原创文档,转载请将原文url地址标明
hadoop 相关视频下载地址: http://pan.baidu.com/share/link?shareid=223046310&uk=3073578852
本文重点研究hadoop启动过程中主要功能模块同配置文件的作用,具体各个部件启动详细情况,后面会继续介绍。Hadoop是一个分布式的系统(也是分散式,各个组件在正常工作过程中都不在一个服务器上,这样才能发挥它的优点)这样一个分散式系统,如何让系统中各个节点都能协调工作起来?如何传递消息的,如何协调一致的启动的?
要回答或者理解这样一个过程,需要对每个组件启动有个了解,然后理解他们的启动过程,启动过程能协调一致,后续工作才能进行。然后是如何协调地通信,协调的工作。在本文我们先初步了解各个组件是如何启动。稍后我们总结整体启动过程。
系列文章简介,hadoop代表一种新的编程思想,基于hadoop有很多衍生项目,充分利用他们是非常必要的,同时hadoop又是一个复杂系统,若能理解他的工作原理对我们将有非常大的帮助,我们以hadoop 0.1.0版本为基础逐步分析他的基本工作原理、结构、思路等等,本文是系统文章的一部分,系列文章详情参见
http://www.iigrowing.cn/hadoop_src_introduction
希望通过这个能帮助我们理解生产中hadoop。 时间有限,经验不足,疏漏难免,在这里仅分享一些心得,希望对大家能起到一个抛砖引玉的作用,有问题请大家给我留言或者评论等,这样也能对我的工作有很大帮助。感谢您阅读这篇文章!
1 Hadoop几个主要的部件
从hadoop相关脚本可知道,hadoop包括如下几个重要的部件(详情请参见前一篇文章)
if [ "$COMMAND" = "namenode" ] ; then
CLASS='org.apache.hadoop.dfs.NameNode'
Hadoop名称节点,主要负责文件系统管理工作
elif [ "$COMMAND" = "datanode" ] ; then
CLASS='org.apache.hadoop.dfs.DataNode'
Hadoop数据节点, 主要负责hadoop的文件存储工作(分布式存储)
elif [ "$COMMAND" = "dfs" ] ; then
CLASS=org.apache.hadoop.dfs.DFSShell
Hadoop的管理脚本, 管理员通过这个脚本程序,管理hadoop的相关事宜
elif [ "$COMMAND" = "fsck" ] ; then
CLASS=org.apache.hadoop.dfs.DFSck
Hadoop的文件检查, 管理通过这个脚本对文件系统进行相关检查
elif [ "$COMMAND" = "jobtracker" ] ; then
CLASS=org.apache.hadoop.mapred.JobTracker
Hadoop任务管理节点, 负责hadoop相关工作任务的管理调度工作
elif [ "$COMMAND" = "tasktracker" ] ; then
CLASS=org.apache.hadoop.mapred.TaskTracker
Hadoop的任务执行节点,负责hadoop的mapreduce程序的具体执行工作等
elif [ "$COMMAND" = "job" ] ; then
CLASS=org.apache.hadoop.mapred.JobClient
Hadoop的任务客户端,负责同任务管理程序通行等,完成任务的处理等
2 NameNode的启动
Namenode启动过程中,主要包括format分支以及正常工作两个分支,相对比较简单(从运行到调用配置文件),因此我们主要采用静态查看代码方法就可以了,如下(注意红色区域)
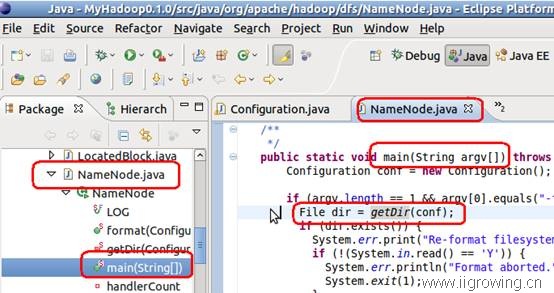
如上图, 在namenode的main函数中, 通过getDir函数获取namenode工作文件夹,而getDir函数定义如下图
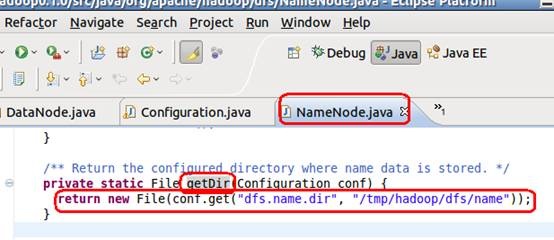
GetDir函数从配置文件中获取用户的相关配置
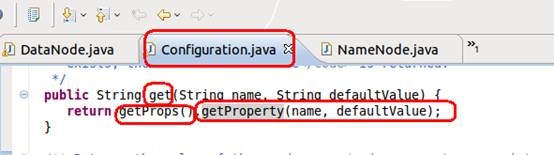
Configuration类根据用户classpath中默认配置的hadoop配置文件中的设置,获取相关属性。因此如上配置文件不在classpath中,则系统会抛出异常,程序退出,启动失败。
Namenode另外一个分支是启动一个namenode节点(上面是一段格式化namenode的代码),这个分支中,main函数调用namenode类的构造函数进行相关操作,如下:
/**
* Create a NameNode at the default location
*/
public NameNode(Configuration conf) throws IOException {
this(getDir(conf),
DataNode.createSocketAddr
(conf.get("fs.default.name", "local")).getPort(), conf);
}
在构造函数中,调用配置文件获取相关属性,然后初始化。
3 DataNode的启动
略,参见第一篇文章,已经包括了演示视频等信息。
4 DFSShell启动
这个过程比较长,采用静态查找的办法找到调用配置文件过程比较长,因此需要采用一点特别的技巧,这里采用动态跟踪的办法。具体是在被认为应该调用配置文件的地方设置断点,然后运行程序(调试模式),程序会在断点处中断运行,这个时候,在通过调试器的堆栈调用次序获取,调用关系。
参考视频
shell-conf_dsfshell-debug-iigrowing.rar5.58M 2012年12月1日 16:39 到期 下载 ,

从上图中,可以知道这个类的功能哈!
