原创文章,转载请指明出处并保留原文url地址
hadoop 相关视频下载地址: http://pan.baidu.com/share/link?shareid=223046310&uk=3073578852
hadoop服务器启动,管理命令,启动任务等都由脚本执行,那么hadoop脚本的启动过程是什么,是不是在任何hadoop节点上执行所有的hadoop命令都可以?为什么?本文我们将一起研究hadoop的启动脚本,理解hadoop的启动脚本最后这些问题基本就可以自己回答了。本文是hadoop系列文章之一,系列文章相关信息如下:
系列文章简介,hadoop代表一种新的编程思想,基于hadoop有很多衍生项目,充分利用他们是非常必要的,同时hadoop又是一个复杂系统,若能理解他的工作原理对我们将有非常大的帮助,我们以hadoop 0.1.0版本为基础逐步分析他的基本工作原理、结构、思路等等,本文是系统文章的一部分,系列文章详情参见
一.hadoop脚本文件功能简介
Hadoop系统启动脚本在 hadoop的安装目录的bin下,如下图
脚本文件如下
Hadoop,hadoop的实际执行脚本,主要功能都在这个脚本中,很多脚本最终都要调用这个脚本执行相关功能
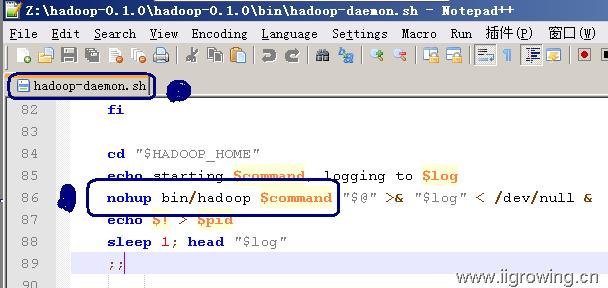
hadoop-daemon.sh,hadoop后台进程脚本,但最终实际功能的脚本还是调用hadoop脚本进行,如下图
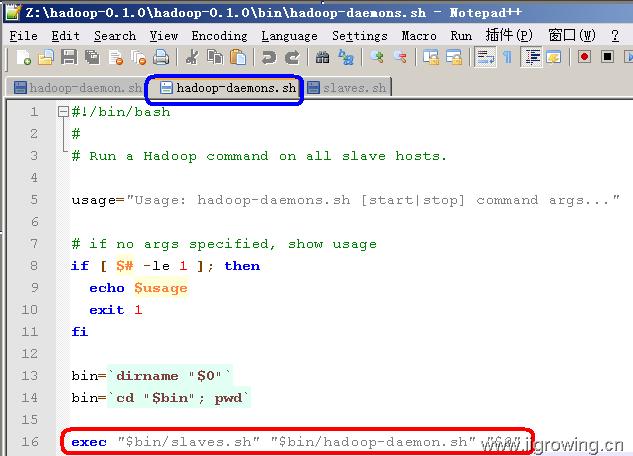
hadoop-daemons.sh, hadoop的脚本执行,最终通过slaves.sh 调用远程服务器上的相应脚本
slaves.sh,hadoop相关服务器节点调用的脚本
start-all.sh, hadoop启动脚本
stop-all.sh, hadoop停止脚本
二.Hadoop启动脚本分析----------调用顺序分析
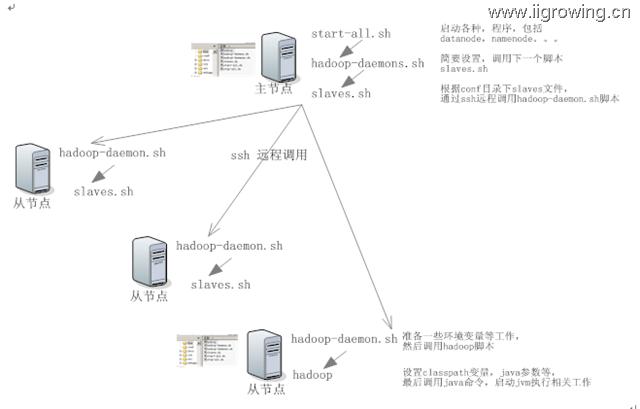
图中,箭头方向就是调用方向及调用顺序, 在跨机器调用时,采用了另一种箭头表示,注意区别。
三.Hadoop脚本简要分析
Hadoop的启动脚本,首先是start-all.sh,我们先来分析这个脚本
1. start-all.sh
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> start-all.sh 开始
#!/bin/bash
# Start all hadoop daemons. Run this on master node.
bin=`dirname "$0"` // 执行 将当前命令行参数(参数0是整个命令行参数)做为参数执行dirname命令, 获取脚本目录, 数据最后保存在bin变量中
bin=`cd "$bin"; pwd` // 进入脚本所在目录,并显示当前目录,将当前目录路径存储在bin变量中(本脚本才有效果的局部变量)
