原创文档,转载请将原文url地址标明
hadoop 相关视频下载地址: http://pan.baidu.com/share/link?shareid=223046310&uk=3073578852
本文将以一个刚刚接触hadoop的程序员视角,来考虑hadoop是什么事物,他有何特点,同时我们应该如何理解hadoop,他的总体结构及特点。
系列文章简介,hadoop代表一种新的编程思想,基于hadoop有很多衍生项目,充分利用他们是非常必要的,同时hadoop又是一个复杂系统,若能理解他的工作原理对我们将有非常大的帮助,我们以hadoop 0.1.0版本为基础逐步分析他的基本工作原理、结构、思路等等,本文是系统文章的一部分,系列文章详情参见希望通过这个能帮助我们理解生产中hadoop。 时间有限,经验不足,疏漏难免,在这里仅分享一些心得,希望对大家能起到一个抛砖引玉的作用,有问题请大家给我留言或者评论等,这样也能对我的工作有很大帮助。感谢您阅读这篇文章!
1. hadoop基本情况
下面我们简单介绍hadoop的一些基本情况,我们可了解相关情况,如下图
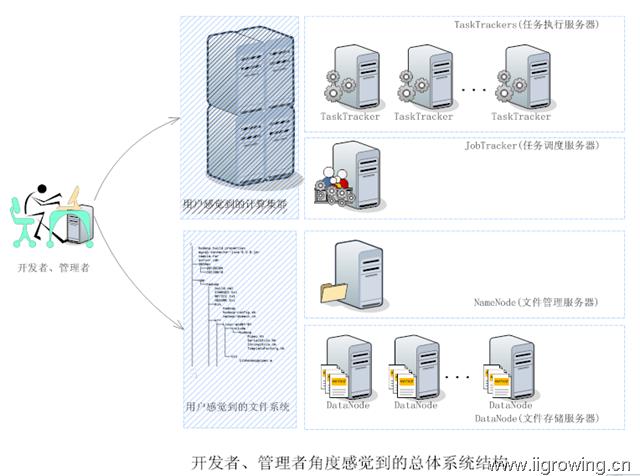
对于管理者、开发者,首先应该了解到hadoop由两个系统组成:
一个是统一的文件系统(一个分布式存储的文件系统,对外提供统一的访问接口,开发者就像使用一个统一的文件系统一样方便,简单)。
另一个是分布式的计算集群,可以简单看为一个计算能力超强的服务器。
管理者的任务是将必要的数据等通过客户端传输到统一的文件系统中。
开发者任务是编写程序,程序在统一的文件系统中获取数据,然后进行处理,最后处理结果存储到统一的分布式文件系统中(为什么
处理结果需要存储到分布式文件系统中?我们后面文档来回答这个问题)。
最后管理者可以对程序结果做各种处理等。
管理者及开发者是一个简单逻辑感念,通常两者可能是同一个人。
2.hadoop常用命令
Hadoop对集群的管理者提供了一系列的管理命令行工具。
当hadoop系统配置完毕后,在hadoop服务器上(任何一台正确配置的hadoop服务器包括:Namenode,Datanode,jobtracter,tasktracter)输入hadoop命令(在hadoop安装系统的bin目录下),系统就会显示相关命令行信息
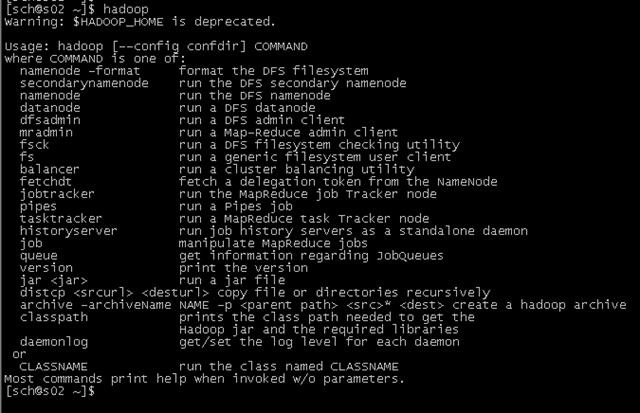
常见的hadoop命令如下
[sch@s02 ~]$ hadoop
namenode -format 格式化一个文件系统,请慎用
namenode 运行一个名称节点(管理文件系统)
datanode 运行一个数据节点
dfsadmin 管理一个文件,包括若干相关命令
fs 文件一般操作,包括移动,上传,获取,显示,列目录(ls)
其中:hadoop fs 是文件的一般操作,使用最为频繁
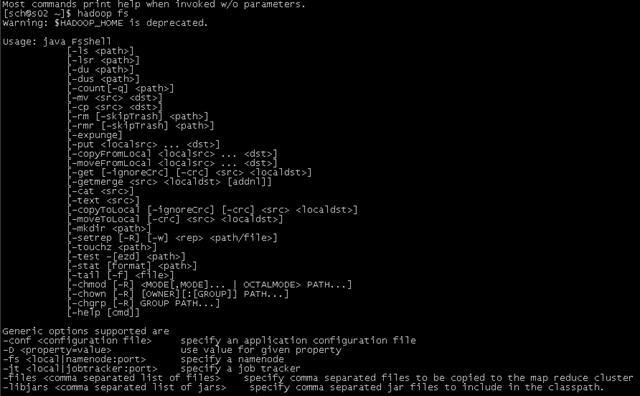
其中:
[-ls <path>] 显示特定目录下文件,例如 hadoop fs –ls / 显示hadoop文件系统中个根目录下的文件等。
[-lsr <path>] 同上面类似,只是递归显示
[-mv <src> <dst>] 移动文件
[-cp <src> <dst>] 复制文件
