原创文档,转载请将原文url地址标明
hadoop 相关视频下载地址: http://pan.baidu.com/share/link?shareid=223046310&uk=3073578852
Hadoop是现在最流行的一个技术名词, 那么hadoop是什么?它为什么这么流行?它的好处有哪些?
Hadoop是一个程序,是一个分布式的程序框架,是一个并行运行分布式框架,是一个将处理程序分发到数据存储节点上然后进行计算的并行分布式框架。
它是一个框架,就意味着他本身不能直接运行(他提供了一个运行的集群,若集群中没有用户处理程序,基本就处于闲置状态,也可以认为是一个没有运行的状态)。用户必须自己编写程序,然后将程序任务下达给hadoop系统(调度系统),系统会根据用户的要求分发工作任务给不同的计算节点(基本上计算节点同任务节点是自同一台机器上,只有一点点边界数据需要从别的机器上获取等)。
以上仅仅是hadoop的简单描述,那么能不能再通俗一点,在明了一点描述hadoop系统,以及hadoop系统同其他普通程序的区别。
系列文章简介,hadoop代表一种新的编程思想,基于hadoop有很多衍生项目,充分利用他们是非常必要的,同时hadoop又是一个复杂系统,若能理解他的工作原理对我们将有非常大的帮助,我们以hadoop 0.1.0版本为基础逐步分析他的基本工作原理、结构、思路等等,本文是系统文章的一部分,系列文章详情参见
http://www.iigrowing.cn/hadoop_src_introduction
希望通过这个能帮助我们理解生产中hadoop。 时间有限,经验不足,疏漏难免,在这里仅分享一些心得,希望对大家能起到一个抛砖引玉的作用,有问题请大家给我留言或者评论等,这样也能对我的工作有很大帮助。感谢您阅读这篇文章!
为了说明这个问题,我们列举两个例子来类比hadoop系统。
1. 服装加工
我们知道服装加工有很多环节构成
1) 把布料裁剪
2) 将布料加成成服装的各个部分
3) 服装各个部分组装到一起
4) 服装熨烫
5) 服装包装等
我们就简化成如上5个步骤吧
首先我们需要了解一些事情, 服装加工中每个环节现在都有很多设备,这些设备都是要调整好的,一旦调整后就不容易移动,否则还得调整。 因此我们在服装加工过程中,主要采用是 设备及工序在不同车间中进行,设备及车间固定。 我们让物料及被加工品在流动。
有专门工人将物料从一个车间转移到另外一个车间,物料转移完毕,整个加工过程就完成了。
我们通常的程序基本都是这个过程。
我们的程序包括若干个模块, 每个模块就相当于服装加工中的各个环节。 由一个模块打开文件(数据或者数据流),或者接受用户输入,或者从数据库获取数据,这些就相当于物料。
数据(物料)在程序模块中不断流转,当数据从程序中流转完毕后就完成了任务,就有了输出数据(就是服装啦)
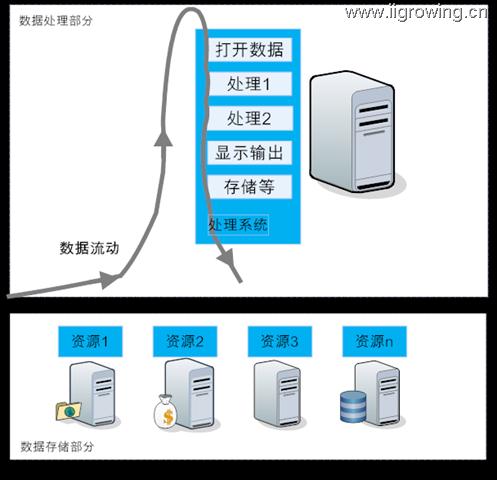
通常程序中数据流动及数据处理的关系图
2. 火车货物检查
假设有这么一个场景,在一个边境口岸,有一列火车等待出国, 但是在出国之前我们需要对火车上货物进行例行海关检查(笔者并没有这方面的经验,仅仅是推测过程)。
那么能否按照前面服装加工的办法,设置一个个环节,然后让货物流转进行检查。
我相信大家心里都明白,不太可能。火车货物都是比较大的,很难能搬移的,就算能搬移,海关那里有那么多地方容纳。就算能容纳,货物搬移过来,然后检查,然后再搬移回去,搬移回去后还得从新打包、码放等等。好像这些是非常不太肯能的事情。
那么可行的做法是什么?
很可能是检查人员到列出上,现场检查,这样成本简单快捷。
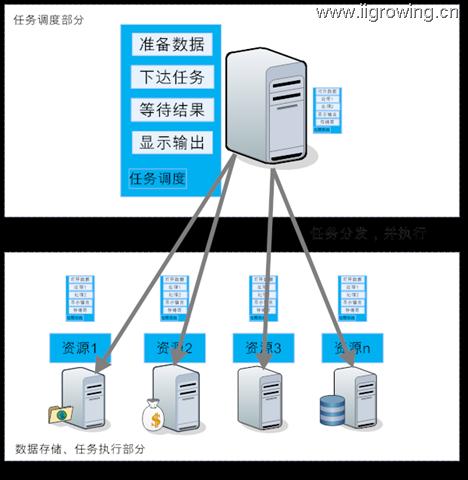
工作任务流转的情况
那么这里这两个例子中的区别是什么?
服装加工中是 工序车间(处理程序)固定, 物料(数据)流转
火车货物检查 工序检查(处理程序)流转 物料被检查货物(数据)固定
什么时候选择物料流转,什么时候选择人员流转。
当物料流转成本 < 人员工序流转成本时 物料流转 我们传统程序基本是这个情况
当物料流转成本 > 人员工序流转成本时 人员流转 hadoop采用的基本办法
总之目的是 尽量减少 系统的总体成本。
总结一句:Hadoop是一个程序,是一个分布式的程序框架,是一个并行运行分布式框架,是一个将处理程序分发到数据存储节点上然后进行计算的并行分布式框架。
后记,后面我们将陆续了解hadoop的一些其他功能等,包括:hadoop的组成模块,hadoop的工作过程等等
参考文章
Hadoop源代码分析 之Datanode工作原理(5)—–拷贝文件过程总结
Hadoop源代码分析 之Datanode工作原理(4)—–拷贝本地文件到hadoop的过程
Hadoop源代码分析 之Datanode工作原理(3)—–datanode工作过程总结
Hadoop源代码分析 之Datanode工作原理(2)—–datanode基本工作过程
Hadoop源代码分析 之Datanode工作原理(1)—–datanode启动过程代码分析
Hadoop源代码分析 之hadoop配置及启动(4)—–启动过程汇总
Hadoop源代码分析 之hadoop配置及启动(3)—–classpath与hadoop主要组件启动过程
Hadoop源代码分析 之hadoop配置及启动(2)—–classpath与启动shell脚本
Hadoop源代码分析 之hadoop配置及启动(1)—–classpath与配置文件
Hadoop源代码分析 之hadoop源代码项目(1)—–创建eclipse下java项目
Hadoop源代码分析 之环境配置(1)—–hadoop虚拟机配置
Hadoop源代码分析 之概念介绍(2)—–初学者眼中的hadoop