主函数中,通过调用FileSystem.parseArgs(….),获取一个文件系统,这个文件系统可以是本地文件系统,也可以是分布式文件系统。具体情况根据配置文件的定义了,在未做任何配置情况,系统将是本地文件系统,供用户调试基本程序,这个接口等同分布式文件系统是相同的。
在程序中正确配置后,返回的是一个本地文件系统,这个文件系统封装了大部分网络操作等,用户仅仅关心或者将文件系统作为本地文件一样看待,简化了编程等。
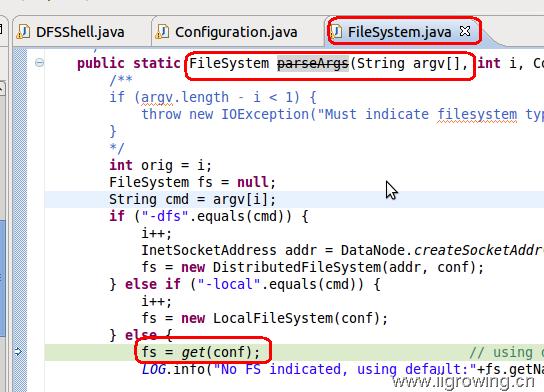
FileSystem的ParseArgs函数中,调用了 get(conf)函数,相关定义如下

在上面定义中,函数首先获取了配置文件相关设置,这个配置是系统根据classpath进行获取的配置文件。
5 DFSck启动
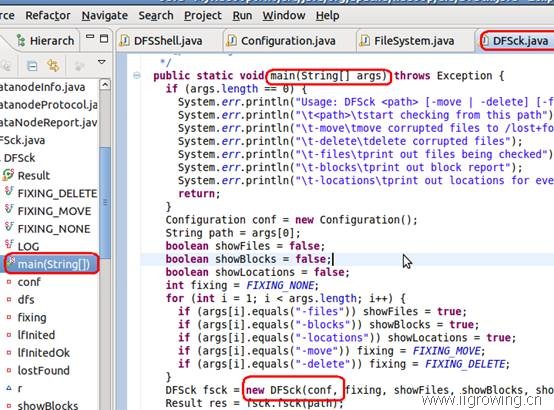
从上图,可以看到DFSck的具体功能了(这里面功能笔者用的不多,因此没多研究,抱歉)
这个类中main函数调用类的构造函数,类构造函数如下图
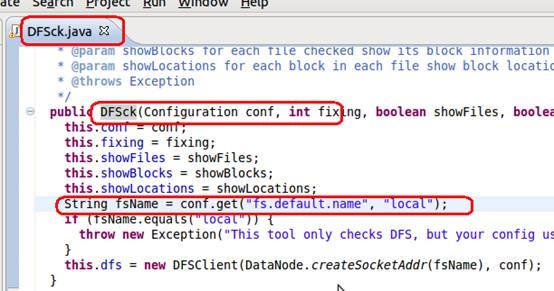
在构造函数中,最终调用配置文件(从classpath中获取配置文件)
6 JobTracker启动
这个类在hadoop中非常重要了,负责正集群的任务调度工作,
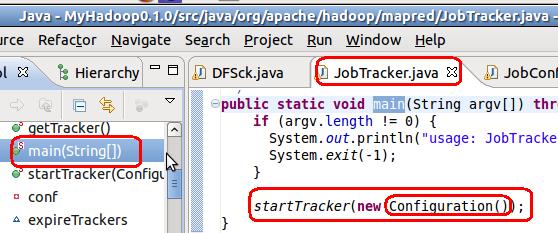
在这个类的main函数中,调用startTracker函数进行相关功能的工作,同时这类参数中,动态创建了一个匿名的configuration类。这类会从系统的classpath中寻找hadoop的配置文件等,然后初始化,若是寻找不到,则抛出异常退出。
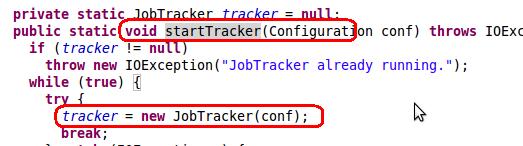
startTracker函数定义如上,函数最后通过调用构造函数,构造函数如下
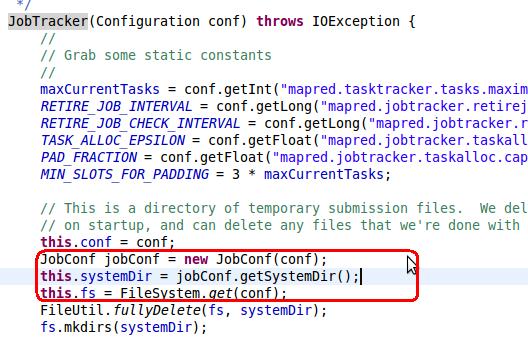
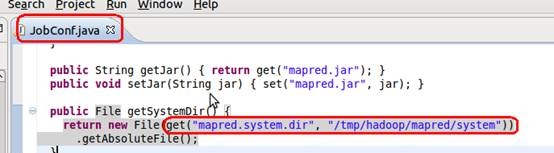