# start dfs daemons
# start namenode after datanodes, to minimize time namenode is up w/o data
# note: datanodes will log connection errors until namenode starts
"$bin"/hadoop-daemons.sh start datanode // 调用bin目录下的脚本,启动全部集群的 数据节点, 从这个脚本可以看到, hadoop启动时先启动的是 数据节点,这个最先启动,稍后我们也将最先分析这个代码,然后一步步分析别的代码模块。
"$bin"/hadoop-daemon.sh start namenode // 启动 hadoop的 名称节点
# start mapred daemons
# start jobtracker first to minimize connection errors at startup
"$bin"/hadoop-daemon.sh start jobtracker // 启动工作任务调度节点,这两个任务我们最后分析
"$bin"/hadoop-daemons.sh start tasktracker // 启动工作任务执行节点
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< start-all.sh 结束
2. hadoop-daemons.sh脚本代码如下(注意这里面的s)
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> hadoop-daemons.sh 开始
#!/bin/bash
#
# Run a Hadoop command on all slave hosts. 在全部的hadoop从节点上运行hadoop命令
usage="Usage: hadoop-daemons.sh [start|stop] command args..." // 声明一个变量,存储使用提示信息
# if no args specified, show usage
if [ $# -le 1 ]; then // 检查参数,若是参数数量小1,显示使用方法退出
echo $usage
exit 1
fi
bin=`dirname "$0"` // 取得当前hadoop的配置目录,并进入,但是当shell程序退出后,恢复到原目录
bin=`cd "$bin"; pwd`
exec "$bin/slaves.sh" "$bin/hadoop-daemon.sh" "$@" // 将"$bin/hadoop-daemon.sh" "$@"部分作为参数传递给新的shell 程序“$bin/slaves.sh”,这些程序是在当前shell进程中进行的