[-rm [-skipTrash] <path>] 删除文件
[-rmr [-skipTrash] <path>] 递归删除
[-put <localsrc> ... <dst>] 将本地文件上传到hadoop文件系统中
[-cat <src>] 显示一个hadoop文件系统中一个文件内容
[-mkdir <path>] 创建目录
下面是一个hadoop 列目录的例子
对于上面的hadoop系统结构中,我们稍加深入了解就会知道,对于统一的文件系统(hdfs,hdfs是hadoop默认文件系统,也是最初的文件系统,但是目前hadoop已经可以支持其他文件系统了)由Namenode及若干Datanode组成。
Namenode负责文件系统本身的管理工作,包括文件名称,文件目录树维护等。
Datanode负责文件的具体存储工作,同时定期汇报相关存储信息。
Namenode从不主动连接Datanode节点,总是Datanode主动联系Namenoed节点,获取相关数据并且从中取得相关命令,并且执行。
Hadoop的另一个集群系统是分布式任务管理系统,由JobTracter及TaskTracter组成。
JobTracter 负责任务的调度,任务信息的汇总等
TaskTracter负接受任务,并执行,然后主动汇报相关信息。
3.运行中hadoop结构情况
那么运行中的hadoop系统结构是否同上面结构一致。基本是上是一致的,如下图
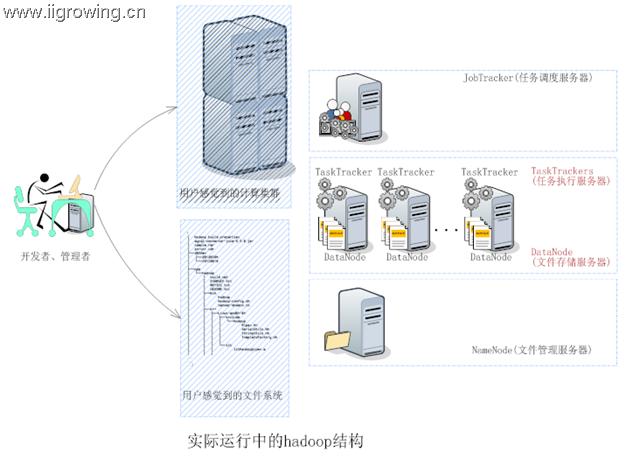
如上图,真正的hadoop系统中, Datanode及TaskTracter一般都是在同一台服务器上,也就是在datanode节点上必有tasktracter。一般hadoop启动时都是datanode及tasktracter一起启动。当然我们可以手动关闭一个任务。但是若一个节点仅仅是任务节点或者数据节点,那么就没办法发挥hadoop的优势,任务流动,数据静止的特点(如果山不过来,我就只好过去啦,一样可看到美好风景!!)
下一篇文档介绍开环环境啦,然后将正式开始分析源代码。
参考文章
Hadoop源代码分析 之Datanode工作原理(5)—–拷贝文件过程总结
Hadoop源代码分析 之Datanode工作原理(4)—–拷贝本地文件到hadoop的过程
Hadoop源代码分析 之Datanode工作原理(3)—–datanode工作过程总结
Hadoop源代码分析 之Datanode工作原理(2)—–datanode基本工作过程
Hadoop源代码分析 之Datanode工作原理(1)—–datanode启动过程代码分析
Hadoop源代码分析 之hadoop配置及启动(4)—–启动过程汇总
Hadoop源代码分析 之hadoop配置及启动(3)—–classpath与hadoop主要组件启动过程
Hadoop源代码分析 之hadoop配置及启动(2)—–classpath与启动shell脚本
Hadoop源代码分析 之hadoop配置及启动(1)—–classpath与配置文件
Hadoop源代码分析 之hadoop源代码项目(1)—–创建eclipse下java项目
Hadoop源代码分析 之环境配置(1)—–hadoop虚拟机配置
Hadoop源代码分析 之概念介绍(2)—–初学者眼中的hadoop

