原创文档,转载请将原文url地址标明
引言,hadoop代表一种全新的编程思想,基于hadoop有很多衍生项目,充分利用他们
为我们服务是非常必要的,同时hadoop又是一个复杂系统,若能理解他的工作原理对
我们将有非常大的帮助,我们在这里以hadoop的0.1.0版本为基础逐步分析他的基本工作
原理、结构、思路等等,希望通过这个能帮助我们理解生产中的hadoop系统。 时间有限,
经验不足,疏漏难免,在这里仅仅分享一些心得,希望对大家能起到一个抛砖引玉的作用吧,
有问题请大家给我留言或者评论等,这样也能对我的工作有莫大的帮助。
感谢您阅读这篇文章!
hadoop 相关视频下载地址: http://pan.baidu.com/share/link?shareid=223046310&uk=3073578852
前面几篇文章介绍了hadoop的启动过程,hadoop启动过程中涉及东西比较多,而且又是分布式的系统,启动过程中涉及多台机器的启动等,因此过程较为复杂,本篇文章主要对启动过程作了汇总整理。
一. Hadoop的主从结构
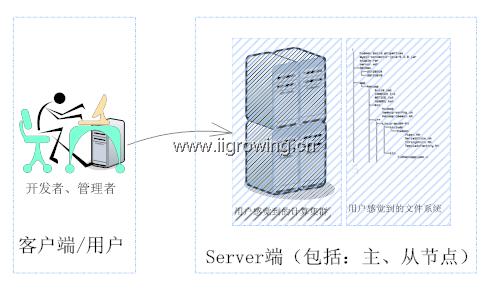
如下图, hadoop系统包括客户端程序,以及server端程序。
客户端程序包括:管理脚本,用户开发的mapreduce程序等。
Server端程序包括:主节点,由名称节点(Namenode),任务管理节点(jobtracter)等组成;server端程序另外一部分是从节点,包括:数据节点(datanode),任务节点(tasktracter)等构成。
整个集群的启动必须在主节点启动,同时主节点可以同时启动相应从节点, 从节点可以启动自己的程序,但是不能启动主节点(具体原因见后面启动的序列图,配置文件等等因素的影响)。
工作中管理员或者用户通过自己的工作机器,通过ssh等登陆主节点,启动整个集群,也可以一个个连接从节点进行相关工作。
二.Hadoop的主从结构与启动关系
Hadoop是一个主从结构的分布式系统, 他的逻辑结构如下图示。
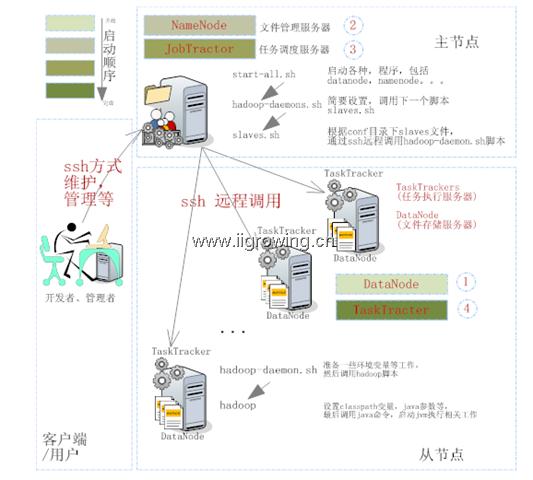
用户通过客户端或者登陆服务器节点,启动服务器。服务器主节点通过ssh方式远程执行从节点上的脚本,从而可以管理从节点,以至于全部集群。
整个启动过程中,首先用户或者管理员首先登陆主节点系统
然后下达${hadoop_home}/bin/start-all.sh命令
脚本首先启动系统中全部的datanode节点,如图中①标记所示;然后启动namenode节点,如图②所示;之后启动jobtracter节点,如图中③所示;最后启动tasktracker节点,如图中④所示。
每个节点上相关工作模块已经表示到了图中,其中各个模块的启动先后顺序根据颜色由浅入深的顺序启动,颜色浅的先启动, 颜色深的后启动。
启动过程中需要调用本机及远程服务器上的不同脚本程序,最后将正确的系统配置文件传递给正在启动中的java进程,从而完成整个集群的启动过程。相对详细的java启动过程需要研究java的源代码,我们前面介绍过一些简单启动主要介绍classpath同启动的关系,大家可以参考。
三.Hadoop个主要部件的启动时间顺序
下图是hadoop各个组件模块在启动过程中时间上调用的次序。由于时间关系我们仅仅分析了启动过程。读者感兴趣可以去分析关闭过程。
图中包括:客户端,用户通过客户端或者自己的电脑登陆到服务器,进行相关的管理等工作。
Server端包括: 主节点,这里的主节点是namendoe及jobtracter都包括在一起的配置方式, 分离的方式不在我们这个系列的讨论范围,读者感兴趣可以研究一下。