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< hadoop-daemons.sh 结束
3.slaves.sh脚本分析
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> slaves.sh 开始
#!/bin/bash
#
# Run a shell command on all slave hosts.
#
# Environment Variables
#
# HADOOP_SLAVES File naming remote hosts. Default is ~/.slaves
# HADOOP_CONF_DIR Alternate conf dir. Default is ${HADOOP_HOME}/conf.
# HADOOP_SLAVE_SLEEP Seconds to sleep between spawning remote commands.
##
usage="Usage: slaves.sh command..." // 添加使用说明
# if no args specified, show usage // 检查参数格式及使用方法
if [ $# -le 0 ]; then
echo $usage
exit 1
fi
# resolve links - $0 may be a softlink // 解决软连接的问题
this="$0"
while [ -h "$this" ]; do
ls=`ls -ld "$this"`
link=`expr "$ls" : '.*-> \(.*\)$'`
if expr "$link" : '.*/.*' > /dev/null; then
this="$link"
else
this=`dirname "$this"`/"$link"
fi
done
# the root of the Hadoop installation
HADOOP_HOME=`dirname "$this"`/.. // 设置hadoop_home的环境变量
# Allow alternate conf dir location. // hadoop配置的位置
HADOOP_CONF_DIR="${HADOOP_CONF_DIR:=$HADOOP_HOME/conf}"
if [ -f "${HADOOP_CONF_DIR}/hadoop-env.sh" ]; then
source "${HADOOP_CONF_DIR}/hadoop-env.sh" // 执行 环境脚本,主要是一些设置,例如java设置等,本文末尾注释中包括了,这个脚本,详情参见文档末尾
脚本执行后JAVA_HOME环境变量就在这里生效,HADOOP_LOG_DIR等可选定义的环境变量也会生效,只要定义啦
fi
if [ "$HADOOP_SLAVES" = "" ]; then
export HADOOP_SLAVES="${HADOOP_CONF_DIR}/slaves" // 输出hadoop从节点等配置
fi
# By default, forward HADOOP_CONF_DIR environment variable to the
# remote slave. Remote slave must have following added to its
# /etc/ssh/sshd_config:
# AcceptEnv HADOOP_CONF_DIR
# See'man ssh_config for more on SendEnv and AcceptEnv.
if [ "$HADOOP_SSH_OPTS" = "" ]; then
export HADOOP_SSH_OPTS="-o ConnectTimeout=1 -o SendEnv=HADOOP_CONF_DIR"
fi
for slave in `cat "$HADOOP_SLAVES"`; do
ssh $HADOOP_SSH_OPTS $slave $"${@// /\\ }" \ // 通过ssh远程执行调用这个脚本传入的程序,如“exec "$bin/slaves.sh" "$bin/hadoop-daemon.sh" "$@"”中,“"$bin/hadoop-daemon.sh" "$@"”部分
2>&1 | sed "s/^/$slave: /" &
if [ "$HADOOP_SLAVE_SLEEP" != "" ]; then
sleep $HADOOP_SLAVE_SLEEP
fi
done
wait
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< slaves.sh 结束
4. hadoop-daemon.sh脚本工作情况,注意这里面没有(s,请注意同前面带s的脚本的差异)
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> hadoop-daemon.sh 开始
#!/bin/bash
#
# Runs a Hadoop command as a daemon.
#
# Environment Variables
#
# HADOOP_CONF_DIR Alternate conf dir. Default is ${HADOOP_HOME}/conf.
# HADOOP_LOG_DIR Where log files are stored. PWD by default.
# HADOOP_MASTER host:path where hadoop code should be rsync'd from
# HADOOP_PID_DIR The pid files are stored. /tmp by default.
# HADOOP_IDENT_STRING A string representing this instance of hadoop. $USER by default
##
usage="Usage: hadoop-daemon [start|stop] [hadoop-command] [args...]"
# if no args specified, show usage
if [ $# -le 1 ]; then
echo $usage
exit 1
fi
# get arguments // 通过移动参数办法获取 命令等参数
startStop=$1
shift
command=$1
shift
# resolve links - $0 may be a softlink
this="$0"
while [ -h "$this" ]; do
ls=`ls -ld "$this"`
link=`expr "$ls" : '.*-> \(.*\)$'`
if expr "$link" : '.*/.*' > /dev/null; then
this="$link"
else
this=`dirname "$this"`/"$link"
fi
done
# the root of the Hadoop installation
HADOOP_HOME=`dirname "$this"`/.. // 获取hadoop目录
# Allow alternate conf dir location.
HADOOP_CONF_DIR="${HADOOP_CONF_DIR:-$HADOOP_HOME/conf}"
if [ -f "${HADOOP_CONF_DIR}/hadoop-env.sh" ]; then
source "${HADOOP_CONF_DIR}/hadoop-env.sh" // 执行配置文件
fi
# get log directory
if [ "$HADOOP_LOG_DIR" = "" ]; then
HADOOP_LOG_DIR="$HADOOP_HOME/logs"
mkdir -p "$HADOOP_LOG_DIR"
fi
if [ "$HADOOP_PID_DIR" = "" ]; then
HADOOP_PID_DIR=/tmp
fi
if [ "$HADOOP_IDENT_STRING" = "" ]; then
HADOOP_IDENT_STRING=$USER
fi
# some variables
log=$HADOOP_LOG_DIR/hadoop-$HADOOP_IDENT_STRING-$command-`hostname`.log
pid=$HADOOP_PID_DIR/hadoop-$HADOOP_IDENT_STRING-$command.pid
case $startStop in
(start)
if [ -f $pid ]; then
if [ -a /proc/`cat $pid` ]; then
echo $command running as process `cat $pid`. Stop it first.
