原创文章,转载请指明出处并保留原文url地址
hadoop是基于java平台的,他有自己的启动及管理脚本,他的启动脚本是如何工作,他的程序是如何启动的,启动过程中配置文件如何传递的,他同普通java项目的区别在那里,为什么我们必须用hadoop脚本来启动hadoop系统以及运行我们自定义的程序。从本文开始,我们将正式进入hadoop源代码中,本文重点阐述hadoop启动过程中配置文件的加载,希望通过文章来解答上面的问题。
本文是对分析过程的一个描述,文章后面还会有两个视频文件, 分别是代码静态分析以及动态分析过程,大家根据习惯参考阅读。
系列文章简介,hadoop代表一种新的编程思想,基于hadoop有很多衍生项目,充分利用他们是非常必要的,同时hadoop又是一个复杂系统,若能理解他的工作原理对我们将有非常大的帮助,我们以hadoop 0.1.0版本为基础逐步分析他的基本工作原理、结构、思路等等,本文是系统文章的一部分,系列文章详情参见
http://www.iigrowing.cn/hadoop_src_introduction
希望通过这个能帮助我们理解生产中hadoop。 时间有限,经验不足,疏漏难免,在这里仅分享一些心得,希望对大家能起到一个抛砖引玉的作用,有问题请大家给我留言或者评论等,这样也能对我的工作有很大帮助。感谢您阅读这篇文章!
一.Hadoop文件组成
Hadoop程序解压缩完成后源代码如下图
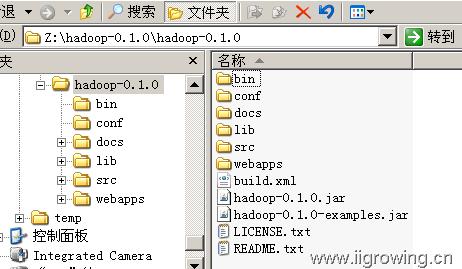
Bin目录,hadoop脚本,管理及维护hadoop系统,
Conf目录,hadoop配置文件,hadoop系统相关信息等,
Docs目录,文档目录
Lib目录,hadoop依赖的相关jar文件
Src目录,hadoop源代码文件
Webapps目录, hadoop内嵌的webserver的j2ee程序目录
相关文件:
Build.xml文件时hadoop的ant编译配置文件
其他文件略
二.Hadoop基本启动过程
假设hadoop程序安装主目录用${hadoop_home}表示
管理人员可以执行${hadoop_home}\bin\start-all.sh文件启动hadoop系统
这个脚本将根据conf目录中相关配置文件,启动datanode,namenode,tasktracter,jobtracter等程序
Hadoop的几个主要配置文件如下:
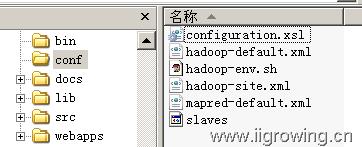
那么脚本在启动hadoop程序中,配置文件信息如何传递给java程序,java程序是如何加载的?
本文将以datanode启动过程为例分析hadoop的配置文件传递,然后后续将逐步分析其他启动程序的配置文件的启动情况。
三.程序员角度看待hadoop启动
我们打开hadoop的源代码项目(eclipse的java项目)
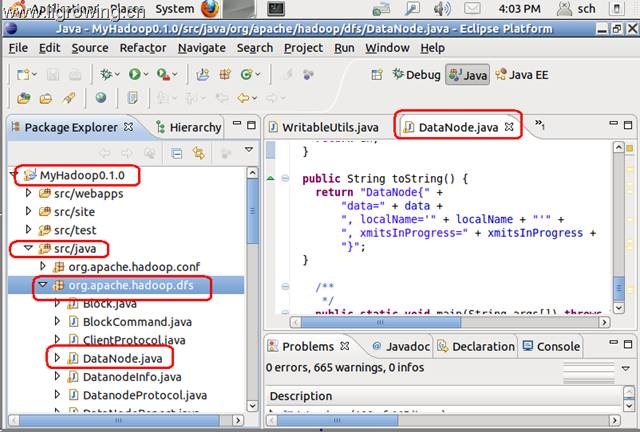
如下图,我们打开如上目录及java源代码文件
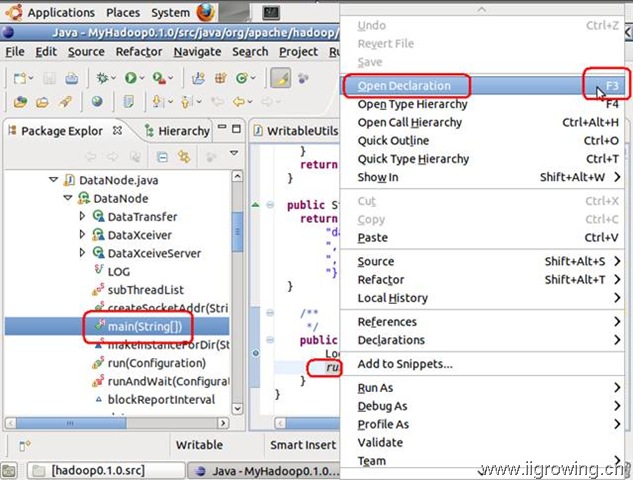
双击左侧 main函数的节点, 然后右面显示相关源代码, 然后在
“runAndWait(new Configuration());”函数调用处,右击鼠标,弹出相关对话框,选择“open Declaration” 选项, 可以直接使用快捷方式 F3按键,可以快速到达相关源代码处
代码如下:
private static void runAndWait(Configuration conf) throws IOException {
run(conf); // 调用run函数,进行相关业务逻辑(注意这里的参数对象 conf是在哪里创建的????? 这个非常重要,呕!!!)