从节点, 主要是datanode及tasktracter节点,同样我们这里也是两个节点在同一台机器上。
我们这里以 3个从节点,1个主节点,为例说明启动过程。
整个启动过程,自上而下进行, 在不同服务器上进行不同的工作。
为了方便阅读,我们将整个启动过程划分为4个区域,分别用不同的颜色表示出来。并且每个区域的编号也表示出了启动的顺序。
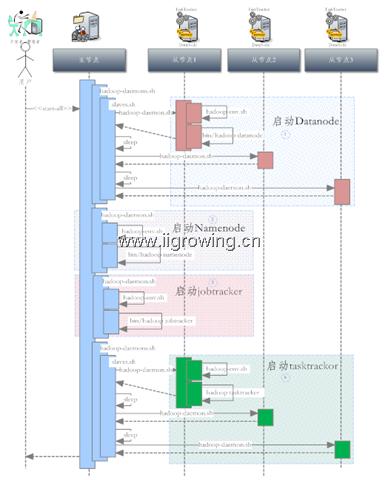
首先用户登录server服务器(主节点后),下达 start-all.sh命令(脚本,在正确的目录中进行)
然后脚本进行相关的启动工作,具体工作过程如下:
1. Datanode启动过程
首先,在主节点上,在start-all.sh脚本中,进行一些列工作后,调用hadoop-daemons.sh这个脚本,这个脚本在进一步调用slaves.sh脚本,这脚本根据slaves文件,循环调用 远程机器(从节点)上的hadoop-daemon.sh脚本,这个脚本根据本地配置等条件(从节点上的相关配置),调用远程(从节点)的hadoop-env.sh脚本等,最后调用远程节点上的hadoop脚本,完成一个从节点的初始化工作。
完成一个从节点初始化后脚本会 sleep一下,然后进行下一个循环。直到全部节点启动完成。然后进行下一个环节的启动。
2. Namenode启动过程
这个启动过程相对简单,是在主节点上进行, 通过调用hadoop-daemon.sh脚本, 这脚本调用主节点的hadoop-env.sh脚本,最后调用hadoop脚本完成启动工作,具体启动调用java的namenode的main函数完成,相对详细的启动过程参加前一篇文章中,有一些介绍。
3. Jobtracter启动过程
这启动过程,同上面Namenode过程类似,只是最后调用的java的main函数类不同,配置文件中的参数不同,从脚本及时间层面没有新东西同namenode的启动过程。
4. Tasktracter启动过程
这个启动过程同上面的datanode启动过程非常相似,仅仅是最后调用的java的main函数类不同,传递参数不同。
后记,学习是一个过程,是一个体验,是一个经历,是一种财富。我们这里没有更多的文字描述以上启动过程,主要都是图示方式,需要大家慢慢体会图形中传递出的一些信息。你经历了,你体验了,你就收获了;而不是你阅读了,你就收获啦(收获的会比较少)。
参考文章
参考文章
Hadoop源代码分析 之Datanode工作原理(5)—–拷贝文件过程总结
Hadoop源代码分析 之Datanode工作原理(4)—–拷贝本地文件到hadoop的过程
Hadoop源代码分析 之Datanode工作原理(3)—–datanode工作过程总结
Hadoop源代码分析 之Datanode工作原理(2)—–datanode基本工作过程
Hadoop源代码分析 之Datanode工作原理(1)—–datanode启动过程代码分析
Hadoop源代码分析 之hadoop配置及启动(4)—–启动过程汇总
Hadoop源代码分析 之hadoop配置及启动(3)—–classpath与hadoop主要组件启动过程
Hadoop源代码分析 之hadoop配置及启动(2)—–classpath与启动shell脚本
Hadoop源代码分析 之hadoop配置及启动(1)—–classpath与配置文件
Hadoop源代码分析 之hadoop源代码项目(1)—–创建eclipse下java项目
Hadoop源代码分析 之环境配置(1)—–hadoop虚拟机配置
Hadoop源代码分析 之概念介绍(2)—–初学者眼中的hadoop