exit 1
fi
fi
if [ "$HADOOP_MASTER" != "" ]; then
echo rsync from $HADOOP_MASTER
rsync -a -e ssh --delete --exclude=.svn $HADOOP_MASTER/ "$HADOOP_HOME"
fi
cd "$HADOOP_HOME"
echo starting $command, logging to $log
nohup bin/hadoop $command "$@" >& "$log" < /dev/null & // 具体执行相关程序功能,通过调用 hadoop脚本的方式
echo $! > $pid
sleep 1; head "$log"
;;
(stop) // 这个分支同上类似
if [ -f $pid ]; then
if [ -a /proc/`cat $pid` ]; then
echo stopping $command
kill `cat $pid`
else
echo no $command to stop
fi
else
echo no $command to stop
fi
;;
(*)
echo $usage
exit 1
;;
esac
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< hadoop-daemon.sh 结束
5. hadoop 脚本工作过程分析,这个脚本是大部分hadoop脚本最终需要调用的,因此是我们重点分析的一个脚本
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> hadoop 开始
#!/bin/bash
#
# The Hadoop command script
#
# Environment Variables
#
# JAVA_HOME The java implementation to use. Overrides JAVA_HOME.
#
# HADOOP_HEAPSIZE The maximum amount of heap to use, in MB.
# Default is 1000.
#
# HADOOP_OPTS Extra Java runtime options.
#
# HADOOP_CONF_DIR Alternate conf dir. Default is ${HADOOP_HOME}/conf.
#
# resolve links - $0 may be a softlink
THIS="$0"
while [ -h "$THIS" ]; do
ls=`ls -ld "$THIS"`
link=`expr "$ls" : '.*-> \(.*\)$'`
if expr "$link" : '.*/.*' > /dev/null; then
THIS="$link"
else
THIS=`dirname "$THIS"`/"$link"
fi
done
# if no args specified, show usage
if [ $# = 0 ]; then // 在没有参数时,显示相关提示信息
echo "Usage: hadoop COMMAND"
echo "where COMMAND is one of:"
echo " namenode -format format the DFS filesystem"
echo " namenode run the DFS namenode"
echo " datanode run a DFS datanode"
echo " dfs run a DFS admin client"
echo " fsck run a DFS filesystem checking utility"
echo " jobtracker run the MapReduce job Tracker node"
echo " tasktracker run a MapReduce task Tracker node"
echo " job manipulate MapReduce jobs"
echo " jar <jar> run a jar file"
echo " or"
echo " CLASSNAME run the class named CLASSNAME"
echo "Most commands print help when invoked w/o parameters."
exit 1
fi
# get arguments
COMMAND=$1
shift
# some directories
THIS_DIR=`dirname "$THIS"`
HADOOP_HOME=`cd "$THIS_DIR/.." ; pwd` // 取得hadoop的home目录
# Allow alternate conf dir location.
HADOOP_CONF_DIR="${HADOOP_CONF_DIR:-$HADOOP_HOME/conf}"
// 取得hadoop配置文件的目录
if [ -f "${HADOOP_CONF_DIR}/hadoop-env.sh" ]; then
source "${HADOOP_CONF_DIR}/hadoop-env.sh" // 执行配置文件中的环境变量等
fi
# some Java parameters
if [ "$JAVA_HOME" != "" ]; then // 设置java home变量,非常重要,主要在上面的 env.sh脚本中执行的
#echo "run java in $JAVA_HOME"
JAVA_HOME=$JAVA_HOME
fi
if [ "$JAVA_HOME" = "" ]; then
echo "Error: JAVA_HOME is not set."
exit 1
fi
JAVA=$JAVA_HOME/bin/java // 设置局部变量,java命令的变量
JAVA_HEAP_MAX=-Xmx1000m // java的内存参数等
# check envvars which might override default args
if [ "$HADOOP_HEAPSIZE" != "" ]; then
#echo "run with heapsize $HADOOP_HEAPSIZE"
JAVA_HEAP_MAX="-Xmx""$HADOOP_HEAPSIZE""m"
#echo $JAVA_HEAP_MAX
fi
//////// 请万分注意了,下面这些代码是本文重点中的重点了,务必仔细观看!!!