构造函数创建了一个配置文件,这个配置文件继承了configuration类,最后调用configuration的get方法获取配置文件,这个方法需要从系统的classpath中获取配置文件,然后获取参数
7 TaskTracker启动
这类负责hadoop中工作任务的具体执行等工作
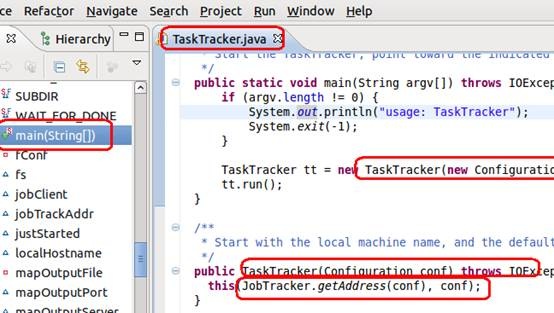
如上图,在main函数中,创建了类的一个实例,实例中调用了 jobTracker的一个方法,方法定义如下:
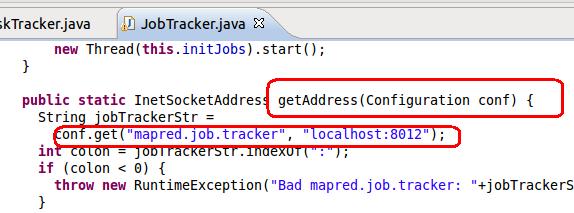
方法中最终需要从classpath中获取相关配置,然后系统能正常的工作
8 JobClient启动
Jobclient是系统任务下达的一个借口,用户(我们)编写的hadoop程序都通过这个接口发布给任务管理程序。
累了,具体代码自己看下面图中 红色部分代码吧!多谢!!
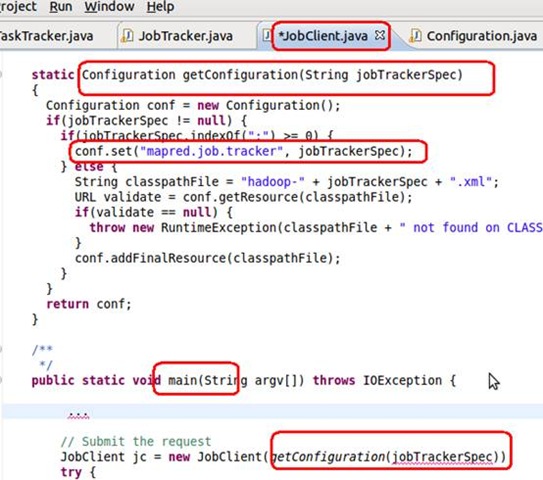
Hadoop是个复杂的应用系统,了解的他的启动过程,是理解他的必备的过程!
参考文章
Hadoop源代码分析 之Datanode工作原理(5)—–拷贝文件过程总结
Hadoop源代码分析 之Datanode工作原理(4)—–拷贝本地文件到hadoop的过程
Hadoop源代码分析 之Datanode工作原理(3)—–datanode工作过程总结
Hadoop源代码分析 之Datanode工作原理(2)—–datanode基本工作过程
Hadoop源代码分析 之Datanode工作原理(1)—–datanode启动过程代码分析
Hadoop源代码分析 之hadoop配置及启动(4)—–启动过程汇总
Hadoop源代码分析 之hadoop配置及启动(3)—–classpath与hadoop主要组件启动过程
Hadoop源代码分析 之hadoop配置及启动(2)—–classpath与启动shell脚本
Hadoop源代码分析 之hadoop配置及启动(1)—–classpath与配置文件
Hadoop源代码分析 之hadoop源代码项目(1)—–创建eclipse下java项目
Hadoop源代码分析 之环境配置(1)—–hadoop虚拟机配置
Hadoop源代码分析 之概念介绍(2)—–初学者眼中的hadoop