// Wait for sub threads to exit 等等线程 退出
for (Iterator iterator = subThreadList.iterator(); iterator.hasNext();) {
Thread threadDataNode = (Thread) iterator.next();
try {
threadDataNode.join();
} catch (InterruptedException e) {
if (Thread.currentThread().isInterrupted()) {
// did someone knock?
return;
}
}
}
}
下面我们看一下配置文件是在哪里创建,我们可以回顾一下main函数,如下图
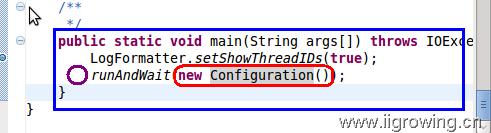
看红色区域,代码,这个代码创建一个匿名的 配置对象,这个配置对象,采用默认的构造函数。
配置类的构造函数如下
/** A new configuration. */
public Configuration() {
defaultResources.add("hadoop-default.xml"); // 添加配置文件,最大问题,这里仅仅有文件名,没有文件路径,系统到哪里去找文件?
finalResources.add("hadoop-site.xml"); // 添加配置文件,同上面有相同问题
}
稍后我们在解释。。。
下面我们看一下run函数(这里run函数同java线程里面的run函数不是同一个类型的,仅仅是名称相同)
/** Start datanode daemons.
* Start a datanode daemon for each comma separated data directory
* specified in property dfs.data.dir
*/
public static void run(Configuration conf) throws IOException {
String[] dataDirs = conf.getStrings("dfs.data.dir"); // 这里面就调用了我们今天需要重点解决的问题,这里调用配置,配置从哪里来的。 Conf对象在哪里来的
下面代码不再今天解释之列,今天可以忽略!!!
subThreadList = new Vector(dataDirs.length);
for (int i = 0; i < dataDirs.length; i++) {
DataNode dn = makeInstanceForDir(dataDirs[i], conf);
if (dn != null) {
Thread t = new Thread(dn, "DataNode: "+dataDirs[i]);
t.setDaemon(true); // needed for JUnit testing
t.start();
subThreadList.add(t);
}
}
}
本函数中重点是: String[] dataDirs = conf.getStrings("dfs.data.dir"); 这行语句的相关情况,直接关联hadoop启动过程中,配置文件的相关获取方法。并且这个过程在整个hadoop中都是类似的,仅仅是获取的配置信息不同而已,但是过程,方法都是非常相似的。
上面函数将调用下面的函数,如下
/** Returns the value of the <code>name</code> property as an array of
* strings. If no such property is specified, then <code>null</code>
* is returned. Values are whitespace or comma delimted.
*/
public String[] getStrings(String name) {
String valueString = get(name); // 重点语句,负责初始化相关代码,我们需要跟踪进入相关代码
if (valueString == null)
return null;
StringTokenizer tokenizer = new StringTokenizer (valueString,", \t\n\r\f");
List values = new ArrayList();
while (tokenizer.hasMoreTokens()) {
values.add(tokenizer.nextToken());
}
return (String[])values.toArray(new String[values.size()]);
}
相关函数代码如下:
/** Returns the value of the <code>name</code> property, or null if no
* such property exists. */
public String get(String name) { return getProps().getProperty(name);}
如下图中用特别颜色标注的代码。

getProps()这是个函数调用,函数调用后会返回一个对象。
getProps().getProperty(name);,根据前一个函数返回的对象,然后调用哪个对象的一个函数
下面是getProps函数的代码
private synchronized Properties getProps() {
if (properties == null) { // 请特别注意这里面的代码,当系统构造配置对象后,这个对象默认是null值的,因此将执行下面代码块中语句的
Properties newProps = new Properties(); // 创建一个资源
loadResources(newProps, defaultResources, false, false); // 装载一个资源,本函数中关键代码!!!!
loadResources(newProps, finalResources, true, true);
properties = newProps;
}
return properties;
}
下面是 配置类中properties 的定义,如下:
private Properties properties; // java中对象默认没有new时 是null的。
装载资源文件函数如下
private void loadResources(Properties props,
ArrayList resources,
boolean reverse, boolean quiet) {
ListIterator i = resources.listIterator(reverse ? resources.size() : 0);
while (reverse ? i.hasPrevious() : i.hasNext()) {
loadResource(props, reverse ? i.previous() : i.next(), quiet); // 循环装入配置文件中的配置,将配置信息存入Properties props中,返回给上层函数。(小问题:java参数一般都是传递值的, 为什么能返回数据给上层???)