# CLASSPATH initially contains $HADOOP_CONF_DIR
CLASSPATH="${HADOOP_CONF_DIR}" // 这一句代码非常重要, 设置了hadoop的配置文件目录为classpath中的一个条目,并且最优先,一般java在classpath加载资源时都是按照classpath中出现顺序来优先获取的。 Hadoop中配置文件就是在classpath中加载的资源,这个也就解释了,为什么没有正确配置classpath时,eclipse的hadoop项目没办法启动。就是因为在classpath中找不到 配置用的 *.xml文件。
Hadoop脚本为了避免这个情况,在设置classpath时,最先设置了这个配置目录到classpath中,并且放到最前面拉,优先搜索
CLASSPATH=${CLASSPATH}:$JAVA_HOME/lib/tools.jar
# for developers, add Hadoop classes to CLASSPATH
if [ -d "$HADOOP_HOME/build/classes" ]; then
CLASSPATH=${CLASSPATH}:$HADOOP_HOME/build/classes
fi
if [ -d "$HADOOP_HOME/build/webapps" ]; then
CLASSPATH=${CLASSPATH}:$HADOOP_HOME/build
fi
if [ -d "$HADOOP_HOME/build/test/classes" ]; then
CLASSPATH=${CLASSPATH}:$HADOOP_HOME/build/test/classes
fi
# so that filenames w/ spaces are handled correctly in loops below
IFS=
# for releases, add hadoop jars & webapps to CLASSPATH
if [ -d "$HADOOP_HOME/webapps" ]; then
CLASSPATH=${CLASSPATH}:$HADOOP_HOME
fi
for f in $HADOOP_HOME/hadoop-*.jar; do
CLASSPATH=${CLASSPATH}:$f;
done
# add libs to CLASSPATH
for f in $HADOOP_HOME/lib/*.jar; do
CLASSPATH=${CLASSPATH}:$f;
done
for f in $HADOOP_HOME/lib/jetty-ext/*.jar; do
CLASSPATH=${CLASSPATH}:$f;
done
# restore ordinary behaviour
unset IFS
////// 下面的代码我们可以看到,启动不同任务时,调用哪个java的类等,请大家仔细看啦
# figure out which class to run
if [ "$COMMAND" = "namenode" ] ; then
CLASS='org.apache.hadoop.dfs.NameNode' // namenode的节点主类,大家都应该内能看董吧!!!!
elif [ "$COMMAND" = "datanode" ] ; then
CLASS='org.apache.hadoop.dfs.DataNode'
elif [ "$COMMAND" = "dfs" ] ; then
CLASS=org.apache.hadoop.dfs.DFSShell
elif [ "$COMMAND" = "fsck" ] ; then
CLASS=org.apache.hadoop.dfs.DFSck
elif [ "$COMMAND" = "jobtracker" ] ; then
CLASS=org.apache.hadoop.mapred.JobTracker
elif [ "$COMMAND" = "tasktracker" ] ; then
CLASS=org.apache.hadoop.mapred.TaskTracker
elif [ "$COMMAND" = "job" ] ; then
CLASS=org.apache.hadoop.mapred.JobClient
elif [ "$COMMAND" = "jar" ] ; then
JAR="$1"
shift
CLASS=`"$0" org.apache.hadoop.util.PrintJarMainClass "$JAR"`
if [ $? != 0 ]; then
echo "Error: Could not find main class in jar file $JAR"
exit 1
fi
CLASSPATH=${CLASSPATH}:${JAR}
else
CLASS=$COMMAND
fi
# cygwin path translation
if expr `uname` : 'CYGWIN*' > /dev/null; then
CLASSPATH=`cygpath -p -w "$CLASSPATH"`
fi
# run it // 到了这里,应该问题都解决啦!!! 配置,命令,参数都已经有了,现在就是 用java执行它啦,剩下我们去java项目中一个个去观察相关影响了。
exec "$JAVA" $JAVA_HEAP_MAX $HADOOP_OPTS -classpath "$CLASSPATH" $CLASS "$@"
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< hadoop 结束
附加一些linux脚本的命令解释!
