op == OP_READSKIP_BLOCK)
Block b = new Block();
b.readFields(in);
......
DataOutputStream out = new DataOutputStream(new BufferedOutputStream(s.getOutputStream()));
try {
......
} else {
while (op >= 0) {
System.out.println("Faulty op: " + op);
op = (byte) in.read();
}
throw new IOException("Unknown opcode for incoming data stream");
}
..............
}
二.任务调度工作过程
1. 任务调度线程的启动
在datanode启动的run函数中,有如下代码,如下图
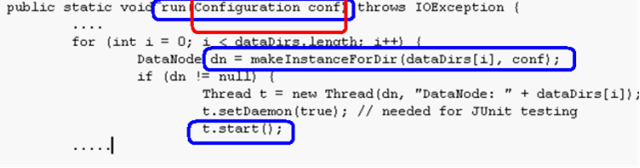
请注意上图中,蓝色及红色区域部分的代码
1. 蓝色区域1(从上到下排列),是run函数定义,这里的run函数,同java线程的run函数是有区别的, 线程的run函数不带任何参数呀,这里的带有参数。 线程的是个实例函数,这里是个静态函数。因此这里仅仅是名称相同而已并无其他联系。请读者注意。
2. 蓝色区域2,是另外一个静态方法创建了一个 datanode类的一个实例,这个实例被保存到dn变量中,然后创建了一个线程,这个变量被传递给新的线程对象,相关的这个函数,请参考前面的章节。
3. 蓝色区域3,开始这个工作线程,这函数调用后线程将被运行,然后线程的run函数将被调用,这里被调用的run函数是个实例的,无参数run函数,因此不会是本run函数,注意红色区域,已经表明了将要介绍的run函数同 本run函数的区别,请特别注意。
2. Datanode的工作函数
Datanode的run函数,如下:

注意datanode中有几个内部类,每个内部类都是线程相关因此都有run函数,因此在寻找run函数时要千万注意别找错误啦
代码如下:
public void run() {
LOG.info("Starting DataNode in: "+data.data); // 日志
while (shouldRun) { // 程序循环判断是否需要退出,若是不退出循环执行下面的函数
try {
offerService(); // 执行相关服务,这个函数非常重要,是本文重要内容之一
} catch (Exception ex) {
LOG.info("Exception: " + ex);
if (shouldRun) {
LOG.info("Lost connection to namenode. Retrying...");
try {
Thread.sleep(5000);
} catch (InterruptedException ie) {
}
}
}
}
LOG.info("Finishing DataNode in: "+data.data);
}
3. Datanode的工作过程offerService函数
如下图

上图是关于工作过程代码的一个简要整理,便于看到相关工作过程,大家需要看图,然后再参照源代码才能较好的理解。还是一句话, 阅读仅仅就是阅读了, 参与才能理解,收获才多。
我们解释一下相关情况。
程序首先会循环进行相关处理工作,知道有退出条件为止(while (shouldRun) )
程序在执行过程作了如下相关工作
1. 如图中红色1处,程序会主动计算多长时间没有向namenode汇报心跳信息了,namenode根据这个信息来维护整个工作集群,若是汇报时间到啦, 则主动汇报工作了。
2. 向namenode汇报本地块信息(namenode中的全部块信息都是这么获取的,然后保存到内存中,因此若是集群从新启动,这个过程是需要一定时间的,这个问题也是本次hadoop分析最终要了解的,了解了才能很好利用hadoop解决生产中的一些问题),汇报同时会获取一下数据从namenode节点,这里是一些需要本地删除的孤立块数据
3. 主动汇报最近接收到的块数据给namenode节点。 提示:这个功能是否同前面的重复呢?应该不是的,考虑系统刚刚启动过程中,没有接收到新数据块,若是没有2中的主动汇报机制,就有问题了。
以上工作完成后datanode还会主动询问是否有工作需要自己做的,若是有,有如下两种情况
4. 数据传输功能,datanode从namenode获得数据传输命令后,进行相关数据传输工作, 另外,好像目前我没有发现datanode节点主要连接别的节点读取数据的情况,好像都是一个datanode主动传输数据给别的节点,这个我没特别花时间去确认。读者可以研究一下,有消息告诉我。
5. 处理那些是需要删除的数据等等
6. 系统等待一段时间
相关源代码如下:
public void offerService() throws Exception {
long wakeups = 0;
long lastHeartbeat = 0, lastBlockReport = 0;
long sendStart = System.currentTimeMillis();
int heartbeatsSent = 0;
LOG.info("using BLOCKREPORT_INTERVAL of " + blockReportInterval + "msec");
//
// Now loop for a long time....