}
}
具体装载资源函数如下
private void loadResource(Properties properties, Object name, boolean quiet) {
try {
DocumentBuilder builder =
DocumentBuilderFactory.newInstance().newDocumentBuilder();
Document doc = null;
// 我们目前的程序默认进入的,是走第一个if分支,即name是string类型的,相关情况可以在动态分析中获取到
if (name instanceof String) { // a CLASSPATH resource
URL url = getResource((String)name); // 从classpath路径中加载一个命名的资源,一般为文件等
if (url != null) {
LOG.info("parsing " + url);
doc = builder.parse(url.toString()); // 解析这个文件
}
} else if (name instanceof File) { // a file resource
File file = (File)name;
if (file.exists()) {
LOG.info("parsing " + file);
doc = builder.parse(file);
}
}
if (doc == null) {
if (quiet)
return;
throw new RuntimeException(name + " not found");
}
// 获取相关配置信息,本是系列文章重点,我们重点研究程序运行脉络,细节都可以忽略!!!!
Element root = doc.getDocumentElement();
if (!"configuration".equals(root.getTagName()))
LOG.severe("bad conf file: top-level element not <configuration>");
NodeList props = root.getChildNodes();
for (int i = 0; i < props.getLength(); i++) {
Node propNode = props.item(i);
if (!(propNode instanceof Element))
continue;
Element prop = (Element)propNode;
if (!"property".equals(prop.getTagName()))
LOG.warning("bad conf file: element not <property>");
NodeList fields = prop.getChildNodes();
String attr = null;
String value = null;
for (int j = 0; j < fields.getLength(); j++) {
Node fieldNode = fields.item(j);
if (!(fieldNode instanceof Element))
continue;
Element field = (Element)fieldNode;
if ("name".equals(field.getTagName()))
attr = ((Text)field.getFirstChild()).getData();
if ("value".equals(field.getTagName()) && field.hasChildNodes())
value = ((Text)field.getFirstChild()).getData();
}
if (attr != null && value != null)
properties.setProperty(attr, value);
}
} catch (Exception e) {
LOG.severe("error parsing conf file: " + e);
throw new RuntimeException(e);
}
}
这个类是上面调用的 加载资源的实现方法
/** Returns the URL for the named resource. */
public URL getResource(String name) {
return classLoader.getResource(name);
}
好了,我们已经基本分析完成启动的基本过程, 万里长征我们终于走出第一步,胜利就在我们脚下。
神秘面纱终于揭开一角,一切即将在眼前展现!!!!!

hadoop-启动-配置文件classpath-静态分析_x264.rar (17.63M, 2012年11月30日 09:56 到期)
hadoop-启动-配置文件classpath-动态分析_x264.rar (39.41M, 2012年11月30日 09:56 到期)
参考文章
Hadoop源代码分析 之Datanode工作原理(5)—–拷贝文件过程总结
Hadoop源代码分析 之Datanode工作原理(4)—–拷贝本地文件到hadoop的过程
Hadoop源代码分析 之Datanode工作原理(3)—–datanode工作过程总结
Hadoop源代码分析 之Datanode工作原理(2)—–datanode基本工作过程
Hadoop源代码分析 之Datanode工作原理(1)—–datanode启动过程代码分析
Hadoop源代码分析 之hadoop配置及启动(4)—–启动过程汇总
Hadoop源代码分析 之hadoop配置及启动(3)—–classpath与hadoop主要组件启动过程
Hadoop源代码分析 之hadoop配置及启动(2)—–classpath与启动shell脚本
Hadoop源代码分析 之hadoop配置及启动(1)—–classpath与配置文件
Hadoop源代码分析 之hadoop源代码项目(1)—–创建eclipse下java项目
Hadoop源代码分析 之环境配置(1)—–hadoop虚拟机配置
Hadoop源代码分析 之概念介绍(2)—–初学者眼中的hadoop
Hadoop源代码分析 之概念介绍(1)—–服装加工,火车货物检查与hadoop
hadoop 相关视频下载地址: http://pan.baidu.com/share/link?shareid=223046310&uk=3073578852