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> dirname
Linux命令之dirname - 截取给定路径的目录部分
用途说明
dirname命令可以取给定路径的目录部分(strip non-directory suffix from file name)。这个命令很少直接在shell命令行中使用,我一般把它用在shell脚本中,用于取得脚本文件所在目录,然后将当前目录切换过去。根据手册 页上说的“Print NAME with its trailing /component removed; if NAME contains no /’s, output ‘.’ (meaning the current directory).”,似乎说“取给定路径的目录部分” 并不能很准确的概括dirname命令的用途。Linux下还有一个命令是basename,它与dirname相反,是取得文件名称部分。
使用示例
示例一 来自手册页的例子
[root@qzt196 ~]# dirname /usr/bin/sort
/usr/bin
[root@qzt196 ~]# dirname stdio.h
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< dirname
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> exec
shell的内建命令exec将并不启动新的shell,而是用要被执行命令替换当前的shell进程,并且将老进程的环境清理掉,而且exec命令后的其它命令将不再执行。
因此,如果你在一个shell里面,执行exec ls那么,当列出了当前目录后,这个shell就自己退出了,因为这个shell进程已被替换为仅仅执行ls命令的一个进程,执行结束自然也就退出了。为 了避免这个影响我们的使用,一般将exec命令放到一个shell脚本里面,用主脚本调用这个脚本,调用点处可以用bash a.sh,(a.sh就是存放该命令的脚本),这样会为a.sh建立一个sub shell去执行,当执行到exec后,该子脚本进程就被替换成了相应的exec的命令。
source命令或者".",不会为脚本新建shell,而只是将脚本包含的命令在当前shell执行。
不过,要注意一个例外,当exec命令来对文件描述符操作的时候,就不会替换shell,而且操作完成后,还会继续执行接下来的命令。
exec 3<&0:这个命令就是将操作符3也指向标准输入。
另外,这个命令还可以作为find命令的一个选项,如下所示:
(1)在当前目录下(包含子目录),查找所有txt文件并找出含有字符串"bin"的行
find ./ -name "*.txt" -exec grep "bin" {} \;
(2)在当前目录下(包含子目录),删除所有txt文件
find ./ -name "*.txt" -exec rm {} \;
linux下shell脚本执行方法及exec和source命令 (2011-03-04 15:11)
exec和source都属于bash内部命令(builtins commands),在bash下输入man exec或man source可以查看所有的内部命令信息。
bash shell的命令分为两类:外部命令和内部命令。外部命令是通过系统调用或独立的程序实现的,如sed、awk等等。内部命令是由特殊的文件格式(.def)所实现,如cd、history、exec等等。
在说明exe和source的区别之前,先说明一下fork的概念。
fork是linux的系统调用,用来创建子进程(child process)。子进程是父进程(parent process)的一个副本,从父进程那里获得一定的资源分配以及继承父进程的环境。子进程与父进程唯一不同的地方在于pid(process id)。
环境变量(传给子进程的变量,遗传性是本地变量和环境变量的根本区别)只能单向从父进程传给子进程。不管子进程的环境变量如何变化,都不会影响父进程的环境变量。
shell script:
有两种方法执行shell scripts,一种是新产生一个shell,然后执行相应的shell scripts;一种是在当前shell下执行,不再启用其他shell。
新产生一个shell然后再执行scripts的方法是在scripts文件开头加入以下语句
#!/bin/sh
一般的script文件(.sh)即是这种用法。这种方法先启用新的sub-shell(新的子进程),然后在其下执行命令。
另外一种方法就是上面说过的source命令,不再产生新的shell,而在当前shell下执行一切命令。
source:
source命令即点(.)命令。
在 bash下输入man source,找到source命令解释处,可以看到解释"Read and execute commands from filename in the current shell environment and ..."。从中可以知道,source命令是在当前进程中执行参数文件中的各个命令,而不是另起子进程(或sub-shell)。
exec:
在bash下输入man exec,找到exec命令解释处,可以看到有"No new process is created."这样的解释,这就是说exec命令不产生新的子进程。那么exec与source的区别是什么呢?