//
while (shouldRun) {
long now = System.currentTimeMillis();
//
// Every so often, send heartbeat or block-report
//
synchronized (receivedBlockList) {
// 心跳信息
if (now - lastHeartbeat > HEARTBEAT_INTERVAL) {
namenode.sendHeartbeat(localName, data.getCapacity(), data.getRemaining());
lastHeartbeat = now;
}
if (now - lastBlockReport > blockReportInterval) {
// 块报告,返回一些数据(孤立的快数据,这些块需要被删除)
Block toDelete[] = namenode.blockReport(localName, data.getBlockReport());
data.invalidate(toDelete);
lastBlockReport = now;
continue;
}
if (receivedBlockList.size() > 0) {
// 回报最近接收到的块数据信息
Block blockArray[] = (Block[]) receivedBlockList.toArray(new Block[receivedBlockList.size()]);
receivedBlockList.removeAllElements();
namenode.blockReceived(localName, blockArray);
}
if (now - sendStart > datanodeStartupPeriod) {
// 主动询问是否有什么命令是需要 datanode节点执行的
BlockCommand cmd = namenode.getBlockwork(localName, xmitsInProgress);
if (cmd != null && cmd.transferBlocks()) {
// 发送一些数据到另外的hadoop的datanode节点
Block blocks[] = cmd.getBlocks();
DatanodeInfo xferTargets[][] = cmd.getTargets();
.....
} else if (cmd != null && cmd.invalidateBlocks()) {
// 检查哪些块是需要删除的,然后删除了,等等
data.invalidate(cmd.getBlocks());
}
}
//
// There is no work to do; sleep until hearbeat timer elapses,
// or work arrives, and then iterate again.
//
long waitTime = HEARTBEAT_INTERVAL - (now - lastHeartbeat);
if (waitTime > 0 && receivedBlockList.size() == 0) {
try {
// 在没有工作任务后,线程等待新任务到来, 同时设置超时时间,
// 1.超时时间到,线程自动检查是否有主动的汇报等任务要执行
// 2.等待另外一个任务通知已经可以工作啦,然后进行相关工作
receivedBlockList.wait(waitTime);
receivedBlockList.wait(waitTime);
} catch (InterruptedException ie) {
}
}
}
}
}
本篇文章仅仅是对启动工作过程中涉及一些主要代码的解释,读者若是想真正理解相关过程,必须自己去体会,自己去看代码,去调试代码等等,相关开发环境及项目在前面文章中已经给出,可以查找前面的文章,再次感谢您阅读本文章,谢谢!
参考文章
Hadoop源代码分析 之Datanode工作原理(5)—–拷贝文件过程总结
Hadoop源代码分析 之Datanode工作原理(4)—–拷贝本地文件到hadoop的过程
Hadoop源代码分析 之Datanode工作原理(3)—–datanode工作过程总结
Hadoop源代码分析 之Datanode工作原理(2)—–datanode基本工作过程
Hadoop源代码分析 之Datanode工作原理(1)—–datanode启动过程代码分析
Hadoop源代码分析 之hadoop配置及启动(4)—–启动过程汇总
Hadoop源代码分析 之hadoop配置及启动(3)—–classpath与hadoop主要组件启动过程
Hadoop源代码分析 之hadoop配置及启动(2)—–classpath与启动shell脚本
Hadoop源代码分析 之hadoop配置及启动(1)—–classpath与配置文件
Hadoop源代码分析 之hadoop源代码项目(1)—–创建eclipse下java项目
Hadoop源代码分析 之环境配置(1)—–hadoop虚拟机配置
Hadoop源代码分析 之概念介绍(2)—–初学者眼中的hadoop