exec命令在执行时会把当前的shell process关闭,然后换到后面的命令继续执行。
exec [-cl] [-a name] [command [arguments]]
If command is specified, it replaces the shell. No new process is created. The arguments become the arguments to command. If
the -l option is supplied, the shell places a dash at the beginning of the zeroth arg passed to command. This is what login(1)
does. The -c option causes command to be executed with an empty environment. If -a is supplied, the shell passes name as the
zeroth argument to the executed command. If command cannot be executed for some reason, a non-interactive shell exits, unless
the shell option execfail is enabled, in which case it returns failure. An interactive shell returns failure if the file can-
not be executed. If command is not specified, any redirections take effect in the current shell, and the return status is 0.
If there is a redirection error, the return status is 1.
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< exec
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> hadoop-env.sh
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use. Required.
# export JAVA_HOME=/usr/bin/java
# The maximum amount of heap to use, in MB. Default is 1000.
# export HADOOP_HEAPSIZE=2000
# Extra Java runtime options. Empty by default.
# export HADOOP_OPTS=-server
# Extra ssh options. Default: '-o ConnectTimeout=1 -o SendEnv=HADOOP_CONF_DIR'.
# export HADOOP_SSH_OPTS="-o ConnectTimeout=1 -o SendEnv=HADOOP_CONF_DIR"
# Where log files are stored. $HADOOP_HOME/logs by default.
# export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
# File naming remote slave hosts. $HADOOP_HOME/conf/slaves by default.
# export HADOOP_SLAVES=${HADOOP_HOME}/conf/slaves
# host:path where hadoop code should be rsync'd from. Unset by default.
# export HADOOP_MASTER=master:/home/$USER/src/hadoop
# Seconds to sleep between slave commands. Unset by default. This
# can be useful in large clusters, where, e.g., slave rsyncs can
# otherwise arrive faster than the master can service them.
# export HADOOP_SLAVE_SLEEP=0.1
# The directory where pid files are stored. /tmp by default.
# export HADOOP_PID_DIR=/var/hadoop/pids
# A string representing this instance of hadoop. $USER by default.
# export HADOOP_IDENT_STRING=$USER
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< hadoop-env.sh
参考文章
Hadoop源代码分析 之Datanode工作原理(5)—–拷贝文件过程总结
Hadoop源代码分析 之Datanode工作原理(4)—–拷贝本地文件到hadoop的过程
Hadoop源代码分析 之Datanode工作原理(3)—–datanode工作过程总结
Hadoop源代码分析 之Datanode工作原理(2)—–datanode基本工作过程
Hadoop源代码分析 之Datanode工作原理(1)—–datanode启动过程代码分析
Hadoop源代码分析 之hadoop配置及启动(4)—–启动过程汇总
Hadoop源代码分析 之hadoop配置及启动(3)—–classpath与hadoop主要组件启动过程
Hadoop源代码分析 之hadoop配置及启动(2)—–classpath与启动shell脚本
Hadoop源代码分析 之hadoop配置及启动(1)—–classpath与配置文件
Hadoop源代码分析 之hadoop源代码项目(1)—–创建eclipse下java项目
Hadoop源代码分析 之环境配置(1)—–hadoop虚拟机配置
Hadoop源代码分析 之概念介绍(2)—–初学者眼中的hadoop




